
DeepSearch:通过蒙特卡罗树搜索克服可验证奖励强化学习的瓶颈
DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search
DeepSearch:通过蒙特卡罗树搜索克服可验证奖励强化学习的瓶颈
后文有个数学小例子解释这篇文章的数学公式和逻辑,MCTS和RLVR是如何工作的。
在人工智能领域,特别是大语言模型(LLM)的推理能力提升上,强化学习与可验证奖励(RLVR)已成为一种关键范式。它允许模型从可客观评估的奖励信号中学习复杂推理路径。然而,正如许多前沿研究所揭示的,这种方法在训练过程中往往遭遇“高原”现象:经过数千步优化后,性能提升趋于平缓,计算投入的边际回报急剧下降。这背后的根源在于训练时的探索不足——模型依赖有限的直接 rollout,往往遗漏关键推理路径,导致解决方案空间覆盖不全。
本文将介绍一篇最新预印本论文《DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search》(arXiv:2509.25454v2,2025年10月1日发布),由斯坦福大学、东京大学、RIKEN AIP 等机构的学者共同撰写。该论文提出了一种创新框架 DeepSearch,将蒙特卡罗树搜索(MCTS)直接嵌入 RLVR 训练循环中,实现从“深度扩展”向“广度探索”的范式转变。对于初学者,这是一个关于如何让 AI “更聪明地思考”的故事;对于专家,它则提供了对训练动态、探索策略和奖励传播的深度剖析。让我们一步步深入。
问题:RLVR 的探索瓶颈与训练-推理脱节
大语言模型在复杂推理任务(如数学证明)上取得了显著进步,这得益于测试时计算扩展策略,例如树搜索结合过程级评估(Li et al., 2023; Yao et al., 2023)。然而,这些方法通常仅将结构化搜索限于推理阶段,而训练过程仍局限于直接策略 rollout。这种分离导致两个核心问题:
- 稀疏探索模式:训练时模型仅生成有限路径,难以覆盖解决方案空间的多样性。结果是,模型虽能在推理时“临时”调用搜索,但无法从系统探索中习得内在模式。
- 性能高原:近期延长 RL 训练的研究(Liu et al., 2025a)显示,数千步后收益递减——额外计算仅带来微弱改进,凸显单纯“堆积训练步数”的局限。
论文的核心洞见在于:要突破瓶颈,必须将训练时的探索置于首位。通过 MCTS 的结构化搜索,模型不仅学习正确解,还从探索过程本身获得丰富监督信号。这不仅是工程优化,更是范式革新:从“结果导向”转向“路径导向”学习。
DeepSearch 框架:MCTS 与 RLVR 的深度融合
