
强化学习第四课 —— 深度强化学习:深度Q网络(DQN)
深度Q网络(DQN)是DeepMind团队提出的里程碑式算法,首次实现从高维感知输入直接学习控制策略。相比传统Q-Learning,DQN通过神经网络逼近Q函数,解决了状态空间过大和泛化问题。其核心技术包括经验回放(打破数据相关性)和目标网络(稳定训练)。改进版本如DoubleDQN和DuelingDQN进一步提升了性能。DQN适用于高维状态空间和离散动作环境,但仍存在样本效率低、超参数敏感等局限
引言
深度 Q 网络(Deep Q-Network,DQN)是由 DeepMind 团队在 2013 年提出,并在 2015 年发表于 Nature 的一项里程碑式的研究成果。DQN 成功地将深度学习与强化学习相结合,首次实现了端到端地从高维感知输入(如游戏画面)直接学习控制策略,在 Atari 2600 游戏上达到了超越人类专家的水平。
为什么 DQN 如此重要?
| 特点 | 传统 Q-Learning | DQN |
|---|---|---|
| 状态空间 | 离散、有限 | 连续、高维 |
| 函数表示 | Q 表格 | 神经网络 |
| 泛化能力 | 无 | 强 |
| 适用场景 | 简单环境 | 复杂环境(如视频游戏) |
Q-Learning 基础回顾
什么是 Q 函数?
Q 函数 表示在状态
下执行动作
后,能够获得的期望累积奖励:
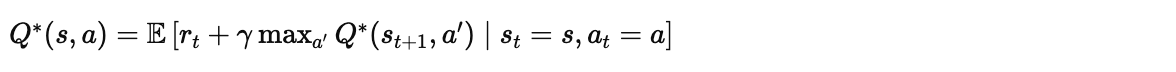
其中:
-
:即时奖励
-
:折扣因子(通常取 0.99)
-
:下一个状态
Bellman 方程
Q-Learning 的核心是 Bellman 最优方程:
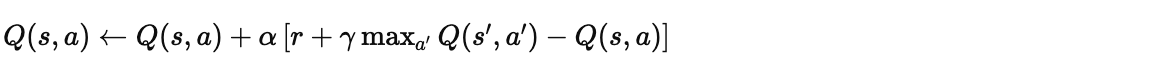
从 Q-Learning 到 DQN
传统 Q-Learning 的局限性
传统 Q-Learning 使用 Q 表格 存储每个状态-动作对的 Q 值,但面对以下情况会失效:
-
状态空间过大:例如 Atari 游戏的画面是 210×160×3 的像素矩阵
-
连续状态空间:无法枚举所有状态
-
缺乏泛化:未见过的状态无法估计 Q 值
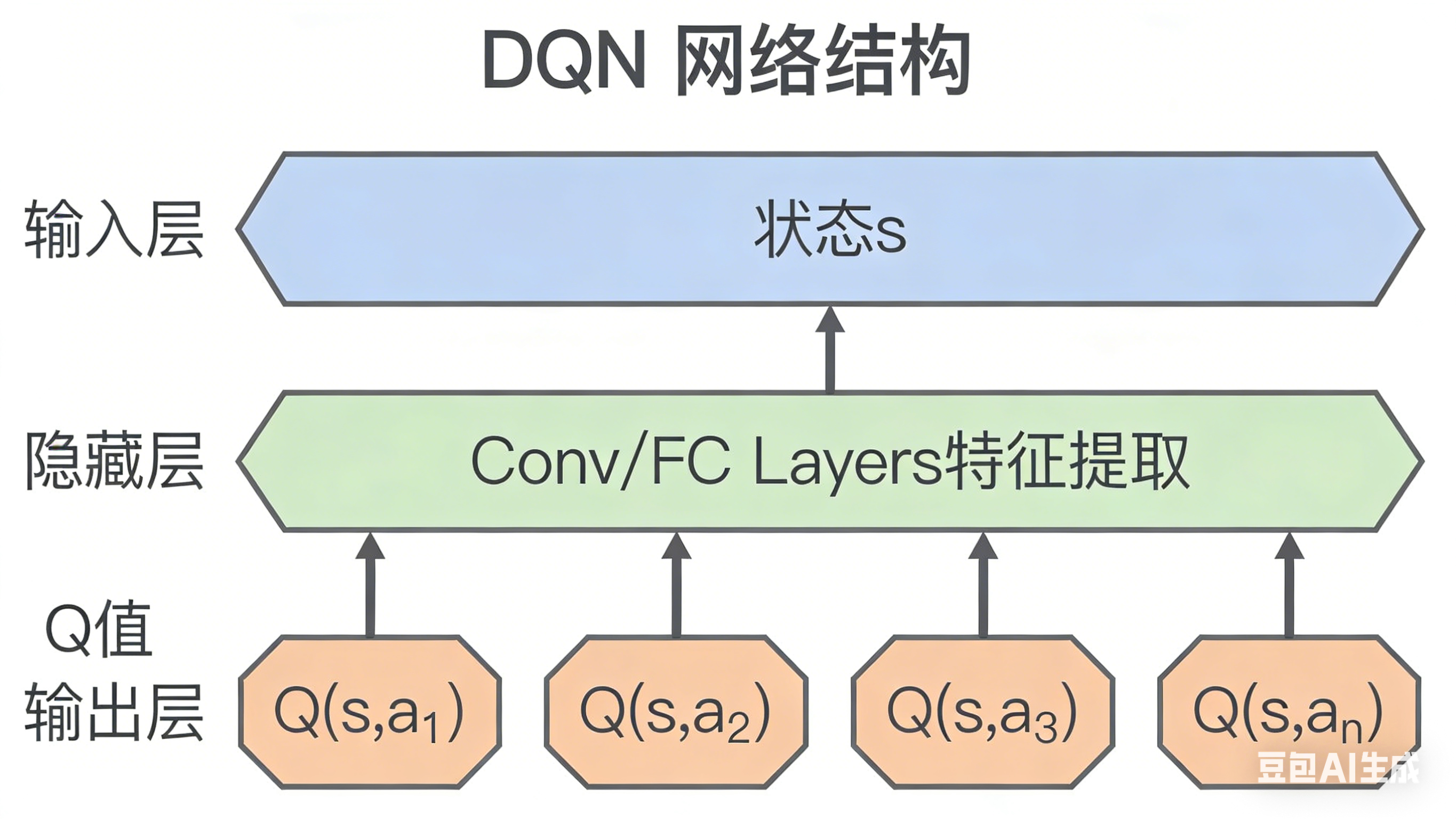
DQN 的解决方案
使用深度神经网络作为函数逼近器来估计 Q 值:

其中 是神经网络的参数。
DQN 核心技术
DQN 引入了两个关键技术来稳定训练过程:
1. 经验回放(Experience Replay)
问题:连续采样的数据具有强相关性,违反了机器学习中数据独立同分布(i.i.d.)的假设。
解决方案:将经验 存储在回放缓冲区中,训练时随机采样。
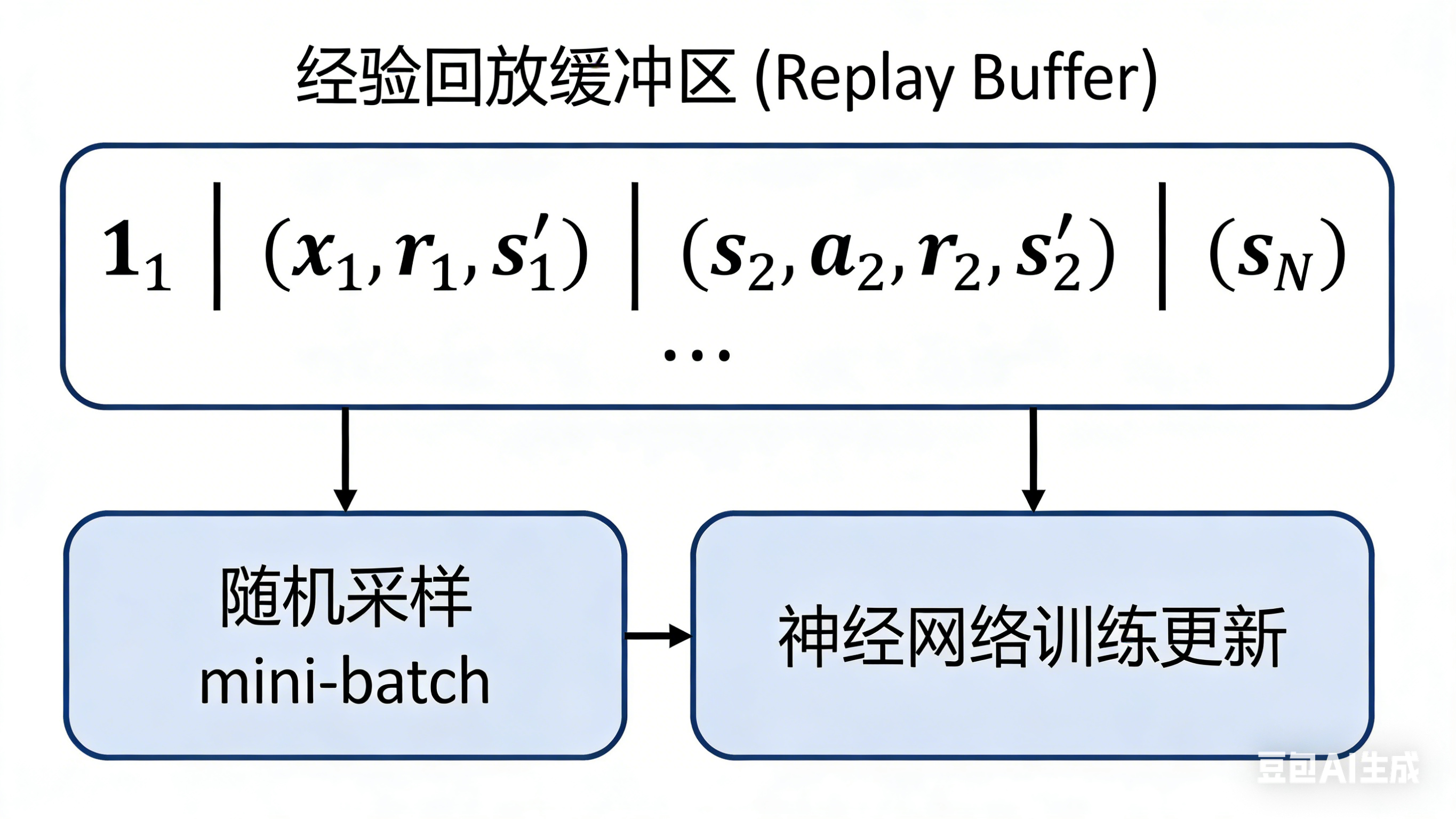
优点:
-
打破数据相关性
-
提高数据利用效率(每个经验可被多次使用)
-
稳定训练过程
2. 目标网络(Target Network)
问题:Q 值的更新目标也依赖于当前网络,导致训练不稳定(追逐移动的目标)。
解决方案:使用两个网络:
-
主网络(Online Network):用于选择动作和更新参数
-
目标网络(Target Network):用于计算目标 Q 值,参数定期从主网络复制
损失函数
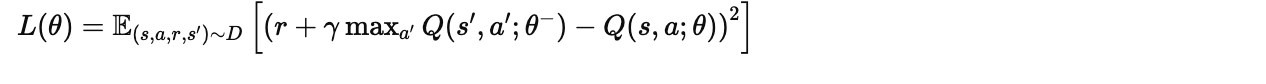
DQN 算法流程
伪代码
算法:Deep Q-Network (DQN)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
初始化:
回放缓冲区 D,容量为 N
主网络 Q(s, a; θ),随机初始化权重 θ
目标网络 Q(s, a; θ⁻),θ⁻ ← θ
For episode = 1 to M do:
初始化状态 s₁
For t = 1 to T do:
// ε-贪婪策略选择动作
以概率 ε 随机选择动作 aₜ
否则 aₜ = argmax_a Q(sₜ, a; θ)
// 执行动作,观察奖励和新状态
执行动作 aₜ,得到奖励 rₜ 和新状态 sₜ₊₁
// 存储经验
将 (sₜ, aₜ, rₜ, sₜ₊₁) 存入 D
// 从 D 中随机采样 mini-batch
采样 batch: {(sⱼ, aⱼ, rⱼ, sⱼ₊₁)}
// 计算目标 Q 值
yⱼ = rⱼ + γ · max_a' Q(sⱼ₊₁, a'; θ⁻)
// 梯度下降更新主网络
对损失 (yⱼ - Q(sⱼ, aⱼ; θ))² 进行梯度下降
// 定期更新目标网络
