
构建基于YOLOV5模型的目标检测DEMO VSCode(二)
在VisualStudio中新建一个名为demo_yolov5_based_qnn_cpp的windows桌面应用项目,并为其添加新配置:ARM64和ARM64EC,它们都是基于x64的,如下图所示:这里ARM64EC(兼容性扩展)是一种 ARM64 的扩展架构,用于兼容性和性能优化。
三、应用开发
1、创建配置项目
在VisualStudio中新建一个名为demo_yolov5_based_qnn_cpp的windows桌面应用项目,并为其添加新配置:ARM64和ARM64EC,它们都是基于x64的,如下图所示: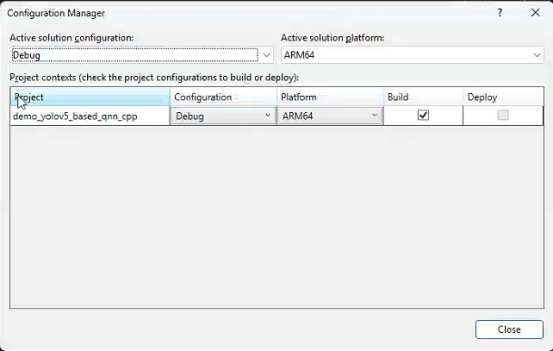
这里ARM64EC(兼容性扩展)是一种 ARM64 的扩展架构,用于兼容性和性能优化。
2、集成OpenCV库
基于YOLOV5模型的目标检测DEMO需要集成OpenCV库,以便能够对需要推理的要数据进行预处理。OpenCV库现在已经纳入了VCPKG包管理器中进行管理,因此为便于在VisualStudio中集成OpenCV库,我们使用VCPKG包管理器将其添加到项目中。执行下面命令即可:
vcpkg new --application
vcpkg add port opencv
然后导航到项目的属性页,选中vcpkg一项,将其中的Use Vcpkg Manifest设置为Yes,这样构建项目之前会检查其依赖包是否安装,若未安装则先安装依赖包再构建:
3、复用ai-engine-direct-helper
ai-engine-direct-helper是高通的一个开源项目,它是参考QNN SDK中的Sample开发的、旨在将QNN SDK封装成python接口以便于算法人员能够使用python语言快速构建demo以验证模型的效果。ai-engine-direct-helper提供的接口简单易用,其基本架构是现在QNN SDK的基础上,封装出一套C++接口,在将C++接口封装成python接口。为了简单yolov5 DEMO的开发,我们可以直接使用ai-engine-direct-helper中封装的C++接口,为此我们需要编译出对应的动态库。具体步骤如下(在WoS开发环境中执行):
git clone https://github.com/quic/ai-engine-direct-helper.git
cd ai-engine-direct-helper
git checkout 216166cbb841db85b155caf4eaee6f194f9ed326
cd src
mkdir build
cd build
cmake ../ -T ClangCL -A ARM64
cmake --build ./ --config Release
编译过程中,会出现报错,涉及到两个文件:src\QnnSampleApp.cpp和src/Utils/DataUtil.cpp,修改如下:
PS C:\Users\HCKTest\source\repos\ai-engine-direct-helper\src\build> git diff ../QnnSampleApp.cpp
diff --git a/src/QnnSampleApp.cpp b/src/QnnSampleApp.cpp
index 7b90659..526dca1 100644
--- a/src/QnnSampleApp.cpp
+++ b/src/QnnSampleApp.cpp
@@ -122,7 +122,7 @@ bool boostPerformance(QnnHtpDevice_PerfInfrastructure_t perfInfra, std::string p
powerConfig.dcvsV3Config.coreVoltageCornerMax = DCVS_VOLTAGE_VCORNER_TURBO;
}
else {
- QNN_ERROR("Invalid performance profile %s to set power configs", perfProfile);
+ QNN_ERROR("Invalid performance profile %s to set power configs", perfProfile.c_str());
return false;
}
(qai_3.8.10) PS C:\Users\HCKTest\source\repos\ai-engine-direct-helper\src\build> git diff ../Utils/DataUtil.cpp
diff --git a/src/Utils/DataUtil.cpp b/src/Utils/DataUtil.cpp
index d3b35e2..4fd2d2d 100644
--- a/src/Utils/DataUtil.cpp
+++ b/src/Utils/DataUtil.cpp
@@ -346,8 +346,8 @@ static inline float datautil::fp32_from_bits(uint32_t w) {
#elif defined(__INTEL_COMPILER)
return _castu32_f32(w);
#elif defined(_MSC_VER) && (defined(_M_ARM) || defined(_M_ARM64))