DeepSearch 的设计围绕一个修改版 MCTS 展开,针对问题 xxx 和策略模型 πθ\pi_\thetaπθ 构建搜索树。根节点表示问题 xxx,子节点对应中间推理步骤 sss,一条从根到叶的路径形成轨迹 t=x⊕s1⊕s2⊕⋯⊕sendt = x \oplus s_1 \oplus s_2 \oplus \dots \oplus s_{\text{end}}t=x⊕s1⊕s2⊕⋯⊕send。不同于传统 MCTS 的根到叶遍历,DeepSearch 引入全局前沿选择,实现高效的树状扩展与回传。
框架迭代通过四个组件运行:扩展(Expansion)、选择(Selection)、分数备份(Score Backup)和自适应训练(Adaptive Training)。其整体流程如图 1 所示(论文第 3 页),强调从全局视角优先高潜力节点。
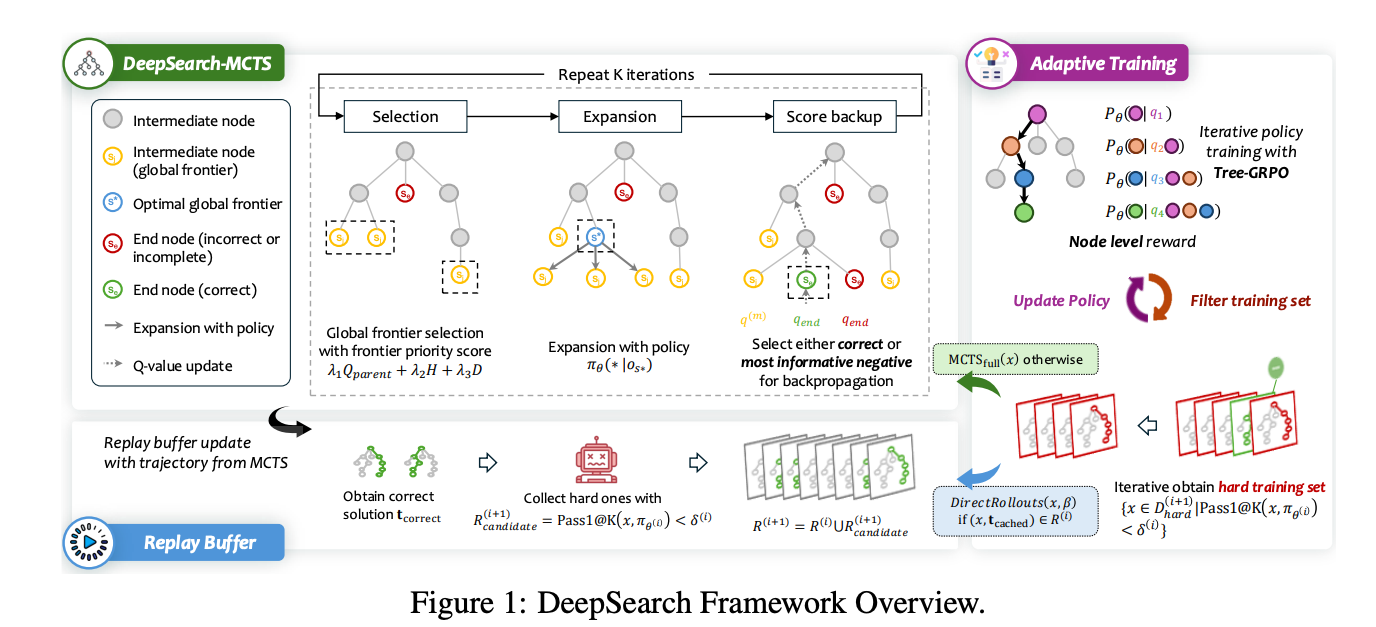
2.1 基于熵引导的扩展(Expansion with Entropy-Based Guidance)
在第 iii 步,收集当前观察oi=x⊕s1⊕⋯⊕si−1o_i = x \oplus s_1 \oplus \dots \oplus s_{i-1}oi=x⊕s1⊕⋯⊕si−1,用 πθ(si∣oi)\pi_\theta(s_i | o_i)πθ(si∣oi) 生成 nnn 个候选下一步 {si,j}j=1n\{s_{i,j}\}_{j=1}^n{si,j}j=1n。重复扩展直至终端节点 send∈Sends_{\text{end}} \in S_{\text{end}}send∈Send(到达最终答案或最大深度 dTd_TdT)。
新生成终端节点集 Send(k)S_{\text{end}}^{(k)}Send(k) 通过验证函数 V:Send→{0,1}V: S_{\text{end}} \to \{0,1\}V:Send→{0,1} 分区:
Scorrect(k)={s∈Send(k)∣V(s)=1},Sincorrect(k)={s∈Send(k)∣V(s)=0}. S_{\text{correct}}^{(k)} = \{s \in S_{\text{end}}^{(k)} \mid V(s) = 1\}, \quad S_{\text{incorrect}}^{(k)} = \{s \in S_{\text{end}}^{(k)} \mid V(s) = 0\}. Scorrect(k)={s∈Send(k)∣V(s)=1},Sincorrect(k)={s∈Send(k)∣V(s)=0}.
