
强化学习SAC和TQC训练gymnasium-robotics中的机械臂任务FetchReach-v4、FetchPush-v4、FetchSlide-v4、FetchPickAndPlace-v4
本文介绍了在Ubuntu 20.04上实现FetchReach机器人任务训练的完整流程。首先详细说明了环境配置步骤,包括MuJoCo210、gymnasium-robotics、PyTorch和stable-baselines3等必要组件的安装方法。然后提供了一个基于SAC算法的训练脚本,该脚本支持三种操作模式:1)从头训练模型,2)继续训练现有模型,3)加载最佳模型进行推理演示。代码实现了训练进
·
1 安装
(1)安装mujoco210
Ubuntu 20.04上安装MuJoCo 210
(2)安装gymnasium-robotics
pip install gymnasium-robotics[mujoco-py]
(3)安装stable-baseline3
根据显卡驱动安装对应版本的torch
pip install --index-url https://download.pytorch.org/whl/cu126 torch torchvision torchaudio --upgrade
pip install stable-baselines3 torch==2.9.0+cu126
pip install sb3-contrib
(4)其他包
pip install tensorboard
pip intall h5py
2 代码
2.1 SAC 算法
import gymnasium as gym
import os
import signal
import sys
from stable_baselines3 import SAC
from stable_baselines3.common.callbacks import EvalCallback, CheckpointCallback
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.her import HerReplayBuffer
from stable_baselines3.common.callbacks import BaseCallback
# 自定义CheckpointCallback以保存replay_buffer
class CustomCheckpointCallback(CheckpointCallback):
def _on_step(self) -> bool:
if self.n_calls % self.save_freq == 0:
model_path = os.path.join(self.save_path, f"{self.name_prefix}_{self.num_timesteps}_steps")
self.model.save(model_path)
self.model.save_replay_buffer(model_path + "_replay_buffer")
if self.verbose > 1:
print(f"Saving checkpoint to {model_path}")
return super()._on_step()
# 日志目录
log_dir = "./fetch_logs/"
os.makedirs(log_dir, exist_ok=True)
# 环境ID(使用v3,根据Gymnasium-Robotics文档;若需v4,替换)
env_id = "FetchReach-v3"
# 训练和评估环境(无render)
train_env = gym.make(env_id)
eval_env = gym.make(env_id)
# HER参数
goal_selection_strategy = "future"
# 中断处理:保存当前模型和buffer
def signal_handler(sig, frame):
print("Interrupt received! Saving current model and replay buffer...")
if 'model' in globals():
model.save(os.path.join(log_dir, "latest_model"))
model.save_replay_buffer(os.path.join(log_dir, "latest_replay_buffer"))
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
# 创建模型函数
def make_model(env):
return SAC(
"MultiInputPolicy",
env,
replay_buffer_class=HerReplayBuffer,
replay_buffer_kwargs=dict(
n_sampled_goal=4,
goal_selection_strategy=goal_selection_strategy,
),
verbose=1,
tensorboard_log=log_dir,
buffer_size=1000000, # 可调整
)
# 用户选择
choice = input("Enter 1 to train from scratch, 2 to continue training, 3 to infer: ").strip()
if choice == '1':
# 从头训练
model = make_model(train_env)
# 回调:评估并保存最佳,自定义checkpoint保存buffer
eval_callback = EvalCallback(eval_env, best_model_save_path=log_dir, log_path=log_dir, eval_freq=10000, n_eval_episodes=10, deterministic=True)
checkpoint_callback = CustomCheckpointCallback(save_freq=10000, save_path=log_dir, name_prefix="sac_checkpoint")
# 训练(总步数可调整)
model.learn(total_timesteps=100000, callback=[eval_callback, checkpoint_callback], log_interval=4)
# 最终评估
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"Final mean reward: {mean_reward:.2f} +/- {std_reward:.2f}")
# 保存最终模型和buffer
model.save(os.path.join(log_dir, "final_model"))
model.save_replay_buffer(os.path.join(log_dir, "final_replay_buffer"))
elif choice == '2':
# 继续训练
model_path = os.path.join(log_dir, "latest_model")
replay_path = os.path.join(log_dir, "latest_replay_buffer")
if not os.path.exists(model_path + ".zip"):
print("No latest model found, starting from scratch.")
model = make_model(train_env)
else:
model = SAC.load(model_path, env=train_env)
if os.path.exists(replay_path):
model.load_replay_buffer(replay_path)
else:
print("No replay buffer found, continuing with empty buffer.")
