
基于强化学习DQN的无人机路径规划研究(Python代码实现)
💥💥💞💞❤️❤️💥💥博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。⛳️行百里者,半于九十。📋📋📋🎁🎁🎁。
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于强化学习DQN的无人机路径规划研究
一、强化学习DQN的基本原理
深度Q网络(DQN)是一种结合深度学习与Q学习的强化学习算法,通过神经网络近似Q值函数,解决高维状态空间下的决策问题。其核心机制包括:
- 神经网络架构:使用卷积层和全连接层提取环境特征,输出动作的Q值。典型结构包括2个卷积层(如3×3核、ReLU激活)和2个全连接层(如512神经元),通过Flatten层将特征转换为一维。
- 经验回放(Experience Replay) :存储历史状态-动作-奖励数据,随机采样训练,打破数据相关性,提升稳定性。
- 目标网络(Target Network) :独立更新目标网络参数,避免Q值估计波动,公式
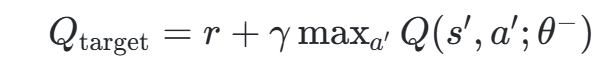
- 探索与利用平衡:采用ε-贪心策略,初期高ε值鼓励探索,后期逐渐降低以利用最优策略。
DQN的扩展如双DQN(Double DQN)和对抗DQN进一步提升了算法性能。
二、无人机路径规划的传统方法与挑战
- 传统方法:
- 经典算法:A*、Dijkstra等在静态环境中有效,但无法处理动态障碍和多目标优化。
- 人工势场法:易陷入局部最优,目标不可达或路径震荡问题显著。
- 挑战:
- 动态障碍物:需实时避障与重规划。
- 三维约束:飞行高度、最小转弯半径(如2m)、俯仰角限制(±30°)。
- 多目标优化:需平衡路径长度、能耗、安全性等冲突目标。
- 计算效率:传统算法在复杂环境中计算量指数增长,难以满足实时需求。
三、基于DQN的无人机路径规划现有研究案例
- 改进分层DQN:宁波大学团队提出加入激励层和动作层,提升Q值准确性,收敛速度提高20%以上。
- 对抗环境下的MPDA框架:结合威胁感知(如窃听和诱捕攻击),设计状态空间编码威胁信息,奖励函数优化数据覆盖与安全着陆,性能提升60%。
