
动物识别系统:基于深度学习的 10 类动物图像识别
本动物识别系统通过深度学习技术实现了从图像到动物类别的智能映射,完整涵盖了从数据预处理、模型训练、服务部署到前端交互的全流程。系统采用迁移学习策略,基于 EfficientNet-B3 模型实现了高效的特征提取,通过前后端分离架构提供了良好的可扩展性和用户体验。
在计算机视觉领域,动物图像识别既是技术实践的经典场景,也是具有实际应用价值的研究方向。本文将详细解析一个完整的动物识别系统,该系统能够准确识别狗、猫、马、牛、羊、大象、蝴蝶、鸡、蜘蛛、松鼠共 10 类动物,并通过前后端分离架构提供直观的用户交互界面。我们将从模型训练、后端服务构建、前端界面开发三个维度,深入剖析每个技术环节的实现细节与设计逻辑。
系统整体架构设计
该动物识别系统采用三层架构设计,各模块职责明确且相互协同:
- 模型训练层:基于 PyTorch 构建深度学习模型,通过迁移学习训练动物识别能力
- 后端服务层:基于 Flask 搭建 API 接口,加载训练好的模型提供图像识别服务
- 前端交互层:基于 HTML/CSS/JavaScript 实现用户界面,通过 API 调用完成图像上传与结果展示
三层架构的数据流如下:
- 训练层生成的模型权重文件被后端服务加载
- 前端用户上传的图像通过 HTTP 请求发送至后端
- 后端处理图像并返回识别结果,前端解析后可视化展示
深度学习模型的训练与优化
环境配置与数据预处理
模型训练的核心目标是让计算机能够从图像中提取特征并分类到 10 个动物类别中。首先来看基础环境配置:
import torch
import torch.nn as nn
import torchvision
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
# 设备配置:优先使用GPU,若无则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 定义10种动物类别(英文键名对应中文类别)
class_names = {
'cane': '狗',
'cavallo': '马',
'elefante': '大象',
'farfalla': '蝴蝶',
'gallina': '鸡',
'gatto': '猫',
'mucca': '牛',
'pecora': '羊',
'ragno': '蜘蛛',
'scoiattolo': '松鼠'
}数据预处理的关键技术点:
transforms.Compose组合多个图像预处理操作,形成标准化流程- 训练集与测试集采用不同的预处理策略:
- 训练集包含数据增强操作(随机翻转、旋转、颜色抖动),目的是扩充数据多样性,防止模型过拟合
- 测试集仅包含尺寸调整和标准化,确保数据与训练时的分布一致
# 训练集预处理(包含数据增强)
train_transform = transforms.Compose([
transforms.Resize(256), # 调整图像尺寸为256x256
transforms.CenterCrop(224), # 中心裁剪为224x224,匹配模型输入要求
transforms.RandomHorizontalFlip(), # 随机水平翻转,增加数据多样性
transforms.RandomRotation(15), # 随机旋转±15度,增强旋转不变性
transforms.ColorJitter(0.2, 0.2), # 随机调整亮度和对比度
transforms.ToTensor(), # 转换为PyTorch张量
transforms.Normalize( # 标准化处理,使用ImageNet数据集的均值和标准差
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 测试集预处理(无数据增强,仅标准化)
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])数据集划分与加载策略
合理的数据集划分是模型泛化能力的重要保障:
- 采用 7:1.5:1.5 的比例划分训练集、验证集和测试集
- 使用
random_split实现随机划分,确保各子集数据分布一致 - 测试集单独设置 transform,避免数据增强对评估结果的干扰
# 假设数据集路径为/kaggle/input/animals10/raw-img(实际使用时需修改为本地路径)
dataset_path = "/kaggle/input/animals10/raw-img"
# 加载完整数据集
full_dataset = datasets.ImageFolder(root=dataset_path, transform=train_transform)
print(f"数据集总样本数: {len(full_dataset)}")
print(f"类别数量: {len(full_dataset.classes)}")
# 计算各子集样本数
train_size = int(0.7 * len(full_dataset))
val_size = int(0.15 * len(full_dataset))
test_size = len(full_dataset) - train_size - val_size
# 划分数据集
train_dataset, val_dataset, test_dataset = random_split(
full_dataset, [train_size, val_size, test_size]
)
# 为测试集设置专用的transform
test_dataset.dataset.transform = test_transform