每 C 步:θ⁻ ← θ
End For
End For
代码实现
环境配置
# 安装依赖
# pip install torch gymnasium numpy matplotlib
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import gymnasium as gym
from collections import deque
import random
import matplotlib.pyplot as plt
DQN 网络定义
class DQN(nn.Module):
"""
深度 Q 网络
输入: 状态向量
输出: 每个动作对应的 Q 值
"""
def __init__(self, state_dim, action_dim, hidden_dim=128):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
经验回放缓冲区
class ReplayBuffer:
"""
经验回放缓冲区
用于存储和采样经验元组 (state, action, reward, next_state, done)
"""
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
"""添加一条经验"""
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
"""随机采样一个 batch"""
batch = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
return (
np.array(states),
np.array(actions),
np.array(rewards, dtype=np.float32),
np.array(next_states),
np.array(dones, dtype=np.float32)
)
def __len__(self):
return len(self.buffer)
DQN Agent 完整实现
class DQNAgent:
"""
DQN 智能体
包含主网络、目标网络、经验回放和训练逻辑
"""
def __init__(
self,
state_dim,
action_dim,
learning_rate=1e-3,
gamma=0.99,
epsilon_start=1.0,
epsilon_end=0.01,
epsilon_decay=0.995,
buffer_size=10000,
batch_size=64,
target_update_freq=10
):
self.action_dim = action_dim
self.gamma = gamma
self.epsilon = epsilon_start
self.epsilon_end = epsilon_end
self.epsilon_decay = epsilon_decay
self.batch_size = batch_size
self.target_update_freq = target_update_freq
self.learn_step_counter = 0
# 设备配置
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化网络
self.policy_net = DQN(state_dim, action_dim).to(self.device)
self.target_net = DQN(state_dim, action_dim).to(self.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
# 优化器
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=learning_rate)
# 经验回放缓冲区
self.memory = ReplayBuffer(buffer_size)
def select_action(self, state):
"""
ε-贪婪策略选择动作
"""
if random.random() < self.epsilon:
return random.randrange(self.action_dim)
with torch.no_grad():
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
