
深度学习入门首选——神经网络分类实战
本文介绍了神经网络在声呐数据分类中的应用,对比了符号主义和连接主义两种AI范式。通过R语言的neuralnet包,构建单隐藏层和双隐藏层神经网络模型对Sonar数据集进行分类。实验结果表明,7-5神经元配置的双隐藏层网络表现最优(准确率85.7%),显著优于逻辑回归模型(准确率75%)。ROC曲线分析显示神经网络AUC值为0.84,验证了其在复杂模式识别任务中的优势。文章详细展示了从数据预处理、模
一、前言:
在人工智能研究领域,主要有两大派系并行发展:符号主义以精密的逻辑架构构建智能世界,通过显式规则与公理系统编码知识,形成可解释的符号结构;而连接主义则另辟蹊径,模仿生物神经元的连接机制,让机器在海量数据中自主调整网络权重,形成隐式知识表达。过往推文中介绍的决策树、逻辑回归等符号主义算法虽具备推理透明的优势,却在处理高维非线性数据时显露局限。
本期我们将目光转向更具仿生特质的连接主义范式。该范式从人脑神经元运作中汲取灵感,通过构建大规模并行连接的网络架构,让机器获得从数据中自主提炼知识的能力。作为连接主义的经典载体,前馈神经网络(FNN) 展现出强大的模式识别特性。为快速理解其核心思想,我们通过三幅示意图揭示仿生智慧的精髓:
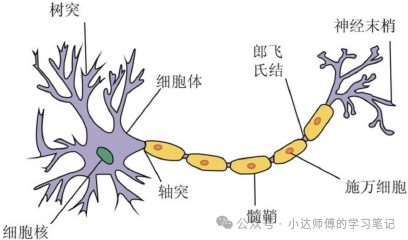
图1展示的是自然界最原始的智能单元——生物神经元。其中树突负责接收信号,细胞体进行信息整合,轴突则将处理后的电脉冲传递出去。这种"接收-整合-发放"的机制,是所有智能活动的生物学基础。
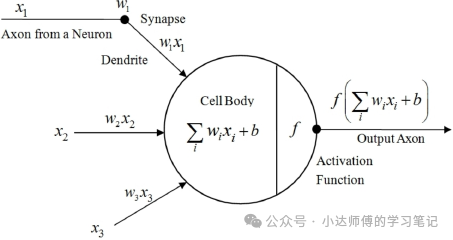
图2是将生物过程抽象出来的数学语言。输入信号(向量 x )经过权重矩阵 W 加权处理,加上偏置项b,再通过激活函数f(·)的非线性变换,最终形成输出y。这个过程是将突触强度转化为权重参数,生物开关抽象为数学函数。
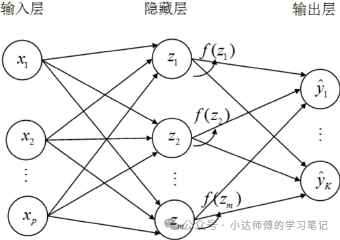