若无正确解,则选最自信负例:
sneg∗=argmins∈Sincorrect(k)Hˉ(t(s)), s_{\text{neg}}^* = \arg\min_{s \in S_{\text{incorrect}}^{(k)}} \bar{H}(t(s)), sneg∗=args∈Sincorrect(k)minHˉ(t(s)),
其中平均轨迹熵 Hˉ(t(s))=1∣t(s)∣∑i=1∣t(s)∣H(πθ(si∣oi))\bar{H}(t(s)) = \frac{1}{|t(s)|} \sum_{i=1}^{|t(s)|} H(\pi_\theta(s_i | o_i))Hˉ(t(s))=∣t(s)∣1∑i=1∣t(s)∣H(πθ(si∣oi)),HHH 为香农熵的蒙特卡罗估计。这优先针对模型“自信错误”的路径,提供针对性监督。
2.2 启发式分数备份(Heuristic Score Backup)
选定轨迹 t∗t^*t∗(正确或负例)后,沿路径更新 q 值:
q(m)(si)=q(m−1)(si)+γ(i,l)⋅q(m)(send), q^{(m)}(s_i) = q^{(m-1)}(s_i) + \gamma(i,l) \cdot q^{(m)}(s_{\text{end}}), q(m)(si)=q(m−1)(si)+γ(i,l)⋅q(m)(send),
γ(i,l)=max(il,γmin)\gamma(i,l) = \max\left( \frac{i}{l}, \gamma_{\min} \right)γ(i,l)=max(li,γmin)(γmin=0.1\gamma_{\min}=0.1γmin=0.1)赋予终端附近节点更高权重。终端奖励 q(send)=+1q(s_{\text{end}}) = +1q(send)=+1(正确)或 −1-1−1(错误/不完整)。约束规则确保正确路径 q 值非负:
q(m)(si)={q(m−1)(si)+γ(i,l)⋅q(m)(send)if q(m−1)(si)⋅q(m)(send)≥0,γ(i,l)⋅q(m)(send)elif q(m)(send)>0,q(m−1)(si)elif q(m−1)(si)>0. q^{(m)}(s_i) = \begin{cases} q^{(m-1)}(s_i) + \gamma(i,l) \cdot q^{(m)}(s_{\text{end}}) & \text{if } q^{(m-1)}(s_i) \cdot q^{(m)}(s_{\text{end}}) \geq 0, \\ \gamma(i,l) \cdot q^{(m)}(s_{\text{end}}) & \text{elif } q^{(m)}(s_{\text{end}}) > 0, \\ q^{(m-1)}(s_i) & \text{elif } q^{(m-1)}(s_i) > 0. \end{cases} q(m)(si)=⎩
⎨
⎧q(m−1)(si)+γ(i,l)⋅q(m)(send)γ(i,l)⋅q(m)(send)q(m−1)(si)if q(m−1)(si)⋅q(m)(send)≥0,elif q(m)(send)>0,elif q(m−1)(si)>0.
这实现细粒度信用分配,避免负值污染正确中间步骤。
2.3 混合选择策略(Hybrid Selection Strategy)
结合局部 UCT(Upper Confidence Bounds for Trees)和全局前沿选择:
- 局部选择(兄弟比较):UCT(s)=Q(s)+λlnNparent(s)N(s)UCT(s) = Q(s) + \lambda \sqrt{\frac{\ln N_{\text{parent}}(s)}{N(s)}}UCT(s)=Q(s)+λN(s)lnNparent(s),平衡利用与探索。
