
强化学习之迷宫Q-Learning实践笔记——入门篇
我们以走迷宫小游戏为例开始学习深度学习,迷宫样例原型来自“莫烦PYTHON”,系统的梳理强化学习和Q-learning基础知识,并结合代码实践跟踪行为轨迹和Q-Table。
众所周知,在2016年,当AlphaGO战胜了世界围棋冠军李世石之后,整个业界都为之振奋,越来越多的学者意识到强化学习在人工智能领域将是更趋近人类智能的研究方向,非常令人激动。强化学习是一个非常有趣且值得广泛研究的领域,强化学习技术的进步及其在现实各领域的应用势必将取得更大的成功。
1. 迷宫游戏
我们以简单的走迷宫小游戏为例开始,样例原型来自“莫烦PYTHON”的强化学习,如下图所示,让探索机器人(红色方框)学会走迷宫,图中黄色圆圈表示是天堂出口(reward为1),黑色方框表示是地狱陷阱(reward为-1)。我们给予机器人的引导只有奖励,如果走到天堂出口奖励给1分,继续重新开始学习,如果走到地狱陷阱处罚扣1分,重新开始学习,其他得零分持续走,行动为“上、下、左、右”四个方向移动。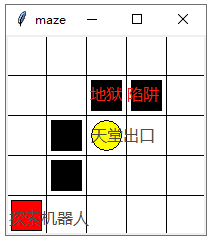
接下来我们将使用强化学习中的Q-Learning算法,训练探索机器人学会走迷宫。大多数强化学习(英文简称RL)是由 奖励(reward)为导向的,所以定义reward是RL中比较重要的一点。
2. 关于强化学习的基础
2.1. 什么是强化学习
强化学习是机器学习里面的一个分支。它强调基于环境而探索行动、学习,以取得最大化的预期收益。其灵感来源于心理学中的行为主义理论,既有机体如何在环境给予的奖励或者惩罚的刺激下,逐步形成对刺激的预期,产生能够最大利益的习惯性行为。简而言之,强化学习就是让机器学着如何在环境中通过不断的试错、尝试,学习、累积经验拿到高分.
2.2. 强化学习基本结构
强化学习致力于控制一个计算机智能体,使之在未知环境中完成任务目标。
下图中给出强化学习基本结构。在一个未知“迷宫”环境中,计算机算法软件(探索机器人控制大脑)基于自身的控制策略行动。基本结构包括:
(1)智能体(Agent):探索机器人大脑,智能体的结构可以是一个神经网络,也可以是一个简单的算法,智能体的输入通常是状态(State),输出通常是策略(Policy);
(2)动作(Actions):是指动作空间。对于机器人玩迷宫游戏,只有上下左右移动方向可行动,那Actions就是上、下、左、右;
(3)状态(State):就是智能体的输入,机器人在迷宫中的位置;
(4)奖励(Reward):机器人进入某个状态时,能给智能体带来正奖励或者负奖励;
(5)环境(Environment):就是指机器人所走的迷宫,能接收action,返回state和reward。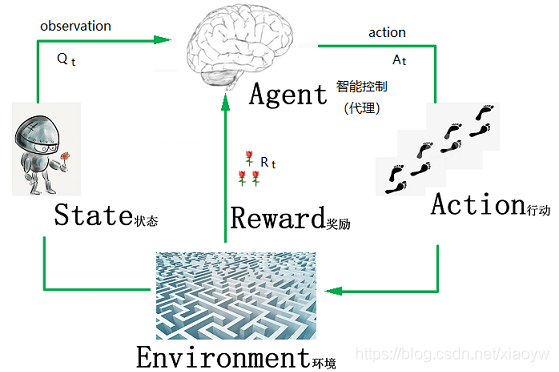
2.3. 强化学习决策过程
马尔科夫决策过程(MDP)为求解强化学习问题提供了数学框架。几乎所有的强化学习问题都可以建模为MDP。
在强化学习中,agent与environment按顺序在互动。在时刻 t 1 t_1 t1,agent会接收到来自环境的一个observation(观察),获取状态 s 1 s_1 s1,基于这个状态 s 1 s_1 s1,agent会做出动作 a 1 a_1 a1,然后这个动作作用在环境上,于是agent可以接收到一个奖赏 r t + 1 r_{t+1} rt+1,并且agent就会到达新的状态 s 2 s_2 s2,以此方式持续下去。所以,其实agent与environment之间的交互就是产生了一个序列,如下图所示。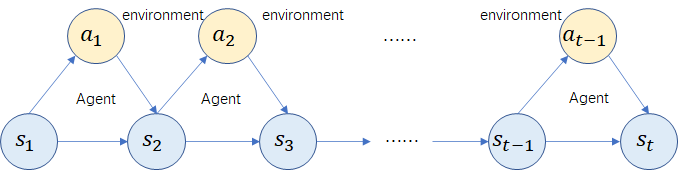
强化学习迷宫Q-Learning算法决策实现过程,就是马尔科夫决策过程(MDP)过程的实现,实践过程如下图所示。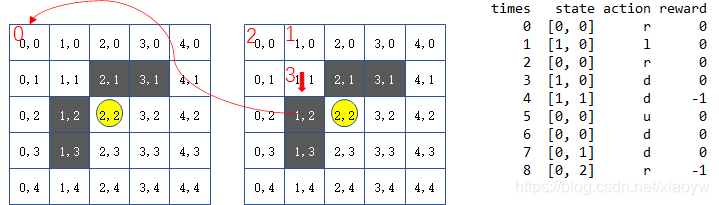
2.4. 强化学习基本要素
基于上述迷宫的案例,我们可以整理出思路里面出现的强化学习要素:
