
Occ-LLM:利用基于占用的大语言模型增强自动驾驶
25年2月来自香港科技大学广州分校的论文“Occ-LLM: Enhancing Autonomous Driving with Occupancy-Based Large Language Models”。大语言模型 (LLM) 在机器人和自动驾驶领域取得重大进步。本研究提出一个基于占用的大型语言模型 (Occ-LLM),它代表将 LLM 与重要表示相结合的开创性努力。为了有效地将占用编码为 LL
25年2月来自香港科技大学广州分校的论文“Occ-LLM: Enhancing Autonomous Driving with Occupancy-Based Large Language Models”。
大语言模型 (LLM) 在机器人和自动驾驶领域取得重大进步。本研究提出一个基于占用的大型语言模型 (Occ-LLM),它代表将 LLM 与重要表示相结合的开创性努力。为了有效地将占用编码为 LLM 的输入并解决与占用相关的类别不平衡问题,其提出运动分离-变分自动编码器 (MS-VAE)。这种方法利用先验知识将动态物体与静态场景区分开来,然后将它们输入到定制的变分自动编码器 (VAE) 中。这种分离增强模型集中于动态轨迹的能力,同时有效地重建静态场景。Occ-LLM 的有效性已经在关键任务中得到验证,包括 4D 占用预测、自规划和基于占用的场景问答。综合评估表明,Occ-LLM 显著超越现有方法,在 4D 占用率预测任务中,交并比 (IoU) 提高约 6%,平均交并比 (mIoU) 提高 4%。
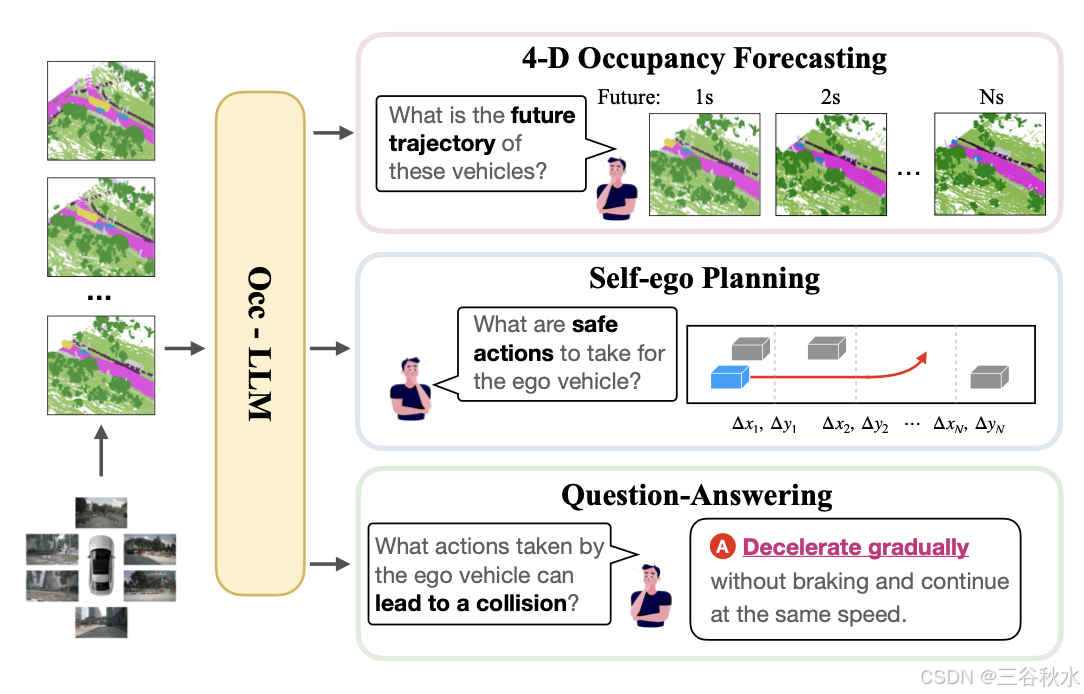
Occ-LLM 如图所示:
大语言模型 (LLM) 发展迅速[1]、[47]、[42]、[53],成为推动各个行业人工智能发展不可或缺的一部分[32]、[33]、[21]、[13]。LLM 最初是为自然语言处理而设计的,由于其强大的泛化能力,在自动驾驶等复杂领域表现出了显著的适应性[5]、[16]、[10]、[39]。这些能力对于机器人或自动驾驶系统尤其重要,因为它们目前缺乏泛化能力[6]、[9]。目前,自动驾驶中的 LLM 应用主要使用基于图像的输入[22],缺乏全面环境理解所需的空间感知。