
2025.10.21-强化学习入门
此外,我们还注意到:在训练初期,随机初始化的奖励预测器(reward predictor)与批评家网络(critic networks)可能产生较大的预测奖励值,从而延迟学习的启动。由于批评家(critic)的回归目标依赖于其自身的预测值,我们通过正则化手段将其预测结果约束为趋近于其自身参数的指数移动平均(exponentially moving average)所输出的结果,从而稳定训练过程。在
常见符号
s, s′ states,状态
a action,动作
r reward,奖励
R reward function,奖励函数
R 是奖励函数,Rt = R(St) 是 MRP (Markov Reward Process(马尔可夫奖励过程))中状态 St 的奖励,Rt = R(St, At) 是 MDP (马尔可夫决策过程)中的奖励, St ∈ S。

MRP 是 MDP(Markov Decision Process, 马尔可夫决策过程) 的特例
MRP = MDP + 固定策略(policy),当在一个 MDP 中固定一个策略 π(a∣s) 后,就得到一个对应的 MRP。
部分涉及概念:
自举(Bootstrapping):从现有数据中随机抽样(有放回),生成大量“新样本集”,用这些样本集计算统计量,从而估计总体参数的分布或误差。
TD 误差(Temporal Difference Error):强化学习中预测值与目标值之间的差异(预测的回报和实际发生的回报差了多少)
好的策略:哪个策略能在环境中长期稳定地得到高分(得到更多的奖励值),就是好的策略;反之,就是不好的策略
马尔可夫:满足下面式子(不会随着更久以前的状态的加入而改变),就可以称状态S 是马尔可夫的(或者 是满足马尔可夫的)
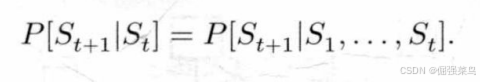
KL 散度(Kullback–Leibler Divergence):
衡量两个概率分布差异的指标。KL 散度衡量“用分布 Q 近似真实分布 P”时,平均会损失多少信息。
-
如果 P=Q,KL 散度 = 0;
-
两者差异越大,KL 散度越大。
OpenAI Gym:OpenAI 发布的一个 强化学习环境库
| 类别 | 示例环境 | 说明 |
|---|---|---|
| Classic Control | CartPole, MountainCar, Acrobot |
经典物理控制问题 |
| Box2D | LunarLander, BipedalWalker |
物理仿真环境 |
| Atari | Pong, Breakout, SpaceInvaders |
基于 Atari 游戏,图像输入 |
| MuJoCo | Hopper, Ant, Humanoid |
高维连续控制(机器人运动) |
| ToyText | FrozenLake, Taxi |
简单离散状态环境 |
| Custom Envs | 用户自定义环境 | 通过继承 gym.Env 创建 |
经典强化学习
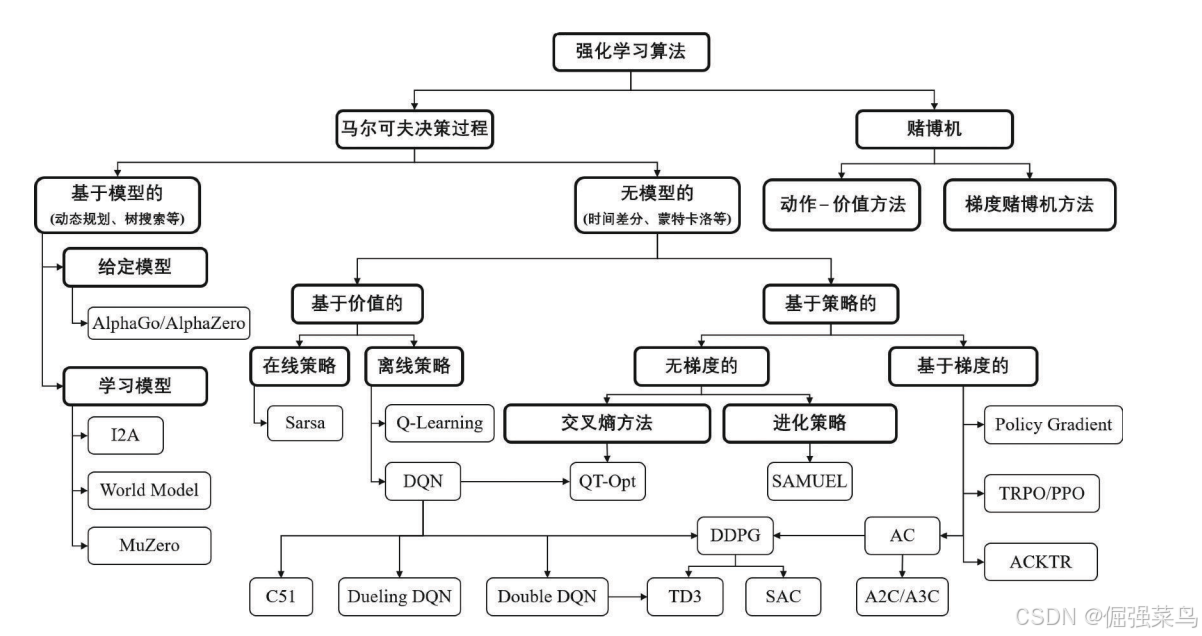
强化学习核心:计算状态s的价值 v(s)
蒙特卡罗算法:
本质就是用“随机”来解决“算不清”的问题。
“模拟大量随机事件,统计结果”
Q-learning算法:
也是时间差分算法,属于离线策略。
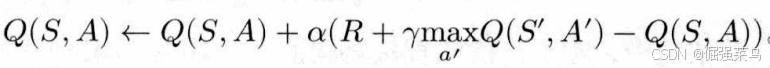
深度强化学习:
