
干货:智算集群网络架构关键技术
多卡训练可极大缩短训练时间,尤其对于千亿级甚至万亿级参数规模的大语言模型,智算集群需支持万卡及以上的并行能力。因此,设计大规模、高可靠、低成本、易运维的优质网络架构,对于满足大模型训练的大算力、低时延和高吞吐需求具有重要意义。、系统复杂度,三层组网的负载均衡、拥塞控制等网路技术的难度和复杂度将大幅提升;交换机,该方式集群通信效率偏低,但在机房实施布线中有较大优势。性,但在时延与建设成本方面并非最优
——以下正文——
在AI 大模型训练场景中,GPU 数量与模型训练时长通常呈正比关系。多卡训练可极大缩短训练时间,尤其对于千亿级甚至万亿级参数规模的大语言模型,智算集群需支持万卡及以上的并行能力。智算集群内网络架构的优劣对 GPU 服务器内外的集合通信存在极大影响。
因此,设计大规模、高可靠、低成本、易运维的优质网络架构,对于满足大模型训练的大算力、低时延和高吞吐需求具有重要意义。
(1)Clos 网络架构
胖树(Fat-Tree)Clos 无阻塞网络架构由于其高效的路由设计、良好的可扩展性及方便管理等优势,成为大模型训练常用网络架构。
对于中小型规模的 GPU 集群网络,通常采用 Spine-Leaf 两层架构, 对于较大规模的GPU集群则使用三层胖树(Core-Spine-Leaf)进行扩展组网,由于网络的层次增加,其转发跳数与时延也相应增加。
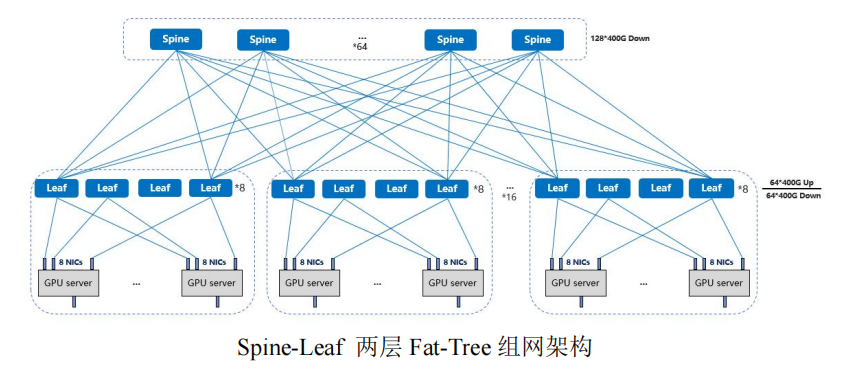
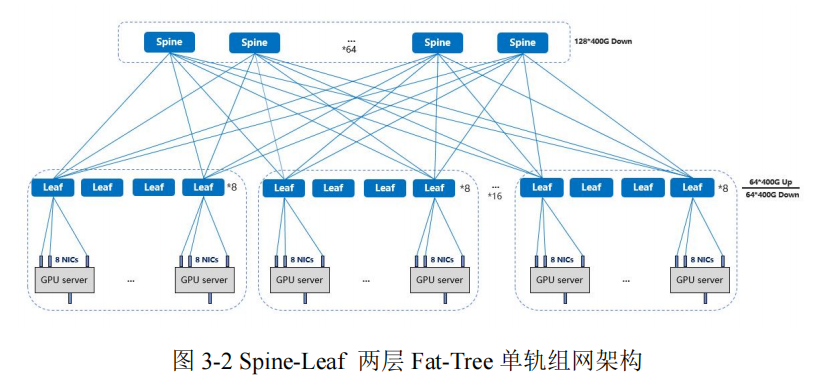