现有的基于视觉的 [39][16] 和基于激光雷达的 [41][38] 方法虽然可以增强车辆导航和环境理解,但计算量大,并且中间推理过程往往缺乏透明度。占用是自动驾驶中一种极具表现力的模式 [29],通过全面呈现场景的前景和背景,提供丰富的空间和语义洞察。这种通用表示有助于感知目标,无论其具体类别如何,无论是已知还是未知。值得注意的是,领先的汽车制造商(如特斯拉 [43])正在逐步在其车辆中采用基于占用的系统,说明人们正在转向这种强大的环境解释方法。
3D 语义占用通过明确建模 3D 网格内每个体素的占用状态,提供更详细的环境表示。SSCNet [40] 首次引入语义场景完成任务,整合几何和语义信息。后续工作通常使用具有明确深度信息的几何输入 [35]、[23]、[51]、[7]。MonoScene [4] 提出第一个用于语义场景完成的单目方法,使用 3D UNet [36] 来处理通过视线投影生成的体素特征。已经设计基于传输架构的各种网络 [20]、[20]、[54]。此外,一些同时进行的工作专注于提出用于 3D 语义占用预测的周围视图基准,促进占用社区的快速发展 [49]、[49]、[50]、[45]、[44]。 OccWorld 学习基于 3D 占用的世界模型,该模型以其可解释性和效率而备受关注。
本文提出的 Occ-LLM 框架,将大语言模型 (LLM) 与占用表示相结合,以改进自动驾驶系统(如图所示)。该框架增强空间和语义理解,有助于场景解释和决策。
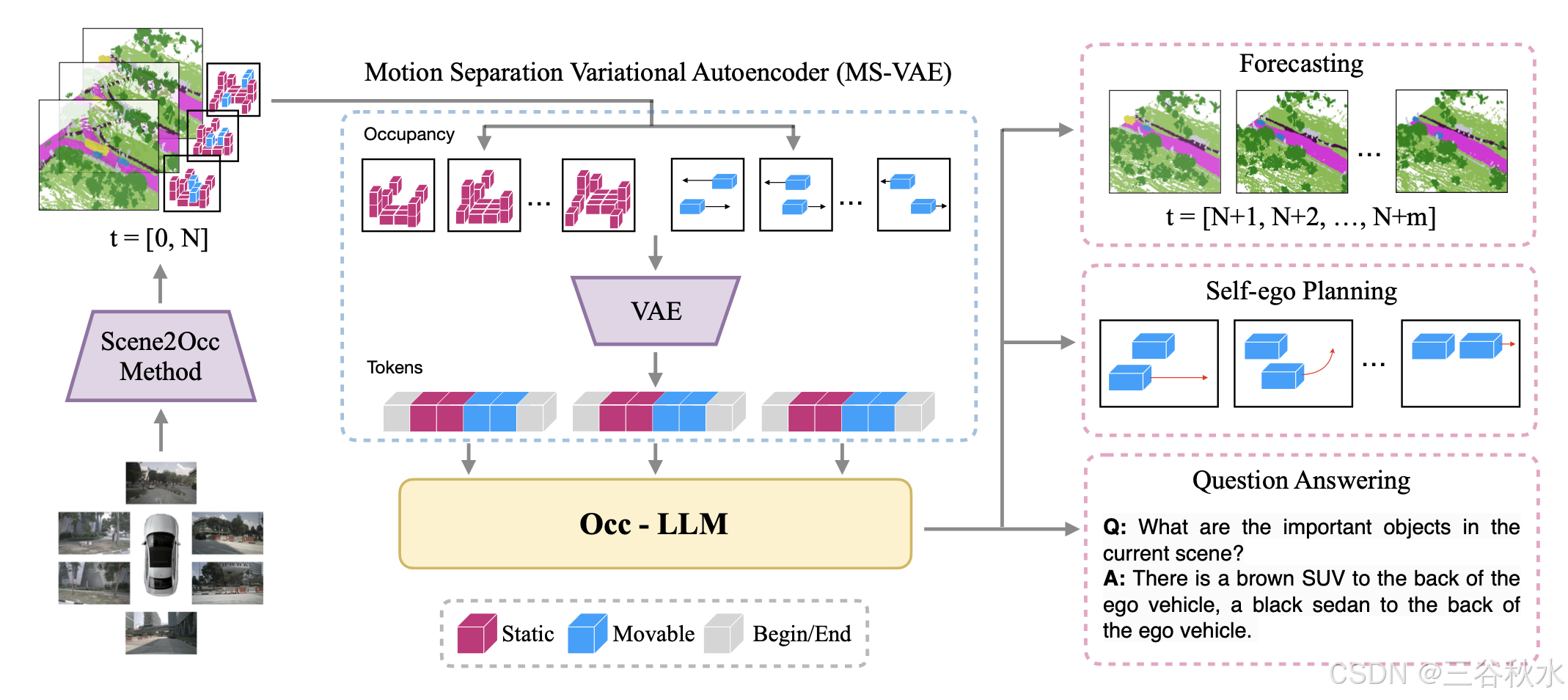
总的来说,Occ-LLM 首先利用现有的占用预测算法将多视角摄像机的结果转换为占用表示。随后,采用运动分离策略来区分与移动目标相关的体素和静态元素。然后使用定制的 VAE 将这些区分的体素独立编码为潜表示。最后,在集成到 LLM 中之前,处理这些潜表征,完成下游应用的准备步骤。
运动分离-变分自动编码器
基于已建立的多模态 LLM 集成方法 [27]、[16]、[37],本文旨在训练变分自动编码器 (VAE),以促进模态融合并降低计算成本。由于占用类别不平衡和空气体素占主导地位,将占用表示直接集成到 LLM 中将面临挑战,导致数据表示稀疏且效率低下。