- 分布式协作DCDQN:东北大学在多无人机覆盖任务中,通过扩展状态空间和协作学习模式,减少任务时间并避免区域遗漏。
- 事件驱动E-DQN:利用事件流数据压缩环境信息,在AirSim模拟器中实现快速响应,规划速度较传统方法提升30%。
四、环境建模与状态空间设计
- 环境建模:
- 三维栅格化:将城市空间划分为网格,包含建筑物、障碍物分布。
- 动态障碍物建模:采用高斯-马尔可夫模型模拟障碍物移动轨迹。
- 状态空间:
- 无人机状态:位置(经纬度)、速度(200 m/s)、剩余能量、与目标点相对距离。
- 环境感知:障碍物位置(LIDAR检测)、禁飞区、风速等动态参数。
- 动作空间:
- 离散动作:调整飞行方向(±10°偏航角)、高度(±50m)、速度(加速/减速)。
- 连续动作:通过Actor-Critic架构实现平滑控制。
五、奖励函数设计策略
- 稀疏奖励:仅到达目标时给予正奖励,适用于简单任务但收敛慢。
- 密集奖励:
- 距离引导:奖励随无人机与目标距离缩短而增加,惩罚碰撞障碍物。
- 人工势场结合:引力(目标)和斥力(障碍物)加权,公式为 R=kgoal⋅dgoal−1+kobs⋅dobs−2R=kgoal⋅dgoal−1+kobs⋅dobs−2 。