- 全局前沿选择:前沿集 F={s∈T∣ξ(s)=0,s∉Send,d(s)<dT}F = \{s \in T \mid \xi(s)=0, s \notin S_{\text{end}}, d(s) < d_T\}F={s∈T∣ξ(s)=0,s∈/Send,d(s)<dT},优先分 F(s)=λ1tanh(Qparent(s))+λ2H(πθ(s∣o))+λ3D(d(s))F(s) = \lambda_1 \tanh(Q_{\text{parent}}(s)) + \lambda_2 H(\pi_\theta(s|o)) + \lambda_3 D(d(s))F(s)=λ1tanh(Qparent(s))+λ2H(πθ(s∣o))+λ3D(d(s))(D(d(s))=d(s)/dTD(d(s)) = \sqrt{d(s)/d_T}D(d(s))=d(s)/dT)。s∗=argmaxs∈FF(s)s^* = \arg\max_{s \in F} F(s)s∗=argmaxs∈FF(s)。
混合设计提升效率:局部确保子树最优,全局避免“局部最优陷阱”,并通过熵奖金引导不确定区域探索。
自适应训练:效率与遗忘防护
为避免全样本 MCTS 的计算开销,DeepSearch 引入迭代过滤与回放缓冲(Replay Buffer):
- 迭代过滤:初始硬集 Dhard(0)={x∈Dtrain∣Pass@1@K(x,πθ(0))<δ(0)}D_{\text{hard}}^{(0)} = \{x \in D_{\text{train}} \mid \text{Pass@1@K}(x, \pi_{\theta}^{(0)}) < \delta^{(0)}\}Dhard(0)={x∈Dtrain∣Pass@1@K(x,πθ(0))<δ(0)}(K=4,δ=0.25K=4, \delta=0.25K=4,δ=0.25)。迭代 Dhard(i+1)={x∈Dhard(i)∣Pass@1@K(x,πθ(i))<δ(i)}D_{\text{hard}}^{(i+1)} = \{x \in D_{\text{hard}}^{(i)} \mid \text{Pass@1@K}(x, \pi_{\theta}^{(i)}) < \delta^{(i)}\}Dhard(i+1)={x∈Dhard(i)∣Pass@1@K(x,πθ(i))<δ(i)},聚焦难题。
- 缓存解决方案:缓冲 R(i+1)=R(i)∪Rcandidates(i)R^{(i+1)} = R^{(i)} \cup R_{\text{candidates}}^{(i)}R(i+1)=R(i)∪Rcandidates(i),Rcandidates(i)={(x,tcorrect)∣… }R_{\text{candidates}}^{(i)} = \{(x, t_{\text{correct}}) \mid \dots \}Rcandidates(i)={(x,tcorrect)∣…}。 rollout 策略:若缓存可用,则 tcached∪DirectRollouts(x,β)t_{\text{cached}} \cup \text{DirectRollouts}(x, \beta)tcached∪DirectRollouts(x,β); 否则全 MCTS。
- Tree-GRPO 目标:q 值软裁剪 q(sj)=tanh(q(kmax)(sj)/ϵq)⋅qmaxq(s_j) = \tanh(q^{(k_{\max})}(s_j)/\epsilon_q) \cdot q_{\max}q(sj)=tanh(q(kmax)(sj)/ϵq)⋅qmax(ϵq=1,qmax=1\epsilon_q=1, q_{\max}=1ϵq=1,qmax=1)。目标:
J(θ)=ET∼T,ti∼T,(sj,oj)∼ti[1∣sj∣∑k=1∣sj∣min(ρj,k(θ)A^j,k,clip(ρj,k(θ),1−ϵ,1+ϵ)A^j,k)], J(\theta) = \mathbb{E}_{T \sim \mathcal{T}, t_i \sim T, (s_j, o_j) \sim t_i} \left[ \frac{1}{|s_j|} \sum_{k=1}^{|s_j|} \min \left( \rho_{j,k}(\theta) \hat{A}_{j,k}, \text{clip}(\rho_{j,k}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{j,k} \right) \right], J(θ)=ET∼T,ti∼T,(sj,oj)∼ti ∣sj∣1k=1∑∣sj∣min(ρj,k(θ)A^j,k,clip(ρj,k(θ),1−ϵ,1+ϵ)A^j,k) ,
A^j,k=q(sj)−μt\hat{A}_{j,k} = q(s_j) - \mu_tA^j,k=q(sj)−μt(序列级归一化)。这融合 q 值正则与策略优化,退化为 DAPO 时忽略树结构。
实验:SOTA 性能与效率跃升
基于 Nemotron-Research-Reasoning-Qwen-1.5B v2 和 DeepMath-103K 数据集,在 AIME24/25、AMC23、MATH 等基准上评估(Pass@1, n=32)。表 1 显示 DeepSearch-1.5B 平均准确率 62.95%,超越 Nemotron v2 的 61.70%(提升 1.25%),尤其在 AIME24(53.65% vs 51.77%)和 AMC(90.39% vs 88.83%)。
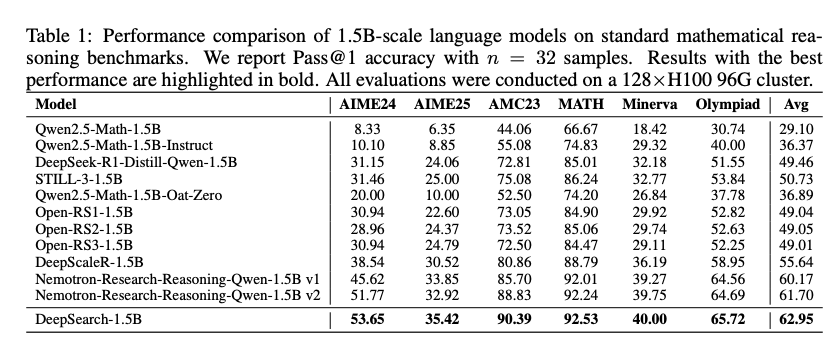
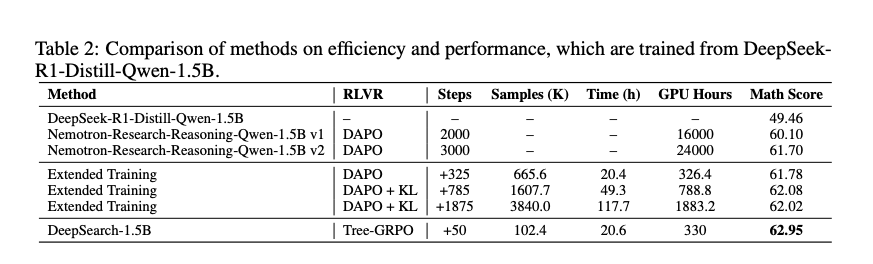
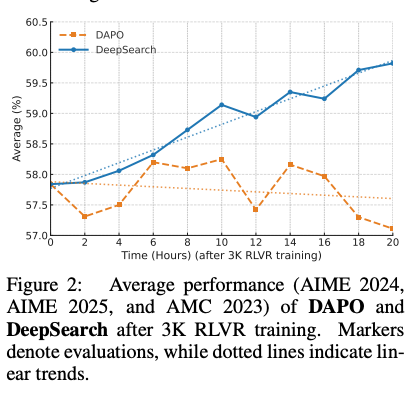
效率分析(表 2)更亮眼:延长训练 1875 步耗 1883.2 GPU 小时仅达 62.02%,而 DeepSearch 仅 50 步用 330 GPU 小时即超之(5.7× 效率)。图 2 展示训练动态:DAPO 线性缓慢,DeepSearch 高效陡峭,验证探索优于 brute-force。
结语:探索驱动的 RLVR 新范式
DeepSearch 不仅解决了 RLVR 的探索瓶颈,还开辟了将训练镜像推理的路径。它提醒我们:AI 推理的未来在于算法创新,而非单纯规模扩张。模型已在 Hugging Face 开放(https://huggingface.co/fangwu97/DeepSearch-1.5B),欢迎开发者探索。未来,可扩展至代码生成或多模态推理,值得持续关注。
DeepSearch 框架:MCTS 与 RLVR 的深度融合——以一个简单数学题为例
在上一篇文章中,我们概述了 DeepSearch 如何通过蒙特卡罗树搜索(MCTS)破解 RLVR(强化学习与可验证奖励)的探索瓶颈。今天,我们深入框架的核心:将 MCTS 直接嵌入 RLVR 训练循环,实现从“盲目试错”到“系统探索”的转变。对于初学者,这就像给 AI 一个“思维导图”,帮助它一步步规划推理路径;对于专家,它提供了全局前沿选择和细粒度 q 值传播的数学优雅设计。别担心,我们会用一个通俗的数学例子——“一个数加上它的一半等于 15,求这个数”——来模拟整个过程,让抽象概念落地。公式会简单解释,确保易懂。
框架回顾:为什么 MCTS 能“拯救” RLVR?
