
百万级经费,「CCF-智谱大模型基金」申报,即将截止
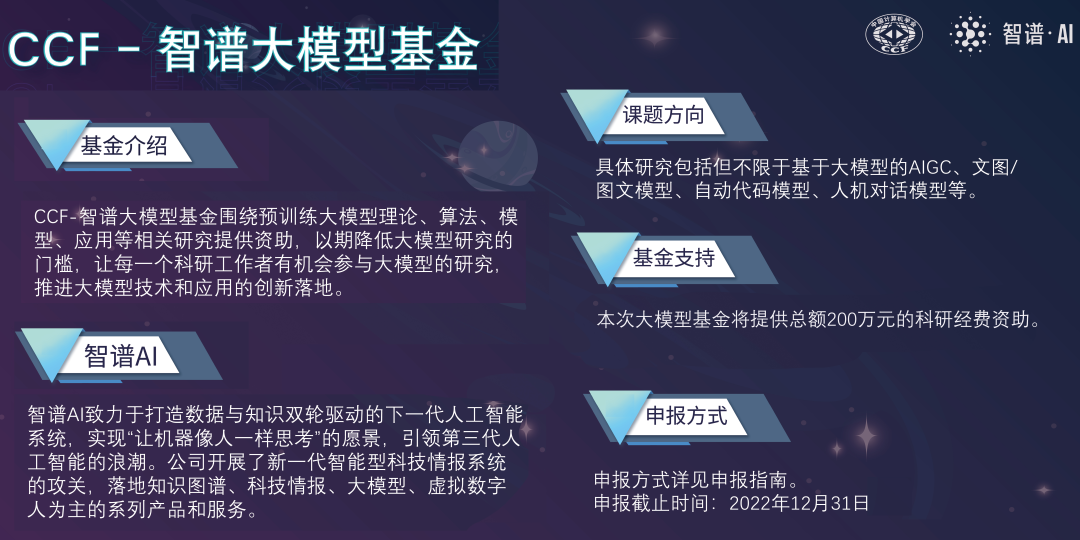
点击蓝字关注我们AI TIME欢迎每一位AI爱好者的加入!如今,大模型研究日新月异。然而,却并非所有师生都有足够的资金和算力,参与到大模型的相关研究当中。为解决这一问题,推进大模型技术和应用的创新落地,2022 年,智谱AI与 CCF 联合发起“CCF-智谱大模型基金”,围绕预训练大模型理论、算法、模型、应用等相关研究提供资助,以期降低大模型研究的门槛,让每一个计算机领域科研工作者均有机会参与大模
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
如今,大模型研究日新月异。然而,却并非所有师生都有足够的资金和算力,参与到大模型的相关研究当中。
为解决这一问题,推进大模型技术和应用的创新落地,2022 年,智谱AI与 CCF 联合发起“CCF-智谱大模型基金”,围绕预训练大模型理论、算法、模型、应用等相关研究提供资助,以期降低大模型研究的门槛,让每一个计算机领域科研工作者均有机会参与大模型的研究。
本基金具体研究内容包括但不限于基于大模型的AIGC、文图/图文模型、自动代码模型、人机对话模型等。将提供百万级科研经费资助,并根据申请项目的具体情况提供算力(来自并行科技赞助)支持。

✦
✦ ✦

申报主题如下
About Theme
各主题均不限于给定的建议研究方向,申请人可自行拓展决定)
更详细信息,可访问:
https://www.ccf.org.cn/Collaboration/Enterprise_Fund/News/zp/2022-10-12/775232.shtml
✦
✦

1. 预训练理论:
1.1 预训练模型鲁棒性(Robustness)和泛化性(Generalization)提升
预训练语言模型目前仍存在鲁棒性问题,在实际应用中,其鲁棒性造成了潜在的安全威胁。同时,预训练模型也需要提高在下游任务上的泛化能力。本课题旨在探索解决预训练模型鲁棒性和泛化性问题的技术。
建议研究方向:
1)模型鲁棒性的提升;
2)模型泛化性的提升。
1.2 预训练模型在分布外数据(out-of-distribution data)上的过度自信问题解决
预训练模型在分布外数据(out-of-distribution data)上会有过度自信问题,导致在某些问题上会给出反直觉的答案。如何处理这种分布外数据是非常具有挑战的。本课题旨在研究解决预训练模型在分布外数据过度自信的问题。
建议研究方向:
使用贝叶斯方法提升模型处理分布外数据的能力。
1.3 预训练模型针对事实性的提升
预训练模型对于基于事实性知识的任务处理能力仍有待提高。本课题旨在研究提升预训练模型对事实性知识相关任务的处理能力。
建议研究方向:
提升预训练模型处理事实性知识相关任务的能力。
1.4 预训练模型的认知和知识学习(包括认知架构、知识增强、知识支持、知识监督等)
认知是人类学习和应用知识的能力。掌握世界知识是构建人工智能系统不可缺少的部分,对下游应用起着重要的支撑作用。随着大规模预训练模型的不断发展,人们发现大模型可以学习到一些知识,也具有与理解知识相关语言文本的能力。但是当前研究缺乏对大模型在知识认知能力上的深入研究。本课题旨在研究预训练模型的知识认知能力。
建议研究方向:
对大模型掌握事实、概念知识的程度进行细致、全面的探测,以指导下游应用的模型选择。
✦
✦