图3则是展示了由代码构建的"数字神经元群落"。信息从输入层流入,经过隐藏层的层层抽象(隐藏层可以是单层也可以是多层。当神经网络的隐藏层很多,则称为深度神经网络,简称深度学习),最终在输出层形成预测结果。通过这种单向流动的信息处理方式,构成了前馈神经网络的基本架构。
网络的学习过程可概括为“预测—计算误差—反向传播—更新权重”的循环,就像学生通过练习和纠错不断提高成绩。R的neuralnet包已内嵌这一机制,只需设定网络结构即可自动完成。
本次推文将手把手演示如何用neuralnet在十分钟内完成一次完整的神经网络建模。
二、神经网络二分类模型的R案例:
2.1加载R包与数据预处理
本案例继续沿用分类随机森林模型所使用的Sonar声呐数据集。其包含208个观测值和61个变量。其中,响应变量为因子Class,表示声呐回音来自“金属”(记为M)还是“岩石”(记为R);特征变量共60个(V1-V60),表示从不同的角度与频道下声呐反射信号的能量。下面我们将根据这60个不同的特征信号,通过神经网络模型来判断这些声呐信号究竟是来自于金属还是岩石。
library(mlbench) # 包含Sonar数据集
library(neuralnet) # 神经网络建模
library(caret) # 数据分割、预处理和评估
library(pROC)
# 数据准备
data(Sonar)
dim(Sonar) # 检查数据维度
# 数据清洗:处理缺失值(本例无缺失值)
if(sum(is.na(Sonar)) > 0) Sonar <- na.omit(Sonar)
# 设置随机种子确保可重复性
set.seed(1)
# 划分训练集和测试集 (7/3)
train_index <- createDataPartition(Sonar$Class, p = 0.7, list = FALSE)
train_data <- Sonar[train_index, ]