传统 RLVR 训练像扔飞镖:模型 πθ\pi_\thetaπθ 从问题 xxx 直接生成有限路径(rollout),用验证函数 VVV 检查正确性(V=1V=1V=1 表示对,V=0V=0V=0 表示错)。但路径太少,容易错过关键分支,导致训练后“高原”——多投几镖也难中靶心。
DeepSearch 的创新在于:用 MCTS 建一棵“推理树” TTT,根节点是问题 xxx,每个子节点 sss 是中间步骤(如“设这个数为 yyy”)。树路径 t=x⊕s1⊕⋯⊕sendt = x \oplus s_1 \oplus \dots \oplus s_{\text{end}}t=x⊕s1⊕⋯⊕send 形成完整轨迹。从树提取轨迹集 T={t1,…,tn}\mathcal{T} = \{t_1, \dots, t_n\}T={t1,…,tn},用于 RLVR 优化。不同于推理时才搜树,这里训练时就搜,确保模型学到“路径智慧”。
迭代包括:扩展(生成候选)、选择(挑最佳节点)、备份(传播奖励)和自适应训练。全局前沿选择取代传统根到叶遍历,避免浪费计算。接下来,用例子走一遍。
例子:解决“一个数加上它的一半等于 15”
假设问题 xxx:“一个数加上它的一半等于 15,求这个数。”(正确解:设 yyy 为数,则 y+y/2=15→1.5y=15→y=10y + y/2 = 15 \to 1.5y = 15 \to y=10y+y/2=15→1.5y=15→y=10。)模型 πθ\pi_\thetaπθ 是 1.5B 参数的推理 LLM,最大深度 dT=4d_T=4dT=4(限 4 步推理),每步生成 n=3n=3n=3 候选。验证 VVV 用简单求解器检查最终答案。
步骤 1: 扩展(Expansion with Entropy-Based Guidance)
从根 xxx 开始,第 1 步观察 o1=xo_1 = xo1=x,πθ\pi_\thetaπθ 生成 3 候选 s1,js_{1,j}s1,j:
- s1,1s_{1,1}s1,1: “设这个数为 yyy。”
- s1,2s_{1,2}s1,2: “这个数是 10。”
- s1,3s_{1,3}s1,3: “加一倍是 30。”(错分支)
重复扩展:对每个 s1,js_{1,j}s1,j 生成下一步,直到 d=4d=4d=4 或答案。假设第 1 迭代 k=1k=1k=1,生成终端集 Send(1)S_{\text{end}}^{(1)}Send(1) 有 6 个(树枝展):
- 正确:send,1s_{\text{end,1}}send,1 (“y=10y=10y=10”,V=1V=1V=1)。
- 错误/不完整:其余 5 个(如直接猜 20,V=0V=0V=0)。
分区:
Scorrect(1)={s∈Send(1)∣V(s)=1},Sincorrect(1)={s∈Send(1)∣V(s)=0}. S_{\text{correct}}^{(1)} = \{s \in S_{\text{end}}^{(1)} \mid V(s)=1\}, \quad S_{\text{incorrect}}^{(1)} = \{s \in S_{\text{end}}^{(1)} \mid V(s)=0\}. Scorrect(1)={s∈Send(1)∣V(s)=1},Sincorrect(1)={s∈Send(1)∣V(s)=0}.