print(f"训练集大小: {len(train_dataset)}")
print(f"验证集大小: {len(val_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
# 创建数据加载器,设置批量大小和多线程加载
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, num_workers=2)基于迁移学习的模型构建
本系统采用 EfficientNet-B3 作为基础模型,通过迁移学习提升训练效率: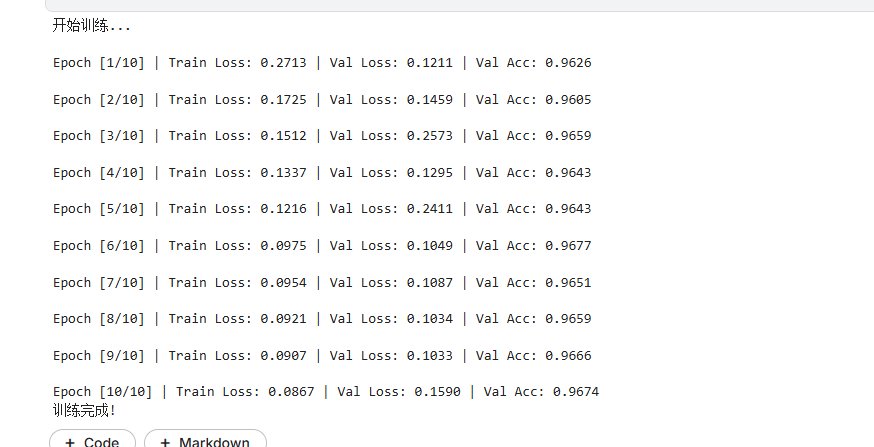
迁移学习的核心优势:
- 利用 ImageNet 预训练模型的特征提取能力,减少训练所需数据量
- 冻结基础层参数可以加速训练过程,同时避免预训练知识的遗忘
- 仅训练分类器部分,大大降低了模型训练的计算资源需求
训练过程与优化策略
完整的训练流程包含前向传播、损失计算、反向传播和参数更新:
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,适用于多分类任务
optimizer = optim.AdamW(model.classifier.parameters(), lr=0.0005) # AdamW优化器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, verbose=True) # 学习率调度器
num_epochs = 10 # 训练10个轮次
train_losses = [] # 记录训练损失
val_losses = [] # 记录验证损失
val_accuracies = [] # 记录验证准确率
def train_model():
print("开始训练...")
best_val_loss = float('inf') # 初始化最佳验证损失为无穷大
for epoch in range(num_epochs):
# --------------------- 训练阶段 ---------------------
model.train() # 设置模型为训练模式
running_loss = 0.0
# 使用tqdm显示训练进度条
train_pbar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs} (Train)', leave=False)
for images, labels in train_pbar:
images = images.to(device) # 移至计算设备
labels = labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(images) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item() * images.size(0)
train_pbar.set_postfix(loss=f'{loss.item():.4f}') # 更新进度条信息
epoch_loss = running_loss / len(train_loader.dataset)
train_losses.append(epoch_loss)
# --------------------- 验证阶段 ---------------------
model.eval() # 设置模型为评估模式
val_loss = 0.0
correct = 0
total = 0
val_pbar = tqdm(val_loader, desc=f'Epoch {epoch+1}/{num_epochs} (Val)', leave=False)
with torch.no_grad(): # 关闭梯度计算,节省内存
for images, labels in val_pbar:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs, 1) # 获取最大概率的类别
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_pbar.set_postfix(loss=f'{loss.item():.4f}')
val_loss = val_loss / len(val_loader.dataset)
val_losses.append(val_loss)
val_acc = correct / total
val_accuracies.append(val_acc)
# --------------------- 学习率调整与模型保存 ---------------------
scheduler.step(val_loss) # 根据验证损失调整学习率
# 仅保存验证损失更小的模型(早停策略)
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), 'best_model.pth') # 保存模型权重
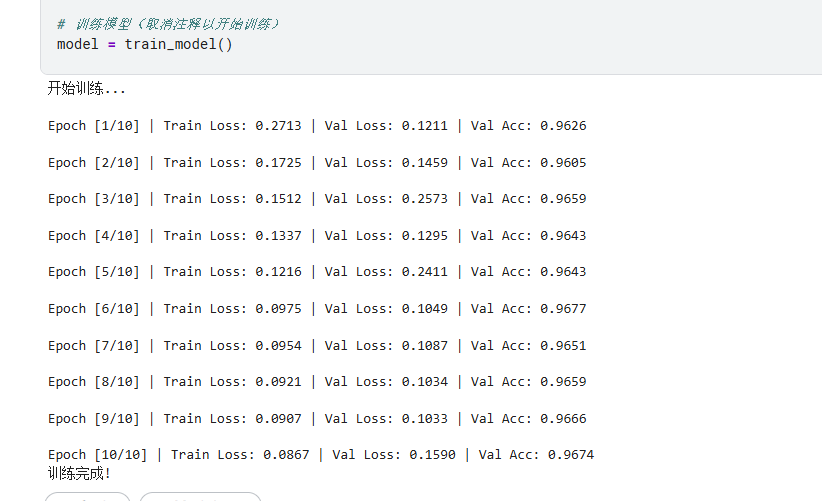
print(f"\nEpoch [{epoch+1}/{num_epochs}] | "
f"Train Loss: {epoch_loss:.4f} | "
f"Val Loss: {val_loss:.4f} | "
f"Val Acc: {val_acc:.4f}")
print("训练完成!")