test_data <- Sonar[-train_index, ]
# 数据归一化 (只对特征变量,不包括标签)
normalize <- function(x) {
(x - min(x)) / (max(x) - min(x))
}
features_norm <- as.data.frame(lapply(Sonar[, -61], normalize))
# 将类别标签转换为0-1变量(R=1, M=0)
class_numeric <- ifelse(Sonar$Class == "R", 1, 0)
Sonar_norm <- cbind(features_norm, Class = class_numeric)在估计神经网络模型之前,需要对数据进行“预处理”,即把数据“归一化”,使得每个变量的最小值变为0,最大值变为1。
2.2初始模型构建:单隐藏层神经网络
接下来,我们来构建单隐藏层的神经网络模型。
set.seed(123)
nn_single <- neuralnet(
Class ~ .,
data = Sonar_norm[train_index, ],
hidden = 10, # 初始隐藏层神经元数
linear.output = FALSE, # 分类问题使用非线性输出
act.fct = "logistic"
)
# 初始模型评估
prob_single <- predict(nn_single, Sonar_norm[-train_index, ])
pred_single <- ifelse(prob_single > 0.5, "R", "M") # 转换为类别标签
pred_single <- factor(pred_single, levels = c("M", "R")) # 转换为因子
# 使用confusionMatrix计算详细指标 (正类为"M")
test_conf_single <- confusionMatrix(pred_single, test_data$Class, positive = "M")
