
为什么XGBoost在绝大多数情况下都比深度学习算法效果好?甚至秒杀各种新提出的算法!原创未发表!!基于非线性二次分解的Ridge-RF-XGBoost时间序列预测
摘要:研究表明,XGBoost在结构化数据的回归与分类任务中持续优于深度学习模型。通过构建分段常数函数,XGBoost能有效捕捉特征间的高阶交互,而无需复杂特征工程。相比DNN对数据规模和质量的高要求,XGBoost具有更强的泛化能力、鲁棒性和可解释性。实际应用中,XGBoost在Kaggle竞赛和工业场景中占据主导地位。研究还提出了一种基于非线性二次分解的Ridge-RF-XGBoost混合模型

近年来,尽管深度学习在图像识别、自然语言处理等领域取得了显著成功,但在结构化数据(tabular data)上的回归与分类任务中,梯度提升树模型——特别是XGBoost(eXtreme Gradient Boosting)——在绝大多数实际应用场景中仍展现出卓越的预测性能。
随着深度学习技术的迅猛发展,研究者普遍认为神经网络具有强大的函数逼近能力,能够自动学习复杂非线性关系。然而,在Kaggle等数据科学竞赛平台以及工业界的实际应用中(如能源、金融风控、医疗诊断、客户行为预测等),基于决策树的集成方法,尤其是XGBoost,长期占据主导地位。Chen & Guestrin(2016)提出的XGBoost不仅在精度上屡创佳绩,还在训练速度和内存效率方面进行了高度工程优化,
结构化数据通常由数值型或类别型特征组成,特征间关系多为局部、非连续且存在交互效应。XGBoost通过构建分段常数函数(piecewise constant functions)来建模这些关系,能够有效捕捉特征间的高阶交互,而无需显式特征工程。相比之下,深度神经网络(DNN)依赖于连续可微的激活函数,在处理稀疏、离散或非平滑特征时往往需要复杂的嵌入或归一化策略,且容易过拟合小规模数据集。
XGBoost在目标函数中引入了L1(Lasso)和L2(Ridge)正则项,分别控制叶子节点权重的稀疏性和幅度。这种显式正则化机制显著提升了模型在有限样本下的泛化能力,而大多数标准DNN缺乏类似的内置正则化结构(除非额外引入Dropout、权重衰减等),在小到中等规模数据集上容易过拟合。
XGBoost在分裂节点时自动学习缺失值的最佳默认方向,无需预处理填充。同时,由于其基于排序的分裂准则(而非距离度量),对异常值不敏感。而DNN对输入尺度敏感,异常值可能严重影响梯度更新,需依赖标准化、裁剪等预处理手段。
XGBoost仅有少量关键超参数(如学习率、最大深度、子采样率等),且对超参变化相对稳健。相比之下,DNN的架构设计(层数、神经元数、激活函数、优化器等)组合空间庞大,调参成本高,且“黑箱”特性限制了其在高可信度场景的应用。XGBoost支持特征重要性、SHAP值等解释工具,增强了模型透明度。
多项大规模基准研究表明XGBoost在结构化数据任务中的优势:
- Grinsztajn et al. (2022): 在《Why do tree-based models still outperform deep learning on tabular data?》中对超过30个真实世界数据集进行系统评估,发现XGBoost、LightGBM和CatBoost在绝大多数情况下显著优于包括TabNet、DeepFM、MLP在内的深度学习模型。
- Kaggle竞赛统计:据Kaggle官方统计,在涉及结构化数据的比赛中,超过70%的获奖方案使用了XGBoost或其变体。
- 计算效率:XGBoost支持并行化、缓存优化和外存计算,在单机环境下训练速度远快于同等精度的DNN,尤其适合快速迭代开发。
尽管近年来出现了如TabNet、NODE、SAINT等专为表格数据设计的神经网络架构,但其性能仍难以稳定超越XGBoost。主要原因包括:
- 数据规模不足:DNN通常需要大量数据才能发挥其容量优势,而多数结构化数据集样本量有限(<10⁵);
- 特征异质性:混合类型特征(数值+类别)难以被统一表示;
- 训练不稳定性:DNN对学习率、初始化敏感,收敛行为不如树模型稳定。
XGBoost之所以在回归与分类任务中“秒杀”众多新算法,根本原因在于其针对结构化数据的建模范式与工程实现高度契合实际需求。它在模型表达力、泛化能力、鲁棒性、效率和可解释性之间取得了优异平衡。尽管深度学习在特定领域展现出潜力,但在通用结构化数据建模任务中,XGBoost仍是当前最可靠、高效且实用的选择。未来研究应聚焦于融合树模型与神经网络优势的混合架构,而非简单替代。
为什么XGBoost在绝大多数情况下都比深度学习算法效果好?甚至秒杀各种新提出的算法!