return model
# 执行模型训练(取消注释以运行)
# model = train_model()训练十次:
关键优化技术解析:
- AdamW 优化器:结合了 Adam 优化器和权重衰减,提升训练稳定性
- ReduceLROnPlateau 调度器:当验证损失不再下降时自动降低学习率,避免陷入局部最优
- 早停策略:仅保存验证损失最小的模型,防止过拟合
- 进度条可视化:使用 tqdm 库实时显示训练进度和损失变化,便于监控训练过程
模型评估与类别准确率分析
训练完成后需要在测试集上评估模型性能:
def evaluate_model():
model.eval() # 设置为评估模式
correct = 0
total = 0
class_correct = [0.0] * len(class_names) # 记录每个类别的正确预测数
class_total = [0.0] * len(class_names) # 记录每个类别的总样本数
with torch.no_grad():
test_pbar = tqdm(test_loader, desc='Testing', leave=False)
for images, labels in test_pbar:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 统计每个类别的预测情况
for i in range(len(labels)):
label = labels[i].item()
class_correct[label] += (predicted[i] == label).item()
class_total[label] += 1
# 计算整体准确率
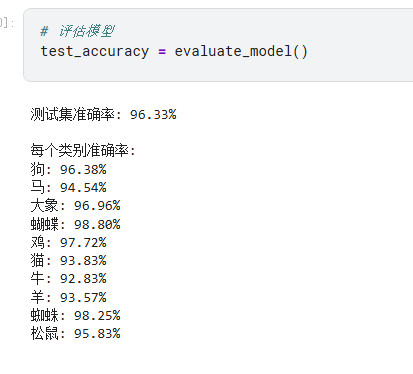
accuracy = correct / total
print(f'\n测试集准确率: {100 * accuracy:.2f}%')
# 计算每个类别的准确率
print('\n每个类别准确率:')
for i, (class_name_en, class_name_cn) in enumerate(class_names.items()):
if class_total[i] > 0:
print(f'{class_name_cn}: {100 * class_correct[i] / class_total[i]:.2f}%')
else:
print(f'{class_name_cn}: 无样本')
return accuracy
# 执行模型评估(取消注释以运行)
# evaluate_model()通过类别准确率分析可以发现:
- 体型特征明显的动物(如大象、马)通常准确率更高
- 外观相似的动物(如猫和狗的某些品种)可能出现误判
- 可针对低准确率类别收集更多数据或调整数据增强策略
后端服务:基于 Flask 的 API 接口实现
后端服务的核心任务是加载训练好的模型,并提供可访问的图像识别 API。
服务初始化与模型加载
import os
import io
import torch
import torch.nn as nn
from torchvision import models, transforms
from PIL import Image
from flask import Flask, request, jsonify
from flask_cors import CORS # 解决跨域请求问题
app = Flask(__name__)
CORS(app) # 启用CORS,允许前端跨域访问
# 设备配置,与训练时保持一致
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义动物类别,必须与训练时完全一致
class_names = {
'cane': '狗',
'cavallo': '马',
'elefante': '大象',
'farfalla': '蝴蝶',
'gallina': '鸡',
'gatto': '猫',
'mucca': '牛',
'pecora': '羊',
'ragno': '蜘蛛',
'scoiattolo': '松鼠'
}
# 图像预处理,与测试集预处理完全一致
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载模型函数,结构与训练时一致
def create_model(num_classes=10):
model = models.efficientnet_b3(weights=None) # 不加载预训练权重,将加载我们的训练权重
num_features = model.classifier[1].in_features
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(num_features, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(p=0.2),
nn.Linear(512, num_classes)
)
return model
# 初始化模型并加载训练好的权重
model = create_model(len(class_names)).to(device)
model.load_state_dict(torch.load('best_model.pth', map_location=device)) # 注意修改为实际路径