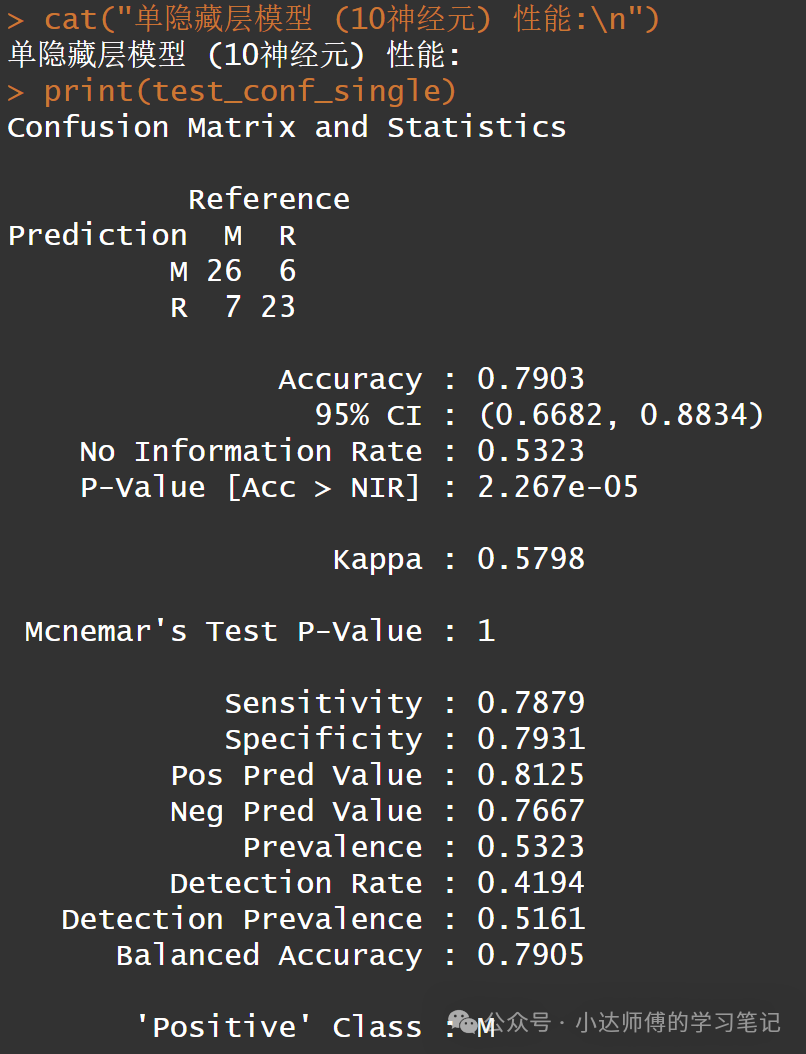
cat("单隐藏层模型 (10神经元) 性能:\n")
print(test_conf_single)参数“hidden=10”表示单一隐藏层中共有10个神经元;参数“act.fct="logistic"”表示使用logistic函数作为激活函数(是默认设置);参数“linear.output = FALSE”表示对输出层也施加logistic激活函数。
2.3双隐藏层模型构建与评估
下面尝试构建一个有两个隐藏层的神经网络模型,通过参数“hidden = c(4,4)”我们可以把第一个隐藏层和第二个隐藏层分别设置为4个神经元。
set.seed(123)
nn_double <- neuralnet(
Class ~ .,
data = Sonar_norm[train_index, ],
hidden = c(4, 4), # 双隐藏层结构
linear.output = FALSE,
act.fct = "logistic"
)
# 双层模型评估
prob_double <- predict(nn_double, Sonar_norm[-train_index, ])
pred_double <- ifelse(prob_double > 0.5, "R", "M")
pred_double <- factor(pred_double, levels = c("M", "R"))
# 使用confusionMatrix计算详细指标
test_conf_double <- confusionMatrix(pred_double, test_data$Class, positive = "M")
cat("\n双隐藏层模型 (4-4神经元) 性能:\n")