q_values = self.policy_net(state)
return q_values.argmax(dim=1).item()
def learn(self):
"""
从经验回放缓冲区采样并更新网络
"""
if len(self.memory) < self.batch_size:
return None
# 采样
states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size)
# 转换为 tensor
states = torch.FloatTensor(states).to(self.device)
actions = torch.LongTensor(actions).unsqueeze(1).to(self.device)
rewards = torch.FloatTensor(rewards).unsqueeze(1).to(self.device)
next_states = torch.FloatTensor(next_states).to(self.device)
dones = torch.FloatTensor(dones).unsqueeze(1).to(self.device)
# 计算当前 Q 值
current_q = self.policy_net(states).gather(1, actions)
# 计算目标 Q 值
with torch.no_grad():
max_next_q = self.target_net(next_states).max(dim=1, keepdim=True)[0]
target_q = rewards + self.gamma * max_next_q * (1 - dones)
# 计算损失并更新
loss = F.mse_loss(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(self.policy_net.parameters(), max_norm=1.0)
self.optimizer.step()
# 更新目标网络
self.learn_step_counter += 1
if self.learn_step_counter % self.target_update_freq == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
return loss.item()
def decay_epsilon(self):
"""衰减探索率"""
self.epsilon = max(self.epsilon_end, self.epsilon * self.epsilon_decay)
训练循环
def train_dqn(env_name='CartPole-v1', num_episodes=500):
"""
训练 DQN 智能体
"""
# 创建环境
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 创建智能体
agent = DQNAgent(state_dim, action_dim)
# 记录训练数据
episode_rewards = []
episode_losses = []
for episode in range(num_episodes):
state, _ = env.reset()
total_reward = 0
losses = []
while True:
# 选择动作
action = agent.select_action(state)
# 执行动作
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# 存储经验
agent.memory.push(state, action, reward, next_state, done)
# 学习
loss = agent.learn()
if loss is not None:
losses.append(loss)
total_reward += reward
state = next_state
if done:
break
# 衰减 epsilon
agent.decay_epsilon()
# 记录数据
episode_rewards.append(total_reward)
