
MFDA-YOLO:面向无人机小目标检测的多尺度特征融合与动态对齐网络
同时,为让AIFI模块更高效地提取关键信息,我们在输入处添加了1×1卷积层以实现通道压缩——这既完成了通道压缩、过滤冗余信息,也确保模块能高效聚焦于无人机检测中最显著的特征。为此,我们采用注意力驱动的尺度内特征交互(AIF)模块替代骨干网络中的SPPF模块——该模块通过单尺度注意力机制捕捉同尺度特征间的依赖关系,增强网络的聚焦能力。随后,经骨干网络增强的特征被输入颈部网络,由我们专门设计的DIDP
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
https://pmc.ncbi.nlm.nih.gov/articles/PMC12680328/
计算机视觉研究院专栏
Column of Computer Vision Institute
将YOLOv8等标准检测器应用于无人机航拍影像时,会面临尺度差异大、目标微小、背景复杂等显著挑战。其通用的特征融合架构易产生假阳性结果或遗漏小目标。为解决这些局限,我们提出一种基于YOLOv8改进的MFDA-YOLO模型。

PART/1
概述
该模型在骨干网络中引入注意力驱动的尺度内特征交互(AIF)模块,增强对多尺度目标的适应性并强化特征表示;在颈部网络中,设计无人机影像检测金字塔(DIDP)网络,整合空间转深度卷积模块,实现多尺度特征从浅层到深层的高效传递;通过在跨阶段局部网络中引入全核模块,恢复图像的全局上下文感知能力,同时消除计算负担,扩展传统的P2检测层。
针对检测头中定位与分类任务协同不足的问题,我们设计动态对齐检测头(DADH)——通过多尺度特征交互学习与动态特征选择机制,实现跨任务表示优化,大幅降低模型复杂度并保持检测精度。此外,我们采用WLoUv3损失函数,动态调整聚焦系数,增强模型对小目标的区分能力。
大量实验结果表明,MFDA-YOLO在VisDrone2019、HIT-UAV和NWPU VHR-10等数据集上,性能优于YOLOv11、YOLOv13等现有主流方法。特别是在VisDrone数据集上,MFDA-YOLO超越基准模型YOLOv8n:mAP0.5提升4.4个百分点,mAP0.5:0.95提升2.7个百分点;同时参数量减少17.2%,有效降低了假阴性与假阳性率。
PART/2
背景
随着科技的飞速发展,无人机(UAV)已广泛应用于农业、灾害救援、运输等领域。其灵活性、低成本与易操作性的优势显著,但无人机目标检测常面临尺度变化、动态视角、复杂背景、密集目标重叠等挑战,导致传统检测框架效果不佳。因此,研发适用于复杂环境的轻量化、高精度无人机小目标检测算法,具有重要的研究价值与应用潜力。
目标检测算法的精度与效率已随深度学习(尤其是卷积神经网络)的广泛应用得到显著提升,超越了传统方法。基于深度学习的检测算法大致分为两类:单阶段算法(如YOLO系列)与两阶段算法(如R-CNN系列)。
综上,研发兼顾精度、效率与轻量化设计的无人机检测算法仍是核心挑战。由于无人机对实时性有要求,更高效的单阶段检测器是更有前景的研究方向。因此,本研究选择YOLOv8作为基准模型——它在速度与精度之间实现了出色的平衡,但在无人机检测常见的小目标、复杂背景场景中仍表现不佳,体现了单阶段检测器的固有局限。为解决这一问题,我们提出MFDA-YOLO,旨在大幅增强模型的多尺度特征能力,同时严格控制计算复杂度。本文的主要贡献如下:
1. 无人机航拍中密集小目标的检测依赖精准的空间细节,而空间金字塔池化快速(SPPF)模块恰好容易模糊这些细节,导致漏检。为此,我们采用注意力驱动的尺度内特征交互(AIF)模块替代骨干网络中的SPPF模块——该模块通过单尺度注意力机制捕捉同尺度特征间的依赖关系,增强网络的聚焦能力。
2. 无人机小目标检测需要P2层的细节信息,但这会带来较高的计算成本。为此,我们提出无人机影像检测金字塔(DIDP):模型采用SPD卷积对P2层进行无损下采样,将空间结构信息重组到通道维度;同时设计C-OKM模块恢复遗漏的图像细节,为后续特征融合提供更丰富的特征。
3. 为进一步缓解P2检测层引入的参数复杂度问题,我们提出动态对齐检测头(DADH):该模块先通过共享卷积提取特征,最大限度控制模型参数量;再通过任务分解为每个任务提取对应特征;结合可变形卷积与动态权重选择机制实现自适应处理,有效缓解任务间的冲突。
4. 考虑到轻量化检测器在处理大量低质量样本时收敛困难,我们将基准的CIOU损失函数替换为WLoUv3损失函数——它通过动态系数引导模型关注难以区分的小目标,并通过自适应归一化有效缓解振荡问题。
本节全面分析YOLOv8的网络架构,并阐释其组件模块的功能。在此基础上,探讨该模型应用于特定任务时存在的固有局限。与前代YOLO模型相比,YOLOv8优化了网络结构,如图1所示,其核心架构包含三个模块:骨干网络(Backbone)、颈部网络(Neck)与检测头(Head)。
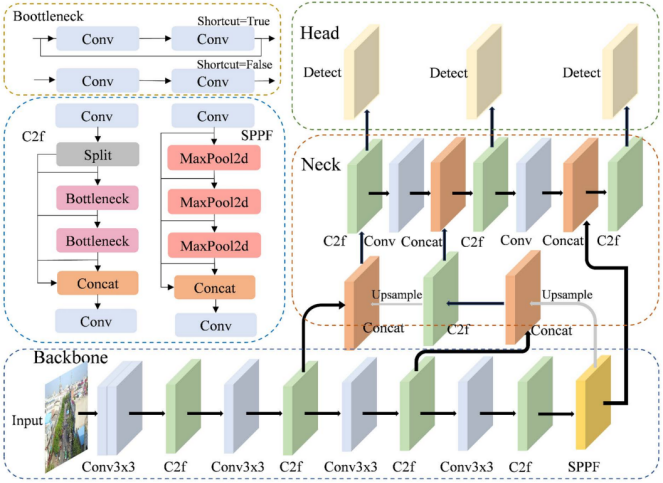
图1
PART/3
新算法框架解析
本研究基于YOLOv8提出面向无人机目标检测的MFDA-YOLO模型,有效解决了无人机场景中的两个核心问题:小目标特征丢失,以及边缘设备的计算约束。MFDA-YOLO的整体网络架构如图2所示,核心改进覆盖骨干网络、颈部网络与检测头。
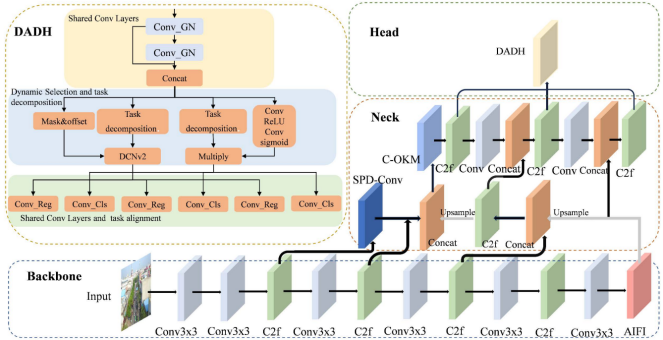
图2
在骨干网络中,我们引入AIF模块——其全局注意力机制增强了深度特征表示,有效缓解了连续下采样导致的小目标信息丢失。随后,经骨干网络增强的特征被输入颈部网络,由我们专门设计的DIDP模块处理小目标特征:该模块高效恢复多尺度特征,确保微小目标的细节被保留并有效传递。
最终,这些经过优化的特征被输入DADH检测头:通过学习任务交互特征并采用动态特征选择机制,该模块显著提升了分类与定位精度。此外,整个架构采用WLoUv3损失函数优化,引导模型在训练中聚焦具有挑战性的复杂目标,进一步提升整体性能。
AIFI模块
无人机的高飞行高度使目标变得极小,而平台的快速移动会模糊识别所需的精细纹理细节。传统SPPF模块虽高效,但在这类场景中往往效果不佳——其为通用特征提取设计的重复池化操作,可能会意外抹除定义航拍小目标所需的细微但关键的信息。
为解决这一问题,我们用AIFI模块替代传统SPPF模块:该模块通过自注意力机制处理高层语义特征,有效捕捉无人机检测中的纹理细节。同时,为让AIFI模块更高效地提取关键信息,我们在输入处添加了1×1卷积层以实现通道压缩——这既完成了通道压缩、过滤冗余信息,也确保模块能高效聚焦于无人机检测中最显著的特征。AIFI的结构如图3所示。
AIFI模块将输入的2D特征图:
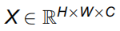
