
王炸!Gemini 3深夜突袭,全球最强AI大模型一夜易主!新一轮军备赛彻底失控!
2025年11月Gemini 3的发布,与马斯克Grok 4 Fast的9月突袭,标志着大模型竞争进入"性能+速度+生态"的三维战争。Google用100万token上下文和72.1%事实准确性证明闭源模型的技术上限,xAI则以Grok 4的10倍速度提升和20万H100的暴力算力诠释"天下武功唯快不破"。这场竞赛的本质,已从单纯的参数军备赛,演变为"开源生态繁荣度×场景深度×硬件协同效率×响应速
2025年11月Gemini 3的发布,与马斯克Grok 4 Fast的9月突袭,标志着大模型竞争进入"性能+速度+生态"的三维战争。Google用100万token上下文和72.1%事实准确性证明闭源模型的技术上限,xAI则以Grok 4的10倍速度提升和20万H100的暴力算力诠释"天下武功唯快不破"。这场竞赛的本质,已从单纯的参数军备赛,演变为"开源生态繁荣度×场景深度×硬件协同效率×响应速度"的四维综合战。
未来三年,决定胜负的关键变量将是:谁能在开源社区中培育出超过百万的活跃开发者,谁能在垂直场景中实现1000个以上的行业模型落地,谁能在端侧芯片上实现10倍于云端的性价比提升,以及谁能将模型响应速度压缩至毫秒级。当Gemini 3的百万token窗口遇见Grok 4的10倍速响应,当开源生态的45%占比碰撞闭源模型的72%事实准确率,这场静默的技术革命,将真正重构全球科技产业的权力版图。

01行业情况 2025年11月Gemini 3引爆新一轮军备赛
全球AI大模型产业在2025年11月迎来历史性拐点,随着谷歌Gemini 3的发布,中美"双极"垄断格局进入白热化阶段。根据斯坦福大学人工智能实验室(SAIL)发布的《2025全球大模型技术白皮书》,中美两国占据全球Top20大模型的90%席位,其中美国企业占据12席,中国企业占据6席。
美国延续"大参数+强算力"路线,OpenAI的GPT-5 Pro以1.8万亿参数和128,000 TPUv5集群实现每秒3200次推理,在复杂逻辑推理任务中保持领先。Google在2025年11月18日发布的Gemini 3实现架构级突破,支持100万个token上下文窗口,在"人类最后的考试"中达到37.5%准确率,在GPQA Diamond测试中斩获91.9%高分,登顶LMArena排行榜并在SimpleQA Verified基准测试中以72.1%得分刷新事实准确性纪录。Gemini 3 Pro被誉为谷歌"最棒的氛围编程模型",其回复"智能、简洁、直接,用真知灼见取代了陈词滥调"。中国则突破"小参数+强架构"路径,深度求索DeepSeek-V3仅用1300亿参数即达到接近GPT-5的数学推理能力,训练效率提升40%。阿里通义千问Qwen-Max通过3D并行训练技术将千亿模型训练成本降低42%,在中文法律文书生成任务中准确率达97.1%。