GPU 服务器接入分为多轨和单轨两种方式。上图为多轨接入方式,其 GPU 服务器上的 8 张网卡依次接入 8 台 Leaf 交换机,该方式集群通信效率高,大部分流量经一级 Leaf 传输或者先走本地 GPU 服务器机内代理再经一级 Leaf 传输。下图为单轨接入方式,1 台 GPU服务器上的网卡全部接入同一台 Leaf 交换机,该方式集群通信效率偏低,但在机房实施布线中有较大优势。此外,若 Leaf 交换机发生故障,多轨方式所影响的 GPU 服务器数量将多于单轨方式。
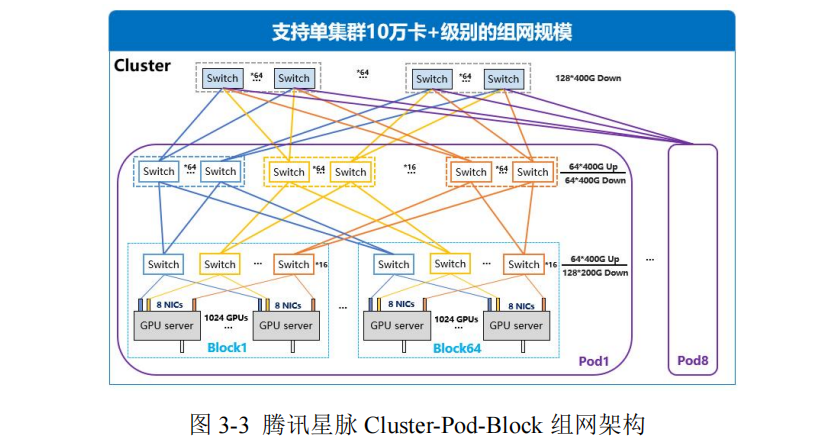
业内典型的大模型组网架构有腾讯星脉与阿里巴巴 HPN 网络。星脉网络采用无阻塞胖树(Fat-Tree)拓扑,分为 Cluster-Pod-Block三级。以 128 端口 400G 交换机为例,其中Block为最小单元,各 Block 包含 1024 个 GPU,各 Pod 支持最大 64 个 Block,即 65536 个 GPU。多个 Pod 构成一个 Cluster 集群,支持 524288 个GPU。
阿里云大模型训练网络(HPN,High-Performance Networking)引入一种双平面两层架构,每台 GPU 服务器配置了 8个 GPU,对应 8 个 NIC,各 NIC 提供 2×200Gbps 带宽,并上行连接到不同 Leaf 设备,形成双平面设计,从而避免单 Leaf 故障对训练任务的影响。若交换机为 128 端口,每台 GPU 服务器分别上行连至 16台 Leaf,组成一个 Segment(包含 1024 个 GPU)。
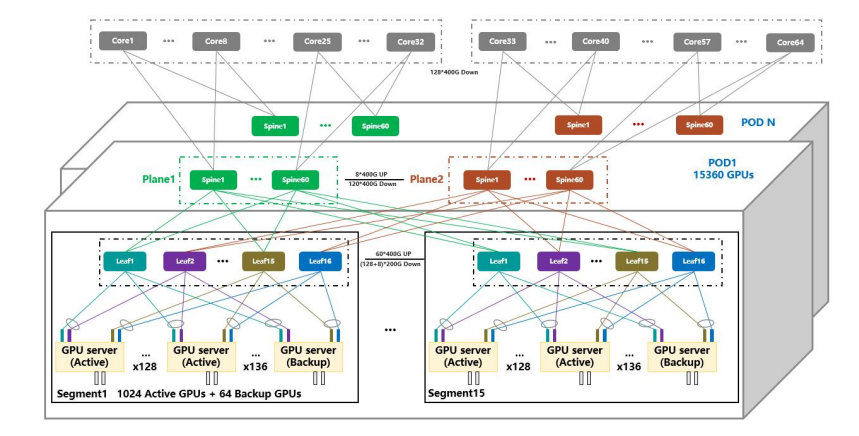