2.4.1. 马尔可夫决策过程(MDP)模型要素
马尔可夫决策过程(MDP)包含5个模型要素,状态(state)、动作(action)、策略(policy)、奖励(reward)和回报(return):
(1)环境的状态 s s s,状态是对环境的描述,正如机器人在迷宫中的位置,也就是 t t t时刻环境的状态 s t s_t st,体现为环境状态集中的某一个状态,在智能体做出动作后,状态会发生变化;MDP所有状态的集合是状态空间,状态空间可以是离散或连续的。
S = s 1 , s 2 , s 3 , . . . . . . , s π S = {s_1,s_2,s_3,......,s_π} S=s1,s2,s3,......,sπ
(2)机器人的动作 A A A, 动作是对智能体行为的描述,是智能体决策的结果。 t t t时刻机器人采取的动作 A t A_t At是它的动作集中某一个动作;MDP所有可能动作的集合是动作空间,动作空间可以是离散或连续的。
A = a 1 , a 2 , a 3 , . . . . . . , a π A = {a_1,a_2,a_3,......,a_π} A=a1,a2,a3,......,aπ
(3)环境的奖励 R R R,奖励是智能体给出动作后,环境对智能体的反馈。是当前时刻状态、动作和下个时刻状态的标量函数。 t t t时刻机器人在状态 s t s_t st采取的动作 a t a_t at对应的奖励 r t + 1 r_{t+1} rt+1,会在 t + 1 t+1 t+1时刻得到;
R = R ( s t , a t , s t + 1 ) R = R(s_t,a_t,s_{t+1}) R=R(st,at,st+1)
(4)机器人的策略(policy) π π π,策略是指代表机器人采取动作的依据,即机器人会依据策略 π π π来选择动作。最常见的策略表达方式是一个条件概率分布 π ( a ∣ s ) π(a|s) π(a∣s), 即在状态 s s s时采取动作 a a a的概率。即 π ( a ∣ s ) = P ( A t = a ∣ s t = s ) π(a|s)=P(A_t=a|s_t=s) π(a∣s)=P(At=a∣st=s),此时概率大的动作被机器人选择的概率较高。
(5)环境的状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型,即在状态 s s s下采取动作 a a a,转到下一个状态 s ′ s′ s′的概率,表示为 P s s ′ a P^a_{ss′} Pss′a。
2.4.2. 贝尔曼方程及其要素
贝尔曼方程(Bellman Equation)也被称作动态规划方程(Dynamic Programming Equation),用于求解马尔可夫决策过程(MDP)过程。
贝尔曼方程是动态规划(Dynamic Programming)这些数学最佳化方法能够达到最佳化的必要条件。此方程把“决策问题在特定时间怎么取值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。借此这个方式把动态最佳化问题变成简单的子问题,而这些子问题遵守从贝尔曼所提出来的“最优原理”。
几乎所有的可以用最优控制理论(Optimal Control Theory)解决的问题也可以通过分析合适的贝尔曼方程得到解决。然而,贝尔曼方程通常指离散时间(discrete-time)最佳化问题的动态规划方程。
贝尔曼方程的三个要素,策略函数、状态价值函数、状态——行为值函数(Q函数)(简称为动作价值函数)。
(1)回报(return),回报是奖励随时间步的积累,在引入轨迹的概念后,回报也是轨迹上所有奖励的总和。
G = ∑ t = 0 π − 1 r t + 1 G = \sum_{t=0}^{π-1}r_{t+1} G=t=0∑π−1rt+1