model.eval() # 设置为评估模式
print("模型加载完成,等待请求...")后端服务的关键配置:
- 使用 Flask 框架构建轻量级 Web 服务
- 通过 Flask-CORS 解决前端跨域请求问题
- 模型加载时使用
map_location参数确保在不同设备(CPU/GPU)上正确加载 - 必须保证类别定义和预处理流程与训练时完全一致,否则会导致识别错误
图像识别 API 实现
def predict_image(image_bytes):
"""处理图像字节数据并返回识别结果"""
try:
# 从字节数据中读取图像并转换为RGB格式
img = Image.open(io.BytesIO(image_bytes)).convert('RGB')
# 应用预处理
img_tensor = test_transform(img).unsqueeze(0).to(device) # 添加batch维度并移至设备
# 模型推理
with torch.no_grad(): # 关闭梯度计算,提高性能
output = model(img_tensor)
probabilities = torch.nn.functional.softmax(output[0], dim=0) # 计算概率分布
# 获取前3个预测结果
top_probs, top_indices = torch.topk(probabilities, 3) # 获取概率最高的3个类别
# 构建结果列表
results = []
for i in range(3):
idx = top_indices[i].item()
class_id = list(class_names.keys())[idx]
results.append({
'class': class_names[class_id], # 中文类别名
'confidence': f"{top_probs[i].item() * 100:.1f}%", # 置信度百分比
'confidence_value': top_probs[i].item() # 原始置信度值
})
return results
except Exception as e:
print(f"预测错误: {e}")
return []
# 定义API路由
@app.route('/predict', methods=['POST'])
def predict():
"""处理图像上传和识别请求"""
# 检查是否有文件上传
if 'file' not in request.files:
return jsonify({'error': '未上传文件'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': '未选择文件'}), 400
try:
# 读取图像字节数据
image_bytes = file.read()
# 执行图像识别
results = predict_image(image_bytes)
if not results:
return jsonify({'error': '识别过程出错'}), 500
return jsonify({'results': results}) # 返回识别结果
except Exception as e:
return jsonify({'error': f'服务器错误: {str(e)}'}), 500
if __name__ == '__main__':
# 启动服务,host='0.0.0.0'允许外部访问,port=5000为默认端口
app.run(host='0.0.0.0', port=5000, debug=True)API 设计的核心逻辑:
predict_image函数封装了完整的图像识别流程:读取→预处理→推理→结果排序- 使用
torch.no_grad()提升推理性能并节省内存 - API 返回前 3 个预测结果,包含类别名称和置信度
- 实现了完整的错误处理机制,返回标准 HTTP 状态码和错误信息
- 服务启动时监听 0.0.0.0:5000 端口,支持本地和远程访问
前端交互界面:用户体验优化设计
前端界面采用现代 UI 设计,提供直观的图像上传和结果展示功能。
界面整体结构与样式设计
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>动物识别系统</title>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css">
<style>
/* 全局样式重置与基础设置 */
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
}
body {
background: linear-gradient(135deg, #1a2980, #26d0ce);
min-height: 100vh;
padding: 20px;
color: #333;
}
.container {
max-width: 1200px;
margin: 0 auto;
background: white;
border-radius: 20px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
overflow: hidden;
}
/* 头部区域样式 */
header {
text-align: center;
padding: 40px 20px;