程序名称:基于非线性二次分解的Ridge-RF-XGBoost时间序列预测
实现平台:python—Jupyter Notebook
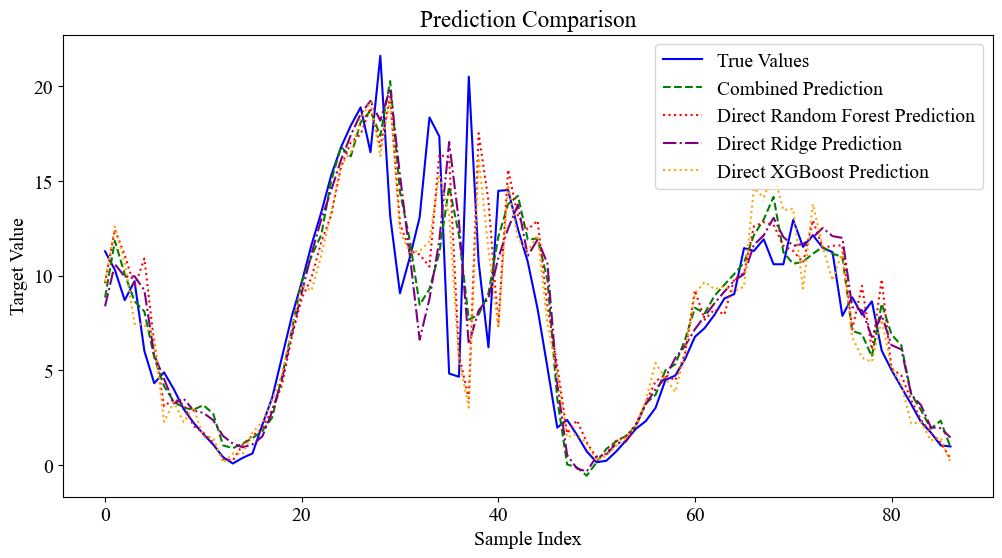
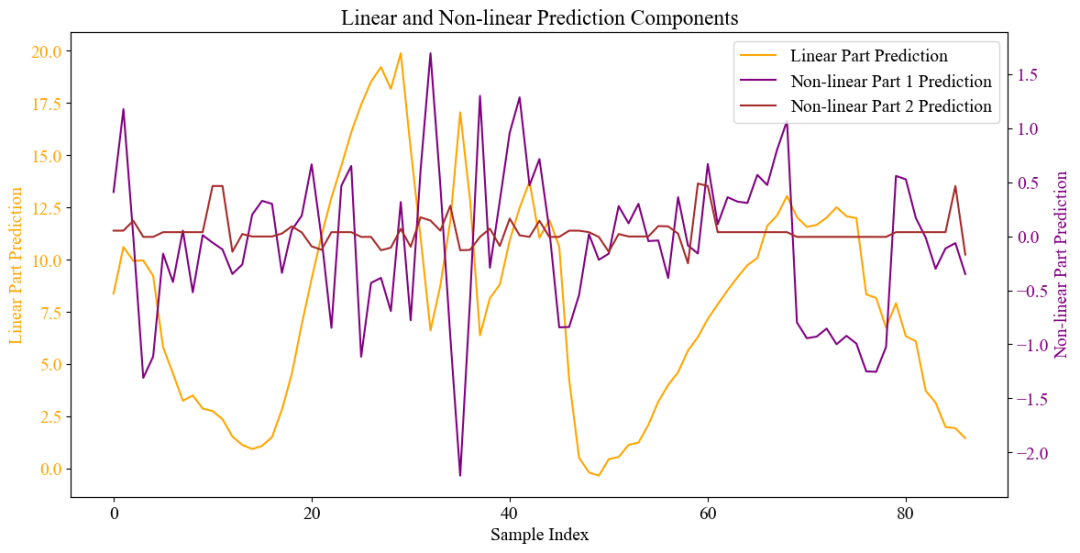
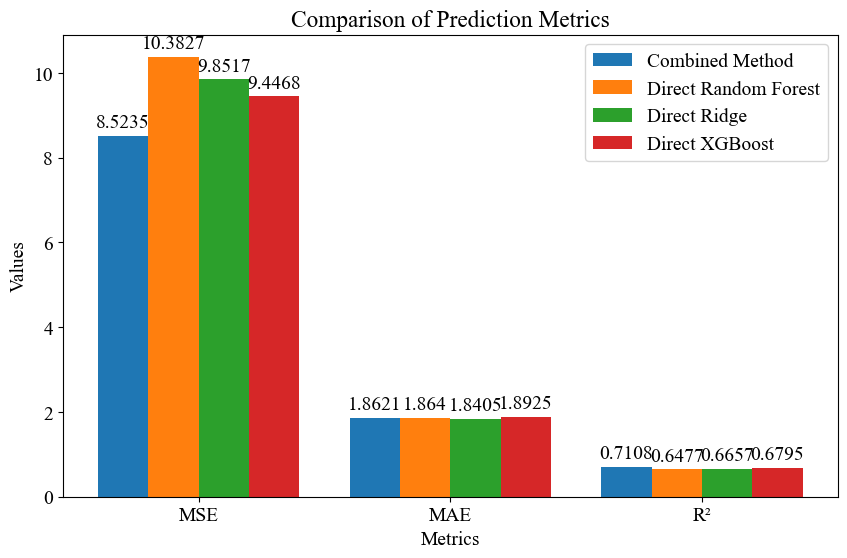
代码简介:构建了基于线性-非线性1次分解-非线性2次分解的岭回归(Ridge)-随机森林(RF)-极端梯度提升(XGBoost)时间序列预测模型。将序列分解为线性部分、非线性部分1和非线性部分2。线性部分使用Ridge的线性拟合能力进行预测,非线性部分1使用随机森林的非线性拟合能力预测,非线性部分2使用非线性拟合能力更强的XGBoost预测,非线性部分算法使用网格搜索与交叉验证寻找最优的超参数组合。最终预测结果为三者之和。
通过将时间序列分解为线性部分和两个非线性部分,可以充分发挥不同模型的优势。线性部分由岭回归处理,非线性部分1由随机森林处理,非线性部分2由XGBoost处理。这种分解方式使得模型能够更全面地捕捉数据中的信息,提高预测精度。通过分解时间序列并分别建模,可以更精细地捕捉数据中的复杂模式。这种方法不仅提高了对周期性特征的捕捉能力,还增强了对非周期性特征的建模能力。在多个真实世界数据集上,这种分解方法实现了优于现有最先进方法的性能。
采用将时间序列数据分割成线性与非线性组件分别进行预测的方法,然后合并这两个预测结果以获得最终预测值。这样做可以最大化利用线性和非线性模型的长处。具体来说,线性模型擅长识别数据中的趋势和模式,而非线性模型则在应对复杂关系及波动方面表现出色。通过这种分解和综合的策略,不仅能提升预测准确性,还能提高模型的灵活性和稳定性。这种方法规避了单独使用一种模型时可能遇到的挑战,并且整合了两者的优点,特别适合用于含有显著趋势以及复杂变化的时间序列数据分析,从而达到更加精确和可信的预测效果。