(2)折扣因素,奖励衰减因子( γ γ γ),在 [ 0 , 1 ] [0,1] [0,1]之间。如果为0,则是贪婪法,即价值只由当前延时奖励决定,如果是1,则所有的后续状态奖励和当前奖励一视同仁。大多数时候,我们会取一个0到1之间的数字,即当前延时奖励的权重比后续奖励的权重大。
折扣因素主要作用:
- 避免连续任务造成回报 G G G无限大;
- 区分即时奖励和未来奖励的重要程度。
(3)状态值函数 V π ( s ) V_π(s) Vπ(s)
机器人在策略 π π π和状态 s s s时,采取行动后的状态所处的最佳的(程度)价值(value),一般用 V π ( s ) Vπ(s) Vπ(s)表示,是一个期望函数。
价值函数 V π ( s ) V_π(s) Vπ(s)一般可以表示为下式,不同的算法会有对应的一些价值函数变种,但思路相同:
V π ( s ) = E π ( r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . ∣ s t = s ) V_π(s)=E_π(r_{t+1}+γr_{t+2}+γ^2r_{t+3}+...|s_t=s) Vπ(s)=Eπ(rt+1+γrt+2+γ2rt+3+...∣st=s)
(4)状态——行为值函数(Q函数)
机器人在策略 π π π和状态 s s s时,采取行动后的行为的所处的最佳的程度,一般用 Q π ( s ) Q_π(s) Qπ(s)表示,也是一个期望函数。
根据策略 π π π从状态 s s s开始采取行动 a a a所获得的期望回报,也就是贝尔曼方程,如下式所述:
Q π ( s , a ) = E π [ ∑ k = 0 ∞ γ k r t + k + 1 ∣ s t = s , a t = a ] Q_π(s,a)=E_π[\sum_{k=0}^\infty γ^kr_{t+k+1}|s_t=s,a_t = a] Qπ(s,a)=Eπ[∑k=0∞γkrt+k+1∣st=s,at=a]
(5)探索率 ϵ ϵ ϵ,这个比率主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率ϵ不选择使当前轮迭代价值最大的动作,而选择其他的动作。
2.5. 强化学习常用算法及分类
强化学习算法通常有多种分类方法,按照有无模型分为有模型和无模型方法,按照学习目标分为基于价值、基于策略和基于Actor-Critic框架的方法,按照更新方式分为蒙特卡洛和时间差分方法,按照采样策略和优化策略是否相同分为在线和离线方法等。
2.5.1. 学习目标分类
基于价值的方法通常优化动作值函数Q,优点在于样本效率高、值函数估计方差较低以及不容易陷入局部最优,但它通常不能处理连续动作空间问题,DQN中的Ꜫ-greedy策略和取最大操作也会导致过估计问题。基于价值的方法中有代表性的包括Q-learning、DQN及其相关改进算法:优先经验回放(使用TD error来为数据赋予不同的权重来提升样本效率)。
如下表,列出部分常用基于值函数的RL算法,详见[7]。
| 强化学习算法 | 策略类型 | 动作空间 | 年份 | 论文题目 |
|---|---|---|---|---|
| Q-learning | off-policy | discrete | 1992 | Q-learning |
| SARSA | on-policy | discrete | 1994 | Online Q-learning using connectionist systems |
| REINFORCE | on-policy | discrete or continuous | 1988 | On the use of backpropagation in associative reinforcement learning |
| DQN | off-policy | discrete | 2015 | Human-level control through deep reinforcement learning |
2.5.2. 有无模型分类