- 自适应奖励:根据障碍物距离动态调整惩罚系数,平衡避障与路径效率。
- 多任务奖励:在数据收集中同时优化任务完成率与能耗,如 R=α⋅数据量−β⋅能耗R=α⋅数据量−β⋅能耗 。
六、收敛性与泛化性优化方法
- 收敛性提升:
- 双重网络架构:双DQN分离动作选择与评估,减少Q值高估。
- 噪声网络(NoisyNet) :在权重中添加高斯噪声,增强探索能力。
- 优先级经验回放(PER) :按TD误差优先级采样,加速关键经验学习。
- 泛化性增强:
- 迁移学习:在模拟环境预训练,微调适应真实场景。
- 域随机化:随机化障碍物分布、风速等参数,提升模型鲁棒性。
七、实验场景与评估指标
- 实验设置:
- 模拟环境:20 km×20 km地图,含圆柱形障碍物(半径随机),无人机速度200 m/s,最小安全距离200 m。
- 训练参数:学习率0.0001,经验池容量10^5,批量大小64,折扣因子γ=0.99。
- 评估指标:
- 路径质量:长度、平滑度(转弯角度)、安全性(碰撞次数)。
- 算法效率:收敛速度(训练步数)、计算耗时(ms/step)。
- 泛化能力:在未知环境中的成功率和路径稳定性。
八、未来研究方向
- 混合架构:结合规则推理(如人工势场)与深度学习,提升复杂环境适应性。
- 多模态感知:融合视觉、雷达等多源数据,增强环境理解。
- 实时硬件部署:优化模型压缩与边缘计算,实现端侧实时推理。
- 异构多无人机协同:研究任务分配与通信机制下的分布式DQN框架。
结论
基于DQN的无人机路径规划通过深度神经网络与环境交互,显著提升了复杂动态场景下的自主决策能力。改进算法如分层DQN、对抗DQN等解决了传统方法的局限性,但在实时性、泛化性和多目标优化方面仍需进一步突破。未来研究需结合仿真与真实场景验证,推动技术落地应用。
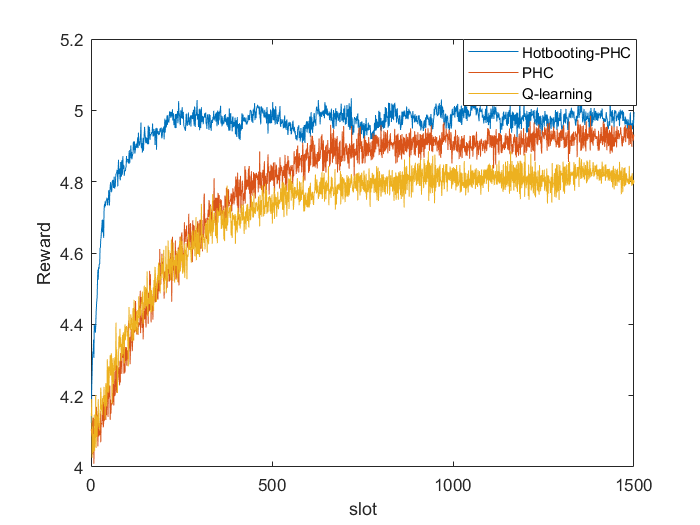
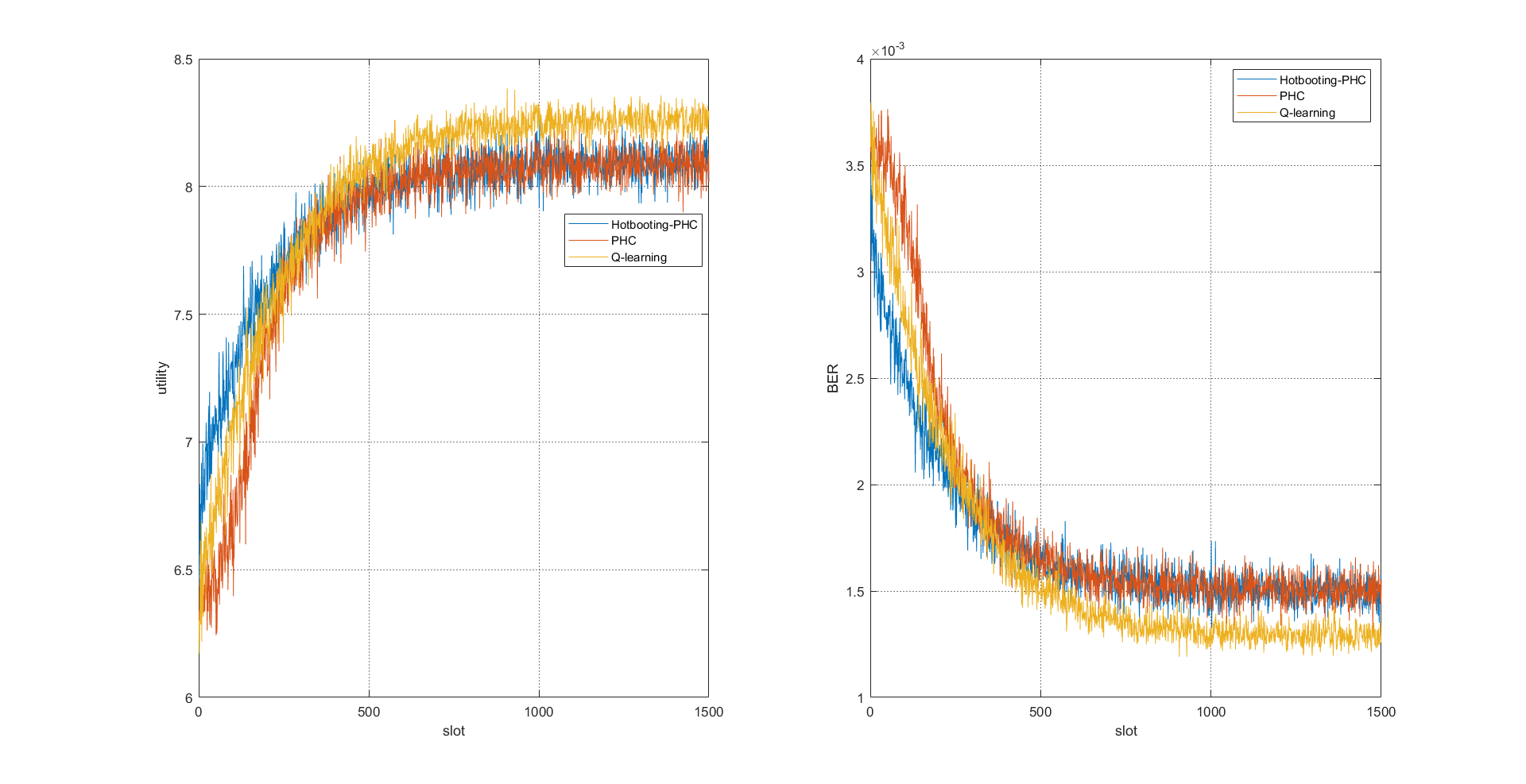
📚2 运行结果
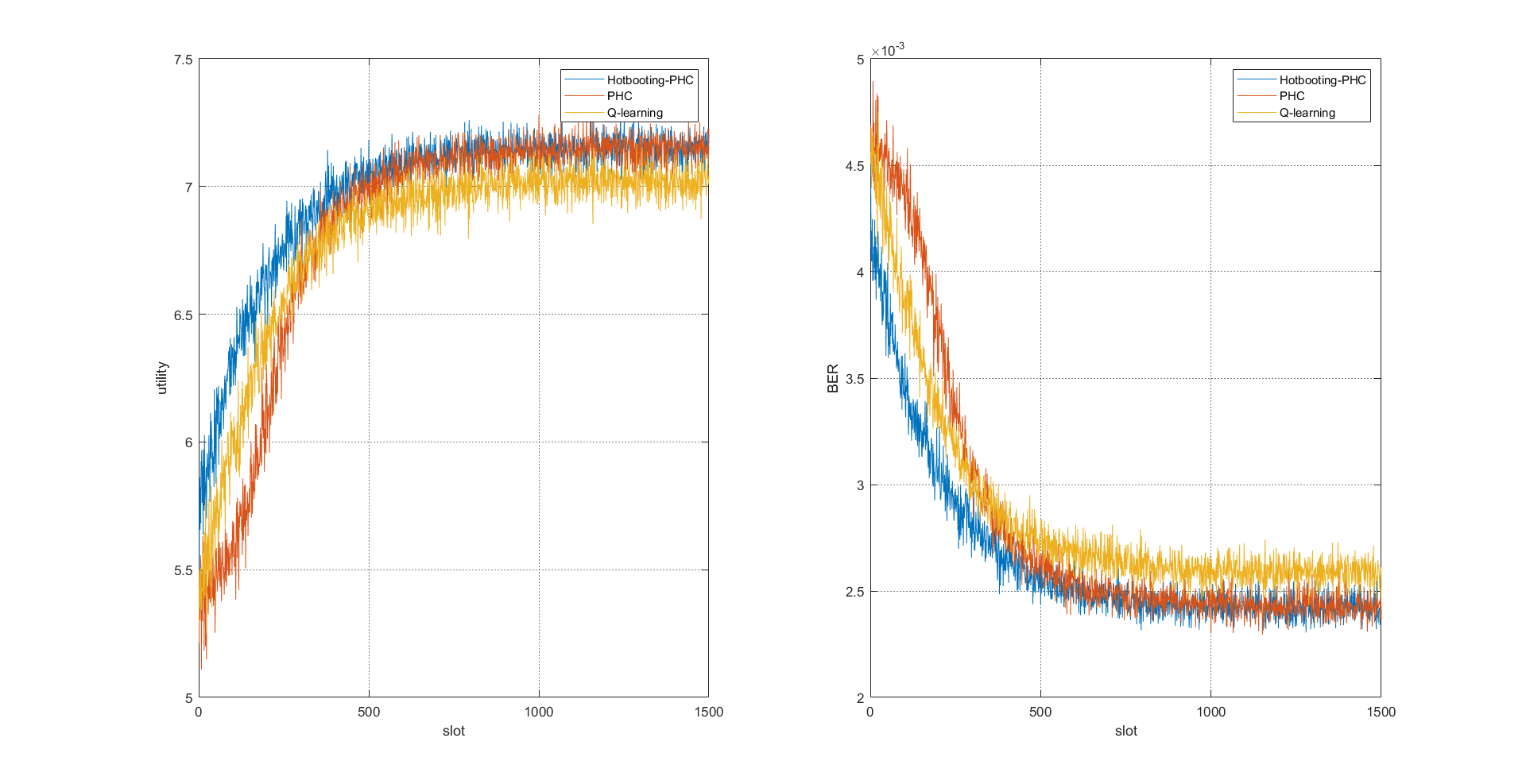
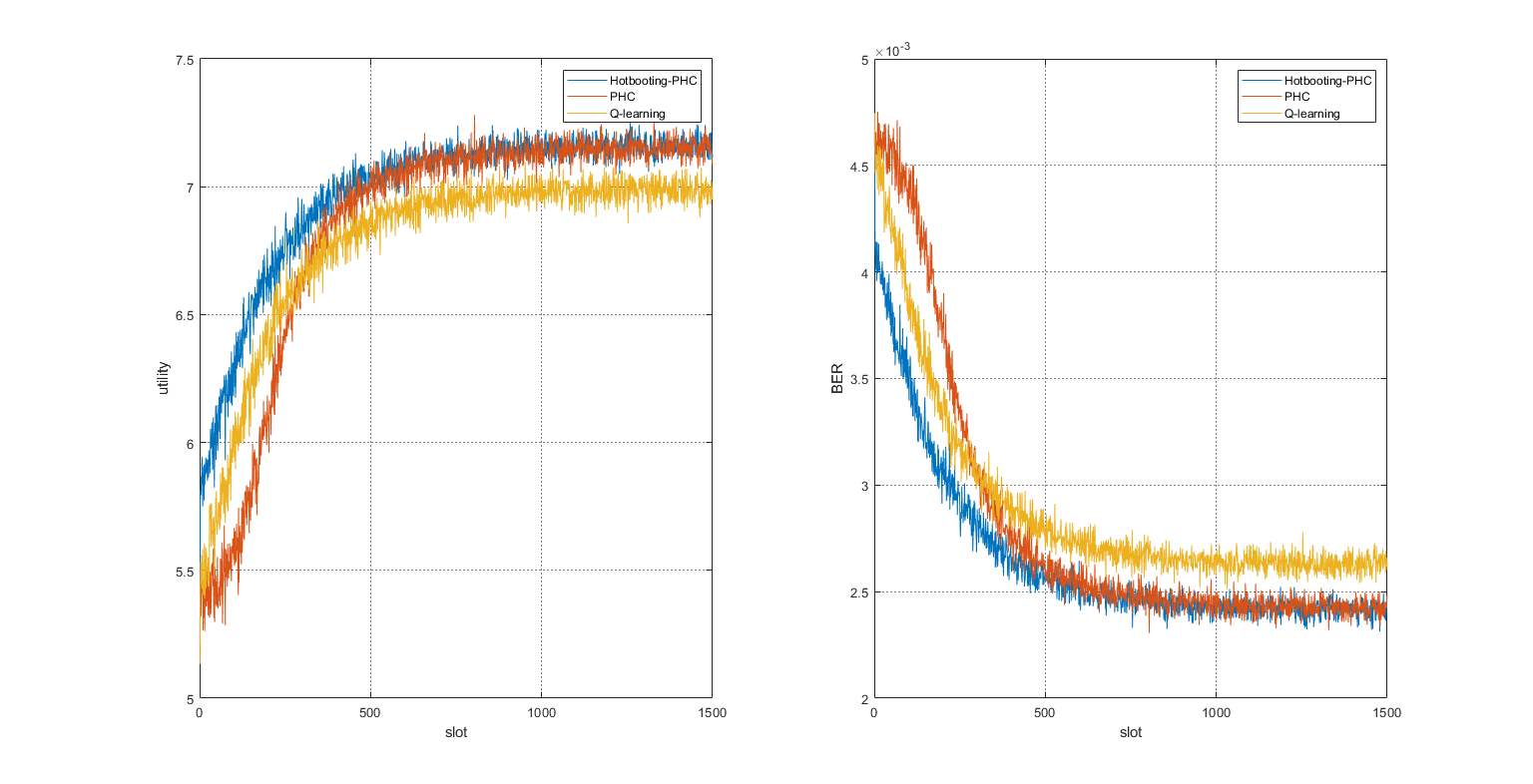