这里 Scorrect(1)S_{\text{correct}}^{(1)}Scorrect(1) 非空,用正确轨迹;若空,则选低熵负例:
sneg∗=argmins∈Sincorrect(1)Hˉ(t(s)), s_{\text{neg}}^* = \arg\min_{s \in S_{\text{incorrect}}^{(1)}} \bar{H}(t(s)), sneg∗=args∈Sincorrect(1)minHˉ(t(s)),
Hˉ(t(s))=1∣t(s)∣∑iH(πθ(si∣oi))\bar{H}(t(s)) = \frac{1}{|t(s)|} \sum_i H(\pi_\theta(s_i | o_i))Hˉ(t(s))=∣t(s)∣1∑iH(πθ(si∣oi)) 是平均轨迹熵(HHH 测模型“犹豫度”,低熵=自信错)。解释:熵像“困惑指数”,选“模型最确定却错”的路径训它,避免纠结的模糊例。
步骤 2: 启发式分数备份(Heuristic Score Backup)
选 t∗t^*t∗(这里正确轨迹:t∗=x⊕t^* = x \oplust∗=x⊕ “设 yyy” ⊕\oplus⊕ “y+y/2=15y + y/2=15y+y/2=15” ⊕\oplus⊕ “1.5y=151.5y=151.5y=15” ⊕\oplus⊕ “y=10y=10y=10”)。沿 t∗t^*t∗ 更新 q 值(奖励信号)。
初始 q(0)(si)=0q^{(0)}(s_i)=0q(0)(si)=0。终端 q(send)=+1q(s_{\text{end}})=+1q(send)=+1(正确)。迭代 mmm 次更新:
q(m)(si)=q(m−1)(si)+γ(i,l)⋅q(m)(send), q^{(m)}(s_i) = q^{(m-1)}(s_i) + \gamma(i,l) \cdot q^{(m)}(s_{\text{end}}), q(m)(si)=q(m−1)(si)+γ(i,l)⋅q(m)(send),
时序衰减 γ(i,l)=max(il,0.1)\gamma(i,l) = \max\left( \frac{i}{l}, 0.1 \right)γ(i,l)=max(li,0.1)(iii 当前步,lll 终端步;近终端权重高)。例如,l=4l=4l=4,第 3 步 i=3i=3i=3,γ=max(3/4,0.1)=0.75\gamma= \max(3/4, 0.1)=0.75γ=max(3/4,0.1)=0.75。
约束版(保正确路径正 q):
q(m)(si)={q(m−1)(si)+γ(i,l)⋅q(m)(send)若符号一致,γ(i,l)⋅q(m)(send)若终端正,重置,q(m−1)(si)否则,保持正. q^{(m)}(s_i) = \begin{cases} q^{(m-1)}(s_i) + \gamma(i,l) \cdot q^{(m)}(s_{\text{end}}) & \text{若符号一致}, \\ \gamma(i,l) \cdot q^{(m)}(s_{\text{end}}) & \text{若终端正,重置}, \\ q^{(m-1)}(s_i) & \text{否则,保持正}. \end{cases} q(m)(si)=⎩
⎨
⎧q(m−1)(si)+γ(i,l)⋅q(m)(send)γ(i,l)⋅q(m)(send)q(m−1)(si)若符号一致,若终端正,重置,否则,保持正.