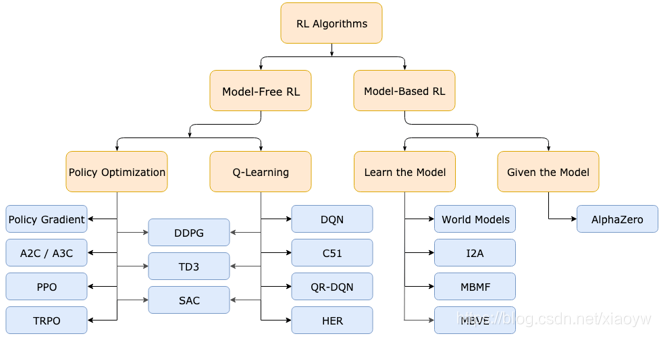
3. Q-Learning算法
3.1. 时间差分学习
时序差分学习 (temporal-difference learning, TD learning):指从采样得到的不完整的状态序列学习,该方法通过合理的 bootstrapping,先估计某状态在该状态序列(episode)完整后可能得到的 return,并在此基础上利用累进更新平均值的方法得到该状态的价值,再通过不断的采样来持续更新这个价值。
时间差分(TD) 学习是蒙特卡罗(MC) 思想和动态规划(DP) 的结合。与MC方法 类似,TD方法 可以直接从经验中学习,而不需要知道环境模型。与 DP 类似,TD方法基于其他学习的估计值来更新估计值,而不用等待最终的结果。首先从预测(prediction)问题出发,建立给定策略 [公式] 对应的值函数 [公式] 的估计。对于控制(control)问题,DP、TD以及MC方法都使用了 广义策略迭代(GPI)的某种形式。这些方法中的不同点主要体现在解决预测问题方面。
3.2. Q-Learning
Q-learning一种TD(Time Difference)方法,也是一种Value-based的方法。所谓Value-based方法,就是先评估每个action的Q值(Value),再根据Q值求最优策略 π ( a ∣ s ) π(a|s) π(a∣s)的方法。
n e w Q ( s , a ) = Q ( s , a ) + α [ R ( s , a ) + γ m a x a ′ Q ′ ( s ′ , a ′ ) − Q ( s , a ) ] newQ(s,a)=Q(s,a)+\alpha[R(s,a)+\gamma max_{a'}Q'(s',a')-Q(s,a)] newQ(s,a)=Q(s,a)+α[R(s,a)+γmaxa′Q′(s′,a′)−Q(s,a)]
在Q -值函数包含了两个可以操作的因素。
首先是一个学习率 learning rate( α \alpha α),它定义了一个旧的Q值将从新的Q值哪里学到的新Q占自身的多少比重。值为0意味着代理不会学到任何东西(旧信息是重要的),值为1意味着新发现的信息是唯一重要的信息。
下一个因素被称为折扣因子discount factor( γ \gamma γ),它定义了未来奖励的重要性。值为0意味着只考虑短期奖励,其中1的值更重视长期奖励。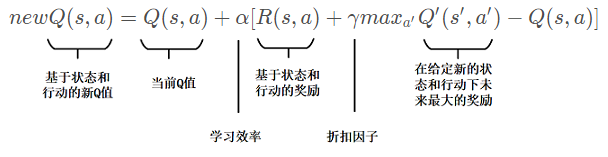
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
公式可以变换为:
n e w Q ( s , a ) = ( 1 − α ) Q ( s , a ) + α [ R ( s , a ) + γ m a x a ′ Q ′ ( s ′ , a ′ ) ] newQ(s,a)=(1-\alpha)Q(s,a)+\alpha[R(s,a)+\gamma max_{a'}Q'(s',a')] newQ(s,a)=(1−α)Q(s,a)+α[R(s,a)+γmaxa′Q′(s′,a′)]
因此:
- ( 1 − α ) Q ( s , a ) (1-\alpha)Q(s,a) (1−α)Q(s,a)是指旧Q值在 n e w Q ( s , a ) newQ(s,a) newQ(s,a)之中所占的比重;
- α [ R ( s , a ) + γ m a x a ′ Q ′ ( s ′ , a ′ ) ] \alpha[R(s,a)+\gamma max_{a'}Q'(s',a')] α[R(s,a)+γmaxa′Q′(s′,a′)]是指为本次行动学习到的奖励(行动本身带来的奖励和未来潜在的奖励)。
3.3. Q-table
