
【AI论文】序列标注任务广义化研究(SFT广义化):基于奖励修正的强化学习视角
本研究针对大语言模型监督微调(SFT)泛化能力不足的问题,提出动态微调(DFT)方法。通过理论分析发现标准SFT梯度存在隐式奖励结构问题,DFT通过动态调整词元损失函数解决了这一缺陷。实验表明,在多个数学推理基准测试中,DFT显著优于标准SFT,平均准确率最高提升15.66点,且在离线强化学习场景中也表现优异。研究还发现DFT能更快收敛、对超参数更鲁棒,并导致词元概率呈现双峰分布。虽然目前评估限于
摘要:我们针对大语言模型(Large Language Model,LLM)的监督微调(Supervised Fine-Tuning,SFT)提出了一种简单但具有理论依据的改进方法,以解决其与强化学习(Reinforcement Learning,RL)相比泛化能力有限的问题。通过数学分析,我们发现标准的SFT梯度隐式地编码了一种有问题的奖励结构,这种结构可能会严重限制模型的泛化能力。为了解决这一问题,我们提出了动态微调(Dynamic Fine-Tuning,DFT)方法,该方法通过根据每个词元的出现概率对目标函数进行动态缩放,来稳定每个词元的梯度更新。值得注意的是,仅对代码进行这一处简单修改,就在多个具有挑战性的基准测试和基础模型上显著优于标准SFT,展现出大幅提高的泛化能力。此外,我们的方法在离线强化学习场景中也表现出具有竞争力的结果,提供了一种有效且更简单的替代方案。本研究将理论见解与实际解决方案相结合,显著提升了SFT的性能。代码将在https://github.com/yongliang-wu/DFT上公开。Huggingface链接:Paper page,论文链接:2508.05629
一、研究背景和目的
研究背景
在自然语言处理领域,大语言模型(LLM)的发展日新月异,监督微调(Supervised Fine-Tuning,SFT)作为一种常用的后训练方法,被广泛应用于模型对新任务的适应和现有能力的增强。SFT通过在专家演示数据集上训练模型,使其能够快速模仿专家行为,具有实现简单、获取专家模式速度快的优点。然而,与强化学习(RL)方法相比,SFT的泛化能力存在明显局限。RL方法利用显式的奖励或验证信号,允许模型探索多样化的策略,从而实现更强的泛化能力。但在实际应用中,RL方法往往需要大量的计算资源,对超参数敏感,并且依赖于奖励信号的可用性,这些条件并不总是能够满足。
尽管已有多种混合方法被开发出来,结合了SFT和RL的优势,但在没有负样本、奖励模型或验证信号的数据集中,SFT仍然是唯一可行的选择。因此,如何从根本上改进SFT本身,提高其泛化能力,成为了一个亟待解决的问题。
研究目的
本研究旨在通过理论分析和数学推导,揭示SFT梯度隐式编码的问题奖励结构,进而提出一种简单而有效的改进方法——动态微调(DFT)。DFT的目标是通过动态调整每个词元的损失函数,稳定梯度更新,从而提高SFT的泛化能力。本研究期望通过这一改进,使SFT在保持其原有优势的同时,能够更接近或达到RL方法的泛化性能,为LLM的后训练提供一种更高效、更稳定的解决方案。
二、研究方法
理论分析与数学推导
本研究首先通过理论分析,揭示了SFT梯度与RL政策梯度之间的数学联系。研究指出,标准的SFT梯度可以看作是一种特殊形式的政策梯度,其隐式定义的奖励结构存在问题,具体表现为奖励极其稀疏且与模型分配给专家动作的概率成反比。这种奖励结构导致当模型为专家动作分配低概率时,梯度会出现无界方差,从而产生不稳定的优化景观。
基于上述分析,研究提出了DFT方法,其核心思想是通过动态调整每个词元的损失函数,消除隐式奖励结构中的逆概率加权问题。具体来说,DFT通过将标准SFT目标函数与词元概率相乘(脱钩以避免梯度流动),实现了对每个词元损失的动态缩放。
实验设计与实施
为了验证DFT方法的有效性,研究在多个具有挑战性的数学推理基准测试和不同规模的基础模型上进行了广泛的实验。实验设置包括:
- 数据集:使用NuminaMath CoT数据集,包含约860,000个数学问题及其解决方案。为了高效管理计算资源,研究随机抽取了100,000个实例进行训练。
- 模型:实验涉及多个最先进的模型,包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、LLaMA-3.2-3B、LLaMA-3.1-8B和DeepSeekMath-7B-Base。