print(test_conf_double)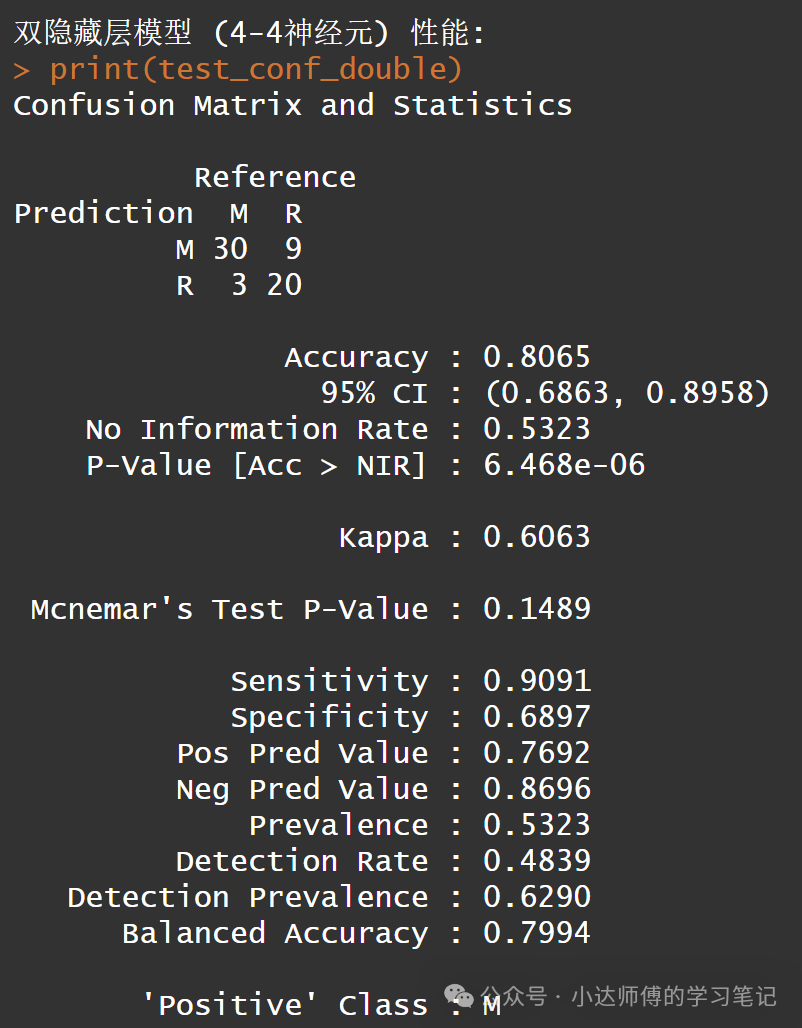
对比单隐藏层和双隐藏层的结果。发现这个双隐藏层模型 (4-4神经元)的准确率要比上面单隐藏层模型 (10神经元)的更高。下面,我们继续看看双隐藏层的神经元数量要多少才能使得模型性能最佳。
2.4参数调优确定最优双隐藏层结构
这里只是简单地演示参数设置,感兴趣的朋友可以自己尝试其他参数。
best_accuracy <- 0
best_config <- c(0, 0)
accuracy_matrix <- matrix(NA, nrow = 10, ncol = 10)
for(i in 1:10) {
for(j in 1:10) {
set.seed(123)
model <- neuralnet(
Class ~ .,
data = Sonar_norm[train_index, ],
hidden = c(i, j),
linear.output = FALSE,
act.fct = "logistic"
)
prob <- predict(model, Sonar_norm[-train_index, ])
pred <- ifelse(prob > 0.5, "R", "M")
pred <- factor(pred, levels = c("M", "R"))
# 使用confusionMatrix计算准确率
conf_matrix <- confusionMatrix(pred, test_data$Class, positive = "M")
current_accuracy <- conf_matrix$overall['Accuracy']
accuracy_matrix[i, j] <- current_accuracy
if(current_accuracy > best_accuracy) {
best_accuracy <- current_accuracy