为了克服这个问题,提出运动分离-变分自动编码器 (MS-VAE),它将占用网格内的动态和静态组件分开。这提高了编码效率,并将焦点转移到自主导航所必需的动态元素上。因此,MS-VAE 能够更平衡、更有效地集成到 LLM 框架中。
运动分离变分自动编码器 (MS-VAE) 的核心概念,涉及训练两个不同的 VQ-VAE 来分别对移动和静态占用体素进行编码和解码。然而,维护单个编码器和解码器,同时对移动和静态体素使用两个不同的码本也可以产生令人满意的结果。
让 x 表示输入占用表示,x_m 和 x_s 分别表示移动和静态体素。编码器 q_φ (z|x) 将输入 x 映射到潜空间 z。对于 MS-VAE,为移动和静态体素定义两个单独的潜变量 z_m 和 z_s。每个编码的潜变量 z_m 和 z_s 在相应的码本 C_m 和 C_s 中搜索,并在输入到解码器之前由最相似的码本条目替换。解码器 p_θ(x|z) 从量化潜变量 z′_m 和 z′_s 重构输入。
为了便于分离占用表示中的运动和静态元素,应用基于体素分类的变换。令 M 表示移动类的集合。在修改的占用表示中,定义运动和空气-填充的指示函数。空气表示静态占用网格中的空气表征,通常编码为代表未占用空间的一个占位符(零)值。为了重构原始占用表示,用一个 mask = (xˆ_m ̸= 0) 来区分活跃的运动区域,这样重构的占用 xˆ 结合静态和运动分量。用于训练 MS-VAE 的整体损失函数结合重构损失和承诺损失,以确保编码的潜变量接近码本的条目。
通过利用运动和静态体素的单独码本,同时保持统一的编码器和解码器,并适当处理占用的表示,这样 MS-VAE 有效地捕捉每种体素类型的不同特征,从而改善占用重构和泛化。
此外,整体 VAE 架构参考 OccWorld 实现 [55] 的方法,具体将占用视为具有 16 个通道的 2D 数据,并使用 2D VAE 进行编码和解码。然而,为了保持三维信息的完整性,在编码器之前和解码器之后都集成一层轻量级 3D 卷积。这种修改尊重占用表示固有的空间维度,并大大提高重建的占用质量。与传统的 2D VAE 用法相比,这种方法显著提高三维空间中占用表示的保真度。
使用 LLM 集成占用的预处理