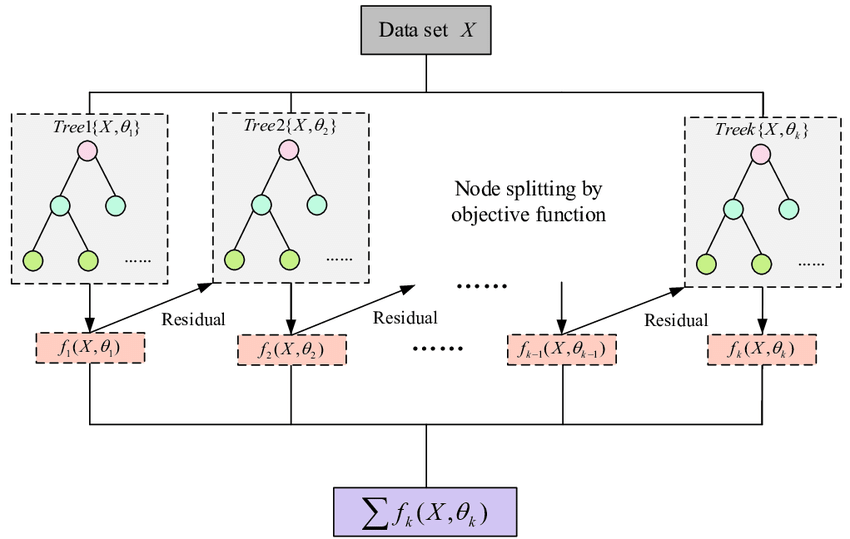
XGBoost在时间序列预测中具有显著优势。首先,其特征工程能力强,能自动捕捉复杂的非线性关系和特征交互,无需人工手动构建这些复杂关系。此外,XGBoost能够提供特征重要性评分,帮助识别对预测结果影响较大的变量,为特征选择和模型优化提供依据。其次,XGBoost的计算性能高效。支持多线程和分布式计算,在处理大规模时间序列数据时,可显著加快训练速度。同时,XGBoost在内存使用上进行了优化,能够高效处理大规模数据,避免因数据量过大导致的计算瓶颈。这些特性使得XGBoost在时间序列预测中不仅能够提升预测精度,还能提高计算效率,适用于各种复杂的时间序列预测场景,如金融市场预测、电力需求预测、交通流量预测等。
代码获取方式:原创未发表!!基于非线性二次分解的Ridge-RF-XGBoost时间序列预测
运行结果
Optimized Random Forest parameters: {'max_depth': 10, 'min_samples_split': 10, 'n_estimators': 100}
Optimized XGBoost parameters: {'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 100}
更多推荐
 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)