# 回调同上
eval_callback = EvalCallback(eval_env, best_model_save_path=log_dir, log_path=log_dir, eval_freq=10000, n_eval_episodes=10, deterministic=True)
checkpoint_callback = CustomCheckpointCallback(save_freq=10000, save_path=log_dir, name_prefix="sac_checkpoint")
# 继续训练(不重置时序)
model.learn(total_timesteps=100000, callback=[eval_callback, checkpoint_callback], log_interval=4, reset_num_timesteps=False)
# 最终评估
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"Final mean reward: {mean_reward:.2f} +/- {std_reward:.2f}")
# 保存最终
model.save(os.path.join(log_dir, "final_model"))
model.save_replay_buffer(os.path.join(log_dir, "final_replay_buffer"))
elif choice == '3':
# 加载最佳模型推理并渲染
best_path = os.path.join(log_dir, "best_model")
if not os.path.exists(best_path + ".zip"):
print("No best model found.")
sys.exit(1)
# 推理环境(带渲染)
infer_env = gym.make(env_id, render_mode="human")
model = SAC.load(best_path, env=infer_env) # 无需buffer for infer
# 运行10个episode渲染
for episode in range(10):
obs, _ = infer_env.reset()
done = False
total_reward = 0
while not done:
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, _ = infer_env.step(action)
infer_env.render()
total_reward += reward
done = terminated or truncated
print(f"Episode {episode + 1} reward: {total_reward}")
infer_env.close()
else:
print("Invalid choice.")
2.2 TQC算法
以下是最佳训练参数,将四个文件放在config文件夹下
FetchReach-v4.txt
OrderedDict([('batch_size', 256),
('buffer_size', 1000000),
('ent_coef', 'auto'),
('env_wrapper', 'sb3_contrib.common.wrappers.TimeFeatureWrapper'),
('gamma', 0.95),
('learning_rate', 0.001),
('learning_starts', 1000),
('n_timesteps', 20000.0),
('normalize', True),
('policy', 'MultiInputPolicy'),
('policy_kwargs', 'dict(net_arch=[64, 64], n_critics=1)'),
('replay_buffer_class', 'HerReplayBuffer'),
('replay_buffer_kwargs',
"dict( online_sampling=True, goal_selection_strategy='future', "
'n_sampled_goal=4 )'),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
FetchPush-v4.txt
OrderedDict([('batch_size', 512),
('buffer_size', 1000000),
('env_wrapper', 'sb3_contrib.common.wrappers.TimeFeatureWrapper'),
('gamma', 0.98),
('learning_rate', 0.001),
('n_timesteps', 1000000.0),
('policy', 'MultiInputPolicy'),
('policy_kwargs', 'dict(net_arch=[512, 512, 512], n_critics=2)'),
('replay_buffer_class', 'HerReplayBuffer'),
('replay_buffer_kwargs',
"dict( online_sampling=True, goal_selection_strategy='future', "
'n_sampled_goal=4, max_episode_length=100 )'),
('tau', 0.005),
('normalize', False)])
FetchSlide-v4.txt
OrderedDict([('batch_size', 512),
('buffer_size', 1000000),
('env_wrapper', 'sb3_contrib.common.wrappers.TimeFeatureWrapper'),
('gamma', 0.98),
('learning_rate', 0.001),
('n_timesteps', 3000000.0),
('policy', 'MultiInputPolicy'),
('policy_kwargs', 'dict(net_arch=[512, 512, 512], n_critics=2)'),
('replay_buffer_class', 'HerReplayBuffer'),
('replay_buffer_kwargs',
"dict( online_sampling=True, goal_selection_strategy='future', "
'n_sampled_goal=4, max_episode_length=100 )'),
('tau', 0.005),
('normalize', False)])
FetchPickAndPlace-v4.txt
OrderedDict([('batch_size', 512),
('buffer_size', 1000000),
('env_wrapper', 'sb3_contrib.common.wrappers.TimeFeatureWrapper'),
('gamma', 0.98),
('learning_rate', 0.001),
('n_timesteps', 1000000.0),
('policy', 'MultiInputPolicy'),
('policy_kwargs', 'dict(net_arch=[512, 512, 512], n_critics=2)'),
('replay_buffer_class', 'HerReplayBuffer'),
('replay_buffer_kwargs',
"dict( online_sampling=True, goal_selection_strategy='future', "
'n_sampled_goal=4, max_episode_length=100 )'),
('tau', 0.005),
('normalize', False)])
import gymnasium as gym
import gymnasium_robotics
import os
import sys
import argparse
import h5py
import numpy as np
import collections
import importlib
import warnings
from pathlib import Path
from stable_baselines3.common.callbacks import EvalCallback, CheckpointCallback
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.her import HerReplayBuffer
from stable_baselines3.common.vec_env import SubprocVecEnv, DummyVecEnv, VecNormalize
from stable_baselines3.common.env_util import make_vec_env
from sb3_contrib import TQC # 从SB3-Contrib导入TQC