DQN(Deep Q-Network)
DQN是一种结合了 深度学习 和 强化学习(Reinforcement Learning, RL) 的算法,用一个 卷积神经网络(CNN) 来输入环境状态(比如游戏画面),输出所有可能动作的 Q 值。
DQN 的关键技术点:
(1)经验回放(Experience Replay)
-
把每次交互得到的
(s, a, r, s')存进一个 经验池。 -
训练时 随机采样小批量数据(mini-batch),打乱数据的相关性。
(2)目标网络(Target Network)
目标网络提供了一个估值供主网络作为标签值去学习,目标网络的参数每隔一段时间赋值为主网络的参数(这样可以避免目标值不断变化导致训练震荡。)
训练过程:
- 初始化 Q 网络和目标网络参数;
- 初始化经验回放池;
-
对每个时间步:
-
以 ε-贪心策略选择动作(探索 vs 利用);
-
执行动作、观察奖励和下一个状态;
-
存储
(s, a, r, s')到经验池; -
从经验池随机采样一批数据;
-
计算目标值并最小化损失:
-
更新 Q 网络参数;
-
定期将 Q 网络参数复制到目标网络。
-
Actor-Critic 模式
Actor角色:一个相对独立的模型,任务就是学动作
Critic角色:也是一个相对独立的模型,目的是学习估值的大小。
优点:更新是连续的(主要是指 Critic 角色),一般是通过梯度单步更新的,因此,更新 的反馈比蒙特卡罗法要好(一个Episode 结束才能进行更新)。此外,由于更新的连续性,方差也比较小,这样模型收敛的稳定性会高一些。
缺点:需要更新两个模型,且其中一个会直接影响另一个。如果 Critic 模型学出来的东西都是错的,那么 Actor 模型根本不可能学到一个好的动作策略。
世界模型Dreamer-v3
Dreamer学习环境模型并通过想象未来场景来改进其行为。基于归一化、平衡和转换的鲁棒性技术可实现跨领域的稳定学习。该算法基于学习世界模型的想法,该模型使智能体具有丰富的感知和想象未来的能力。世界模型预测潜在行动的结果,批评神经网络判断每个结果的价值,行动者神经网络选择行动以达到最佳结果。
与之前的强化学习(PPO)的差别:一种无需重新配置即可学习掌握新领域的通用算法,使强化学习很容易适用于新问题。
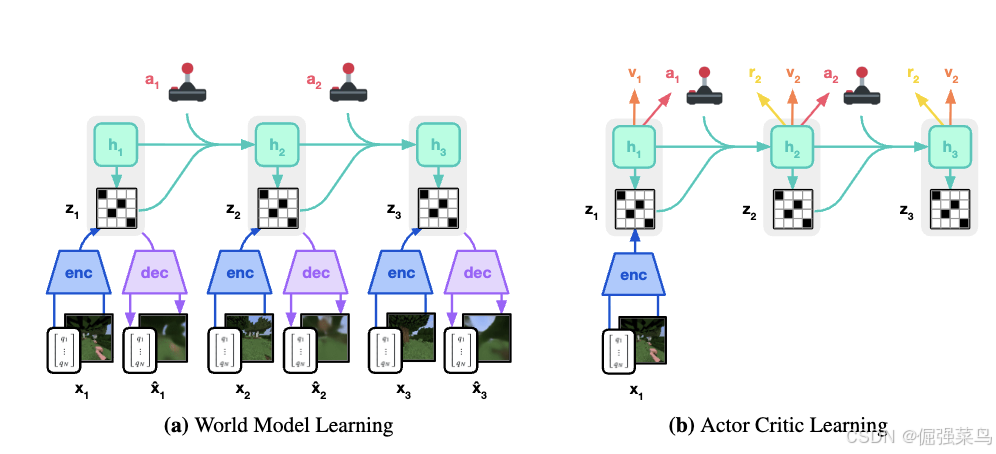
图1
这2幅图的理解:
世界模型encoder将x输入编码为离散的表征z,并由带有递归状态 hₜ 的序列模型在给定动作 aₜ 的情况下对这些表征进行预测。输入被重建获得表征的shape。actor(策略网络) 和 critic(价值网络) 使用世界模型预测得到的抽象表征序列来分别预测动作 aₜ 和价值 vₜ,并从这些抽象轨迹中进行学习。
该算法由三个神经网路构成:世界模型预测潜在actions的结果, critic判断每个结果的价值,actor选择可以达到最有价值的结果。
世界模型学习
世界模型通过 自编码 的方式学习感官输入的紧凑表征,并通过预测潜在动作所带来的未来表征和奖励,实现规划能力。
使用模型的是 Recurrent State-Space Model (RSSM),如图1。

encoder和decoder使用CNN用于图片输入,多层感知器 (MLP) 用于向量(vector)输入,dynamics, reward, and continue predictors 也使用MLP。
给定一个序列batch(输入x₁:T、动作 a₁:T、奖励 r₁:T、持续标记 c₁:T)世界模型的参数 ϕ 通过端到端方式进行优化,以最小化以下损失:
-
预测损失 Lpred
-
dynamics loss Ldyn
-
表征损失 Lrep
三者分别对应的损失权重为:![]()
![]()
预测损失(prediction loss)使用后文介绍的 symlog 平方损失 来训练解码器和奖励预测器,并使用 逻辑回归 来训练持续性(continue)预测器。
dynamics loss 用于训练序列模型,使其能预测下一个表征,通过最小化![]() 和下一个随机表征
和下一个随机表征![]() 之间的 KL 散度实现
之间的 KL 散度实现
表征损失(representation loss) 则用于训练表征,使其更加可预测,从而允许我们在想象训练(imagination training)中使用 分解式的动力学预测器(factorized dynamics predictor) 以实现快速采样。
动力学损失(dynamics loss)与表征损失(representation loss)的区别在于stop-gradient operator sg(·)和损失尺度(loss scale)
为了避免出现退化情况:动力学(dynamics)非常容易预测,但表征却不包含足够的输入信息,我们使用 free bits 技巧,将动力学损失和表征损失裁剪到低于 1 nat(约等于 1.44 bits)。
当这两个损失已经充分优化(小于该阈值)时,它们会被禁用,从而专注于预测损失(prediction loss)。
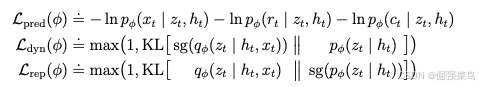
以往的世界模型需要根据环境的视觉复杂度,对表征损失使用 不同的缩放方式。在复杂的 3D 环境中,存在许多对控制无关的细节,因此需要更强的正则化来简化表征,让其更可预测。而在具有静态背景、且单个像素可能关乎任务表现的游戏中,则需要更弱的正则化,以便提取细粒度的细节。我们发现,将 free bits 与 较小的表征损失 结合使用可以解决这一矛盾,使得超参数可以在不同领域中保持固定。此外,我们使用后文介绍的 symlog 函数 来转换向量类型的观测值,以避免较大的输入值及其引起的巨大重建梯度,从而进一步稳定与表征损失之间的权衡。
在早期实验中,我们偶尔观察到 KL 损失的峰值,这与深度变分自编码器(VAE)的相关报告一致。为避免这一问题,我们将编码器和动力学预测器输出的分类分布参数化为 1% 的均匀分布 + 99% 的神经网络输出 的混合形式,使其无法变成确定性分布,从而保证 KL 损失在训练中保持稳定。
价值网络学习(Critic learning)
Actor(策略网络)和 Critic(价值网络)仅通过 世界模型预测得到的抽象表征轨迹 来学习行为,而不直接依赖真实环境数据。在与环境交互时,我们通过从actor network采样来选择行为,而不进行前瞻式规划(lookahead planning)。Actor 和 Critic 都作用于模型状态![]()
因此能够从循环世界模型学习到的 马尔可夫表征 中获益。Actor 的目标是在每个模型状态下最大化回报![]() 其中
其中![]()
为了考虑超过预测范围 T = 16 之外的奖励,Critic 学习去近似在当前 actor 行为策略下,每个状态对应的 回报分布。
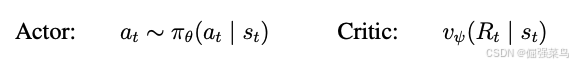
从重新放入(replayed inputs)的表征开始,世界模型和 actor 会生成一段想象轨迹,包括![]()