美国聚焦通用能力商业化,OpenAI的API调用量突破10亿次/月,覆盖60%的全球SaaS企业。Google Gemini依托搜索业务打造的Deep Research成为行业标杆,2025年11月20日发布的Gemini 3 Pro Image预览版(Nano Banana 2)将图像生成能力推向新高度。中国则在垂直场景实现深度渗透,商汤科技"明眸"医疗大模型通过CFDA三类认证,在眼底病变诊断中准确率达98.7%,已部署于3000家基层医疗机构。阿里通义在国内企业AI模型使用中占比17.7%,全球市场份额超12%。字节跳动豆包大模型与抖音生态结合,图生视频能力突出。
美国通过《2024人工智能安全法案》强制要求模型透明度,但未限制技术出口。中国则将大模型纳入"新质生产力"战略核心,深圳、上海等地设立百亿级专项基金,对模型研发企业给予30%研发费用加计扣除。2025年"东数西算"工程构建的全国一体化算力网络,使华为昇腾AI集群实现96%的算力利用率,较行业平均水平高23个百分点。
2025年全球大模型市场规模突破800亿美元,其中美国企业占比55%,中国企业占比28%,欧洲及其他地区占17%。中国AI大模型产业年增速达210%,远超全球平均增速65%。










02产业链情况 从算力军备赛到场景收割战
(一)上游:算力、数据与核心元器件
算力基础设施
美国依托NVIDIA Hopper架构GPU集群,单模型训练成本较2023年下降45%。中国通过政策驱动构建自主算力网络,华为昇腾910B芯片使字节跳动CloudModel推理延迟比A100方案降低37%,单位算力成本下降58%。马斯克xAI的Colossus超级计算机搭载20万块英伟达H100 GPU,为Grok 4提供2亿GPU小时训练算力,硬件投入超70亿美元。2025年谷歌成为全球最大自研ASIC采购商,TPU V7集群单芯片算力较V5p提升10倍,直接拉动1.6T光模块需求上修至2000万只以上,中际旭创、新易盛等光模块厂商深度受益。
训练数据与语料
中文语料库建设成为竞争焦点。阿里通义千问训练数据达10万亿token,其中30%为中文专业领域数据(法律文书、医疗病例、金融合规)。百度文心5.0依托日均数十亿次搜索请求构建动态知识增强体系。海天瑞声为Gemini模型提供多语种训练素材,覆盖40个语种,成为跨境AI应用的基础设施。
AI芯片与框架
美国CUDA生态仍是行业事实标准,但国产框架崛起。华为昇腾AI集群算力利用率96%,深度优化的CANN架构支持PyTorch、TensorFlow无缝迁移。寒武纪思元590芯片在智源研究院大模型评测中,推理性能达A100的85%,但成本仅为60%。NVIDIA Nemotron-4聚焦GPU计算效率优化,支持分布式训练,在超算中心和自动驾驶场景广泛应用。
(二)中游:基础模型研发与生态构建
闭源通用大模型