- return _CopyFloatFromInt32((__int32) w);
-#else
+// return _CopyFloatFromInt32((__int32) w);
+// #else
union {
uint32_t as_bits;
float as_value;
@@ -364,8 +364,8 @@ static inline uint32_t datautil::fp32_to_bits(float f) {
#elif defined(__INTEL_COMPILER)
return _castf32_u32(f);
#elif defined(_MSC_VER) && (defined(_M_ARM) || defined(_M_ARM64))
- return (uint32_t) _CopyInt32FromFloat(f);
-#else
+// return (uint32_t) _CopyInt32FromFloat(f);
+// #else
union {
float as_value;
uint32_t as_bits;
编译完成后,会生成libappbuilder.dll和libappbuilder.lib文件,将其添加到demo_yolov5_based_qnn_cpp项目中。
4、设计开发应用
下图为基于YOLOV5模型的目标检测DEMO的架构图,其中最底部的两层为分别为QNN SDK以及ai-engine-direct-helper,后者是对前者的进一步封装,它为上层提供了更易于使用的C++接口。
而QnnContext则为基于ai-engine-direct-helper提供的C++接口进一步抽象出来的类,该类定义了5个接口。其中最为重要的接口为推理接口,该接口输入为待推理的图像数据,输出为结构化的数据,该类使用了类的模板参数T,即模型推理输出的结构化数据由派生类决定。另外还有两个接口为纯虚接口,它们分别对应模型的预处理和后处理,派生类需要实现该接口。并且这两个接口在推理接口中被调用,构成了一个完整的处理流程。剩下的两个接口便为构造函数以及检查函数,前者负责模型的加载以及相关的初始化,后者负责检查初始化是否成功。
图中的Yolov5为QnnContext的派生类,实现了基类定义的两个纯虚接口。其中预处理接口要根据yolov5模型的要求,负责对待进行目标检测的图像数据进行预处理,包括缩放、截取以及归一化等,后处理接口同样要根据yolov5模型的标准对模型推理输出的数据进行后处理,以输出目标框、置信度及其类别等。其它模型的部署推理,都可以参考Yolov5类,实现与模型本身对应的前后处理接口。
最上层为DEMO程序本身,主要流程也比较简单,就是先初始化QNN SDK并加载标签文件,然后实例化一个Yolov5类对象,并检查初始化是否成功,然后读取本地的图片bus.jpg以及zidane.jpe,并使用Yolov5实例对其进行目标检测,然后将检测到的目标绘制到原始图像上并进行显示,直到用户按下’n’键退出本地图片的识别。退出本地图片识别后,通过OpenCV的cv::VideoCapture采集USB摄像头的视频数据,并将采集到的每一帧图像数据送给Yolov5实例进行目标检测,并将检测到的目标绘制到原始图像上并进行显示,直到用户按下’q’键退出USB摄像头实时视频的识别。
5、实际效果展示
bus.jpg图片的检测效果如下图所示,其中右上角为模型推理所耗费的时间:
zidane.jpg图片的检测效果如下图所示,其中右上角为模型推理所耗费的时间:
USB摄像头视频的检测效果如下图所示:
常见问题
1、图像在内存中不连续
问题:运行基于YOLOV5模型的目标检测DEMO,发现推理结果完全不正确,并且发现ai-engine-direct-helper中保存下来的待推理图像数据不正确,请问这是怎么回事?
答案:opencv Mat数据的tranpose操作和pytorch张量的premute操作都不会进行拷贝以重排数据的,而是通过设置步幅(stride)来达到重排的目的,这就导致了重排后数据的不连续性。而QNN SDK在对传过来的数据进行推理时,是忽略应用层数据的stride属性而默认数据是连续的,从而导致推理结果异常。因此,需要对不连续的张量数据执行contiguous()操作。
2、模型输出不正常
问题:运行基于YOLOV5模型的目标检测DEMO,选择在NPU上加载和运行量化版的dlc模型文件,对本地图片进行推理时,发现推理结果经过后处理后,目标的框位置是正确的,但是其对应的置信度,它们的值都为0或趋于0,并因此滤掉了所有检测出来的目标,请问这是怎么回事?
答案:经过调试分析发现模型中最后一个激活层(Sigmoid)的输出是正确,但是最后一个链接层(Contact)的输出则是不正确的——置信度的值都为0或趋于0,如下图所示:
有两种法可以用来处理这个问题:
- 简单起见,加载构建原量化版yolov5l模型时,屏蔽其原输出层(output0),并添加最后一个激活层作为输出,并在后处理中对推理结果其进行额外的处理(Split、Mul、Add等);
- 编写python脚本或使用相关工具对onnx模型进行修改——删除Split及其后续节点,并添加三个输出节点分别与最后一个激活层Sigmod节点的输出相连接,后处理方式通前一种方式。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)