
【深度学习】彻底搞懂!Transformer多头注意力 !!
适当增加头数可以使得模型获得更多视角,但头数过多可能导致每个头的维度过低,从而影响每个头的表达能力。展示了模型在未见数据上的预测效果,通过对比两条曲线是否重合或接近,可以直观评估模型的预测准确性。因此,通过实验观察各参数设置下的训练时间与硬件资源消耗,选择在保证效果的前提下资源占用较低的配置。通过这样的划分,可以直观观察模型在未见数据上的预测效果,并判断是否存在过拟合或欠拟合现象。在实际场景中,可
今儿咱们围绕Transformer多头注意力机制和大家聊聊,有一个直观的认识~
Transformer 多头注意力机制用于在处理序列数据(如自然语言或时间序列)时捕捉不同部分之间的复杂关系。
主要思想是:将输入数据分成多个子空间,在每个子空间中独立计算注意力分数,然后将各子空间的信息综合起来,得到更丰富、更全面的表示。
假如大家在开一个讨论会,大家围绕一个问题讨论。每个人都从不同的角度出发,关注问题的不同方面,最后大家把各自的观点汇总,形成一个全面的结论。
Transformer 中的多头注意力就是这样:
-
分成多个小组(头):输入的信息会先被映射到多个不同的子空间。每个子空间(每个头)都会独立地计算注意力,也就是计算各部分之间的重要性。
-
各自讨论后汇总:每个头算出自己的“讨论结果”后,再将所有头的结果拼接起来,经过一次线性变换,就得到了综合各个角度的信息。
-
好处:这样做能让模型同时关注输入的不同特征和不同位置的信息,使得整体信息的提取更加全面和细致。
细节原理
1. 输入表示与线性映射
假设输入序列的表示为矩阵 (其中 是序列长度, 是模型维度),我们需要从中提取三种不同的表示:
-
Query(查询):用于提问,表示当前元素需要关注哪些信息。
-
Key(键):用来和 Query 进行匹配,判断哪些位置的信息更相关。
-
Value(值):包含实际要传递的信息。
通过三个不同的线性变换:
其中 是需要学习的权重矩阵,通常 , 表示头数。
2. Scaled Dot-Product Attention
对于单个注意力头,我们通过计算 Query 和 Key 的点积来衡量相关性:
-
**缩放因子 **:当 较大时,点积可能会变得很大,导致 softmax 后梯度非常小,所以用 对点积进行缩放以稳定梯度。
-
Softmax:接着对每一行应用 softmax 得到注意力权重:
-
加权求和:最后将注意力权重与 Value 相乘,得到该头的输出:
3. 多头注意力机制
在多头注意力中,我们并行执行 个上述的注意力运算,每个头拥有独立的线性变换参数:
每个头输出的维度为 。
接下来,将所有头的输出拼接起来:
然后再经过一个线性变换得到最终的输出:
其中 是输出变换矩阵。
4. 推理过程
-
为什么需要多个头?
每个头可以在不同的子空间里捕捉不同类型的依赖关系。例如,一个头可能关注句子中的语法结构,另一个头可能关注语义关联。这样,模型能够同时从多个角度理解输入数据。 -
为什么用缩放因子?