OpenAI GPT-5.1以13.2万亿参数、128K上下文窗口、98.7%代码准确率定义行业天花板。Google Gemini 3于2025年11月18日发布,支持100万token上下文,在编程、智能体任务和长文本理解方面实现代际突破。Anthropic Claude 4.5 Opus在智能体任务和工具使用能力达SOTA水平,是最安全稳健的对齐模型。Meta LLaMA-3.1-405B虽性能强劲但已一年多未更新,开源社区活跃度已被中国模型超越。
开源模型革命
2025年开源成为行业标配,DeepSeek的开源改变了大模型发展轨迹。全球性能前25的大模型中,中国开源模型占据9席,Huggingface累计下载量突破3亿次。阿里通义千问全尺寸开源(7B~110B参数),在Open LLM Leaderboard排名第1。DeepSeek开源五大核心代码库,构建全球开发者协作网络。智谱AI GLM-4-Plus在视频通话交互优化方面表现突出。
垂直行业模型
中国企业在医疗、金融、制造等领域形成卡位优势。商汤"明眸"医疗大模型获CFDA认证,诊断准确率98.7%。华为盘古5.0气象预测模型将台风路径误差缩小至32公里。京东Joy AI大模型支撑智能客服"天象",2025年"双11"服务42亿人次,问题解决率85%。Cohere Command-R专注企业级生成式AI,提供定制化数据隐私保护,在客户服务自动化领域占据一席之地。
(三)下游:应用场景与商业化变现
企业服务API
OpenAI以10亿次/月API调用量垄断全球SaaS市场,60%的企业AI应用基于GPT模型构建。Google Gemini通过Google Cloud和Workspace生态渗透,2024年Q4云业务收入首破100亿美元,Gemini 3的发布将进一步巩固其生态优势。Microsoft Copilot在办公软件、云计算等领域与自身业务紧密结合,为用户提供智能化办公和云服务解决方案。中国厂商采取"开源免费+高阶服务收费"模式,百度文心5.0在金融风控场景响应速度突破80ms。
消费级应用
字节跳动豆包大模型与抖音生态深度融合,图生视频、多模态交互能力突出。阿里通义千问通过淘宝、钉钉等场景触达10亿级用户,在企业AI模型使用中占比17.7%。腾讯混元大模型支持微信、QQ等国民级应用,在LMSYS榜单中位列中国第二。昆仑万维天工大模型转型办公场景AI Agent,2025年全面发力企业级应用。
硬件载体创新
AI玩具成为端侧大模型新战场。乐鑫科技ESP32-S3芯片支持本地AI语音识别,占全球AI玩具市场45%。华为"小精灵AI玩伴"搭载昇腾310芯片,实现端侧2TOPS算力,功耗仅1.5W,通过鸿蒙生态实现全家桶联动。MosaicML MPT-50B在低成本训练方面成为行业标杆,适合初创企业MVP开发。
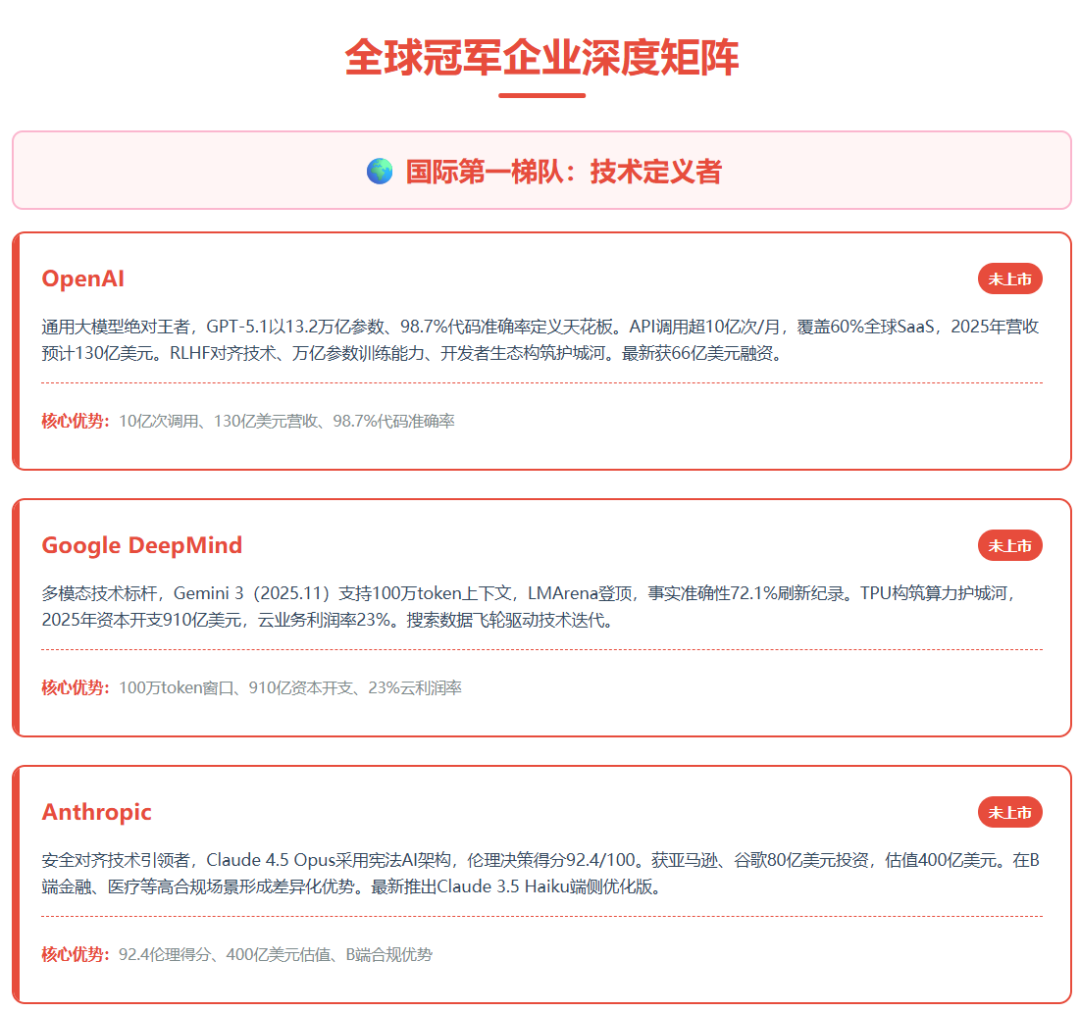
03冠军企业 (一)国际第一梯队:技术定义者
OpenAI(未上市)