Q-Learning最终目标是获得回报 G G G,这样需要保存训练过程中的轨迹上所有奖励的总和。因此设计了Q-table用于存储 Q ( s , a ) Q(s,a) Q(s,a),创建一个二维表,可以存储每个state中每个action的未来预期的最大奖励值。这样我们可以知道每个state下的最佳action。
如下图迷宫,每个state(这里指的是方块)允许四种可能性的action,即上、下、左、右。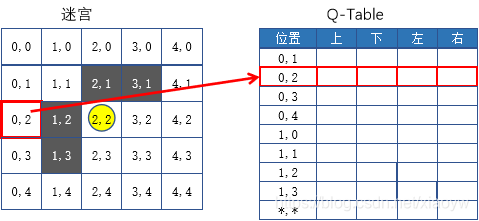
这个table就叫做Q-table(Q指的是这个action的预期奖励)。迷宫的Q-table中的列有四个action(上下左右行为),行代表state,每个单元格的值将是特定状态(state)和行动(action)下未来预期的最大奖励值。
4. 迷宫游戏代码结构及解读
通过上述背景知识的介绍,下面我开始解读来自“莫烦PYTHON”代码。
4.1. 代码结构
迷宫游戏代码有三部分组成:
- maze_env 是迷宫环境,基于Python标准GUI库Tkinter开发
- RL_brain 是Q-Learning的核心实现
- run_this 是控制执行算法的代码
代码使用工具包比较少、简洁,主要有pandas和numpy,以及python自带的Tkinter 。其中,pandas用于Q-table的数据存储及处理。
在run_this中,首先我们先 import 两个模块,maze_env 是我们的迷宫环境模块,maze_env 模块我们可以不深入研究,如果你对编辑环境感兴趣,可以去修改迷宫的大小和布局。RL_brain模块是 RL 核心的大脑部分。
4.2. 关于迷宫环境
Tkinter 是 Python 的标准 GUI 库。Python 使用 Tkinter 可以快速的创建 GUI 应用程序。
由于 Tkinter 是内置到 python 的安装包中、只要安装好 Python 之后就能 import Tkinter 库、而且 IDLE 也是用 Tkinter 编写而成、对于简单的图形界面 Tkinter 还是能应付自如。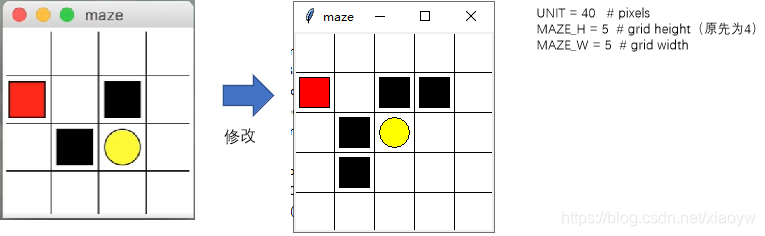
改造后迷宫代码如下所示,增加两个陷阱hell3、hell4,以及终止(terminal)条件。
import numpy as np
import time
import sys
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 5 # grid height
MAZE_W = 5 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'r', 'l']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 3, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# hell
hell3_center = origin + np.array([UNIT, UNIT * 3])
self.hell3 = self.canvas.create_rectangle(
hell3_center[0] - 15, hell3_center[1] - 15,
hell3_center[0] + 15, hell3_center[1] + 15,
fill='black')
# hell
hell4_center = origin + np.array([UNIT * 2, UNIT])
self.hell4 = self.canvas.create_rectangle(
hell4_center[0] - 15, hell4_center[1] - 15,
hell4_center[0] + 15, hell4_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # left
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # right