best_config <- c(i, j)
}
}
}
# 输出最优参数
cat("\n===== 最优参数结果 =====\n")
cat("最佳隐藏层配置:", best_config[1], "-", best_config[2], "神经元\n")
cat("最高准确率:", best_accuracy, "\n")
print("准确率矩阵:")
print(accuracy_matrix)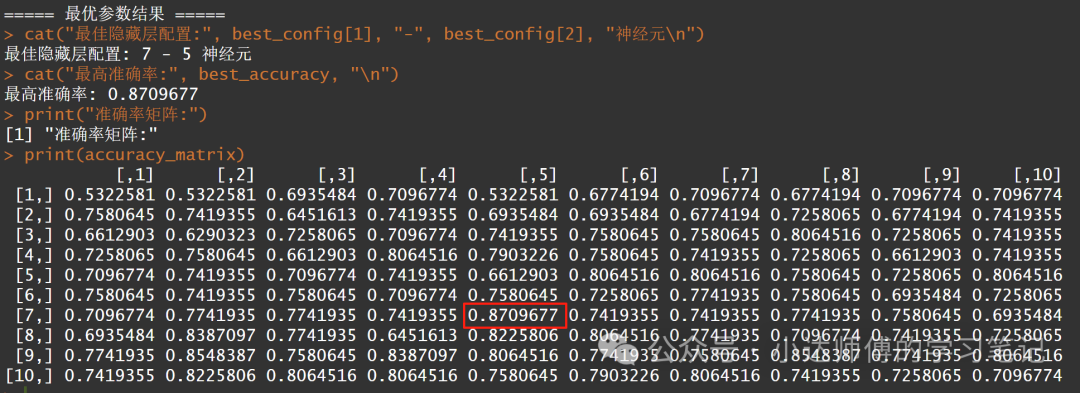
从上面的结果中我们可以看到在这个10*10的矩阵中,7-5的双层神经元准确率最高。
2.5最终模型拟合与评估
接下来,我们对这个7-5的双隐藏层模型进行评估并且将其的神经网络图形绘制出来。
set.seed(123)
final_nn <- neuralnet(
Class ~ .,
data = Sonar_norm[train_index, ],
hidden = best_config,
linear.output = FALSE,
act.fct = "logistic"
)
# 最终模型评估
prob_final <- predict(final_nn, Sonar_norm[-train_index, ])
pred_final <- ifelse(prob_final > 0.5, "R", "M")
pred_final <- factor(pred_final, levels = c("M", "R"))
# 使用confusionMatrix计算详细指标 (正类为"M")
test_conf_final <- confusionMatrix(pred_final, test_data$Class, positive = "M")
cat("\n最终模型性能:\n")
print(test_conf_final)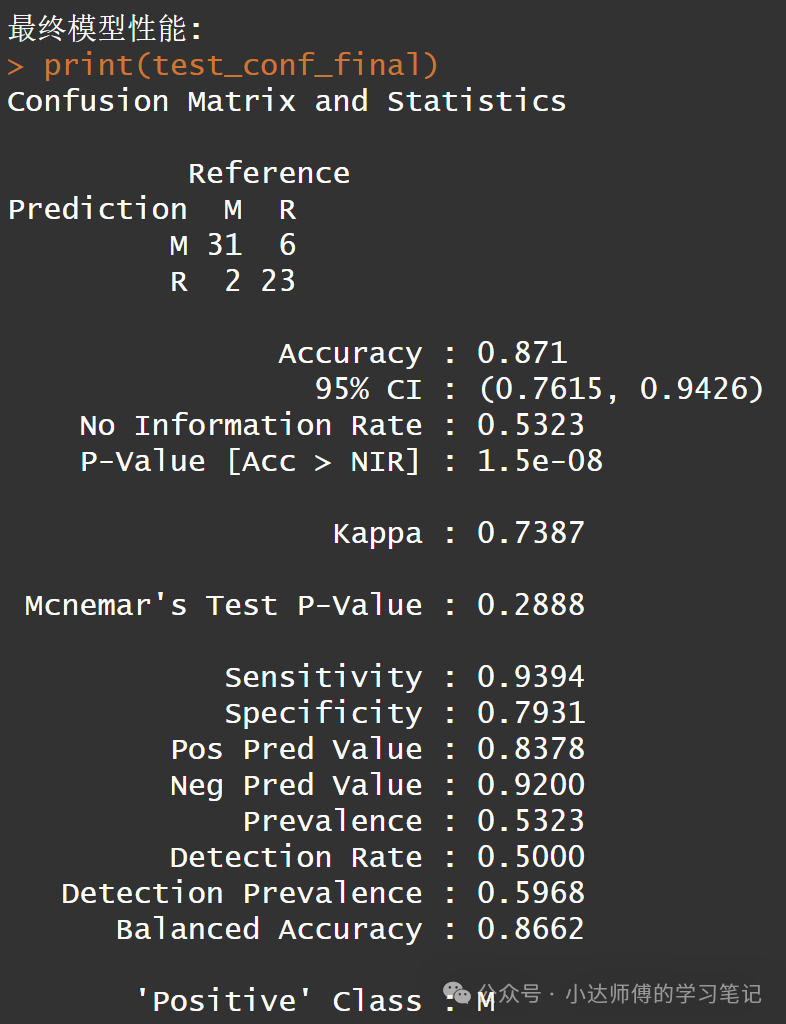