通用大模型绝对王者,GPT-5.1以13.2万亿参数、128K上下文窗口、98.7%代码准确率定义行业天花板。API调用量超10亿次/月,覆盖60%全球SaaS企业,2025年营收预计突破130亿美元,其中API业务占70%。核心壁垒在于RLHF对齐技术、万亿参数训练工程化能力、开发者生态网络效应。最新动态:2025年11月与甲骨文合作扩大Stargate项目,获66亿美元新融资用于AGI研发。
Google DeepMind(未上市)
多模态技术标杆,Gemini 3于2025年11月18日发布,支持100万token超长上下文,在LMArena排行榜登顶,72.1%的事实准确性刷新行业纪录。Gemini 3 Pro Image预览版(Nano Banana 2)将图像生成能力推向新高度。TPU自研芯片构筑算力护城河,2025年资本开支910-930亿美元,其中AI服务器占比超60%。云业务已实现季度盈利,利润率23%。核心优势:搜索数据飞轮、TPU硬件闭环、多模态技术领先。
Anthropic(未上市)
安全对齐技术引领者,Claude 4.5 Opus采用宪法AI架构,在伦理决策测试得分92.4/100,智能体任务和工具使用能力业界SOTA。2025年获亚马逊、谷歌合计80亿美元战略投资,估值超400亿美元。其"AI安全"定位在B端金融、医疗等高合规场景形成差异化优势。最新动态:推出Claude 3.5 Haiku,专注端侧部署优化,适合移动设备安全对话。
xAI(未上市)
马斯克打造的"速度之王",Grok 4于2025年7月发布,在Colossus超算(20万块H100)上训练,训练量为Grok 2的100倍。Grok 4 Fast于9月上线,速度提升10倍,针对简单查询和工具使用场景优化。Grok 4 Imagine在图像生成速度上表现惊艳。2025年8月Grok 4限时免费,正面迎战GPT-5。计划2026年推出Grok 5(6万亿参数),马斯克称其将"发现新物理学"。xAI估值已超750亿美元,获英伟达、AMD战略投资。核心优势:X平台实时数据、马斯克品牌效应、超算暴力美学。
Meta(NASDAQ: META)
开源生态霸主,LLaMA系列模型全球下载量超10亿次。2025年虽未更新旗舰模型,但LLaMA-3.1-405B在开源社区仍有强大影响力。Cicero AI在策略外交游戏Diplomacy中击败人类玩家,展现复杂博弈能力。战略重心转向AI与元宇宙结合,Reality Labs部门年投入超150亿美元。核心优势:开源社区统治力、社交数据护城河、元宇宙先行优势。
NVIDIA(NASDAQ: NVDA)
AI算力基础设施之王,虽未直接研发消费级大模型,但Hopper架构GPU集群支撑了全球90%的大模型训练。2025年推出H200 GPU,性能较H100提升30%。Nemotron-4模型聚焦GPU计算效率优化。其CUDA生态仍是行业事实标准,但面临华为CANN、AMD ROCm挑战。核心优势:硬件垄断、CUDA生态、算力网络。
Microsoft(NASDAQ: MSFT)