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2), self.canvas.coords(self.hell3), self.canvas.coords(self.hell4)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
def update():
for t in range(10):
s = env.reset()
while True:
env.render()
a = 1
s, r, done = env.step(a)
if done:
break
if __name__ == '__main__':
env = Maze()
env.after(100, update)
env.mainloop()
4.3. 强化学习
源代码表达很清晰,简单说明如下:
- actions: 行为
- learning_rate: 学习率, 来决定这次的误差有多少是要被学习的
- reward_decay: 是折扣因子,表示时间的远近对回报的影响程度,为0表示之看当前状态采取行动的reward
- e_greedy: 是用在决策上的一种策略, 比如 epsilon = 0.9 时, 就说明有90% 的情况我会按照 Q 表的最优值选择行为, 10% 的时间使用随机选行为
上述参数,在类QLearningTable初始化时,默认设置,感兴趣可以自行修改体验。
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.uniform() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
4.4. 运行及算法体验
我们看到运行代码也比较简单,如何体验算法的魅力呢,在此做了些输出改造:
(1)源代码中state用矩形四角坐标表示,读起来稍微复杂些,我改为二维矩阵坐标,易于直接在表格上表达;
(2)输出跟踪行为轨迹和Q_table,主要是通过构造pandas表输出到csv文件中。
- action.csv 行为轨迹,包括state、action、reward、Q值
- q_table.csv 最终Q-table
from study.RLearning.maze_env import Maze
from study.RLearning.RL_brain import QLearningTable
import pandas as pd
def update():
# 跟着行为轨迹
df = pd.DataFrame(columns=('state','action_space','reward','Q','action'))
# 转换为迷宫坐标(x,y)
def set_state(observation):
p = []
p.append(int((observation[0]-5)/40))
p.append(int((observation[1]-5)/40))
return p
for episode in range(100):
# initial observation
observation = env.reset()
observation = set_state(observation)
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
if observation_ != 'terminal':
observation_ = set_state(observation_)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
q = RL.q_table.loc[str(observation),action]