- 训练细节:基于verl框架实现,使用推荐的SFT超参数。具体来说,采用AdamW优化器,学习率设置为5×10-5(LLaMA-3.1-8B模型为2×10-5),迷你批次大小为256,最大输入长度为2048个词元。学习率遵循余弦衰减计划,预热比率为0.1。
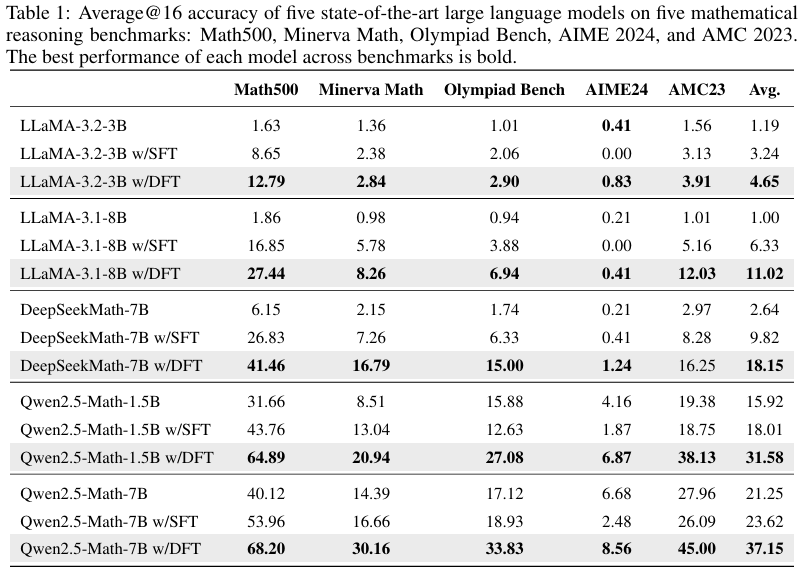
- 评估设置:在数学推理任务上,研究在Math500、Minerva Math、Olympiad Bench、AIME2024和AMC2023等基准测试上进行了评估。每个模型使用默认的聊天模板和思维链(CoT)提示来激发逐步推理。所有报告的结果均为在温度为1.0和最大生成长度为4096个词元下,进行16次解码运行的平均准确率。
对比方法
为了全面评估DFT方法的性能,研究还实现了以下对比方法:
- 标准SFT:作为基线方法,用于比较DFT的改进效果。
- 重要性加权SFT(iw-SFT):作为一种同时利用SFT和RL优势的混合方法,用于与DFT进行对比。
- 离线RL方法:包括DPO和RFT/RAFT,用于在离线RL设置下评估DFT的性能。
- 在线RL方法:包括PPO和GRPO,用于在在线RL设置下与DFT进行比较。
三、研究结果
主要发现
- DFT显著优于标准SFT:在所有评估的LLM上,DFT的平均性能提升均显著超过标准SFT。例如,在Qwen2.5-Math-1.5B模型上,DFT的平均准确率提升了+15.66点,是SFT提升(+2.09点)的5.9倍以上。
- DFT在具有挑战性的基准测试上表现尤为突出:在Olympiad Bench、AIME2024和AMC2023等具有挑战性的基准测试上,标准SFT往往出现性能下降,而DFT则能够持续提供显著的性能提升。例如,在Olympiad Bench上,SFT使Qwen2.5-Math-1.5B的准确率从15.88降至12.63,而DFT则将其提升至27.08。
- DFT在离线RL设置下表现优异:在利用拒绝采样生成的奖励信号的离线RL设置下,DFT的表现超过了所有离线RL基线方法,甚至超过了最强的在线RL算法GRPO。例如,在Qwen2.5-Math-1.5B模型上,DFT的平均得分达到了35.43,超过了GRPO的32.00。
- DFT的收敛速度更快:与标准SFT相比,DFT在大多数基准测试上表现出更快的收敛速度。通常在120个训练步骤内就能达到峰值性能,而SFT则需要更多的训练步骤。
深入分析
- 词元概率分布变化:研究通过分析模型在训练集上的词元概率分布变化,发现DFT与标准SFT在优化过程中对词元概率的调整方式存在显著差异。标准SFT倾向于均匀增加所有词元的概率,而DFT则显著提升了部分词元的概率,同时主动抑制了其他词元的概率,导致词元概率分布呈现双峰分布。
- 超参数敏感性分析:研究通过消融实验评估了DFT对关键训练超参数的敏感性,发现DFT在不同学习率和批次大小下均能保持稳定的性能提升,表明DFT对超参数的选择具有较强的鲁棒性。
四、研究局限
尽管本研究在提高SFT泛化能力方面取得了显著成果,但仍存在以下局限:
- 评估范围有限:目前的研究仅在数学推理基准测试和最多70亿参数的模型上进行了评估,未在其他任务领域(如代码生成、常识问答)和更大规模的LLM(如130亿+参数)上进行验证。
- 文本场景限制:当前研究仅限于文本场景,未在视觉语言任务上验证DFT的有效性。
- 理论分析的简化假设:在理论分析中,研究对SFT梯度与RL政策梯度之间的联系进行了一定的简化假设,这些假设在实际应用中可能不完全成立。
五、未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
- 扩展评估范围:将DFT方法应用于更广泛的任务领域和更大规模的LLM上,以验证其普适性和有效性。特别是在代码生成、常识问答等非数学推理任务上,评估DFT的泛化能力。
- 多模态场景验证:在视觉语言任务上验证DFT的有效性,探索其在多模态大语言模型后训练中的应用潜力。
- 深化理论分析:进一步放松理论分析中的简化假设,更精确地揭示SFT梯度与RL政策梯度之间的联系,为DFT方法的优化提供更坚实的理论基础。
- 结合其他先进技术:探索将DFT与其他先进技术(如元学习、迁移学习)相结合的可能性,以进一步提高LLM的后训练性能和泛化能力。
- 实际应用探索:将DFT方法应用于实际场景中,如智能客服、内容生成等,评估其在真实世界中的表现和价值。
更多推荐
 19
19 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)