gym.register_envs(gymnasium_robotics)
# 加载参数文件
def load_params(env_id):
file_map = {
"FetchReach-v4": "config/FetchReach-v4.txt",
"FetchPush-v4": "config/FetchPush-v4.txt",
"FetchSlide-v4": "config/FetchSlide-v4.txt", # 注意文件名为v1,但用于v4环境
"FetchPickAndPlace-v4": "config/FetchPickAndPlace-v4.txt"
}
file_path = file_map.get(env_id)
if not file_path:
raise ValueError(f"No parameter file for environment {env_id}")
with open(file_path, 'r') as f:
content = f.read()
try:
# 使用eval解析OrderedDict
params = eval(content, {"OrderedDict": collections.OrderedDict})
except Exception as e:
raise ValueError(f"Error parsing params file {file_path}: {e}")
return params
# 自定义CheckpointCallback以保存replay_buffer和vec_normalize(如果存在)
class CustomCheckpointCallback(CheckpointCallback):
def _on_step(self) -> bool:
if self.n_calls % self.save_freq == 0:
model_path = os.path.join(self.save_path, f"{self.name_prefix}_{self.num_timesteps}_steps")
self.model.save(model_path)
self.model.save_replay_buffer(model_path + "_replay_buffer")
if self.model._vec_normalize_env is not None:
self.model._vec_normalize_env.save(model_path + "_vec_normalize.pkl")
if self.verbose > 1:
print(f"Saving checkpoint to {model_path}")
return super()._on_step()
# 自定义EvalCallback以保存best_vec_normalize(如果存在)
class CustomEvalCallback(EvalCallback):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
if self.log_path is not None:
self.log_path = Path(self.log_path)
self.log_path.mkdir(parents=True, exist_ok=True)
def _sync_env_norms(self, training_env, eval_env):
if hasattr(training_env, 'obs_rms'):
eval_env.obs_rms = training_env.obs_rms.copy()
eval_env.clip_obs = training_env.clip_obs
# 注意:不同步ret_rms,因为它不向后兼容
def _do_rollout(self, is_deterministic):
obs = self.eval_env.reset()
episode_reward = 0.0
episode_length = 0
done = False
while not done:
action, _ = self.model.predict(obs, deterministic=is_deterministic)
new_obs, rewards, dones, infos = self.eval_env.step(action)
episode_reward += rewards[0]
episode_length += 1
done = dones[0]
info = infos[0]
obs = new_obs
if "is_success" in info:
self._is_success_buffer.append(info["is_success"])
return episode_reward, episode_length
def _on_step(self) -> bool:
continue_training = True
if self.n_calls % self.eval_freq == 0:
# Sync training and eval env if there is VecNormalize
if self.model.get_vec_normalize_env() is not None:
self._sync_env_norms(self.training_env, self.eval_env)
# Reset success rate buffer
self._is_success_buffer = []
episode_rewards, episode_lengths = [], []
is_deterministic = self.deterministic
if not self.deterministic and self.warn:
warnings.warn(
"evaluate_policy will use 'deterministic=True' instead of 'deterministic=False' for evaluation "
"in a future version of Stable Baselines3. Please pass `deterministic` to `evaluate_policy` instead.",
FutureWarning,
)
is_deterministic = True
for _ in range(self.n_eval_episodes):
# Do rollouts
episode_reward, episode_length = self._do_rollout(is_deterministic)
episode_rewards.append(episode_reward)
episode_lengths.append(episode_length)
if self.log_path is not None:
np.save(self.log_path / "episode_rewards.npy", episode_rewards)
np.save(self.log_path / "episode_lengths.npy", episode_lengths)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
if self.verbose >= 1:
print(f"Eval mean reward: {mean_reward:.2f} +/- {std_reward:.2f}")
# Add to current Logger
self.logger.record("eval/mean_reward", float(mean_reward))
self.logger.record("eval/mean_ep_length", np.mean(episode_lengths))
self.logger.record("eval/std_reward", float(std_reward))
if len(self._is_success_buffer) > 0:
success_rate = np.mean(self._is_success_buffer)
if self.verbose >= 1:
print(f"Success rate: {100 * success_rate:.2f}%")
self.logger.record("eval/success_rate", success_rate)
# Dump log so the evaluation results are printed with the correct timestep
self.logger.record("time/total_timesteps", self.model.num_timesteps, exclude="tensorboard")
self.logger.dump(self.model.num_timesteps)
if mean_reward > self.best_mean_reward:
if self.verbose >= 1:
print("New best mean reward!")