2. 预训练技术:
2.1 预训练模型的推理加速技术
预训练模型在推理时,由于计算量较大,推理速度相对较慢,影响了预训练模型的响应速度。对模型进行推理加速,是亟待解决的问题之一。本课题旨在研究预训练模型的推理加速技术。
建议研究方向:
针对预训练模型的推理进行优化,包括算子融合、模型并行、内存管理等。
2.2 预训练模型的压缩技术
目前预训练模型在推理时占用显存较大,对于算力资源的需求较大,限制了预训练模型的广泛应用。如何降低模型参数规模,减少推理内存的需求,使预训练模型在较小 GPU 上运行,并能加快推理速度,且尽可能保留原有性能,是一项非常重要且具有挑战性的任务。本课题旨在研究压缩预训练模型的关键技术。
建议研究方向:
1)对预训练模型进行量化;
2)预训练模型在特定任务上的知识蒸馏;
3)对预训练模型进行剪枝。
2.3 预训练模型的多平台适配(包括数据移动、并行策略、大规模训练等)
目前业界涌现了很多 GPU 平台,除 NVIDIA、AMD 之外,还有华为昇腾、神威、海光SOC 等,预训练模型在这些平台上的适配还不充分。对于多平台的适配,涉及数据移动、并行计算、大规模训练等方面。本课题旨在研究适配于多平台的大模型训练与推理框架。
建议研究方向:
1)在多平台进行模型训练,发现低效的模块和算子并进行针对性的优化;
2)对于并行策略进行优化和融合,并减轻由卡规模较大产生的故障问题;
3)利用自动调优等技术手段提高训练的软硬件适配度,使模型能在超大规模集群运行并大大降低算力消耗。
2.4 预训练模型赋能的知识获取
研究发现大模型可以学习到事实知识,也具有理解知识相关语言文本的能力。由此,如何利用预训练模型对知识图谱进行增强,是非常有意义的问题。本课题旨在研究探索预训练模型与大规模知识图谱相互帮助、增强的途径。
建议研究方向:
利用预训练模型进行知识获取。
2.5 预训练模型的领域适应与任务适应技术
预训练模型学到的是通用领域的知识,如何在预训练模型的基础上,针对下游的特定领域或者特定任务进行优化,是模型实际应用中的痛点。本课题旨在研究通用领域的预训练模型如何针对特定领域或特定任务进行适应。
建议研究方向:
1)针对特定领域的预训练模型的领域适应技术;
2)针对特定任务的预训练模型的任务适应技术。
✦
✦

3. 预训练模型:
3.1 多语言的预训练模型
单语言的预训练模型只能解决单一语言的应用场景。在实际语境中,经常有一种语言文本混有其他语言,或者多语言交替出现的场景。同时,考虑到不同语言可以表征到同一语义空间的可能性,使用通用的多语言模型,可以提升对低资源的语言的处理能力。由此,本课题旨在研究如何提升多语言预训练模型的理解与生成能力。
建议研究方向:
1)提升多语言预训练模型的理解能力;
2)提升多语言预训练模型的生成能力。
3.2 多模态的预训练模型
实际应用场景中,视觉/语音/文本数据经常是同时出现的,使用多模态预训练模型可以解决多种数据同时处理的问题。目前多模态预训练模型的输入输出信号处理方法以及预训练的目标多种多样,本课题旨在探索更加统一的多模态的信号处理,以及更加通用的多模态预训练模型。
建议研究方向:
1)统一的多模态信号处理方法;
2)通用的多模态预训练模型。
3.3 融合知识图谱的预训练语言模型
知识图谱显式地存储了世界知识,如何使用知识图谱对于预训练模型的知识处理能力进行提升,是自然语言处理领域中非常重要的问题。本课题旨在研究如何利用知识图谱提升预训练模型的认知能力。
建议研究方向:
利用大规模知识图谱中的实例及其概念体系对大模型做针对性增强,提升大模型对长尾事实和抽象概念的掌握。
3.4 面向对话系统,融合知识的预训练模型
对话系统,是自然语言处理中非常重要的分支。如何训练既有准确性、相关性、多样性,同时使对话符合常识和事实的预训练模型,是目前对话系统中面临的问题。本课题旨在研究面向对话系统、融合知识的预训练模型。
建议研究方向:
1)提升准确性、相关性、多样性的预训练对话模型;
2)融合知识的预训练对话模型。
3.5 面向信息检索,融合互联网结构或模型知识的预训练模型
信息检索,是自然语言处理中非常重要的组成部分。如何提升信息检索中预训练模型的相关性、覆盖率,是目前信息检索中面临的问题。本课题旨在探索融合互联网结构或模型知识,面向信息检索的预训练模型。
建议研究方向:
1)融合互联网结构的检索预训练模型;
2)融合模型知识的检索预训练模型。
3.6 垂直领域预训练大模型(如医疗、法律、金融、汽车等)
通用预训练模型对于专业术语的处理能力尚待提升,因此训练面向垂直领域的预训练大模型就显得非常必要。本课题旨在研究面向垂直领域的预训练大模型。
建议研究方向:
1)医疗领域预训练大模型;
2)法律领域预训练大模型;
3)金融领域预训练大模型;
4)汽车领域预训练大模型。
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了900多位海内外讲者,举办了逾400场活动,超400万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看更多!
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)