当维度 较高时, 的数值可能会很大,导致 softmax 变得“尖锐”,即分布中少数几项几乎占据全部权重。除以 可以使得分布更加平滑,从而有助于梯度稳定和训练收敛。 -
整体流程总结
-
线性映射:将输入分别映射到 Query、Key、Value 三个表示上。
-
注意力计算:对每个头计算 得到注意力分布,再与 Value 结合。
-
并行处理与拼接:多个头并行计算后,把各头输出拼接,再经过一个线性变换得到最终的表示。
这种设计使得 Transformer 能够有效捕捉句子中各个部分之间的复杂依赖关系,并且在并行计算上具有很大的优势。
完整案例
这里咱们利用 Transformer 的多头注意力机制解决时间序列预测问题,并且通过构造虚拟数据集来验证该机制的有效性。
实验目的主要包括:
-
掌握 Transformer 多头注意力机制的基本原理与实现流程;
-
了解如何利用位置编码和 Transformer Encoder 提取序列信息;
-
通过虚拟数据集训练,展示模型在时间序列预测任务中的效果;
-
通过多种图形可视化手段展示训练损失、预测曲线、预测分布以及注意力权重,直观分析模型性能;
-
探讨模型的优化方向和超参数调优的具体流程,为后续研究提供参考。
数据集
我们利用正弦函数生成数据序列,每个样本均为一段正弦波形序列,并在此基础上加入随机噪声。
-
数据生成:每个样本首先确定一个随机相位和随机频率,然后根据线性空间生成固定长度的正弦序列,并在生成的过程中加入高斯噪声。噪声的引入使得数据更加贴近实际场景,因为在真实世界中数据往往不会是理想的数学函数,而是会受到各种外部干扰。
-
目标设定:对于每个输入序列,模型的目标是预测下一个时刻的数值。该任务为典型的单变量回归问题,通过预测未来值来验证模型对序列模式的捕捉能力。
-
数据划分:数据集被分为训练集和测试集,其中训练集占 80%,用于模型训练;测试集占 20%,用于评估模型泛化性能。通过这样的划分,可以直观观察模型在未见数据上的预测效果,并判断是否存在过拟合或欠拟合现象。
模型训练和损失函数
训练过程中,使用均方误差(MSE)作为损失函数,原因在于 MSE 能够衡量预测值与真实值之间的平方误差,对于回归问题而言较为常用。
训练流程包括:
-
前向传播:将批次输入经过线性映射、位置编码、Transformer Encoder 层及输出层,得到预测结果。
-
损失计算:利用 MSE 损失函数计算预测值与真实值之间的误差。
-
反向传播与参数更新:计算梯度后采用 Adam 优化器更新模型参数,不断减小损失函数值,使得模型逐步拟合数据分布。
-
训练监控:每个 epoch 结束后记录整体训练损失,通过打印损失值了解模型是否在逐步收敛。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
np.random.seed(42)
# 数据集参数设置
SEQ_LENGTH = 20 # 序列长度
NUM_SAMPLES = 1000 # 样本数量
TRAIN_SPLIT = 0.8 # 训练集比例
# 生成合成时间序列数据:使用正弦函数生成平滑曲线,并加入噪声模拟真实数据
def generate_data(num_samples, seq_length):
X = []
y = []
for i in range(num_samples):
phase = np.random.rand() * 2 * np.pi # 随机相位
freq = np.random.uniform(0.1, 0.5) # 随机频率
# 生成序列数据,加入噪声(标准差 0.1)
x_seq = np.sin(np.linspace(phase, phase + freq * seq_length, seq_length)) + np.random.normal(scale=0.1, size=seq_length)
# 预测下一个时刻的值(延续正弦波趋势,不加入噪声)
next_val = np.sin(phase + freq * (seq_length + 1))
X.append(x_seq)
y.append(next_val)
X = np.array(X)
y = np.array(y)
return X, y
# 生成数据
X_data, y_data = generate_data(NUM_SAMPLES, SEQ_LENGTH)
# 划分训练集和测试集
split_idx = int(NUM_SAMPLES * TRAIN_SPLIT)
X_train = X_data[:split_idx]
y_train = y_data[:split_idx]
X_test = X_data[split_idx:]
y_test = y_data[split_idx:]
# 定义 PyTorch 数据集类
class TimeSeriesDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.float32)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# 实例化数据集和数据加载器
train_dataset = TimeSeriesDataset(X_train, y_train)
test_dataset = TimeSeriesDataset(X_test, y_test)
BATCH_SIZE = 32