if self.best_model_save_path is not None:
self.model.save(os.path.join(self.best_model_save_path, "best_model"))
if self.model._vec_normalize_env is not None:
self.model._vec_normalize_env.save(os.path.join(self.best_model_save_path, "best_vec_normalize.pkl"))
self.best_mean_reward = mean_reward
# Trigger callback on new best model, if needed
if self.callback_on_new_best is not None:
continue_training = self.callback_on_new_best.on_step()
# Trigger callback if needed
if self.callback is not None:
continue_training = continue_training and self._on_event()
return continue_training
# 创建环境(支持VecEnv,支持wrapper但不包括normalize)
def create_env(env_id, render_mode=None, n_envs=1):
params = load_params(env_id)
def make_single_env():
env = gym.make(env_id, render_mode=render_mode)
if 'env_wrapper' in params:
wrapper_str = params['env_wrapper']
module_name, class_name = wrapper_str.rsplit('.', 1)
module = importlib.import_module(module_name)
wrapper_class = getattr(module, class_name)
env = wrapper_class(env)
return env
vec_env_cls = DummyVecEnv if n_envs == 1 else SubprocVecEnv
vec_env = vec_env_cls([make_single_env for _ in range(n_envs)])
return vec_env
# 创建模型(使用加载的参数配置TQC)
def create_model(env, log_dir, env_id):
params = load_params(env_id)
policy = params['policy']
replay_buffer_class = HerReplayBuffer # 假设总是HerReplayBuffer
replay_buffer_kwargs = eval(params['replay_buffer_kwargs'])
policy_kwargs = eval(params['policy_kwargs'])
tqc_kwargs = {
"policy": policy,
"env": env,
"replay_buffer_class": replay_buffer_class,
"replay_buffer_kwargs": replay_buffer_kwargs,
"policy_kwargs": policy_kwargs,
"verbose": 1,
"tensorboard_log": log_dir,
}
for key in ['batch_size', 'buffer_size', 'ent_coef', 'gamma', 'learning_rate', 'learning_starts', 'tau']:
if key in params:
tqc_kwargs[key] = params[key]
return TQC(**tqc_kwargs)
# 保存数据集到HDF5(从replay buffer采样)
def save_dataset(buffer, file_path):
# 采样整个buffer(或子集以节省空间)
batch_size = min(buffer.pos if buffer.full else buffer.buffer_size, 10000) # Limit to avoid OOM
data = buffer.sample(batch_size)
with h5py.File(file_path, 'w') as f:
# 保存非字典字段
for key in ['actions', 'rewards', 'dones']:
f.create_dataset(key, data=getattr(data, key).cpu().numpy())
# 保存observations和next_observations作为组
obs_group = f.create_group('observations')
for subkey, value in data.observations.items():
obs_group.create_dataset(subkey, data=value.cpu().numpy())
next_obs_group = f.create_group('next_observations')
for subkey, value in data.next_observations.items():
next_obs_group.create_dataset(subkey, data=value.cpu().numpy())
# 额外保存HER相关(从observations)
f.create_dataset('achieved_goals', data=data.observations['achieved_goal'].cpu().numpy())
f.create_dataset('desired_goals', data=data.observations['desired_goal'].cpu().numpy())
# 训练函数(通用,用于scratch或continue)
def train_model(model, eval_env, log_dir, total_timesteps=100000, reset_num_timesteps=True):
# 回调(增强评估,使用自定义EvalCallback)
eval_callback = CustomEvalCallback(eval_env, best_model_save_path=log_dir, log_path=log_dir, eval_freq=50000, n_eval_episodes=50, deterministic=True, warn=True)
checkpoint_callback = CustomCheckpointCallback(save_freq=10000, save_path=log_dir, name_prefix="tqc_checkpoint")
try:
# 训练
model.learn(total_timesteps=total_timesteps, callback=[eval_callback, checkpoint_callback], log_interval=4, reset_num_timesteps=reset_num_timesteps)
except KeyboardInterrupt:
print("Interrupt received! Saving current model and replay buffer...")