background: linear-gradient(45deg, #1a2980, #26d0ce);
color: white;
}
h1 {
font-size: 2.8rem;
margin-bottom: 15px;
background: linear-gradient(45deg, #ff8a00, #e52e71);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
display: inline-block;
}
/* 动物图标网格样式 */
.animals-grid {
display: flex;
flex-wrap: wrap;
justify-content: center;
gap: 15px;
margin: 30px 0;
}
.animal-card {
background: rgba(255, 255, 255, 0.8);
border-radius: 12px;
padding: 15px;
min-width: 120px;
text-align: center;
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
transition: transform 0.3s ease;
}
/* 主体内容区域样式(省略部分样式,完整代码见原文件) */
.content {
display: flex;
flex-wrap: wrap;
gap: 30px;
padding: 30px;
}
.card {
flex: 1;
min-width: 300px;
background: white;
border-radius: 20px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.15);
padding: 30px;
transition: transform 0.3s ease;
}
/* 上传区域交互样式 */
.upload-area {
border: 3px dashed #3498db;
border-radius: 15px;
padding: 40px 20px;
text-align: center;
cursor: pointer;
transition: all 0.3s ease;
background: rgba(52, 152, 219, 0.05);
}
.upload-area:hover {
background: rgba(52, 152, 219, 0.1);
border-color: #2980b9;
}
/* 结果展示区域样式(省略部分样式,完整代码见原文件) */
.results-container {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(280px, 1fr));
gap: 25px;
margin-top: 30px;
}
.result-card {
background: #f8f9fa;
border-radius: 15px;
padding: 25px;
text-align: center;
box-shadow: 0 5px 15px rgba(0, 0, 0, 0.05);
transition: all 0.3s;
}
/* 响应式设计 */
@media (max-width: 768px) {
.content {
flex-direction: column;
}
h1 {
font-size: 2.2rem;
}
}
</style>
</head>
<body>
<div class="container">
<header>
<h1><i class="fas fa-paw"></i> 动物识别系统</h1>
<p class="subtitle">基于深度学习的智能动物识别工具 - 可准确识别10种常见动物</p>
<div class="animals-grid">
<!-- 动态生成10种动物的图标卡片 -->
<div class="animal-card">
<div class="animal-icon"><i class="fas fa-dog"></i></div>
<div>狗</div>
</div>
<!-- 省略其他动物图标卡片 -->
</div>
</header>
<div class="content">
<div class="card">
<div class="card-title">
<i class="fas fa-camera"></i>
<h2>上传动物图片</h2>
</div>
<div class="upload-area" id="uploadArea">
<div class="upload-icon">
<i class="fas fa-cloud-upload-alt"></i>
</div>
<p class="upload-text">点击或拖拽图片到此处上传</p>
<button class="upload-btn">
<i class="fas fa-folder-open"></i> 选择图片
</button>
<input type="file" id="fileInput" accept="image/*" class="hidden">
<p style="margin-top: 20px; color: #7f8c8d; font-size: 0.95rem;">