AI应用整合大师,Copilot在Office 365、Azure、GitHub深度集成,覆盖3亿企业用户。2025年Copilot for Security在网络安全领域实现自动化响应,准确率85%。战略投资OpenAI超130亿美元,Azure OpenAI服务年收入超50亿美元。核心优势:企业软件生态、云服务整合、战略投资布局。
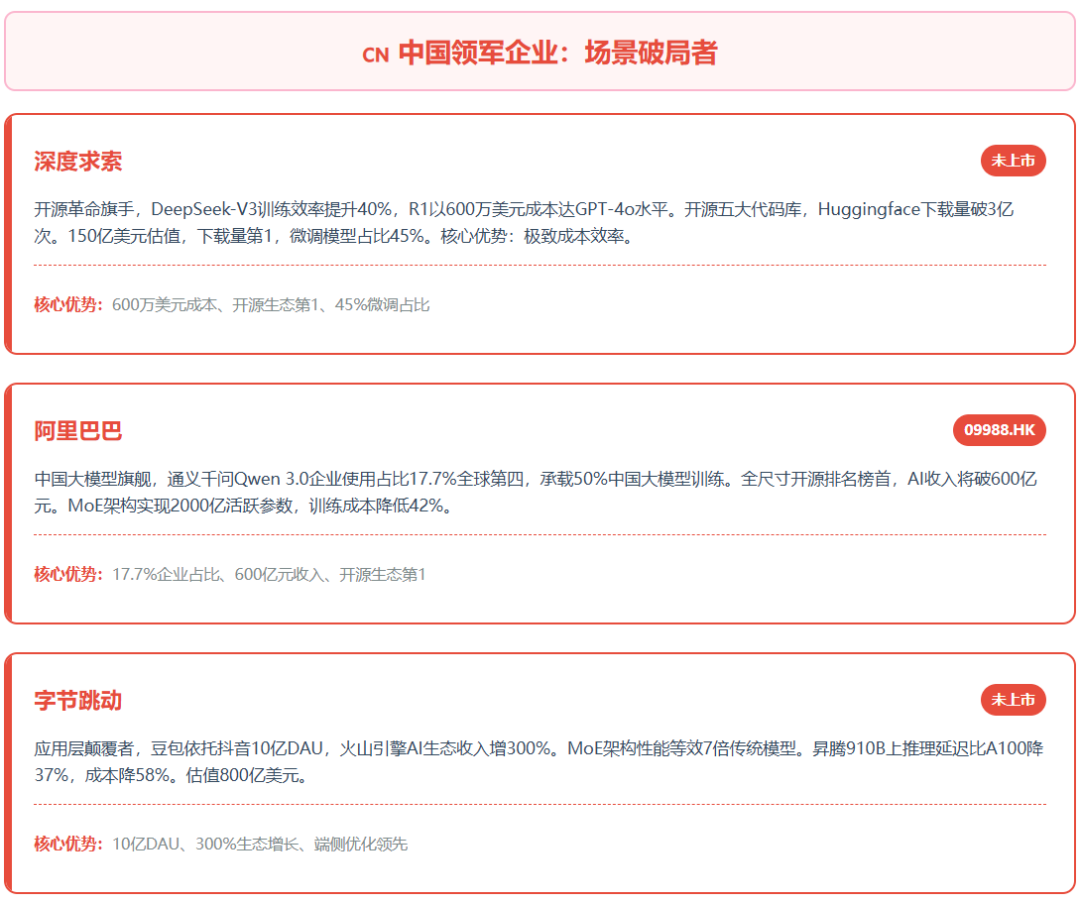
(二)中国领军企业:场景破局者
深度求索(未上市)
开源革命旗手,DeepSeek-V3以1300亿参数实现接近GPT-5的数学推理能力,训练效率提升40%。DeepSeek-R1通过强化学习与模型蒸馏技术,仅耗资600万美元即达到GPT-4o水平,训练成本仅为OpenAI的1/27。开源五大核心代码库,构建全球开发者协作网络,Huggingface下载量突破3亿次。2025年获高领、红杉等机构20亿美元融资,估值150亿美元。最新动态:在Hugging Face Open LLM Leaderboard排名第1,微调模型占比45%。核心优势:极致成本效率、开源生态统治力、推理优先范式。
阿里巴巴 09988.HK
中国大模型产业旗舰,通义千问Qwen 3.0在国内企业AI模型使用中占比17.7%全球第四,阿里云平台承载超50%中国大模型训练任务。2025年Qwen-Max 2.0通过MoE架构实现2000亿活跃参数,训练成本降低42%。通义千问全尺寸开源(7B~110B参数),在Open LLM Leaderboard排名第1。AI相关收入预计2025年突破600亿元。核心优势:开源生态最完善、全场景落地能力、云计算基础设施。
字节跳动(未上市)
应用层颠覆者,豆包大模型依托抖音10亿DAU生态,图生视频、多模态交互能力突出。豆包采用稀疏MoE架构,性能等效7倍传统模型,训练成本大幅降低。火山引擎向AI玩具、教育硬件输出端侧大模型,采用"硬件预装+云服务费"模式,2024年AI生态收入同比增长300%。CloudModel在昇腾910B芯片上推理延迟比A100降低37%,成本下降58%。核心优势:流量生态、端侧优化、商业化速度。
百度 09888.HK
知识增强大模型领导者,文心5.0搭载ERNIE-Bot架构,在金融风控场景响应速度突破80ms。搜索日均数十亿次请求构建动态知识增强体系,Q4财报显示大模型相关收入占比提升至18%。文心一言4.0在文言文互译、方言交互场景准确率92%。智能云在交通、能源等领域落地超30个大模型解决方案,2025年营收预计增长45%。核心优势:搜索数据飞轮、中文场景深度、B端解决方案。
科大讯飞 002230.SZ
语音交互技术王者,星火X1大模型在语音识别、多语种支持、教育医疗专精方面领先。星火儿童版大模型已赋能50余款AI玩具,调用成本降至0.001元/次。2025年AI玩具相关收入预计超15亿元,占消费者业务20%。讯飞星火在医疗场景落地最深,支持安徽、河南等省基层医疗AI辅助诊断。核心优势:语音技术壁垒、教育医疗场景、硬件整合能力。
