
LLM 推理能力是怎么炼成的?一文读懂「强化学习驱动的大模型推理」完整路线图(RL for LRM 全面综述)
这篇综述系统性梳理了强化学习(RL)在大型推理模型(LRM)领域的最新进展。研究表明,相比监督微调(SFT),RLVR(可验证奖励的强化学习)通过提供客观、可验证的奖励信号,能更有效提升模型的泛化推理能力。综述指出RLVR的三大关键要素:可验证奖励机制、无Critic优化算法和动态采样策略,并探讨了当前关于RL是否创造新知识的核心争议。最后提出了包括持续强化学习、基于模型的RL等九大未来研究方向,
LLM 推理能力是怎么炼成的?一文读懂「强化学习驱动的大模型推理」完整路线图(RL for LRM 全面综述)
在近日发布于 arXiv 的一篇长达120页、引用超600篇文献的重磅综述中,来自清华大学与上海人工智能实验室的研究者们,为大模型推理能力的进化指明了一条关键路径:
“SFT(监督微调)只会‘记忆’,而RL(强化学习)才能让模型真正学会‘泛化’。”
这篇综述系统性地梳理了强化学习(RL)在大型推理模型(LRMs)领域的最新进展,并点出了当前最核心的几个争议与未来方向。
为什么LLM需要RL?
在过去,提到RL在大模型中的应用,大家首先想到的是 RLHF(人类反馈强化学习) 或 DPO(直接偏好优化)。
然而,这篇综述指出,这些技术的核心目标是“对齐”(Alignment)——即让模型变得有帮助(Helpfulness)、诚实(Honesty)和无害(Harmlessness)。
但一个新的趋势正在兴起:使用RL来“激励推理本身”。
这正是将普通 LLM(大语言模型)转变为 LRM(大推理模型) 的关键。
这种新技术被称为 RLVR(Reinforcement Learning with Verifiable Rewards),即可验证奖励的强化学习。它不再依赖模糊的人类偏好,而是使用“答案正确性”或“单元测试通过率”等可验证的信号来训练模型。
这一范式的代表作,正是 OpenAI o1 和 DeepSeek-R1。
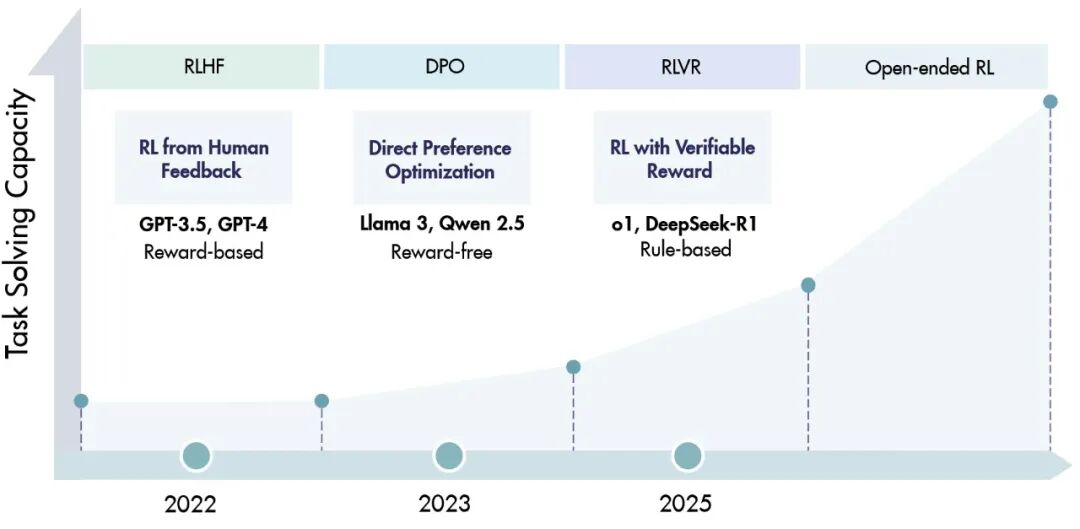
图1:不同的RL方法时间线
LRM的推理能力是怎么“炼”成的?
SFT 只是“预热”,RLVR 才是真正的“淬火”。综述拆解了炼成LRM推理能力的“三驾马车”:
**1.****核心燃料:可验证的奖励这是 RLVR 的基石。**研究者不再需要昂贵且主观的人类标注,而是使用“规则”来自动评判 。
数学题: 最终答案是否等于 \boxed{…} 里的标准答案?