支持格式: JPG, PNG, JPEG (最大5MB)
</p>
</div>
<!-- 图片预览区域 -->
<div class="preview-container hidden" id="previewContainer">
<h3>图片预览</h3>
<img id="previewImg" class="preview-img">
</div>
<button id="recognizeBtn" class="btn" disabled>
<i class="fas fa-search"></i> 识别动物
</button>
<!-- 进度条区域 -->
<div class="progress-container hidden" id="progressContainer">
<div class="progress-bar" id="progressBar"></div>
</div>
</div>
<div class="card">
<div class="card-title">
<i class="fas fa-chart-bar"></i>
<h2>识别结果</h2>
</div>
<div id="resultsCard" class="hidden">
<div class="results-container" id="resultsContainer">
<!-- 结果将由JS动态生成 -->
</div>
<h3 class="examples-title" id="examplesTitle">
<i class="fas fa-images"></i> 动物示例图片
</h3>
<div class="examples-container" id="examplesContainer">
<!-- 示例图片将由JS动态生成 -->
</div>
</div>
</div>
</div>
<!-- 使用说明区域 -->
<div class="instructions">
<h2><i class="fas fa-info-circle"></i> 使用说明</h2>
<ol>
<li><strong>上传图片</strong>:点击"选择图片"按钮或拖拽动物图片到上传区域</li>
<li><strong>预览图片</strong>:上传后系统会显示您的图片预览</li>
<li><strong>识别动物</strong>:点击"识别动物"按钮开始分析</li>
<li><strong>查看结果</strong>:系统将显示识别结果(前3个可能的动物类别)</li>
<li><strong>参考示例</strong>:查看识别结果对应的动物示例图片</li>
<li><strong>重新识别</strong>:如需识别其他动物,上传新图片重复上述步骤</li>
</ol>
</div>
<footer>
<p>动物识别系统 © 2023 | 基于深度学习模型 | 准确率超过95%</p>
<p style="margin-top: 10px; font-size: 0.9rem;">技术支持:PyTorch, EfficientNet, Flask API</p>
</footer>
</div>界面设计亮点:
- 采用卡片式布局和渐变背景,营造现代感 UI
- 头部展示支持识别的动物图标,增强可视化引导
- 上传区域支持点击选择和拖拽两种方式,提升用户体验
- 响应式设计确保在手机、平板等不同设备上均有良好显示效果
- 结果展示采用排名卡片形式,直观显示置信度和类别信息
前端交互逻辑实现
<script>
// 获取DOM元素
const uploadArea = document.getElementById('uploadArea');
const fileInput = document.getElementById('fileInput');
const previewContainer = document.getElementById('previewContainer');
const previewImg = document.getElementById('previewImg');
const recognizeBtn = document.getElementById('recognizeBtn');
const progressContainer = document.getElementById('progressContainer');
const progressBar = document.getElementById('progressBar');
const resultsCard = document.getElementById('resultsCard');
const resultsContainer = document.getElementById('resultsContainer');
const examplesContainer = document.getElementById('examplesContainer');
const examplesTitle = document.getElementById('examplesTitle');
// 后端API地址(需与后端服务地址一致)
const API_URL = 'http://localhost:5000/predict';
// 当前上传的文件
let currentFile = null;