商汤科技 0020.HK
视觉大模型领导者,SenseChat 5.5在中文自然语言生成刷新纪录,文科得分81.8分。 "明眸"医疗大模型获CFDA三类认证,诊断准确率98.7%,已部署3000家医院 。SenseNova 5.5大模型体系在安防、智慧城市领域占据60%市场份额。2025年推出"日日新"大模型一体机,实现私有化部署。核心优势:计算机视觉技术、医疗认证壁垒、垂直场景深耕。
智谱AI(未上市)
清华大学技术转化标杆,GLM-4.6在中文场景表现优异,在通用编程与中文工程任务中达到国际顶尖水平。GLM-4-Plus视频通话交互优化,知识问答均衡。开源ChatGLM系列模型,在学术圈影响力巨大。2025年获腾讯、阿里战略投资,估值120亿美元。核心优势:学术背景、中文工程能力、开源社区。
腾讯 00700.HK
全场景布局者,混元大模型支持微信、QQ等国民级应用,在LMSYS榜单中位列中国第二。腾讯元宝依托微信生态,用户量超2亿。AI Lab与游戏、社交、金融业务深度整合,王者荣耀AI"绝悟"达到职业电竞水平。2025年推出"腾讯智影"AIGC平台,服务百万创作者。核心优势:社交数据护城河、应用场景丰富、游戏AI技术。
月之暗面(未上市)
长文本技术专家,Kimi(K2)支持20万+ token上下文,在科研分析、法律文本处理场景被誉为"读论文神器"。2025年Kimi智能助手月活突破3000万,在学术圈、法律界形成口碑效应。采用MoE架构,总参数达1万亿,激活参数320亿。核心优势:长文本技术、垂直用户粘性、科研场景深耕。
昆仑万维 300418.SZ
转型AI的出海先锋,天工大模型2025年全面转型办公场景AI Agent。旗下Opera浏览器用户量超1亿,集成AIGC功能后ARPU值提升35%。2025年推出"天工AI搜索",在海外市场下载量超5000万次。核心优势:海外用户基础、浏览器入口、AI Agent转型。
(三)产业链概念龙头与生态伙伴
中科蓝讯 688332.SH
AI大模型芯片概念龙头,2024年实现净利润3亿,同比增长19.23%。Wi-Fi/蓝牙音频芯片广泛应用于AI玩具、智能音箱,在端侧AI芯片市场占据25%份额。2025年推出"讯龙"系列AI芯片,支持本地大模型推理,功耗降低40%。核心优势:端侧芯片、音频AI、快速增长。
恒生电子 600570.SH
金融科技AI龙头,2024年净利润10.43亿元。恒生大模型平台支撑智能投研、风控、客服,服务超1000家金融机构。2025年与通义千问合作推出"金融AI一体机",实现私有化部署。核心优势:金融场景壁垒、合规能力、B端客户基础。
软通动力 301236.SZ
AI大模型生态服务商,结合算力中心云端算力和软通天璇2.0MaaS端侧AI大模型,构建云边端生态系统。为华为、阿里、百度等大模型提供算力部署和运维服务,2025年AI业务营收占比提升至30%。核心优势:算力运维、生态整合、企业服务能力。