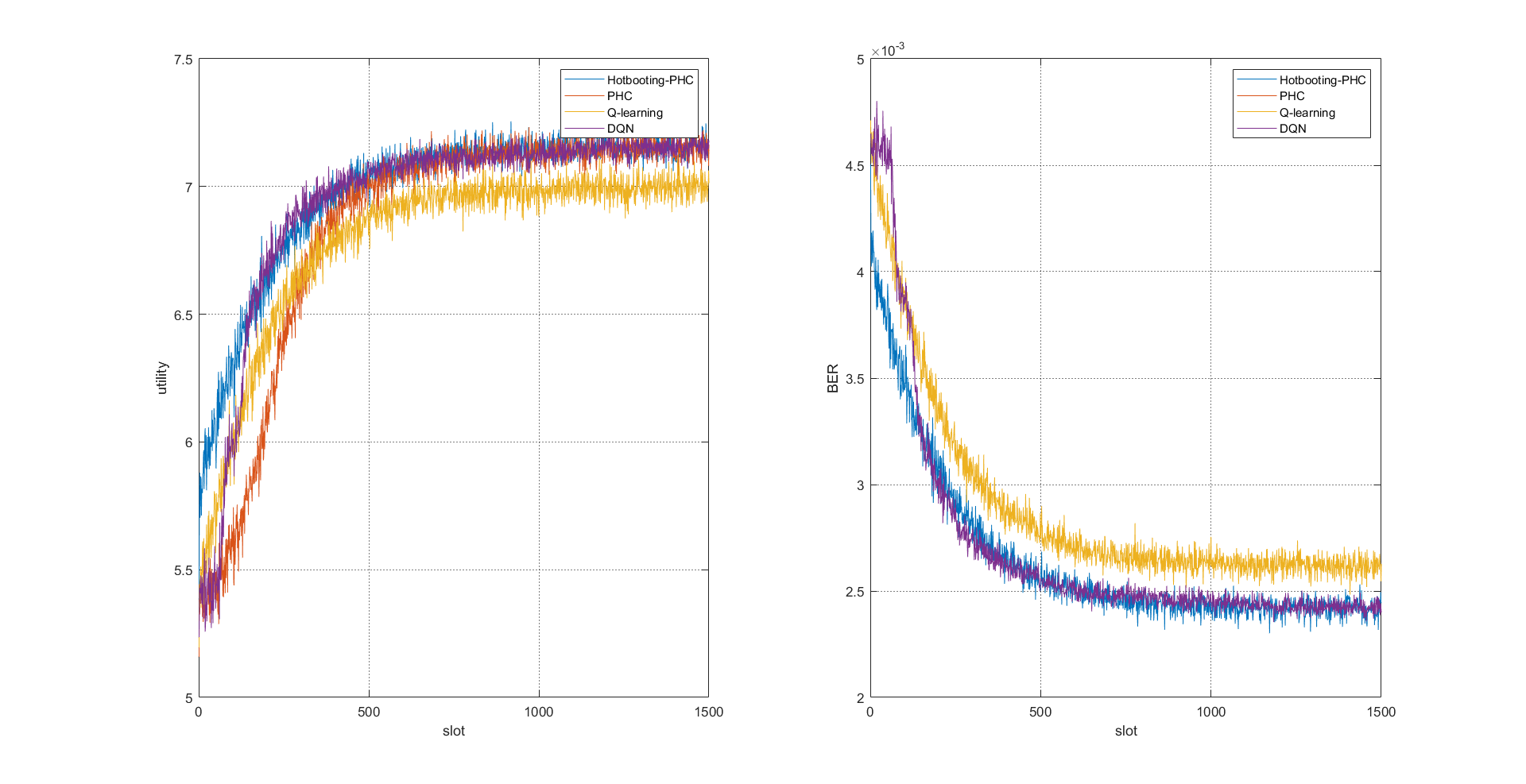
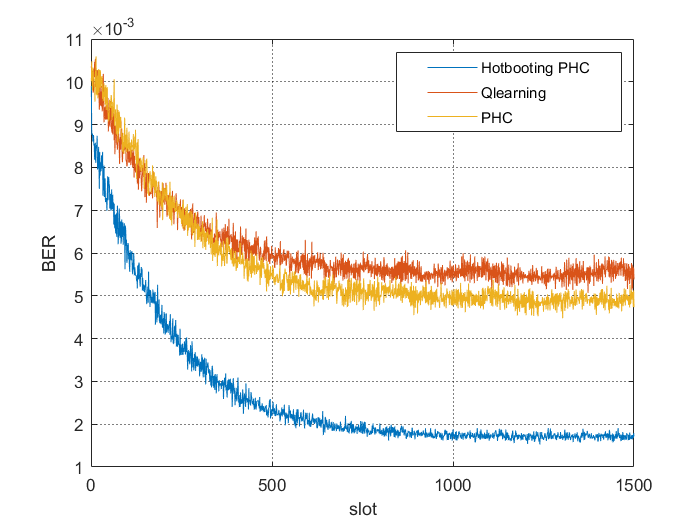
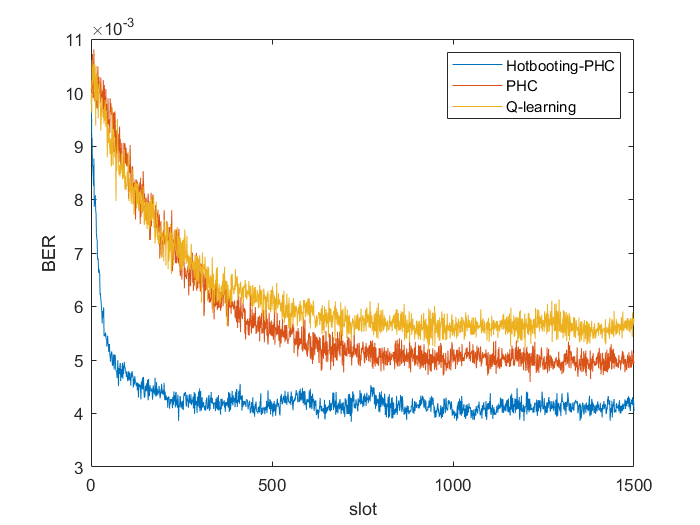
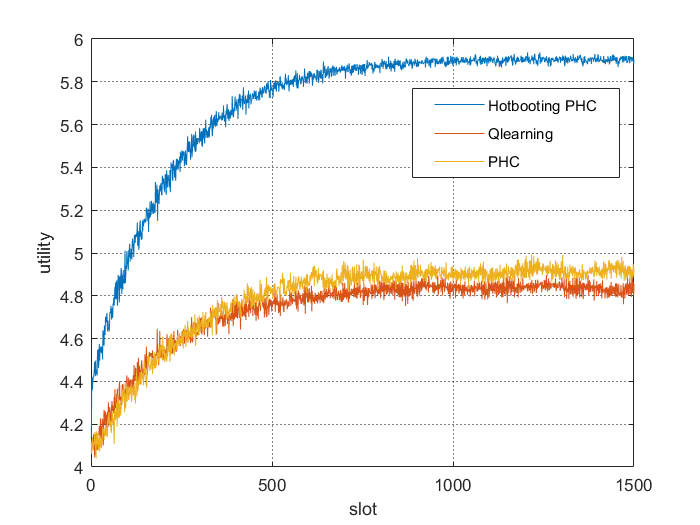
部分代码:
"""构造状态向量"""
State_U_p = [SINR1_idx_p, SINR2_idx_p]
State_U_p_Q = [SINR1_idx_p, SINR2_idx_p]
State_U_p_phc = [SINR1_idx_p, SINR2_idx_p]
State_U_p_DQN = [SINR1_p,SINR2_p]
for time_step in range(max_time):
"""根据观测到的状态执行动作"""
Action_idx_U = Agent_U.choose_action_phc(State_U_p)
Action_idx_U_Q = Agent_U_Q.choose_action(State_U_p_Q)
Action_idx_U_phc = Agent_U_phc.choose_action_phc(State_U_p_phc)
Action_idx_U_DQN = Agent_U_DQN.act(State_U_p_DQN)
tx_power = 2
tx_power_Q = 2
tx_power_phc = 2🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]杨博.蚁群路由算法在车载自组网中的研究和应用[D].西安电子科技大学[2025-03-18].
[2]亓法欣,童向荣,于雷.基于强化学习DQN的智能体信任增强[J].计算机研究与发展, 2020, 57(6):12.
[3]韩中华.基于强化学习DQN算法的智能决策模型研究[J].现代计算机, 2023(14):52-56.
🌈4 Python代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取

更多推荐
 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)