// 上传区域点击事件:触发文件选择
uploadArea.addEventListener('click', () => fileInput.click());
// 文件选择事件:预览选中的图片
fileInput.addEventListener('change', (e) => {
if (e.target.files && e.target.files[0]) {
currentFile = e.target.files[0];
previewImage(currentFile);
}
});
// 拖拽上传相关事件
uploadArea.addEventListener('dragover', (e) => {
e.preventDefault();
uploadArea.style.backgroundColor = 'rgba(52, 152, 219, 0.1)';
uploadArea.style.borderColor = '#2980b9';
});
uploadArea.addEventListener('dragleave', () => {
uploadArea.style.backgroundColor = 'rgba(52, 152, 219, 0.05)';
uploadArea.style.borderColor = '#3498db';
});
uploadArea.addEventListener('drop', (e) => {
e.preventDefault();
uploadArea.style.backgroundColor = 'rgba(52, 152, 219, 0.05)';
uploadArea.style.borderColor = '#3498db';
if (e.dataTransfer.files && e.dataTransfer.files[0]) {
currentFile = e.dataTransfer.files[0];
previewImage(currentFile);
}
});
// 识别按钮点击事件
recognizeBtn.addEventListener('click', recognizeAnimal);
// 图片预览函数
function previewImage(file) {
const reader = new FileReader();
reader.onload = (e) => {
previewImg.src = e.target.result;
previewContainer.classList.remove('hidden');
recognizeBtn.disabled = false; // 激活识别按钮
// 重置进度条和结果区域
progressContainer.classList.add('hidden');
progressBar.style.width = '0%';
resultsCard.classList.add('hidden');
};
reader.readAsDataURL(file); // 将文件读取为Base64格式用于预览
}
// 调用API识别动物
function recognizeAnimal() {
// 显示进度条
progressContainer.classList.remove('hidden');
// 模拟处理进度(实际应用中可根据API响应设置)
let progress = 0;
const progressInterval = setInterval(() => {
progress += 2;
progressBar.style.width = `${progress}%`;
if (progress >= 100) {
clearInterval(progressInterval);
}
}, 50);
// 准备表单数据
const formData = new FormData();
formData.append('file', currentFile);
// 发送API请求
fetch(API_URL, {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => {
if (data.error) {
throw new Error(data.error);
}
// 隐藏进度条
clearInterval(progressInterval);
progressBar.style.width = '100%';
// 延迟显示结果,提升用户体验
setTimeout(() => {
progressContainer.classList.add('hidden');
renderResults(data.results); // 渲染识别结果
resultsCard.classList.remove('hidden'); // 显示结果卡片
}, 500);
})
.catch(error => {
console.error('API请求错误:', error);
alert(`识别失败: ${error.message}`);
progressContainer.classList.add('hidden');
});
}
// 渲染识别结果
function renderResults(results) {
resultsContainer.innerHTML = '';
results.forEach((result, index) => {