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 定义位置编码模块,用于向输入添加位置信息
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 构造位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 利用指数函数构造缩放因子
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 调整为 [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
# x: [batch_size, seq_length, d_model]
x = x + self.pe[:, :x.size(1)]
return x
# 定义 Transformer 模型,包含多头注意力机制,进行时间序列预测
class TransformerModel(nn.Module):
def __init__(self, input_dim=1, d_model=64, nhead=4, num_layers=2, seq_length=SEQ_LENGTH):
super(TransformerModel, self).__init__()
self.d_model = d_model
# 输入线性映射,将原始输入映射到 d_model 维度
self.input_linear = nn.Linear(input_dim, d_model)
# 添加位置编码
self.pos_encoder = PositionalEncoding(d_model)
# 构造 Transformer Encoder 层(内含多头注意力机制)
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=128)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 输出层,将 Transformer 输出整合后映射为单一预测值
self.output_linear = nn.Linear(d_model, 1)
def forward(self, src):
# src: [batch_size, seq_length]
src = src.unsqueeze(-1) # 调整为 [batch_size, seq_length, 1]
src = self.input_linear(src) # 线性映射到 [batch_size, seq_length, d_model]
src = self.pos_encoder(src) # 添加位置编码信息
# Transformer 要求输入形状为 [seq_length, batch_size, d_model]
src = src.transpose(0, 1)
# 经过 Transformer Encoder 层进行编码,内部包含多头注意力机制
transformer_output = self.transformer_encoder(src) # [seq_length, batch_size, d_model]
# 取序列最后一个时刻的输出作为整个序列的表示
output = transformer_output[-1, :, :] # [batch_size, d_model]
output = self.output_linear(output) # 映射为 [batch_size, 1]
return output.squeeze(-1), transformer_output # 返回预测结果及中间输出(用于可视化分析)
# 实例化模型、定义均方误差损失函数和 Adam 优化器
model = TransformerModel()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 开始模型训练
num_epochs = 50
train_losses = [] # 用于记录每个 epoch 的训练损失
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for batch_X, batch_y in train_loader:
optimizer.zero_grad()
# 前向传播得到预测值和 Transformer Encoder 输出
pred, _ = model(batch_X)
loss = criterion(pred, batch_y)
loss.backward()
optimizer.step()
epoch_loss += loss.item() * batch_X.size(0)
epoch_loss /= len(train_loader.dataset)
train_losses.append(epoch_loss)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}")
# 在测试集上进行预测
model.eval()
predictions = []
ground_truth = []
attention_weights = None# 用于存储示例批次的注意力权重信息
with torch.no_grad():