这是最佳模型的混淆矩阵结果。下面,我们继续可视化神经网络:
plot(final_nn, rep = "best",
col.entry = "skyblue",
col.hidden = "lightgreen",
col.out = "salmon",
main = "最优神经网络结构")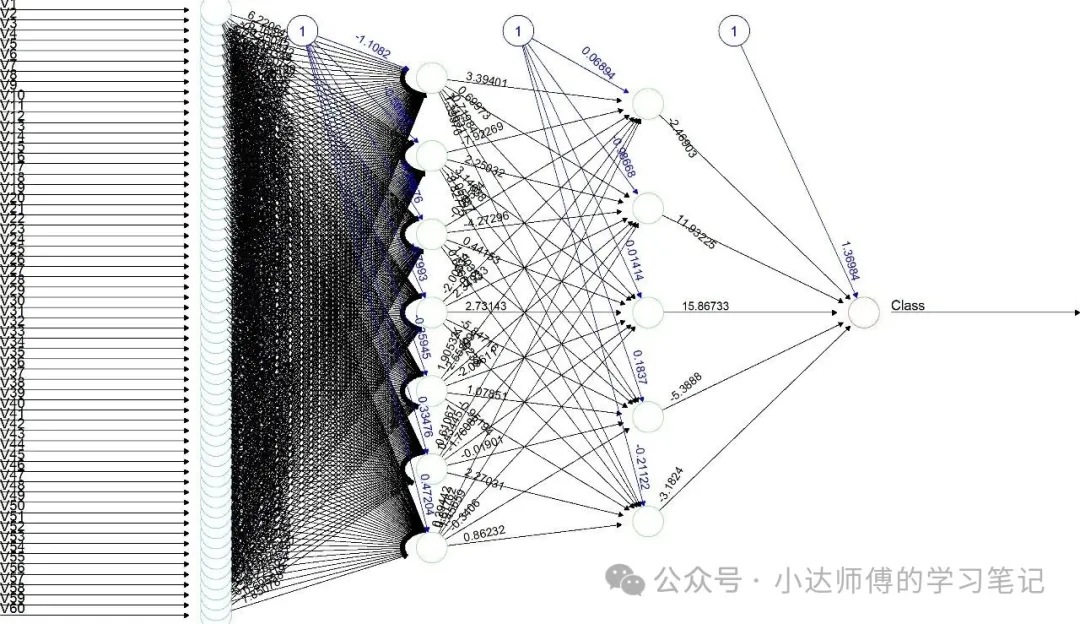
2.6与逻辑回归比较
最后,我们简单的与逻辑回归的预测结果进行一个比较:
logit_model <- glm(Class ~ .,
data = train_data,
family = binomial(link = "logit"))
prob_logit <- predict(logit_model, test_data, type = "response")
pred_logit <- ifelse(prob_logit > 0.5, "R", "M")
pred_logit <- factor(pred_logit, levels = c("M", "R"))
# 使用confusionMatrix计算详细指标
logit_conf <- confusionMatrix(pred_logit, test_data$Class, positive = "M")
cat("\n逻辑回归性能:\n")
print(logit_conf)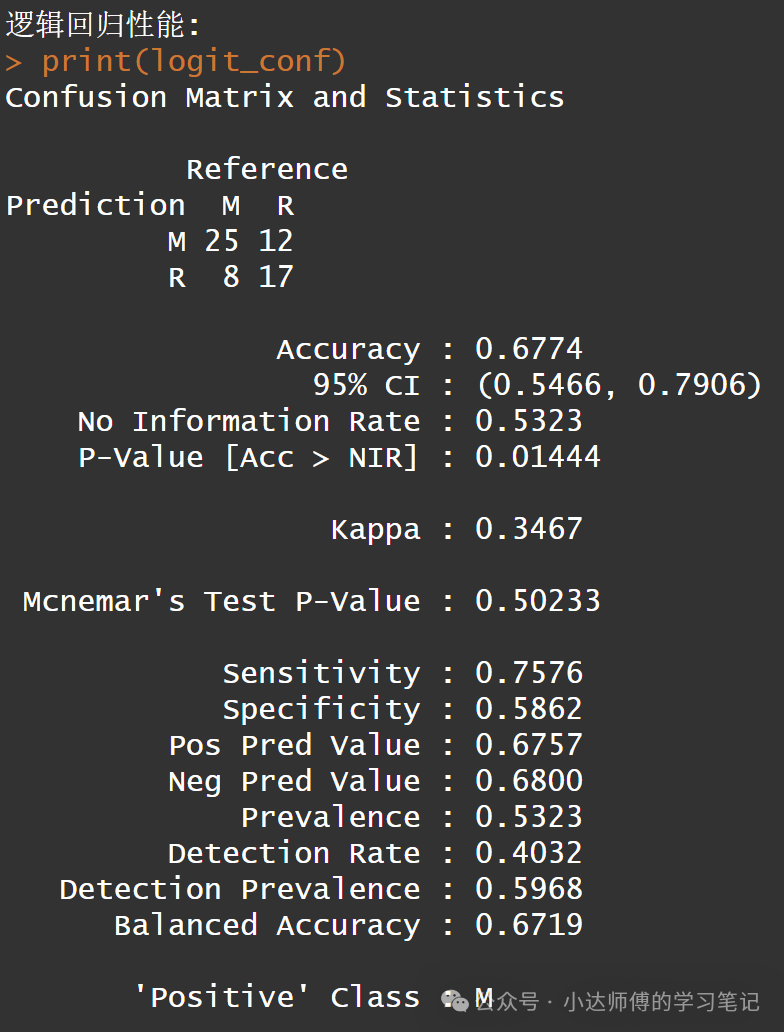
可以发现,神经网络模型的性能还是明显比逻辑回归模型更强一些。
浅浅看一下这两个模型所预测的结果(篇幅有限,展示前20个)。
# 模型预测结果
results <- data.frame(
Actual = test_data$Class,
NN_Probability = prob_final,
NN_Prediction = pred_final,