因为critic预测一个分布,我们将他的预测值![]() 作为这个分布的期望值。为了估计能够考虑超出预测范围(T)以外奖励的回报,我们计算 bootstrapped λ-return,它结合了预测的奖励和价值。Critic 学习预测这个分布,这个分布使用最大似然损失(maximum likelihood loss)返回估计值
作为这个分布的期望值。为了估计能够考虑超出预测范围(T)以外奖励的回报,我们计算 bootstrapped λ-return,它结合了预测的奖励和价值。Critic 学习预测这个分布,这个分布使用最大似然损失(maximum likelihood loss)返回估计值![]()
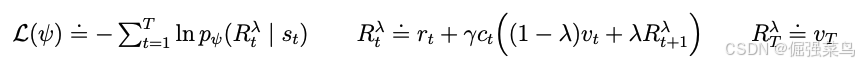
虽然可以将 critic 简单地参数化为 正态分布,但实际中回报分布往往具有多模态,并且在不同环境之间其数量级可能相差数个数量级。为了在这种条件下稳定并加速学习,我们将 critic 参数化为 具有指数间隔(exponentially spaced bins)的分类分布,这种做法将梯度的尺度与预测目标的取值范围解耦。为了在奖励难以预测的环境中提升 value 的预测质量,我们对两个来源的轨迹同时施加 critic 损失:
- 想象轨迹(imagination trajectories),损失权重
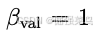
- 重放缓冲(replay buffer)中的采样轨迹

批评家回放缓冲区损失(critic replay loss)利用想象轨迹起始状态处的想象回报 Rλ 作为回放缓冲区轨迹的“在线策略”价值标签(on-policy value annotations),进而基于回放缓冲区中的奖励计算 λ-回报(λ-returns)。
由于批评家(critic)的回归目标依赖于其自身的预测值,我们通过正则化手段将其预测结果约束为趋近于其自身参数的指数移动平均(exponentially moving average)所输出的结果,从而稳定训练过程。这一做法与先前强化学习中使用的目标网络(target networks)类似,但允许我们直接使用当前批评家网络来计算回报(returns)。此外,我们还注意到:在训练初期,随机初始化的奖励预测器(reward predictor)与批评家网络(critic networks)可能产生较大的预测奖励值,从而延迟学习的启动。为此,我们将奖励预测器和批评家的输出层权重矩阵初始化为零;这一措施有效缓解了上述问题,并显著加快了早期学习(early learning)进程。
策略网络学习(Actor learning)
Actor 通过一个 熵正则项 来进行探索,同时学习选择能够最大化回报的动作。然而,这个正则项的合适权重取决于环境中奖励的尺度和出现频率。
理想情况下:
-
如果奖励 稀疏,智能体应当 更多探索;
-
如果奖励 密集或容易获得,智能体应当 更多利用(exploit)。
同时,探索量不应受到环境中奖励数值的任意缩放影响。为此,需要对回报尺度进行归一化,同时保留关于奖励出现频率的信息。
为了在不同环境中都能使用固定的熵系数η = 3 × 10−4,我们将returns进行归一化,使其大致落在区间 [0, 1] 内。在实际操作中,从returns中减去一个偏移量(offset)并不会改变 actor 的梯度,因此只需用一个范围 S 对returns进行除法即可。此外,为了避免在奖励稀疏的情况下,由于函数逼近带来的噪声被过度放大,我们仅对较大的return数值进行缩放,而将小于阈值L=1的return保持不变。我们对 离散动作 和 连续动作 都使用 Reinforce 估计器,从而得到如下的代理损失函数(surrogate loss function):