值得买 300785.SZ
AI大模型应用先锋,接入MiniMax的海螺AI大模型,提供商品比价、推荐等功能。2025年"AI购物助手"服务超5000万用户,转化率提升25%。核心优势:消费场景、用户基础、应用创新。
(四)新兴势力与垂直专家
MiniMax(未上市)
多模态AI新锐,"海螺AI"在视频生成、商品推荐场景表现优异。2025年获阿里、腾讯投资,估值80亿美元,专注于AI内容生成。核心优势:多模态技术、内容生态、快速迭代。
百川智能(未上市)
王小川创立的大模型公司,聚焦医疗场景,百川大模型在中文医疗咨询准确率92%。2025年与北京协和医院合作推出AI导诊系统。核心优势:医疗专注、创始人背景、场景深耕。
零一万物(未上市)
李开复创办的AI 2.0公司,2025年推出"Yi"系列大模型,在开源社区获得关注。专注于企业级大模型解决方案,服务制造业客户超200家。核心优势:企业级服务、国际化视野、李开复品牌。
第四范式 6682.HK
决策类AI龙头,聚焦企业智能化转型,2025年在金融、零售、制造领域落地大模型解决方案超500个。核心优势:B端决策AI、垂直行业know-how、商业化能力。
美图公司 1357.HK
AIGC应用专家,“美图AI"在图像、视频生成领域用户超2亿,2025年推出"美图设计室” SaaS服务,订阅收入占比提升至40%。核心优势:C端用户基础、视觉AI、订阅模式。
(五)国际重要参与者
Cohere(未上市)
企业级AI专家,Command-R专注企业级生成式AI,提供定制化数据隐私保护,在客户服务自动化领域占据一席之地。核心优势:企业级服务、数据安全、客户服务场景。
Inflection AI(未上市)
对话AI创新者,Inflection-2.5在对话自然度和情感理解方面表现优异,专注个人AI助手场景。核心优势:对话技术、用户体验、个人助手。
Stability AI(未上市)
开源图像AI领导者,Stable Diffusion在AIGC图像生成领域占据主导地位,与Midjourney形成竞争。核心优势:开源生态、图像生成、创意产业。
Mistral AI(未上市)
欧洲大模型代表,Mixtral 8x7B在开放权重模型中性能领先,获欧盟大力支持。核心优势:欧洲市场、开放权重、政策扶持。
04行业趋势 核心趋势研判
1. 开源模型性能超越闭源,生态决定未来:2025年全球性能前25的大模型中,中国开源模型占据9席,Huggingface累计下载量突破3亿次。阿里通义、DeepSeek等通过"开源免费+高阶服务收费"模式,快速扩大开发者生态。Gemini 3的发布标志着闭源模型在事实准确性和长文本能力上的新高度,但开源社区的45%微调模型占比显示生态力量正在重塑竞争规则。