avg_loss = np.mean(losses) if losses else 0
episode_losses.append(avg_loss)
# 打印进度
if (episode + 1) % 50 == 0:
avg_reward = np.mean(episode_rewards[-50:])
print(f"Episode {episode + 1}, "
f"Avg Reward: {avg_reward:.2f}, "
f"Epsilon: {agent.epsilon:.3f}")
env.close()
return agent, episode_rewards, episode_losses
# 运行训练
if __name__ == "__main__":
agent, rewards, losses = train_dqn(num_episodes=500)
训练结果可视化
def plot_training_results(rewards, losses, window=50):
"""
绘制训练曲线
"""
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 奖励曲线
axes[0].plot(rewards, alpha=0.3, color='blue', label='Episode Reward')
# 滑动平均
smoothed = np.convolve(rewards, np.ones(window)/window, mode='valid')
axes[0].plot(range(window-1, len(rewards)), smoothed,
color='red', linewidth=2, label=f'Moving Average ({window})')
axes[0].set_xlabel('Episode')
axes[0].set_ylabel('Reward')
axes[0].set_title('DQN Training - Episode Rewards')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 损失曲线
axes[1].plot(losses, alpha=0.5, color='green')
axes[1].set_xlabel('Episode')
axes[1].set_ylabel('Loss')
axes[1].set_title('DQN Training - Loss')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('dqn_training_results.png', dpi=150)
plt.show()
# 绘制结果
plot_training_results(rewards, losses)
实验结果与分析
CartPole-v1 训练曲线
┌────────────────────────────────────────────────────────────┐
│ Training Rewards │
│ 500 ┤ ▄▄▄▄▄▄▄▄▄▄▄▄ │
│ │ ▄▄▄▄▀▀ │
│ 400 ┤ ▄▄▄▀▀ │
│ │ ▄▄▄▀▀ │
│ 300 ┤ ▄▄▀▀ │
│ │ ▄▄▀▀▀ │
│ 200 ┤ ▄▄▀▀▀ │
│ │ ▄▀▀ │
│ 100 ┤▀▀ │
│ │ │
│ 0 ┼──────────────────────────────────────────────── │
│ 0 100 200 300 400 500 │
│ Episode │
└────────────────────────────────────────────────────────────┘
关键超参数分析
| 超参数 | 推荐值 | 说明 |
|---|---|---|
| Learning Rate | 1e-3 ~ 1e-4 | 过大导致不稳定,过小收敛慢 |
| Batch Size | 32 ~ 128 | 影响梯度估计的方差 |
| Gamma (γ) | 0.99 | 折扣因子,权衡即时与长期奖励 |
| Buffer Size | 10000 ~ 100000 | 经验回放缓冲区大小 |
| Target Update | 每 100~1000 步 | 目标网络更新频率 |
| Epsilon Decay | 0.995 ~ 0.999 | 探索率衰减速度 |
DQN 的改进变体