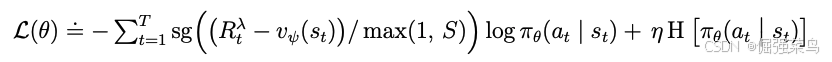
回报分布可能是 多峰的(multi-modal),并且可能包含 离群值(outliers),尤其是在随机化环境中,不同的 episode 可能具有不同的最高可达回报。如果直接用最小和最大回报来归一化,那么整体回报会被缩放得过小,从而导致次优收敛(suboptimal convergence)。为了使归一化对离群值更加稳健,我们使用以下方法:
-
在回报(return)批次中计算 第 5 百分位数(5th percentile) 到 第 95 百分位数(95th percentile) 之间的范围;
-
并使用 指数滑动平均(EMA) 来对这一范围进行平滑处理。
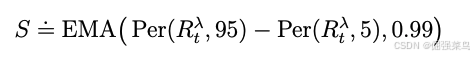
以往的研究通常对 优势函数(advantage) 进行归一化,而不是对return进行归一化。这种做法会让“最大化回报”相对于“增加熵”的侧重点保持恒定,而不考虑奖励是否实际可获得。
-
当奖励 稀疏 时,如果将优势放大,可能会同时放大噪声,使得噪声的影响超过熵正则,从而导致探索停滞。
-
用标准差对奖励或回报归一化,在奖励稀疏时会失效,因为它们的标准差接近 0,这会极大地放大奖励,无论奖励本身多小。
-
“约束优化”方法在所有状态上固定平均熵,这虽然稳健,但在奖励稀疏时探索会非常慢,而在奖励密集时收敛到较低性能。
我们发现这些方法都难以在不同环境间找到稳定的超参数。使用 带有下限的回报归一化(return normalization with a denominator limit)能克服上述问题:
-
在奖励稀疏时,能够快速探索;
-
在不同环境中都能收敛到较高性能。
稳健预测(Robust predictions)
重建输入(Reconstructing inputs)以及预测奖励和回报(rewards and returns)是具有挑战性的任务,因为这些量的数值尺度在不同领域之间可能差异巨大。如果用平方损失(squared loss)来预测数值很大的目标,可能会导致训练发散;而绝对损失(L1)和 Huber 损失则会让学习停滞。另一方面,基于运行统计量对目标进行归一化会给优化过程引入非平稳性。为了解决这一困境,我们提出使用 symlog 平方误差(symlog squared error) 作为一种简单的解决方案。具体地,一个具有输入 x和参数 θ的神经网络 f(x,θ)学习去预测目标 y的某种变换版本。为了读取网络的预测值 ![]() ,我们应用逆变换:
,我们应用逆变换:
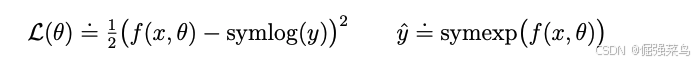
如果直接使用对数作为变换函数,将无法预测取负值的目标。因此,我们从 双对称对数函数族(bi-symmetric logarithmic family) 中选择了一个函数作为变换,并将其称为 symlog;其逆变换称为 symexp。
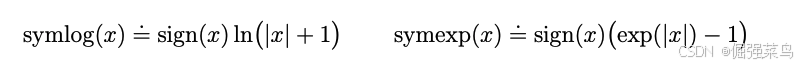