for batch_X, batch_y in test_loader:
pred, transformer_output = model(batch_X)
predictions.extend(pred.numpy())
ground_truth.extend(batch_y.numpy())
# 注意:TransformerEncoderLayer 内部默认并不直接返回注意力权重
# 本示例仅以 transformer_output 的均值作为示例,模拟注意力权重的展示
if attention_weights isNone:
# 计算每个时刻的特征均值作为伪注意力权重
attention_weights = transformer_output.mean(dim=-1).transpose(0,1).numpy() # [batch, seq_length]
# 绘制结果图:一张图中包含4个子图,分别为训练损失曲线、预测曲线、预测值与真实值散点图以及注意力权重热力图
plt.figure(figsize=(16, 12))
# 子图1:Training Loss Curve
plt.subplot(2, 2, 1)
plt.plot(range(1, num_epochs+1), train_losses, color='red', marker='o')
plt.title("Training Loss Curve", fontsize=14)
plt.xlabel("Epoch", fontsize=12)
plt.ylabel("Loss", fontsize=12)
plt.grid(True)
# 子图2:Prediction Curve on Test Set
plt.subplot(2, 2, 2)
plt.plot(range(len(ground_truth)), ground_truth, label="Ground Truth", color='blue', marker='x')
plt.plot(range(len(predictions)), predictions, label="Predictions", color='green', marker='o')
plt.title("Prediction Curve", fontsize=14)
plt.xlabel("Sample Index", fontsize=12)
plt.ylabel("Value", fontsize=12)
plt.legend()
plt.grid(True)
# 子图3:Scatter Plot of Predictions vs Ground Truth
plt.subplot(2, 2, 3)
plt.scatter(ground_truth, predictions, color='purple', alpha=0.7)
plt.plot([min(ground_truth), max(ground_truth)], [min(ground_truth), max(ground_truth)], color='orange', linestyle='--')
plt.title("Predictions vs Ground Truth", fontsize=14)
plt.xlabel("Ground Truth", fontsize=12)
plt.ylabel("Predictions", fontsize=12)
plt.grid(True)
# 子图4:Attention Weights Heatmap (示例展示伪注意力权重)
plt.subplot(2, 2, 4)
plt.imshow(attention_weights, aspect='auto', cmap='hot')
plt.colorbar()
plt.title("Attention Weights Heatmap", fontsize=14)
plt.xlabel("Sequence Position", fontsize=12)
plt.ylabel("Batch Index", fontsize=12)
plt.tight_layout()
plt.show()数据分析图形可视化
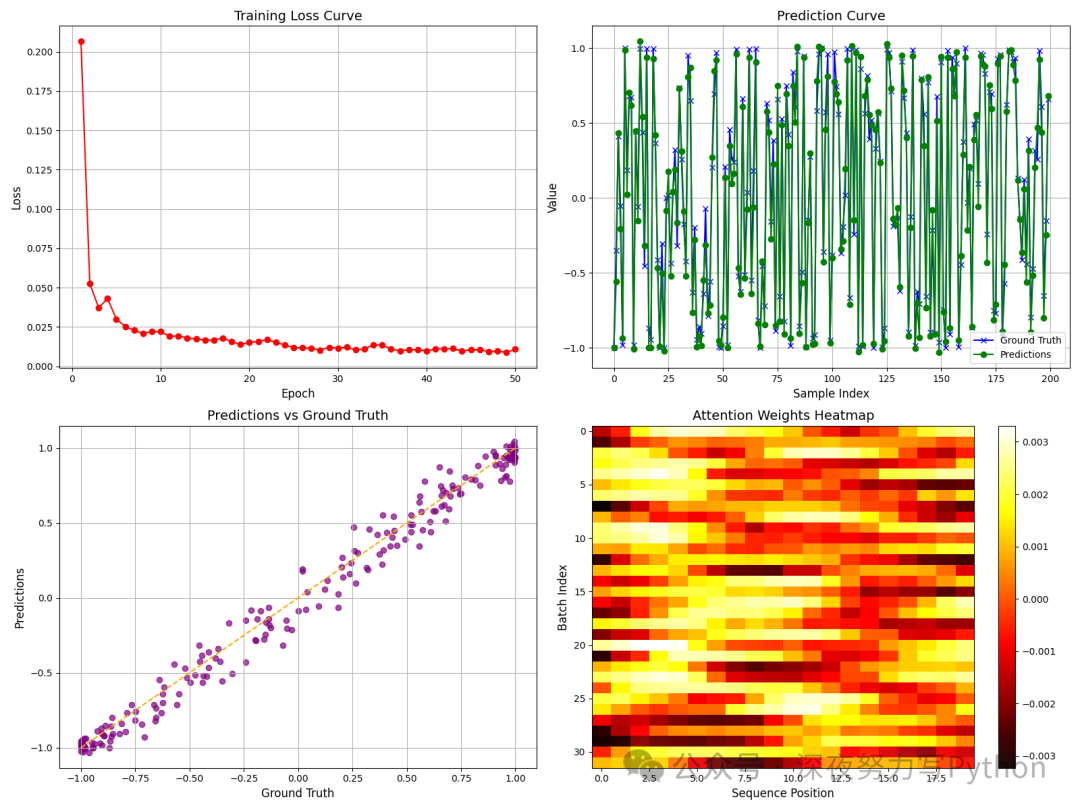
-
图1:Training Loss Curve: 绘制了每个 epoch 的训练损失曲线,横坐标为 epoch 数,纵坐标为损失值。展示模型在训练过程中的损失下降趋势,可以直观地观察模型是否在不断收敛。鲜艳的红色曲线与圆形标记使得曲线清晰可见,便于对比初期较高的损失与后期稳定下降的趋势。
-
图2:Prediction Curve on Test Set:在测试集上绘制了真实值(Ground Truth)与预测值(Predictions)的对比曲线。真实值使用蓝色叉号标记,预测值使用绿色圆形标记。展示了模型在未见数据上的预测效果,通过对比两条曲线是否重合或接近,可以直观评估模型的预测准确性。该图能够帮助我们发现模型是否存在系统性偏差或预测不平滑的问题。
-
图3:Scatter Plot of Predictions vs Ground Truth:通过散点图展示每个样本的预测值与真实值的对应关系,同时绘制了理想情况下的 y=x 参考线(橙色虚线)。能直观反映出模型预测分布与真实值的偏差情况。如果大部分散点分布在参考线上,则说明模型预测效果较好;若存在明显偏离,则说明模型在某些样本上预测存在较大误差。图中采用紫色散点和鲜艳的橙色参考线,使得数据对比更加醒目。