patch 化。在使用 MS-VAE 对原始占用表示进行编码后,得到的潜表示仍然很重要。为了解决这个问题,采用类似于 Vision Transformer (ViT) [12] 的方法,将占用潜空间划分为小网格并将其展平。patch 大小显着影响占用重建的质量。这是因为预测未来的占用帧,涉及感知和低级视觉任务的各个方面。例如,感知任务通常受益于更大的patch 大小,从而有助于更好地理解输入数据的语义信息 [12]。相反,低级视觉任务通常采用较小的 patch 大小来实现更高质量的数据重建 [2]。(注:实验中得到,补丁大小为 10 可产生最佳结果)
帧分离。每帧的平坦占用潜变量相对较长,直接连接多帧的平坦占用潜变量,会导致生成的占用出现位置漂移。这种漂移表现为来自一帧的占用部分出现在后续帧中,从而导致级联错位(如图所示)。
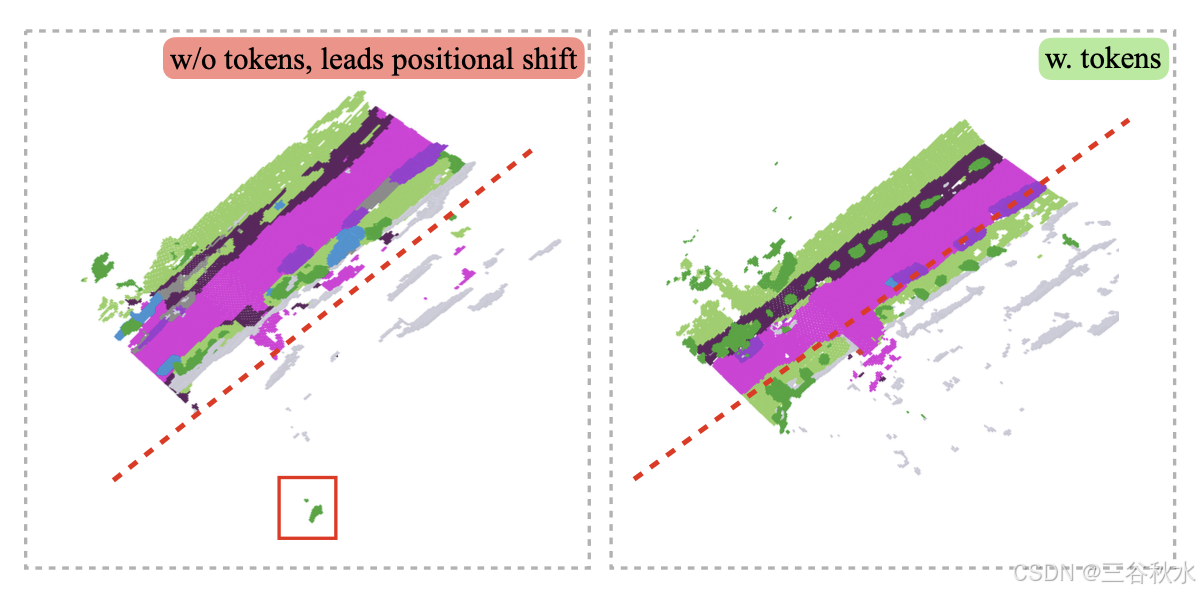
为了解决这个问题,提出一个简单但有效的解决方案:在每个占用潜变量帧的开头和结尾,添加特定的文本token。具体来说,在开头使用“”,在结尾使用“”。这些tokens在推理过程中划定帧之间的间隔,有效地消除漂移问题。
预融合。引入一种预融合方法来更好地建立占用表示和自车行为之间的联系。该方法首先涉及通过多个 MLP 层对自车行为进行编码。与 SE-Net [17] 的方法类似,用编码的动作隐变量作为权重来调节占用情况。该技术增强占用表示与自车动作之间的一致性,从而提高整体模型性能。
下游任务
Occ-LLM 框架支持各种对增强自动驾驶系统至关重要的下游任务,包括 4D 占用预测、自我规划和基于占用的场景问答。任务切换通过特定提示进行管理:“<4-D 占用预测和自车规划>”启动 4D 占用预测和自我规划的组合任务,而“<问答>”触发问答任务。这些任务共同增强态势-觉察和决策能力。4-D 占用预测可预测环境动态,这对于预测危险至关重要。自车规划使用这些预测进行安全、高效的导航。基于占用的场景问答可解释复杂情况,有助于做出明智的决策。这些功能共同显著提高自动驾驶系统的安全性、可靠性和效率。
更多推荐
 21
21 0
0- 0



 已为社区贡献122条内容
已为社区贡献122条内容

所有评论(0)