model.save(os.path.join(log_dir, "latest_model"))
model.save_replay_buffer(os.path.join(log_dir, "latest_replay_buffer"))
if model._vec_normalize_env is not None:
model._vec_normalize_env.save(os.path.join(log_dir, "latest_vec_normalize.pkl"))
sys.exit(0)
# 最终评估
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=50, deterministic=True)
print(f"Final mean reward: {mean_reward:.2f} +/- {std_reward:.2f}")
# 保存最终模型和buffer
model.save(os.path.join(log_dir, "final_model"))
model.save_replay_buffer(os.path.join(log_dir, "final_replay_buffer"))
if model._vec_normalize_env is not None:
model._vec_normalize_env.save(os.path.join(log_dir, "final_vec_normalize.pkl"))
# 保存数据集为HDF5
dataset_path = os.path.join(log_dir, "dataset.h5")
save_dataset(model.replay_buffer, dataset_path)
print(f"Dataset saved to {dataset_path}")
# 从头训练 (choice 1)
def train_from_scratch(env_id, log_dir, steps=None):
params = load_params(env_id)
train_steps = steps if steps is not None else params['n_timesteps']
# 创建环境并根据参数添加normalize
train_env = create_env(env_id, n_envs=1)
if params.get('normalize', False):
normalize_kwargs = params.get('normalize_kwargs', {})
train_env = VecNormalize(train_env, **normalize_kwargs)
eval_env = create_env(env_id, n_envs=1)
if params.get('normalize', False):
normalize_kwargs = params.get('normalize_kwargs', {})
eval_env = VecNormalize(eval_env, training=False, **normalize_kwargs)
model = create_model(train_env, log_dir, env_id)
train_model(model, eval_env, log_dir, total_timesteps=train_steps)
train_env.close()
eval_env.close()
# 继续训练 (choice 2)
def continue_training(env_id, log_dir, steps=None):
params = load_params(env_id)
total_timesteps = steps if steps is not None else params['n_timesteps']
# 创建环境并根据参数添加normalize
train_env = create_env(env_id, n_envs=1)
eval_env = create_env(env_id, n_envs=1)
if params.get('normalize', False):
normalize_kwargs = params.get('normalize_kwargs', {})
vec_path = os.path.join(log_dir, "latest_vec_normalize.pkl")
if os.path.exists(vec_path):
train_env = VecNormalize.load(vec_path, train_env)
else:
train_env = VecNormalize(train_env, **normalize_kwargs)
eval_env = VecNormalize(eval_env, training=False, **normalize_kwargs)
model_path = os.path.join(log_dir, "latest_model.zip")
replay_path = os.path.join(log_dir, "latest_replay_buffer")
if not os.path.exists(model_path):
print("No latest model found, starting from scratch.")
model = create_model(train_env, log_dir, env_id)
else:
model = TQC.load(model_path, env=train_env)
if os.path.exists(replay_path):
model.load_replay_buffer(replay_path)
else:
print("No replay buffer found, continuing with empty buffer.")
train_model(model, eval_env, log_dir, total_timesteps=total_timesteps, reset_num_timesteps=False)
train_env.close()
eval_env.close()
# 推理 (choice 3)
def perform_inference(env_id, log_dir):
best_path = os.path.join(log_dir, "best_model.zip")
if not os.path.exists(best_path):
print("No best model found.")