df = df.append(pd.DataFrame({'state':[observation],'action_space':[env.action_space[action]],'reward':[reward],'Q':[q],'action':action}), ignore_index=True)
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
df.to_csv('action.csv')
RL.q_table.to_csv('q_table.csv')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
运行情况:
(1)输出行为轨迹结果(截取部分)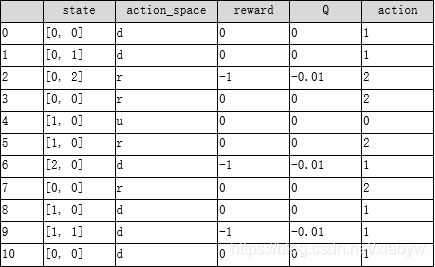
(2)输出Q_table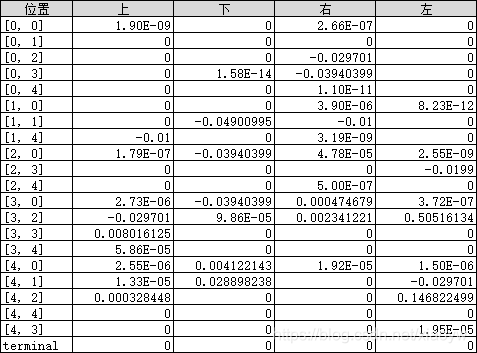
5. 结果分析及展望
5.1. 结果分析
我们主要是看Q_table里,在状态state下行为的的预期奖励值,取每行(状态)预期最大的值,根据行为分析落实轨迹,标示如下结果。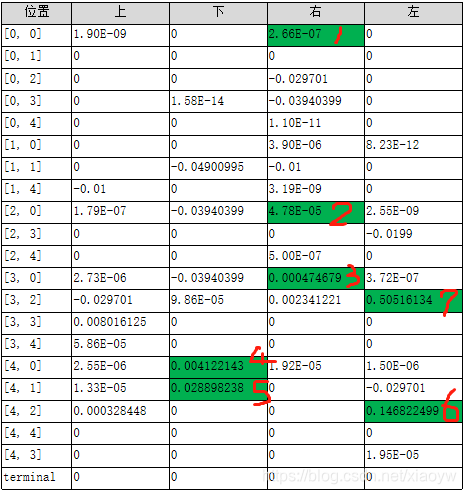
从Q_table分析,如果状态数为 n n n,行为数为 m m m,则Q_table的容量大小将为 n × m n \times m n×m。
Q-Learning方法很好的解决了这个迷宫问题,但是这终究只是一个小问题(状态空间和动作空间都很小),实际情况下,大部分问题都是有巨大的状态空间或者动作空间,想建立一个Q表,将需要巨量的内存,往往是不现实的,而且数据量和时间开销也是个难题。
5.2. 展望
对于实用型的推荐算法,例如针对加油站将流失的客户,精准发优惠券,维系客户的场景,状态空间和动作空间都将比较大,接下来将结合深度强化学习等算法研究。
深度强化学习(Deep Reinforcement Learning,DRL)本质上属于采⽤神经⽹络作为值函数估计器的⼀类⽅法,其主要优势在于它能够利⽤深度神经⽹络对状态特征进⾏⾃动抽取,避免了⼈⼯定义状态特征带来的不准确性,使得 Agent 能够在更原始的状态上进⾏学习。
由于编者水平有限,欢迎交流讨论。
参考:
[1].《Nuts & Bolts of Reinforcement Learning: Model Based Planning using Dynamic Programming》 Analytics Vidhya ,ANKIT CHOUDHARY, SEPTEMBER 18, 2018
[2].《强化学习(一)模型基础》 博客园 ,刘建平Pinard ,2018年7月
[3].《强化学习:Q-learning由浅入深:简介1》 知乎 ,wiliken ,2018年4月
[4].《强化学习 Q—learning(python 代码)》 CSDN博客 , qq_42105426 ,2019年3月
[5].《强化学习及Python代码示例》 CSDN博客 , 夏轻 , 2017年7月
[6].《强化学习 — 马尔科夫决策过程(MDP)》 博客园 ,jsfantasy ,2020年6月
[7].《强化学习(Reinforcement Learning)知识整理》 知乎, 我勒个矗 ,2019年10月
[8].《强化学习算法分类》 CSDN博客 ,Fox_Alex , 2020年11月
[9].《Python强化学习实战:应用OpenAI Gym和TensorFlow精通强化学习和深度强化学习》机械工业出版社 ,连晓峰译,2019年1月
[10].《强化学习(Q-Learning,Sarsa)》 CSDN博客 ,上杉翔二 ,2019年3月
[11].《强化学习Q-leaning算法之走迷宫》 CSDN博客 ,xckkcxxck ,2018年11月
[12].《常见强化学习方法总结》 知乎 , marsggbo ,2019年12月
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)