-
图4:Attention Weights Heatmap:以热力图的形式展示 Transformer Encoder 输出的伪注意力权重,横坐标表示序列中各个时刻,纵坐标表示批次内不同样本。虽然在本示例中注意力权重为模拟数据,但该图意在展示 Transformer 内部注意力分布的一个视角,从中可以观察模型是否在不同时间步上赋予不同权重。热力图采用鲜艳的“hot”配色,色彩层次分明,能帮助研究人员直观地了解模型在各个时间步上的信息聚合情况。
算法优化点与超参数调优流程
1. 模型结构优化
-
Transformer Encoder 层数(num_layers):增加 Encoder 层数有助于模型捕捉更加复杂的序列依赖关系,但同时会增加模型参数量,可能导致过拟合问题。在实际应用中,可以采用交叉验证来确定最优层数,或者在模型中引入残差连接和层归一化技术以缓解深层网络的训练难度。
-
隐藏层维度(d_model)与前馈网络维度(dim_feedforward):较高的隐藏层维度可以提高模型的表达能力,但也会使计算量显著增加。前馈网络的维度一般设置为 d_model 的 2~4 倍,可以在模型性能和计算开销之间进行平衡。调参时可以尝试不同的维度组合,观察验证集上的表现来选择最优配置。
-
注意力头数(nhead):多头注意力的核心优势在于能从不同子空间捕捉信息。适当增加头数可以使得模型获得更多视角,但头数过多可能导致每个头的维度过低,从而影响每个头的表达能力。因此,需综合考虑 d_model 与头数之间的关系,确保每个头的维度(d_k)足够表达关键信息。实验中可尝试 2、4、8 等不同设置,并比较各自的预测误差与训练稳定性。
2. 数据预处理与数据增强
-
归一化/标准化:对输入数据进行归一化或标准化处理,能够使数据分布更加均衡,加快模型收敛速度。对于时间序列数据,可以考虑对每个样本或整个数据集进行归一化处理。
-
数据噪声与数据增强:在虚拟数据集上,已引入随机噪声以模拟真实数据。在实际场景中,可以考虑进一步扩充数据集,如对序列进行局部扰动、切分等方法,增加数据多样性,提升模型鲁棒性。
3. 学习率与优化器调优
-
初始学习率选择:本案例中初始学习率设为 0.001,后续可以采用学习率调度器(如 StepLR、CosineAnnealingLR 或 ReduceLROnPlateau)动态调整学习率。初始学习率过高可能导致模型训练不稳定,而过低则训练速度缓慢,故需要通过实验逐步调优确定合适的范围。
-
优化器的选择:Adam 优化器具有自适应学习率调整的优势,适用于大部分场景。但在某些问题上,SGD 或 AdamW 也可能表现更好。调参时可以对比不同优化器的收敛速度和最终预测误差,选取最佳方案。
-
梯度裁剪与正则化:对于 Transformer 模型,由于层数较深,梯度爆炸问题可能会出现。可以采用梯度裁剪技术限制梯度幅度;同时,适当增加 dropout 率也能有效防止过拟合。常用的 dropout 概率范围为 0.1~0.5,根据数据量和模型复杂度进行调整。
4. 超参数调优流程
超参数调优常用方法包括网格搜索、随机搜索和贝叶斯优化。
-
确定初始范围:根据理论经验及初步实验结果,确定每个超参数(如 learning rate、batch size、num_layers、d_model、nhead、dropout 等)的初始范围。例如:
-
learning rate: 0.0001 ~ 0.01
-
batch size: 16、32、64
-
num_layers: 1 ~ 4
-
d_model: 32、64、128
-
nhead: 2、4、8
-
dropout: 0.1 ~ 0.5
-
单变量调优:固定其他超参数,逐一对某一超参数进行调优,记录验证集损失及预测误差。比如先固定模型结构,测试不同学习率的效果,找到在稳定收敛与较低验证误差之间的平衡点。
-
联合调优:根据单变量调优结果,选取若干组合进行联合实验。采用网格搜索或随机搜索方法,在各参数交互作用下寻找最佳组合。实验中可以利用早停机制(Early Stopping)防止过拟合,并记录每次实验的详细指标(如训练损失、验证损失、预测误差、收敛速度等)。
-
模型复杂度与计算资源平衡:在调参过程中还需要考虑模型参数量和计算资源的平衡。较大的 d_model 或更多的 Encoder 层虽然可能提升模型表达能力,但同时会带来更高的训练时间和内存占用。因此,通过实验观察各参数设置下的训练时间与硬件资源消耗,选择在保证效果的前提下资源占用较低的配置。
-
结果分析与可视化:记录各组实验数据,利用损失曲线、预测曲线、散点图、注意力权重热图等多种可视化手段,直观对比不同超参数设置下模型表现。通过数据统计与图形展示,判断哪些超参数对模型影响较大,并据此调整下一步实验策略。
-
最终模型确定:综合验证集表现、实验记录和实际需求,最终确定最优超参数组合,并在测试集上进行最终评估。必要时,可采用交叉验证进一步检验模型的稳定性。
-
最后
总的来说,咱们整个内容不仅提供了一个基于 Transformer 多头注意力机制的时间序列预测实例,还详细介绍了从数据生成到模型构建、训练、可视化分析及超参数调优的完整流程。
喜欢本文的朋友可以收藏、点赞、转发起来!
更多推荐
 0
0 0
0- 0



 已为社区贡献112条内容
已为社区贡献112条内容

所有评论(0)