转换为1D特征序列:
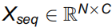
随后,该序列通过多头自注意力机制处理,学习位置关联并生成注意力特征;接着进行残差拼接与层归一化,以保留原始特征信息;前馈网络进一步引入非线性变换,学习特征序列间的复杂关联;最终,生成的序列被重构为2D特征图,实现全局上下文信息与局部空间结构的有效融合。AIFI模块流程的数学表示如下:

无人机影像检测金字塔
尽管AIFI模块增强了骨干网络的特征,但如何将这些特征有效融合以实现小目标检测,仍是核心挑战。标准特征金字塔(P3-P5)缺乏无人机影像中常见小目标所需的分辨率。
然而,直接引入高分辨率的P2层会带来极高的计算开销,这对于需要实时响应的资源受限无人机平台而言并不现实。
为解决这些问题,我们针对无人机影像的小目标检测设计了DIDP模块:在P2检测层,我们采用SPD卷积进行特征提取,并将其与P3检测层融合;同时,为避免特征衰减,我们提出C-OKM模块——该模块通过跨阶段局部网络实现通道分离,并整合全核(Omni-Kernel)的多尺度感知能力,以实现高效的特征恢复。
SPD-Conv模块
SPD-Conv通过空间重组与卷积操作提取多尺度特征,提升了低分辨率图像中小目标的检测精度。该模块包含两个核心组件:SPD层与无步长卷积(N-S Conv)层。SPD-Conv的工作流程如图4所示。
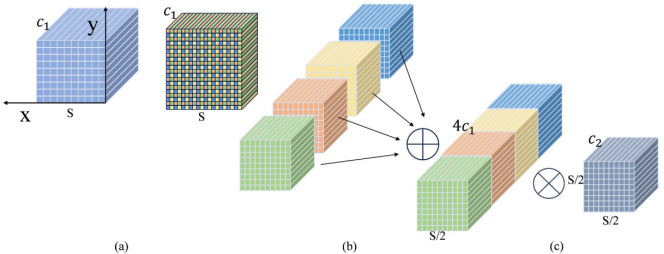
图4
C-OKM模块
然而,在特征提取与融合后,特征仍易因运动模糊和抖动出现衰减。为此,我们设计了C-OKM模块来实现图像恢复。如图5所示,C-OKM模块采用多分支架构,可在很大程度上恢复小目标特征,同时保持计算效率。
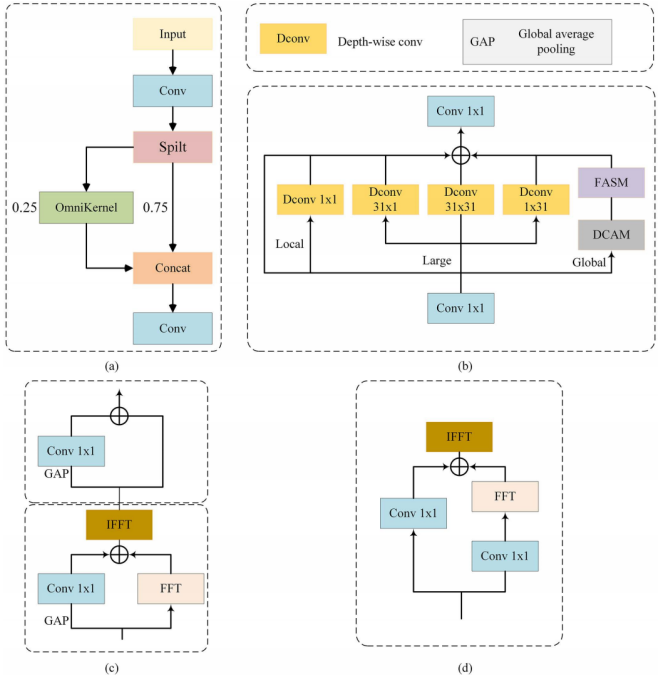
图5
如图5(a)所示,跨阶段局部结构将输入特征图划分为4个通道切片。其中一个切片经全核(Omni-Kernel)模块增强后,与其他切片融合,以保留通道维度的原始特征。全核模块如图5(b)所示:输入特征先通过1×1卷积层变换,随后分为3个分支,分别捕捉局部、大尺度和全局特征;各分支的输出经加法融合后,再通过另一个1×1卷积层进一步细化。
在局部分支中,我们采用1×1深度可分离卷积(D-Conv)增强局部图像特征;在大分支中,采用低复杂度的大奇数尺寸KK捕捉大尺度特征并扩大感受野;同时,为高效捕捉上下文信息并控制计算开销,我们在瓶颈位置并行使用1×31和31×1的D-Conv。
在全局分支中,网络主要基于裁剪后的图像片段训练,但推理时输入图像的尺寸远大于训练样本——这种尺寸差异导致卷积核无法覆K×K盖整个全局域。因此,我们引入双域处理技术增强全局建模能力:具体而言,全局分支整合了两个核心模块,即图5(c)中的双域通道注意力模块(DCAM)和图5(d)中的基于频率的空间注意力模块(FSAM)。
DCAM模块先通过傅里叶变换将特征转换到频域,再利用空间域全局平均池化生成的通道权重对频域特征进行重加权,随后在空间域进行二次通道优化;FSAM模块通过双路径在频域提取全局上下文,并生成空间域重要性掩码,这些掩码在频域融合后,经逆变换返回空间域。
动态对齐检测头
无人机的动态观测视角,加剧了检测模型中分类与定位任务的固有冲突。目标外观的剧烈变化放大了核心矛盾:特征无法同时满足分类所需的通用性与定位所需的精准性,进而导致定位精度下降。