代码题: 生成的代码能否通过单元测试?这种方式提供了可扩展、可靠且客观的训练信号,让模型可以大规模地“试错”和“自我修正” 。
**2.**核心引擎:无Critic的优化 (Critic-Free Optimization) 传统的 PPO 算法需要一个“Critic”模型(即奖励模型)来打分 。但在 LRM 训练中,这不仅计算开销巨大 ,还容易被模型“钻空子”(Reward Hacking)。
因此,前沿工作(如 DeepSeek-R1)转向了“无Critic”算法,其中的明星是 GRPO(群体相对策略优化)。 GRPO 的逻辑很巧妙:它不再需要一个裁判来给“绝对分数”,而是让模型针对一个问题生成“一组”答案,然后“在组内比较” 。能通过验证的答案就是好答案,其奖励自然高于那些失败的答案 。这种“相对奖励”极大地简化了训练,并提升了稳定性 。
3.**核心策略:动态采样 (Dynamic Sampling) 在训练中,如果总是给模型太简单或太难的题,效率会很低。研究者发现,必须使用动态采样策略** 。 通过在线评估问题的成功率,系统可以“过滤”掉那些 100% 答对(太简单)或 0% 答对(太难)的问题*,集中算力让模型去攻克那些“跳一跳才能够得着”的中等难度任务 ,从而实现最高效的梯度更新。
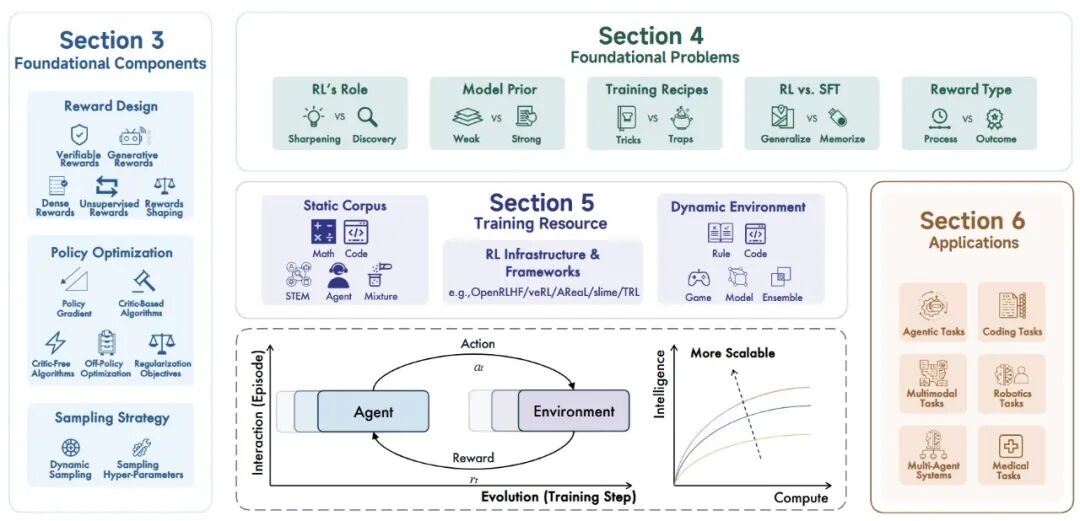
图2:综述概览
核心思辨(一):SFT vs RL——记忆还是泛化?
大模型训练最常见的路径是 SFT 和 RL。一个经典的问题是:我们为什么需要RL的复杂性,而不是只用SFT?
这篇综述给出了一个尖锐的答案:SFT 倾向于记忆,而 RL 才能泛化 。
许多研究(包括这篇综述所引用的)发现:
SFT-on-math(在数学数据上SFT):会导致模型在非数学任务上的性能显著下降,出现“灾难性遗忘”。
RL-on-math(在数学数据上RL):不仅能提升数学能力,还能保持甚至增强在其他任务(如指令遵循)上的性能。
研究者认为,这是因为SFT 倾向于“过度拟合表面模式”,而 RL 鼓励模型探索,从而培养了“可迁移的模式”。
核心思辨(二):RL在“锐化”还是“发现”?