2. 垂直场景深度决定商业化速度:中国企业在医疗、金融、制造等领域形成卡位优势,商汤医疗大模型已部署3000家医院,华为盘古气象模型误差缩至32公里。美国企业聚焦通用平台,API调用量虽大但垂直场景渗透较慢。马斯克Grok 4通过X平台数十亿推文数据构建私域生态,在实时信息处理场景形成差异化。2025年中国大模型在B端收入增速(210%)远超美国(65%),场景深度成为差异化关键。
3. 端侧大模型爆发,硬件载体重构入口:AI玩具、智能眼镜、车载座舱成为端侧大模型新战场。乐鑫科技ESP32芯片占AI玩具市场45%,华为昇腾310实现端侧2TOPS算力。Grok 4 Fast的推出证明速度将成为端侧竞争核心,实时性比深度更重要。2025年端侧AI芯片出货量将超5亿颗,推动大模型从云端走向边缘。
4. 算力自主化成为国家安全战略:美国CUDA生态仍是事实标准,但华为昇腾、寒武纪思元590通过CANN架构支持PyTorch无缝迁移。中国"东数西算"工程构建自主算力网络,使昇腾集群算力利用率高达96%。xAI的Colossus超算投入70亿美元,吞噬300兆瓦电力,展现算力军备赛的残酷性。2025年国产AI芯片在推理场景占比提升至35%,训练场景达15%,自主化趋势不可逆转。
5. 多模态与智能体成下一代技术高地:Gemini 2.5 Flash支持10M token上下文,Claude 4.5 Opus智能体任务达SOTA水平。Gemini 3的100万token窗口和Deep Think推理模式标志着智能体时代的真正到来。从文本生成向"文本-图像-视频-动作"多模态融合演进,2025年支持多模态的AI应用占比将从20%提升至50%。Google Deep Research、AutoGPT等智能体应用预示AI从"工具"向"协作者"进化。
从算力军备赛到生态决胜赛
2025年11月Gemini 3的发布,与马斯克Grok 4 Fast的9月突袭,标志着大模型竞争进入"性能+速度+生态"的三维战争。Google用100万token上下文和72.1%事实准确性证明闭源模型的技术上限,xAI则以Grok 4的10倍速度提升和20万H100的暴力算力诠释"天下武功唯快不破"。这场竞赛的本质,已从单纯的参数军备赛,演变为"开源生态繁荣度×场景深度×硬件协同效率×响应速度"的四维综合战。
未来三年,决定胜负的关键变量将是:谁能在开源社区中培育出超过百万的活跃开发者,谁能在垂直场景中实现1000个以上的行业模型落地,谁能在端侧芯片上实现10倍于云端的性价比提升,以及谁能将模型响应速度压缩至毫秒级。当Gemini 3的百万token窗口遇见Grok 4的10倍速响应,当开源生态的45%占比碰撞闭源模型的72%事实准确率,这场静默的技术革命,将真正重构全球科技产业的权力版图。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?
更多推荐
 13
13 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)