sys.exit(1)
params = load_params(env_id)
infer_env = create_env(env_id, render_mode="human", n_envs=1)
vec_path = os.path.join(log_dir, "best_vec_normalize.pkl")
if params.get('normalize', False):
normalize_kwargs = params.get('normalize_kwargs', {})
if os.path.exists(vec_path):
infer_env = VecNormalize.load(vec_path, infer_env)
else:
infer_env = VecNormalize(infer_env, training=False, **normalize_kwargs)
infer_env.training = False
model = TQC.load(best_path, env=infer_env) # 无需buffer for infer
# 运行10个episode渲染
for episode in range(10):
obs = infer_env.reset()
done = False
total_reward = 0
while not done:
action, _ = model.predict(obs, deterministic=True)
obs, rewards, dones, _ = infer_env.step(action)
infer_env.render()
total_reward += rewards[0]
done = dones[0]
print(f"Episode {episode + 1} reward: {total_reward}")
infer_env.close()
# 主函数
def main():
parser = argparse.ArgumentParser(description="Train or infer TQC on Fetch environment.")
parser.add_argument('--choice', type=int, choices=[1, 2, 3], required=True,
help='1: train from scratch, 2: continue training, 3: infer')
parser.add_argument('--env_id', type=str, default="FetchReach-v4",
choices=["FetchReach-v4", "FetchPush-v4", "FetchSlide-v4", "FetchPickAndPlace-v4"],
help='The environment ID to use.')
parser.add_argument('--steps', type=float, default=None, required=False,
help='Number of training steps (only for training options). If not provided, use from params file.')
args = parser.parse_args()
log_dir = f"./tqc_fetch_logs/{args.env_id}/"
os.makedirs(log_dir, exist_ok=True)
if args.choice == 1:
train_from_scratch(args.env_id, log_dir, args.steps)
elif args.choice == 2:
continue_training(args.env_id, log_dir, args.steps)
elif args.choice == 3:
perform_inference(args.env_id, log_dir)
if __name__ == "__main__":
main()
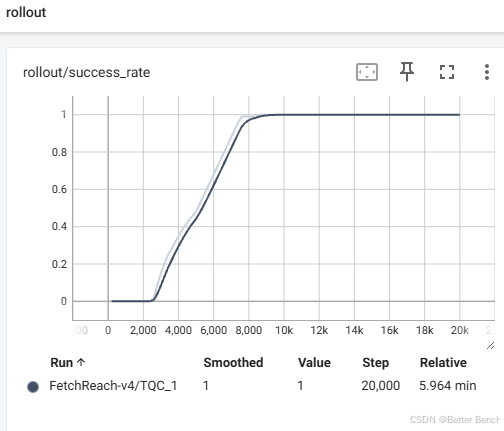
python tqc_fetch.py --choice 1 --env_id FetchReach-v4
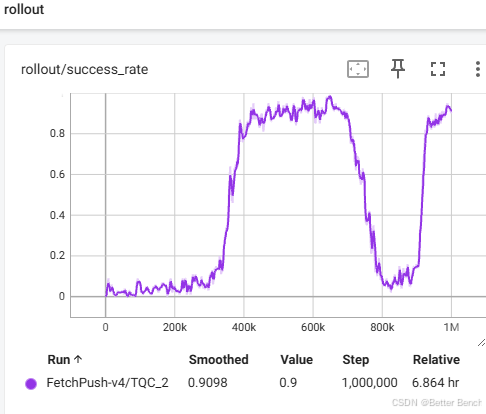
python tqc_fetch.py --choice 1 --env_id FetchPush-v4
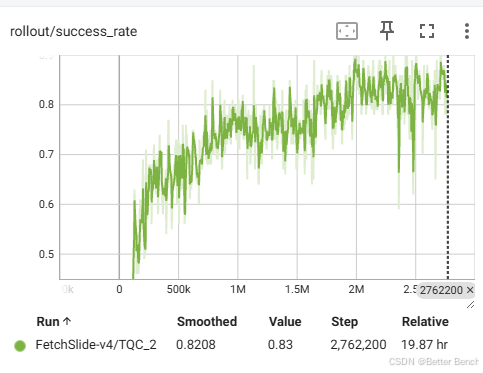
python tqc_fetch.py --choice 1 --env_id FetchSlide-v4
python tqc_fetch.py --choice 1 --env_id FetchPickAndPlace-v4
FetchReach-v4训练的时间大约6分钟
FetchPush-v4 训练的时间大约6.8小时
FetchSlide-v4 训练的时间大约20个小时
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)