每台 Leaf 预留了额外 8×200G 端口接入 GPU 服务器,便于 GPU 服务器发生硬件等故障后可快速替换。Spine 层面连接多个 Segments 组成一个 Pod,每台Leaf 上行有 60×400G 端口连接 Spine,因此一个 Pod 可容纳 15 个Segments,即 15360 个 GPU。对于更大规模的训练任务,则会涉及到 Core 层面的连接进而组成算力规模更大的 GPU 集群。阿里根据其训练任务流量特性,选择 Spine-Core 之间采用 15:1 的收敛比设计,集群可支持 245760 个 GPU。
(2)Dragonfly 网络架构
传统 Clos 树形架构作为主流的智算网络架构,重点突出其普适性,但在时延与建设成本方面并非最优。在高性能计算网络中,Dragonfly 网络因其较小的网络直径与较低的部署成本被大量使用。
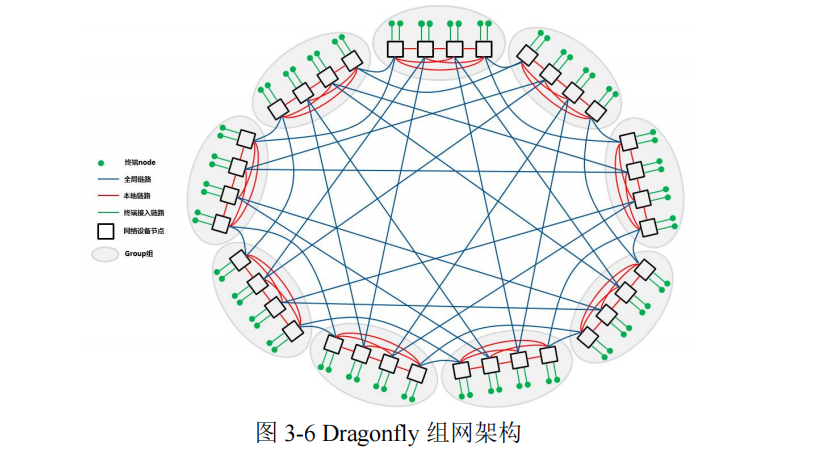
Dragonfly 可支持超过 27 万个 GPU 卡,相当于三层 Fat-Tree 架构所容纳 GPU 数量的 4 倍以上,而交换机数量及传输跳数可降低 20%。尽管 Dragonfly 网络可提供较高的性价比与更低的传输时延,但 GPU集群每次扩展都需重新部署链路,因此其可维护性相对较差。
(3)Group-wise Dragonfly+网络架构
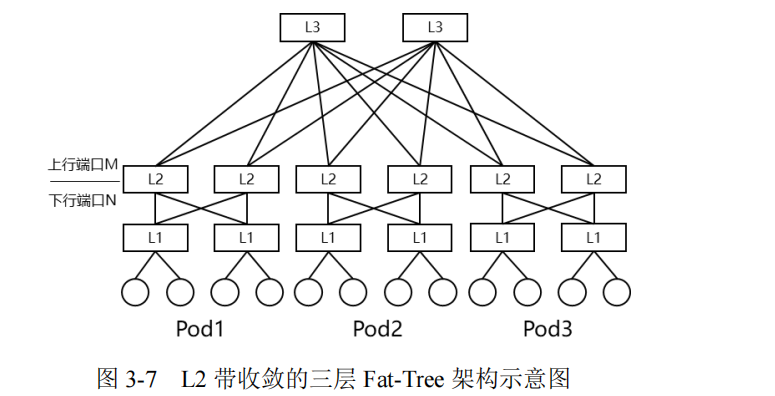
当规模需求超过十万卡时,最直接的组网方式是引入无收敛三层Fat-Tree 架构。以单端口为 400G 的 51.2T 盒式交换机为例,三层盒盒盒组网,最大支撑 50 万+节点组网。然而此架构存在以下两个主要问题:
1、系统复杂度,三层组网的负载均衡、拥塞控制等网路技术的难度和复杂度将大幅提升;
