
GRPO强化学习训练翻译模型的奖励函数设计
本文主要看一下翻译模型的GRPO奖励函数设计。
·
本文主要看一下翻译模型的GRPO奖励函数设计。
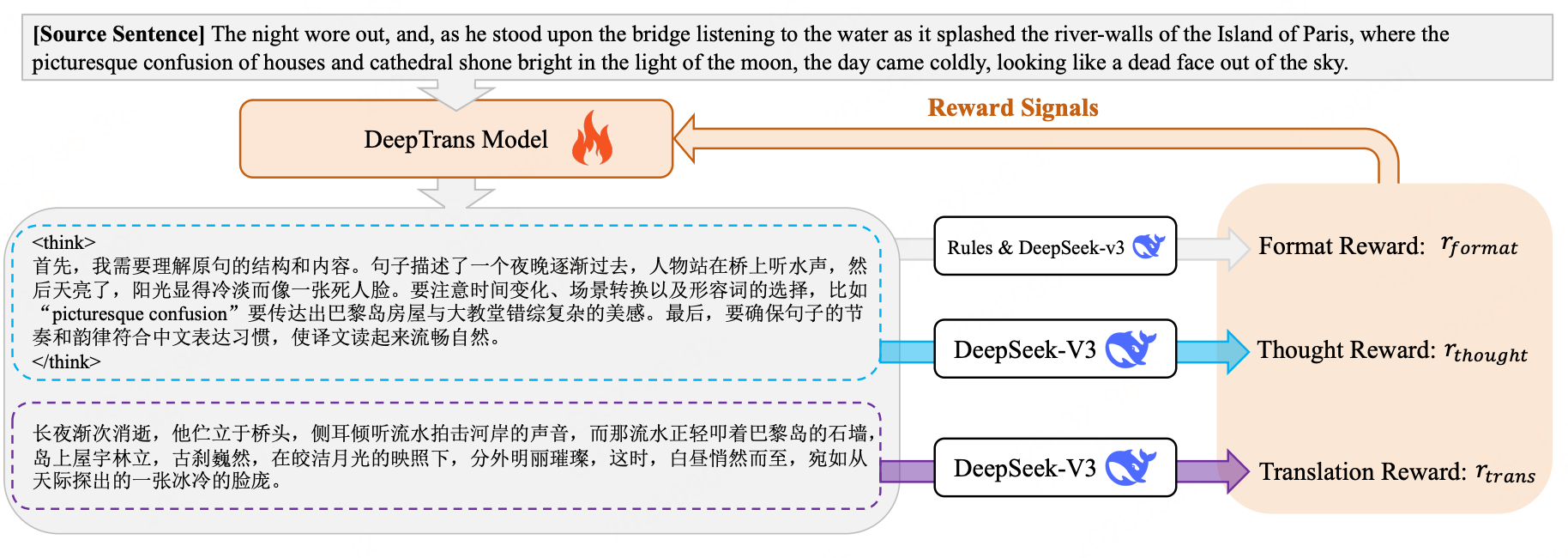
奖励函数设计
格式奖励
模型生成格式: “< think > [thought]< /think> [translation]”,其中 “< think>” 和“< /think>” 是两个特殊 token,用于表示思考内容的边界。“[thought]” 和 “[translation]” 分别表示思考内容和翻译内容。
使用deepseek判断翻译结果是否仅包含翻译内容判断prmopt如下

同时满足(a)生成格式正确(由正则表达式判断),且(b)翻译结果不包含任何解释(由 DeepSeek-v3 判断),则认为格式正确;否则视为不正确。
思维奖励
思维奖励的目标是鼓励模型生成针对原文的具体、详细推理过程,通过 DeepSeek-v3 按 3 分制评分。

作用:避免模型“跳过推理直接翻译”,确保推理过程对翻译质量有实际指导意义(尤其针对文学翻译中的隐喻、文化背景)。

翻译奖励

翻译奖励的目标是评估译文的流畅性、语义准确性、文学性(针对文学翻译场景),通过DeepSeek-v3按 100分制 评分,评分标准细化为5个梯度,每个梯度对应明确的质量要求。
综合奖励
综合奖励将上述三个模块整合,格式正确是前提,在此基础上平衡推理质量与翻译质量。计算公式为:
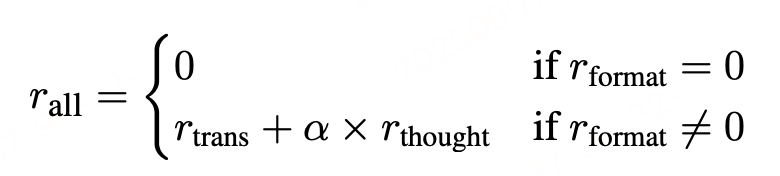
参考文献:DeepTrans: Deep Reasoning Translation via Reinforcement Learning,https://arxiv.org/pdf/2504.10187v2
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)