结果:q(send)=1q(s_{\text{end}})=1q(send)=1,q(s3)=0.75q(s_3)=0.75q(s3)=0.75,q(s2)=0.5q(s_2)=0.5q(s2)=0.5 等。解释:像“信用链”,终端成功“拉高”上游节点,但衰减防早期步过度乐观;约束避负污染,确保“设 yyy” 得正反馈。
步骤 3: 混合选择策略(Hybrid Selection Strategy)
备份后,选下一扩展节点。
-
局部选择(兄弟比):扩展 s1,1s_{1,1}s1,1 时,3 候选用 UCT:
UCT(s)=Q(s)+λlnNparent(s)N(s), UCT(s) = Q(s) + \lambda \sqrt{\frac{\ln N_{\text{parent}}(s)}{N(s)}}, UCT(s)=Q(s)+λN(s)lnNparent(s),
Q(s)=q(s)/N(s)Q(s)=q(s)/N(s)Q(s)=q(s)/N(s)(平均奖励),λ\lambdaλ 平衡利用(高 Q)和探索(低访 N)。选“设 yyy” 因 Q 高。 -
全局前沿选择:前沿 F={s∣F=\{s \midF={s∣ 无子、未完、d(s)<4}d(s)<4\}d(s)<4}。优先 F(s)=λ1tanh(Qparent(s))+λ2H(πθ(s∣o))+λ3d(s)/dTF(s)=\lambda_1 \tanh(Q_{\text{parent}}(s)) + \lambda_2 H(\pi_\theta(s|o)) + \lambda_3 \sqrt{d(s)/d_T}F(s)=λ1tanh(Qparent(s))+λ2H(πθ(s∣o))+λ3d(s)/dT(质量+不确定+深度奖金)。选 s∗=argmaxF(s)s^* = \arg\max F(s)s∗=argmaxF(s),如第 2 步“y+y/2y + y/2y+y/2”因父 Q 高、熵中(需探索)。
解释:局部如“家族投票”,全局如“全城竞选”——避陷一枝,广搜树。
重复 K=100 次迭代,建完整树。
步骤 4: 自适应训练(Adaptive Training with Replay Buffer)
树 T\mathcal{T}T 后,迭代过滤硬题集 Dhard(i+1)={x∈Dhard(i)∣Pass@1@K(x,πθ(i))<0.25}D_{\text{hard}}^{(i+1)} = \{x \in D_{\text{hard}}^{(i)} \mid \text{Pass@1@K}(x, \pi_\theta^{(i)})<0.25\}Dhard(i+1)={x∈Dhard(i)∣Pass@1@K(x,πθ(i))<0.25}(K=4,难题留)。缓存正确 tcorrectt_{\text{correct}}tcorrect 到缓冲 R,下轮若有,用 tcached∪t_{\text{cached}} \cuptcached∪ 少量 rollout;否则全 MCTS。
Tree-GRPO 优化:
先软裁剪 q(sj)=tanh(q(kmax)(sj)/1)⋅1q(s_j)=\tanh(q^{(k_{\max})}(s_j)/1) \cdot 1q(sj)=tanh(q(kmax)(sj)/1)⋅1(防爆炸,保梯度)。
目标:
J(θ)=E[1∣sj∣∑kmin(ρj,kA^j,k,clip(ρj,k,1−ϵlow,1+ϵhigh)A^j,k)], J(\theta) = \mathbb{E} \left[ \frac{1}{|s_j|} \sum_k \min \left( \rho_{j,k} \hat{A}_{j,k}, \text{clip}(\rho_{j,k}, 1-\epsilon_{\text{low}}, 1+\epsilon_{\text{high}}) \hat{A}_{j,k} \right) \right], J(θ)=E[∣sj∣1k∑min(ρj,kA^j,k,clip(ρj,k,1−ϵlow,1+ϵhigh)A^j,k)],
ρ=πθ/πold\rho=\pi_\theta / \pi_{\text{old}}ρ=πθ/πold(重要比,防漂移),A^j,k=q(sj)−μt\hat{A}_{j,k}=q(s_j)-\mu_tA^j,k=q(sj)−μt(优势,μt\mu_tμt 树均奖励,序列归一防长文)。解释:像“剪刀优化”,min\minmin 和 clip\text{clip}clip 稳更新,q 导路径学,训模型偏好高 A^\hat{A}A^ 步。
一轮后,πθ\pi_\thetaπθ 更懂“设变量”路径。多次迭代,准确升。
启示:从例子看框架威力
这个小题模拟了 DeepSearch 如何转“运气猜”为“结构搜”:扩展广生分支,选择精挑路径,备份准传奖励,训练智用缓存。实验中,它让 1.5B 模型在 MATH 等题上达 62.95%——非堆计算,而是聪明探索。
框架不止数学:可推代码调试或逻辑谜题。开源在 Hugging Face,试试建你的“推理树”!浅看,它教 AI“多想想再答”;深究,混合选择和 Tree-GRPO 是 RL 新范式。欢迎讨论你的例子。
后记
2025年10月4日于山东,在grok 4 fast辅助下完成。
更多推荐
 27
27 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)