2、成本和功耗,对比二层 Fat-Tree 组网网络成本和功耗开销提高。为了应对以上两个挑战,在此场景下可以有两种架构选择:
架构一为第二层带收敛的三层 Fat-Tree 架构,即下图中 L2 层交换机的下行带宽:上行带宽为 N:M(N>M)。在同等规模下此架构可降低 L3 层的设备数量,节省成本和功耗。
架构二为 Group-wise Dragonfly+(GW-DF+)直连架构。如下图所示,每个 Pod 内设备通过二层 Fat-Tree 架构互联。Pod 间,同位置或同号的 L2 设备两两直连。以单端口为 400G 的 51.2T 盒式交换机为例,此架构最大可支持 20 万+节点规模。如果 L2 替换为框式交换机,规模可超100 万。
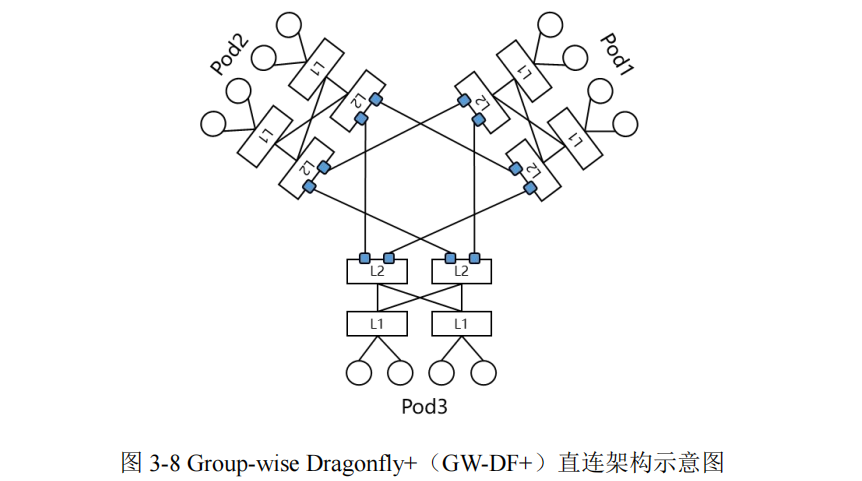
对比二层 Fat-Tree 架构,此架构可大幅提高组网规模;对比三层Fat-Tree 架构,此架构可节省一层交换机带来的成本和功耗开销;对比传统 DF+架构,此架构可避免上下设备绕行,简化路由复杂度和提升系统效率。
(4)Torus 网络架构
Torus 网络架构是一种完全对称的拓扑结构,具备低时延、低网络直径等特性,适合集合通信使用,可显著降低建设成本。
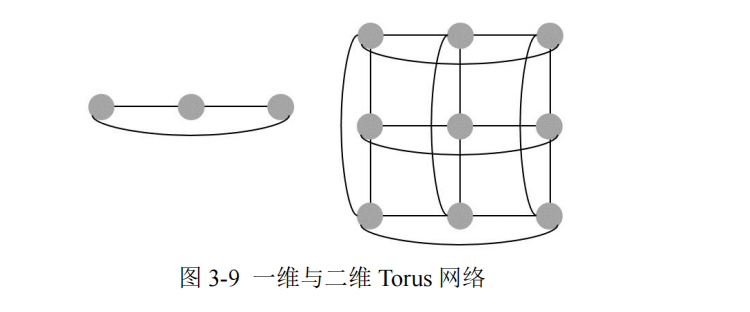
下图呈现了一维边长为 3 的 Torus 及二维边长为 3 的 Torus 网络。Torus 网络环面拓扑特性可使得其在邻居节点之间拥有最优通信性能。然而,Torus 网络扩展可能涉及拓扑重新调整,且维护复杂度较高。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)