
【强化学习-02】PPO算法
xn,并计算它们对应的权重值w1,w2,…在进行On-Policy的过程中,actor先于环境进行交互,交互得到很多的评价得分,然后构建损失,进行更新Policy Network。如上述图片所示,当在左侧的时候,p(x) > q(x),计算得到等式左侧的值是负值。当在右侧的时候,q(x) < p(x),采样计算得到的等式左侧的值看起来是正值,会导致左右两侧不同。:由于On-Policy方法依赖于连
文章目录
On-policy v.s. Off-policy
On-policy:进行训练的actor和与环境交互的actor是一样的
Off-policy:进行训练的actor和与环境的交互的actor不是一个

On-policy就是自己下棋,自己学习
Off-policy就是看别人下棋,进行学习
On-policy的缺点
上一篇文章当中,提到过Policy Gradient的方式是On-Policy。在进行On-Policy的过程中,actor先于环境进行交互,交互得到很多的评价得分,然后构建损失,进行更新Policy Network
on-policy公式:
∇ R ˉ θ = E τ ∼ p θ ( τ ) [ R ( τ ) ∇ log p θ ( τ ) ] \nabla \bar{R}_{\theta} = E_{\tau \sim p_{\theta}(\tau)} \left[ R(\tau) \nabla \log p_{\theta}(\tau) \right] ∇Rˉθ=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]

On-Policy方法在强化学习中具有一定的局限性,主要包括以下几个方面:
-
数据效率低下:On-Policy算法如A3C(Asynchronous Advantage Actor-Critic)和TRPO(Trust Region Policy Optimization)需要持续与环境交互来收集最新的经验数据。这意味着旧的、过时的数据不能用于更新策略,导致了数据利用效率较低的问题。
-
样本复杂度高:由于On-Policy方法依赖于实时产生的新鲜数据进行学习,它们通常需要大量的样本才能学习到有效的策略。这在实践中可能导致训练时间较长,尤其是在模拟成本高昂的环境中。
-
探索限制:On-Policy算法在探索(exploration)和利用(exploitation)之间维持了一种动态平衡。然而,这种机制有时可能限制了算法的探索能力,因为它倾向于根据当前策略生成的数据进行学习,而不是从历史数据中学习。
-
难以应用在非平稳或多人游戏等场景:在一些应用场景中,如非平稳环境或多智能体系统,环境的状态转移概率和奖励函数可能会随着时间变化。On-Policy方法在这种情况下可能表现不佳,因为它们依赖于基于当前策略的最新数据进行优化。
-
训练过程不稳定:由于On-Policy方法依赖于连续地更新策略,并且每次更新都需要新的样本来保证策略改进的方向正确,这可能导致训练过程中的不稳定性增加。
这些缺点促使研究人员开发Off-Policy方法,例如DQN(Deep Q-Networks)、DDPG(Deep Deterministic Policy Gradient)等,这些方法可以更有效地重用过往数据,提高数据利用率并降低样本复杂度。不过,每种方法都有其适用场景和局限性,选择合适的算法取决于具体的应用背景和需求。
Off-policy(PPO)实现
Importance Sampling(重要抽样)
重要抽样(Importance Sampling)是一种蒙特卡罗方法,用于估计概率分布函数或积分。它通过使用不同的样本生成器来提高计算效率,并减少所需采样的数量。
在传统的蒙特卡罗方法中,随机数被用来模拟实验结果的概率分布。然而,在某些情况下,这种方法可能会产生大量的错误结果,导致计算成本过高。这时,重要抽样就可以发挥作用了。
E x ∼ p [ f ( x ) ] ≈ 1 N ∑ i = 1 N f ( x i ) E_{x \sim p}[f(x)] \approx \frac{1}{N} \sum_{i=1}^{N} f(x^i) Ex∼p[f(x)]≈N1i=1∑Nf(xi)
重要抽样的基本思想是选择一种更合适的样本生成器,使得其能够更好地反映目标概率分布。这个样本生成器被称为“权重函数”,它的值越大,表示该样本越有可能出现在最终的结果中。因此,通过对样本进行加权处理,可以有效地减少不必要的计算量。
具体来说,假设我们想要计算某个函数f(x)在[0,1]上的积分。我们可以使用重要抽样算法,首先选择一个权重函数w(x),然后从该区间内随机抽取一些样本x1,x2,…,xn,并计算它们对应的权重值w1,w2,…,wn。最后,我们将这些样本按照权重值加权平均,得到一个近似的积分值:
I ≈ w 1 f ( x 1 ) + w 2 f ( x 2 ) + ⋯ + w n f ( x n ) w 1 + w 2 + ⋯ + w n I \approx \frac{w_1 f(x_1) + w_2 f(x_2) + \cdots + w_n f(x_n)}{w_1 + w_2 + \cdots + w_n} I≈w1+w2+⋯+wnw1f(x1)+w2f(x2)+⋯+wnf(xn)
其中,I为实际需要求解的积分值。
选择合适的权重函数非常重要。如果选择不当,可能会导致重要的部分没有被充分考虑,从而影响计算结果的准确性。因此,在实际应用中,需要根据具体情况仔细选择权重函数,并进行多次试验以确保结果的可靠性。
E x ∼ p [ f ( x ) ] ≈ 1 N ∑ i = 1 N f ( x i ) E_{x \sim p}[f(x)] \approx \frac{1}{N} \sum_{i=1}^{N} f(x^i) Ex∼p[f(x)]≈N1i=1∑Nf(xi)
- x i x^i xi is sampled from p ( x ) p(x) p(x)
- p ( x ) p(x) p(x)可以看作是概率分布
如果我们只能从 q ( x ) q(x) q(x)采样,而不能从 p ( x ) p(x) p(x)进行采样,需要进行如下的变换。
E x ∼ p [ f ( x ) ] = ∫ f ( x ) p ( x ) d x = ∫ f ( x ) p ( x ) q ( x ) q ( x ) d x = E x ∼ q [ f ( x ) p ( x ) q ( x ) ] \begin{align*} E_{x \sim p}[f(x)] &= \int f(x) p(x) dx \\ &= \int f(x) \frac{p(x)}{q(x)} q(x) dx \\ &= E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] \end{align*} Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]