symlog 函数能够压缩 正值和负值 的大幅数值。与普通对数函数不同,它在原点附近是对称的,同时保留输入的符号。这使得在需要时,优化过程能够快速将网络的预测推向较大的数值。同时,symlog 函数在原点附近近似于恒等变换,这意味着对于那些本身数值就很小的目标,它不会影响学习过程。
对于可能具有随机性的目标(如奖励或回报),我们引入了 symexp twohot loss。在该方法中,网络输出的是一个 softmax 分布 在指数间隔的桶(bins)上的 logits(he network outputs the logits for a softmax distribution over exponentially spaced bins)![]()
网络的预测值通过各桶(bin)位置的加权平均来读取,权重为网络预测的概率。重要的是,由于加权平均可以落在桶(buckets)之间,网络因此可以输出区间内的 任意连续值。
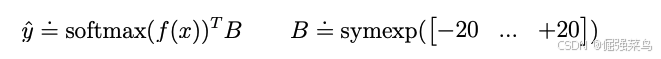
网络使用 twohot 编码的目标 进行训练,这是一种将 onehot 编码推广到连续值的方法。具体来说,一个标量的 twohot 编码是一个长度为 ∣B∣的向量,除了与该标量最接近的 两个桶(bins)索引 k 和 k+1 外,其余位置均为 0。这两个非零条目(entries)的和为 1,并且离连续数值更近的桶获得更高的线性权重。然后,网络通过最小化 带软标签(soft targets)的分类交叉熵损失(categorical cross-entropy loss) 来训练。需要注意的是,这个损失只依赖于网络分配给各桶的概率,而不依赖于桶位置对应的连续数值,从而实现了梯度大小与目标数值大小的解耦。
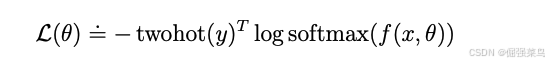
应用这些原则,Dreamer 对向量观测值使用 symlog 函数 进行变换,包括编码器的输入和解码器的目标,同时对奖励预测器(reward predictor)和 critic 使用 symexp twohot loss。我们发现,这些技术能够在多种不同领域中实现稳健且快速的学习。在 critic learning方面,之前曾提出过一种非对称变换(asymmetric transformation),但我们发现其在不同领域上的平均效果不如 symlog。其他方法不同,symlog 变换避免了截断大数值目标,归一化引入的非平稳性,在检测到新的极端值时调整网络权重。
结论
Dreamer 算法的第三代版本,这是一种通用的强化学习算法,能够在固定超参数下掌握广泛的任务领域。Dreamer 不仅在 150 多个任务 中表现出色,而且能够在不同的数据量和计算资源下进行稳健学习,将强化学习推向更广泛的实际应用。开箱即用时,Dreamer 是首个能够 从零开始在 Minecraft 中收集钻石(diamonds) 的算法,标志着人工智能领域的重要里程碑。作为一种基于 学习到的世界模型(learned world model) 的高性能算法,Dreamer 为未来的研究方向铺平了道路,包括:通过互联网视频向智能体教授世界知识;在不同领域中学习单一世界模型,使人工智能能够逐步积累更加通用的知识与能力。
原文:https://arxiv.org/abs/2301.04104
表征学习
旨在通过自动学习数据的有效表示(representations)来提高模型对任务的理解和泛化能力,让模型自动从原始数据中提取特征,而不是依赖人工设计特征。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)