1. Double DQN (DDQN)
问题:标准 DQN 倾向于过高估计 Q 值。
解决方案:使用主网络选择动作,目标网络评估 Q 值。
# Double DQN 的目标计算
with torch.no_grad():
# 用主网络选择最优动作
best_actions = self.policy_net(next_states).argmax(dim=1, keepdim=True)
# 用目标网络评估该动作的 Q 值
max_next_q = self.target_net(next_states).gather(1, best_actions)
target_q = rewards + self.gamma * max_next_q * (1 - dones)
2. Dueling DQN
思想:将 Q 值分解为状态价值 V(s) 和优势函数 A(s,a)。

class DuelingDQN(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=128):
super(DuelingDQN, self).__init__()
# 共享特征层
self.feature = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU()
)
# 价值流
self.value_stream = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
# 优势流
self.advantage_stream = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
def forward(self, x):
features = self.feature(x)
value = self.value_stream(features)
advantage = self.advantage_stream(features)
# Q = V + A - mean(A)
q_values = value + advantage - advantage.mean(dim=1, keepdim=True)
return q_values
3. Prioritized Experience Replay (PER)
思想:优先采样 TD 误差较大的经验,提高学习效率。
4. Rainbow DQN
集成多种改进:
-
Double DQN
-
Dueling DQN
-
Prioritized Experience Replay
-
Multi-step Learning
-
Distributional RL
-
Noisy Networks
┌─────────────────────────────────────────────────────────┐
│ DQN 改进路线图 │
├─────────────────────────────────────────────────────────┤
│ │
│ DQN (2015) │
│ │ │
│ ├──► Double DQN ──┐ │
│ │ │ │
│ ├──► Dueling DQN ──┼──► Rainbow DQN (2017) │
│ │ │ │
│ ├──► PER ─────────┘ │
│ │ │
│ └──► Noisy Nets │
│ │
└─────────────────────────────────────────────────────────┘
总结
DQN 的核心贡献
-
函数逼近:用深度神经网络代替 Q 表格
-
经验回放:打破数据相关性,提高样本效率
-
目标网络:稳定训练过程,避免目标漂移
适用场景
-
高维状态空间(图像输入)
-
离散动作空间
-
单智能体环境
局限性
-
不适用于连续动作空间(需要使用 DDPG、SAC 等)
-
样本效率仍有提升空间
-
超参数敏感
学习资源
-
论文:Human-level control through deep reinforcement learning(Nature 2015)
💡 提示:如果你想深入学习强化学习,建议从经典的 Q-Learning 开始,理解 Bellman 方程,再逐步过渡到 DQN 及其改进版本!
希望这篇文档对你有帮助!🎉 如果有任何疑问,欢迎在评论区留言讨论~
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)