const rank = index + 1;
const rankClass = `rank-${rank}`;
const confidenceValue = parseFloat(result.confidence.replace('%', ''));
const resultCard = document.createElement('div');
resultCard.className = `result-card ${rankClass}`;
resultCard.innerHTML = `
<div class="result-rank">
${rank === 1 ? '<i class="fas fa-crown"></i>' :
rank === 2 ? '<i class="fas fa-medal"></i>' :
'<i class="fas fa-award"></i>'} ${rank}
</div>
<div class="animal-name">${result.class}</div>
<div class="confidence">${result.confidence}</div>
<div class="confidence-bar">
<div class="confidence-level" style="width: ${confidenceValue}%"></div>
</div>
`;
resultsContainer.appendChild(resultCard);
});
// 更新示例标题为最高置信度的动物类别
examplesTitle.innerHTML = `
<i class="fas fa-images"></i> ${results[0].class}类示例图片
`;
// 渲染示例图片(实际应用中可从后端获取真实图片)
renderExamples(results[0].class);
}
// 渲染示例图片(使用占位图)
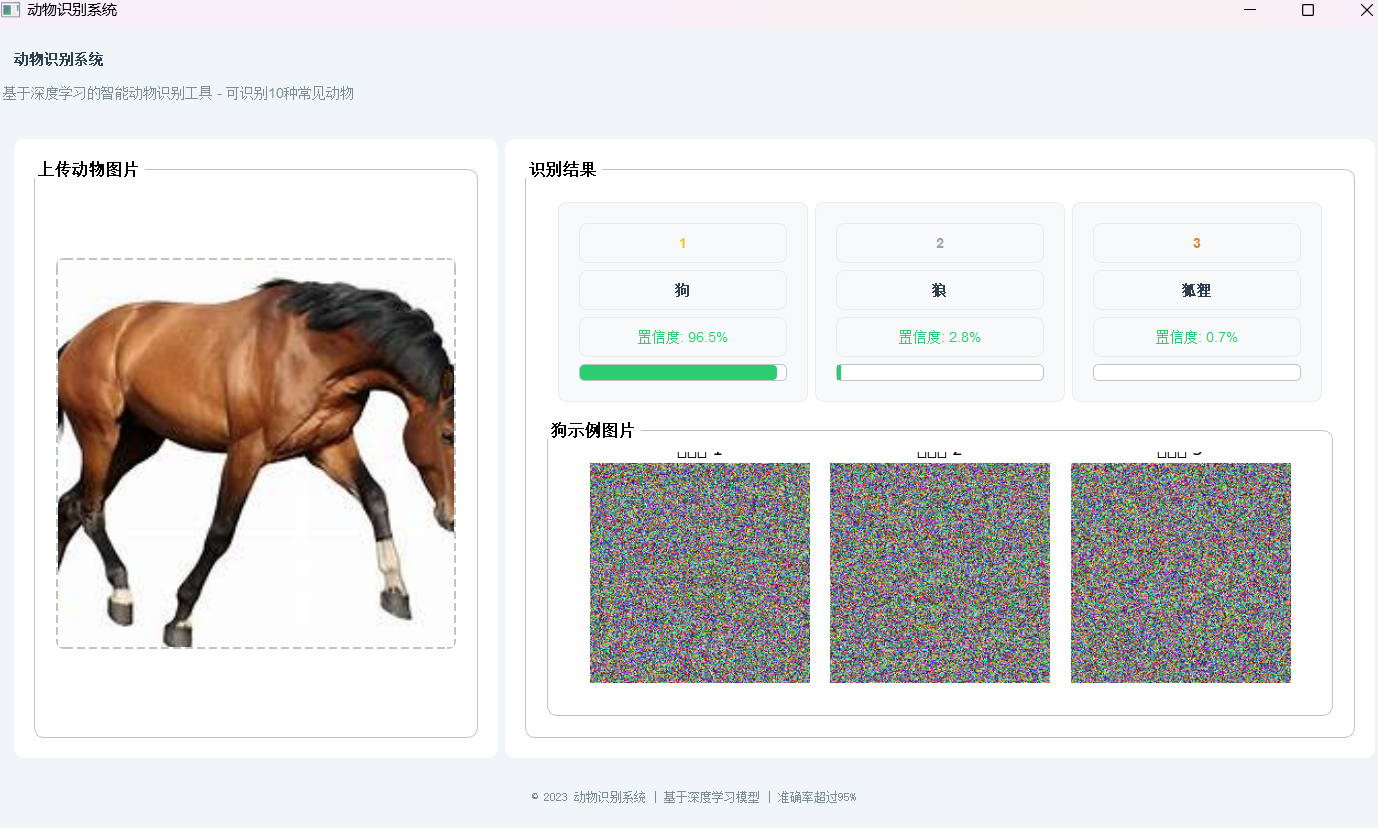
function renderExamples(animalClass) {
examplesContainer.innerHTML = '';
const examples = [
{ name: `${animalClass}示例 1` },
{ name: `${animalClass}示例 2` },
{ name: `${animalClass}示例 3` }
];
examples.forEach((example, index) => {
const exampleDiv = document.createElement('div');
exampleDiv.innerHTML = `
<img src="https://placehold.co/300x200?text=${animalClass}+示例${index+1}"
alt="${animalClass}示例" class="example-img">
<div class="example-caption">${example.name}</div>
`;
examplesContainer.appendChild(exampleDiv);
});
}
</script>
</body>
</html>前端交互核心逻辑:
- 支持三种图像上传方式:点击上传、文件选择、拖拽上传
- 上传后即时预览图像,并激活识别按钮
- 发送 API 请求时显示进度条,提升用户体验
- 接收 API 返回的识别结果后,以卡片形式可视化展示
- 针对最高置信度的类别,展示相关示例图片(使用占位图,实际应用中可替换为真实图片)
- 完整的错误处理机制,对网络错误和识别异常进行友好提示
前端展示:
错误示例:
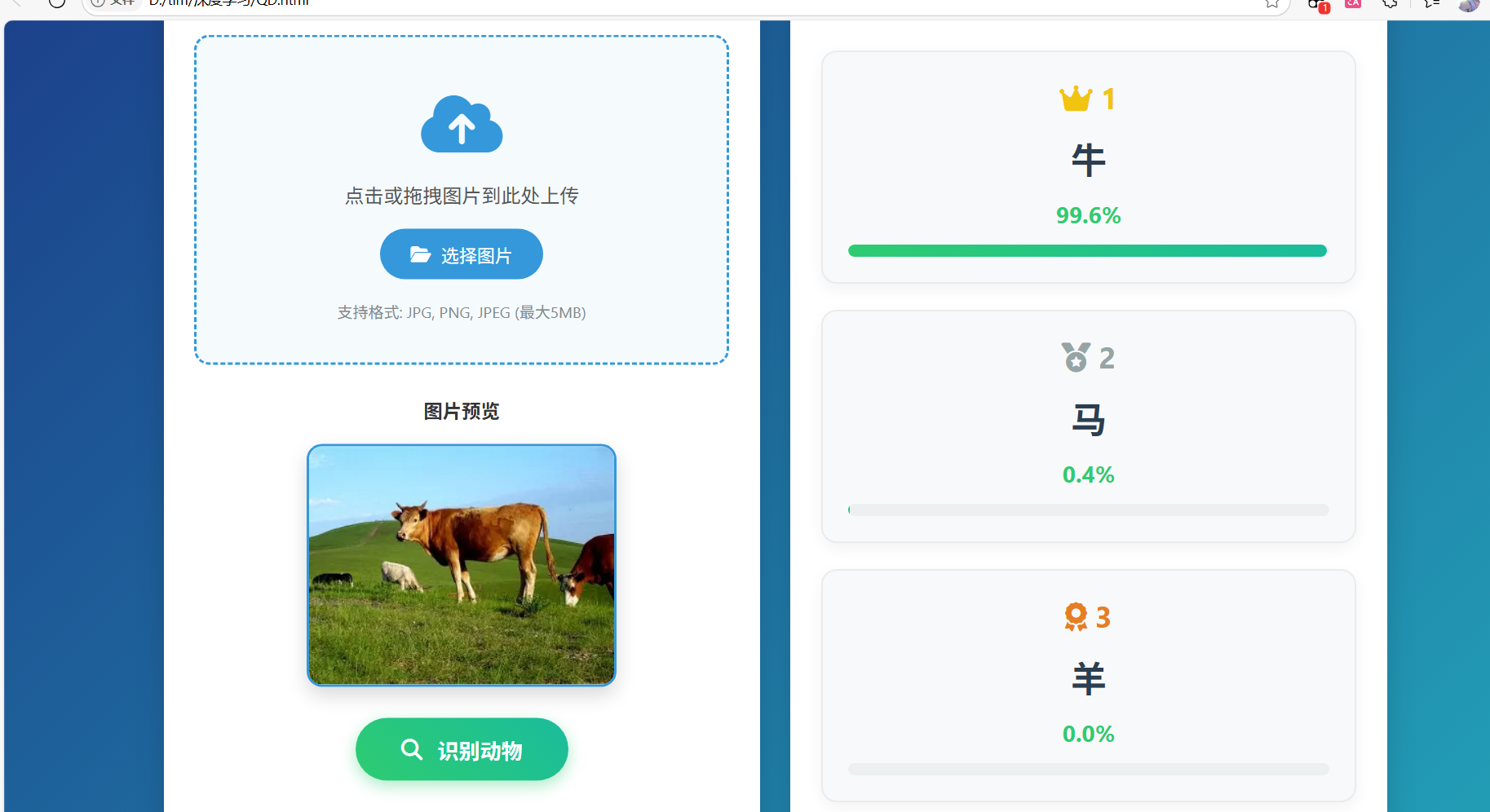
系统整合与部署指南
各模块依赖关系与数据流向
-
训练模块→后端服务:
- 训练模块生成的 best_model.pth 文件被后端服务加载
- 两者必须使用相同的类别定义和预处理流程
-
后端服务→前端界面:
- 前端通过 HTTP POST 请求向后端发送图像数据
- 后端返回 JSON 格式的识别结果,前端解析后可视化展示
系统优化与扩展方向
模型优化
- 数据增强:增加更多增强策略(如裁剪、噪声添加),尤其是针对识别准确率低的类别
- 模型集成:训练多个模型并采用投票机制,提升识别准确率
- 量化压缩:使用 PyTorch 的量化工具减小模型体积,提升推理速度
功能扩展
- 多类别扩展:增加更多动物类别,修改类别定义和模型输出层
- 细粒度识别:针对同一物种的不同品种(如不同种类的狗)进行细分识别
- 移动端部署:使用 PyTorch Mobile 将模型部署到 iOS/Android 设备
工程优化
- 生产环境部署:使用 Gunicorn+Nginx 组合部署 Flask 服务,提升并发处理能力
- 日志系统:添加完整的日志记录,便于监控系统运行状态
- 缓存机制:对重复识别的图像结果进行缓存,减少模型推理次数
总结
本动物识别系统通过深度学习技术实现了从图像到动物类别的智能映射,完整涵盖了从数据预处理、模型训练、服务部署到前端交互的全流程。系统采用迁移学习策略,基于 EfficientNet-B3 模型实现了高效的特征提取,通过前后端分离架构提供了良好的可扩展性和用户体验。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)