Logit_Probability = prob_logit,
Logit_Prediction = pred_logit
)
# 查看前20个样本的预测结果
print(head(results, 20))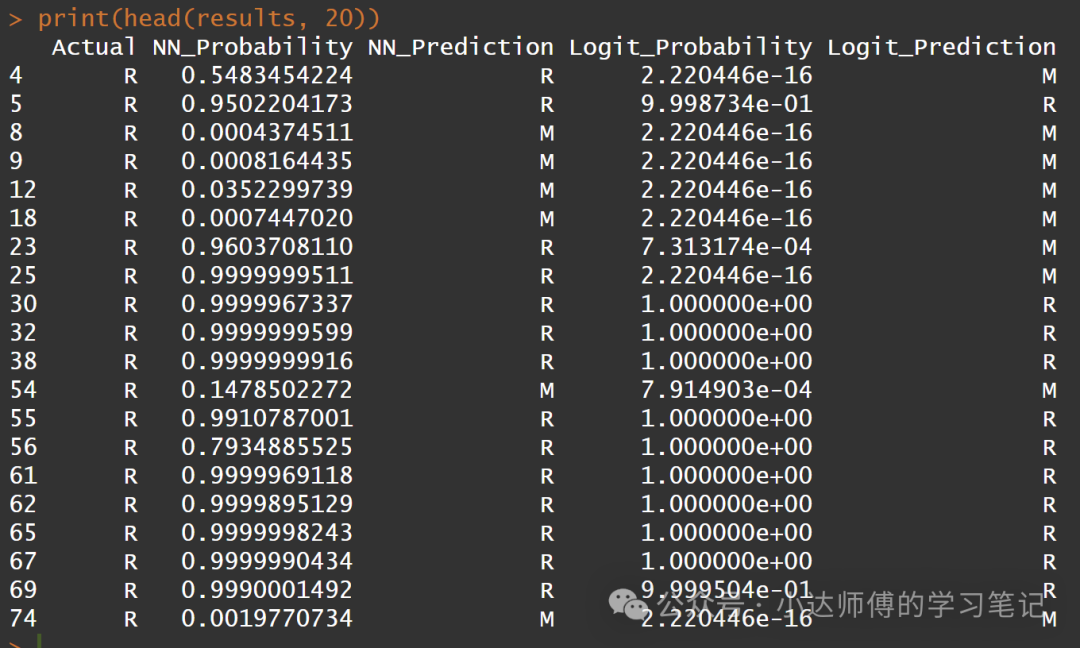
最后,绘制ROC曲线来看看两个模型的性能。
roc_nn <- roc(response = test_data$Class, predictor = as.numeric(prob_final))
roc_logit <- roc(response = test_data$Class, predictor = prob_logit)
plot(roc_nn, col = "blue", main = "ROC曲线比较")
lines(roc_logit, col = "red")
legend("bottomright", legend = c(paste("神经网络 (AUC =", round(auc(roc_nn), 3)),
paste("逻辑回归 (AUC =", round(auc(roc_logit), 3))),
col = c("blue", "red"), lwd = 2)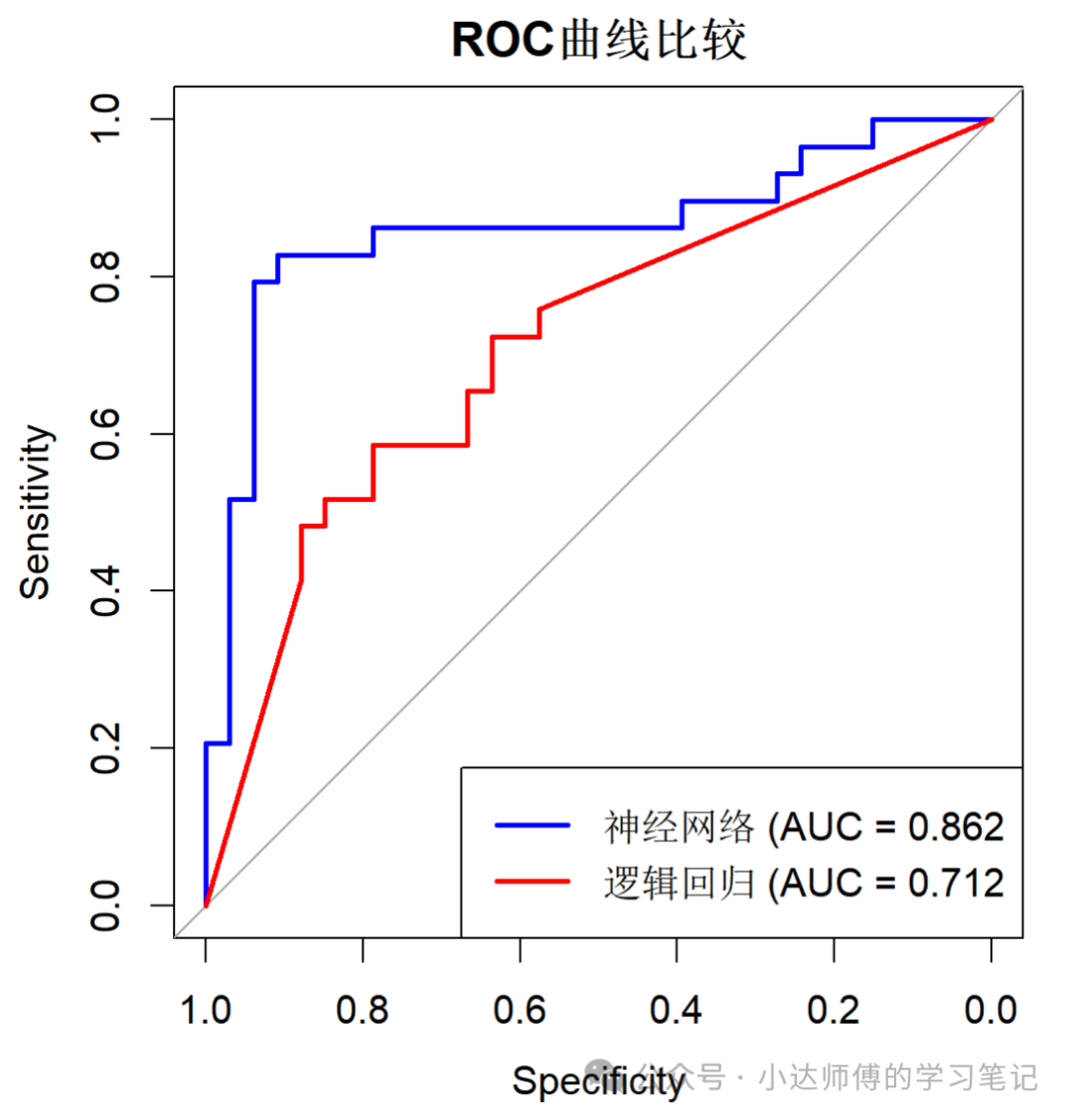
三、小结:
本次实战演示了神经网络在声呐数据分类中的应用,展现了其在处理复杂模式识别任务时的优势。通过R语言的neuralnet包,我们快速构建并优化了神经网络模型,最终取得了优于传统方法的分类效果。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

😝有需要的小伙伴,可以扫描下方二v码免费领取【保证100%免费】🆓
更多推荐
 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)