重要性采样的核心思想是,当我们难以直接从目标分布 p ( x ) p(x) p(x)中采样时,可以通过从另一个易于采样的提议分布 q ( x ) q(x) q(x)中采样,并使用重要性权重 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)
对样本进行加权,来近似计算目标分布下的期望值。
这种方法在强化学习、贝叶斯推断、蒙特卡洛模拟等领域有广泛应用,特别是在处理复杂或高维分布时,能够显著提高采样效率和估计精度。
E x ∼ p [ f ( x ) ] = E x ∼ q [ f ( x ) p ( x ) q ( x ) ] Var x ∼ p [ f ( x ) ] Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] \begin{align*} E_{x \sim p}[f(x)] &= E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] \\ \text{Var}_{x \sim p}[f(x)] &\quad \text{Var}_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] \end{align*} Ex∼p[f(x)]Varx∼p[f(x)]=Ex∼q[f(x)q(x)p(x)]Varx∼q[f(x)q(x)p(x)]
V a r Var Var表示了两个分布下的方差之间的关系。
VAR [ X ] = E [ X 2 ] − ( E [ X ] ) 2 \boxed{ \begin{aligned} \text{VAR}[X] &= E[X^2] - (E[X])^2 \end{aligned} } VAR[X]=E[X2]−(E[X])2
定义了随机变量 x x x的方差的计算公式,即方差等于平方的期望减去期望的平方。
Var x ∼ p [ f ( x ) ] = E x ∼ p [ f ( x ) 2 ] − ( E x ∼ p [ f ( x ) ] ) 2 Var x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 = E x ∼ p [ f ( x ) 2 p ( x ) q ( x ) ] − ( E x ∼ p [ f ( x ) ] ) 2 \begin{align*} \text{Var}_{x \sim p}[f(x)] &= E_{x \sim p}[f(x)^2] - \left(E_{x \sim p}[f(x)]\right)^2 \\ \text{Var}_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] &= E_{x \sim q}\left[\left(f(x) \frac{p(x)}{q(x)}\right)^2\right] - \left(E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]\right)^2 \end{align*} \\ = E_{x \sim p}\left[f(x)^2 \frac{p(x)}{q(x)}\right] - \left(E_{x \sim p}[f(x)]\right)^2 Varx∼p[f(x)]Varx∼q[f(x)q(x)p(x)]=Ex∼p[f(x)2]−(Ex∼p[f(x)])2=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2
详细展示了如何计算从分布 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)中采样的函数 f ( x ) f(x) f(x)的方差。
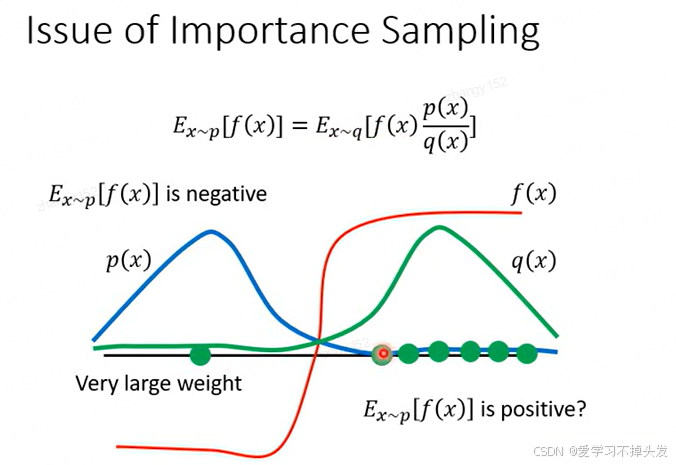
如果是 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)的顺序不一致,那么上面图片中的等式可能不成立。
如上述图片所示,当在左侧的时候,p(x) > q(x),计算得到等式左侧的值是负值。当在右侧的时候,q(x) < p(x),采样计算得到的等式左侧的值看起来是正值,会导致左右两侧不同。
所以在采用importance sampling的时候,采用的两个分布不同,会导致等式不成立。
Off-policy公式





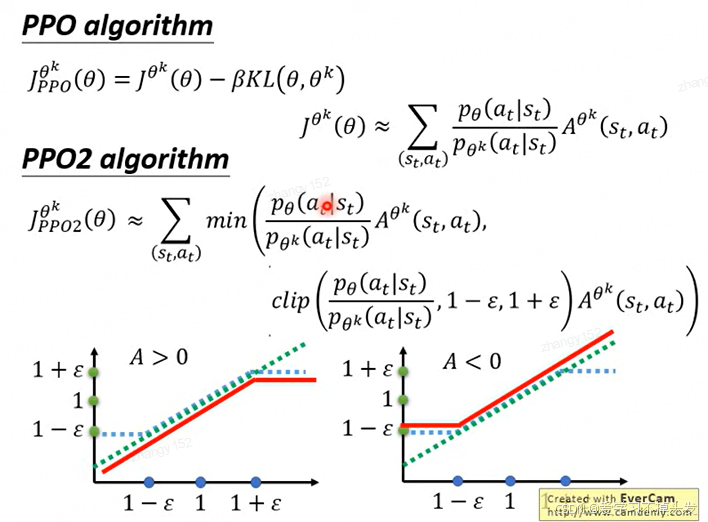
PPO algorithm

更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)