RL 究竟是让模型“学会了新东西”,还是仅仅“把已经会的东西磨得更亮”?这是目前学界争论的焦点。
1️⃣ **RL 并没有创造真正的新知识,只是在“精炼和重新加权”**模型在预训练中已经学到的能力。
证据1: 有研究(Limit-of-RLVR)发现,RL 能显著提高 Pass@1(模型第一次就答对),但在 Pass@K(撒网式采样更多答案)上表现不佳。这说明 RL 只是在“收窄搜索空间”,而不是在“发现新解法”。
证据2: 即便给 Qwen 这类模型输入“虚假”或“随机”的奖励信号,它们在某些指标上依然能获得提升。这暗示 RL 只是在激发模型预训练时就有的潜在特征。
2️⃣ 另一派则坚信,RL 能够“揭示预训练中未获得的新模式”。
证据1: 有研究(ProRL)反驳了 Pass@K 的结论,指出只要给予“足够长时间且稳定”的 RL 训练,模型在 Pass@1 和 Pass@K 上都能实现提升。
证据2: 论文指出,LLM 可以通过 RL 学会“组合”现有的能力来解决新问题。这超越了简单的能力“锐化”,属于涌现出了新行为。
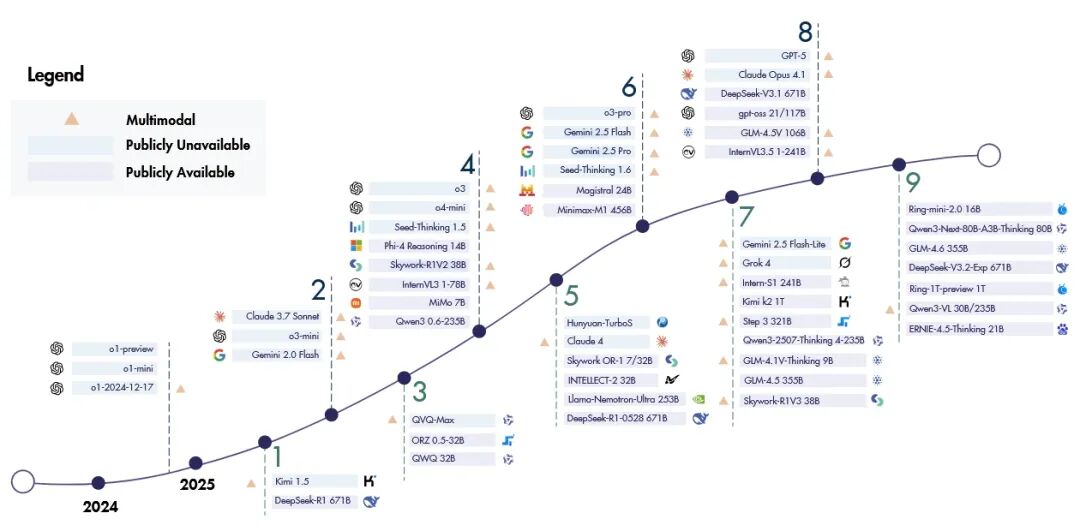
图3:一些使用RL进行训练的代表性模型时间线
未来的九大研究方向
这篇综述在最后(第7节)高瞻远瞩地指出了未来最值得探索的几个方向:
用于LLM的持续强化学习 (Continual RL for LLMs)
目标: 如何让模型在动态变化的环境中持续学习新知识,同时不遗忘旧能力(即克服“灾难性遗忘”)?这是实现终身学习的关键。
基于模型的RL (Model-based RL)
目标: 不再依赖真实环境,而是让 LLM 自己构建“世界模型”(World Models) 。模型在自己“想象”出的世界中训练,并自己生成奖励信号。
教会LLM在“潜空间”中推理 (Latent Space Reasoning)
目标: 目前的思维链(CoT)是在离散的“文本Token”上进行的。未来是否可以转向在模型内部的**“连续潜空间”**中进行推理?这种推理可能更流畅、更高效,也更适合RL优化。
将RL用于预训练 (RL for LLMs Pre-training)
目标: 一个激进的想法——为什么RL只能在“后训练”(Post-training)阶段使用?论文提出,可以在预训练阶段就引入RL,例如将“下一个词预测”任务重构成一个RL问题。
用于扩散模型LLM的RL (RL for Diffusion-based LLMs)
目标: 扩散模型(DLLMs)在生成上具有非自回归、可修正等优势,但将其与RL结合还很困难。如何为扩散过程中的每一步“去噪”设计奖励,是一个开放性问题。
此外,还包括基于记忆的RL(Memory-based RL)、教会LRM高效推理(Efficient Reasoning)、RL用于科学发现(Scientific Discovery),以及架构-算法协同设计(Architecture-Algorithm Co-Design) 等。
“与 RLHF 或 DPO 等主要为人类对齐而设计的方法不同,RLVR(可验证奖励的强化学习)通过提供直接的、可验证的结果级奖励,极大地增强了 LLM 的推理能力,并有效地将 LLM 转变为 LRM(大型推理模型)。**”
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**
更多推荐


 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)