为解决这一问题,我们结合TOOD的交互标签分配机制与任务一致性优化,提出DADH模块。与依赖注意力加权的动态头(如DyHead)不同,DADH整合了可变形卷积网络v2(DCNv2)与任务分解,动态优化定位任务的特征采样。DADH模块的具体细节如图6所示:首先通过共享卷积层高效提取多尺度特征;随后将这些特征输入任务分解模块,解耦为定位与分类两个并行分支。在定位分支中,我们引入DCNv2动态优化特征采样区域,以适配无人机航拍影像中目标的复杂几何形变;同时,分类分支通过对共享特征进行动态加权,生成更具区分性的任务专属特征表示。最终,动态对齐过程增强了两个并行分支间的特征一致性,使两者能生成更精准的分类与定位预测结果。
共享卷积层
为减少模型参数量并高效整合多尺度特征,我们设计了共享卷积层:输入特征图先经过共享卷积进行初始特征提取,随后通过组归一化将通道划分为多个组并进行组内标准化;之后,处理后的特征图再次进行卷积与组归一化操作,进一步细化并提取更深层的特征信息;最后,将细化后的特征与原始输入沿通道维度拼接,整合层级特征并增强表示能力。输出特征图Y是通过将共享卷积核K在输入X的局部区域滑动计算得到的,其表达式为:
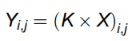
其中(i,j)是输出特征图 Y 上的位置。最终增强后的特征图 Y 会作为统一输入,送入后续的动态选择与任务分解模块。
任务分解
在单分支网络中,分类与定位任务对特征的不同需求,会在共享同一组特征时引发特征冲突。为解决这一问题,我们引入任务分解机制,其核心是加入逐层注意力机制——该机制动态解耦共享的任务交互特征,从而生成任务专属的特征表示。任务分解的原理如图7所示。
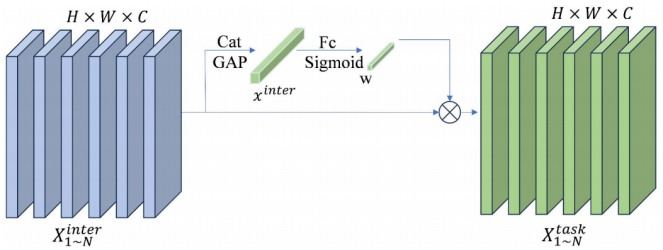
图7
WLoUv3损失函数
无人机影像中剧烈的尺度变化与密集重叠的目标,给边界框回归带来了显著挑战。YOLOv8默认的CIoU损失函数尤其容易受这些问题影响,在拥挤场景中往往收敛到局部最优解,导致定位精度不理想。 为解决这些局限,我们引入WLoUv3——这是一种采用动态非单调聚焦策略的损失函数。该设计通过聚焦样本质量、缓解低质量样本常被分配的过度梯度,增强了模型的适应性。 WLoUv3损失函数通过“离群程度”评估候选锚框的质量:离群程度越低,锚框质量越高;离群程度越高,锚框质量越低。
PART/4
实验及可视化
消融实验
我们评估了WLoUv3中超参数α和δ对检测精度的影响,在VisDrone2019数据集上测试了关键参数组合。
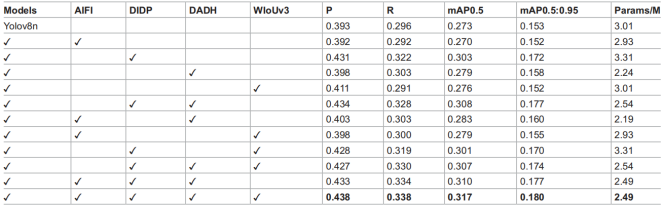
为验证所提AIFI、DIDP、DADH和WLoUv3模块对MFDA-YOLO模型的有效性,我们在VisDrone2019数据集上开展了以下消融实验,详细结果汇总于表2。
表2
为评估所提方法的有效性,我们开展了大量对比实验。对比方法包括YOLO系列的多个版本(如YOLOv5s、YOLOv5n、YOLOv8n、YOLOv9-t、YOLOv10n、YOLOX、YOLOv11n、YOLOv12n、YOLOv13n),以及FCOS、Retina-Net等其他模型。我们从参数量、精确率、FPS、mAP0.5和mAP0.5:0.95等维度综合评估各模型性能,结果在Visdrone2019-DET-Test数据集下汇总于表3。
表3
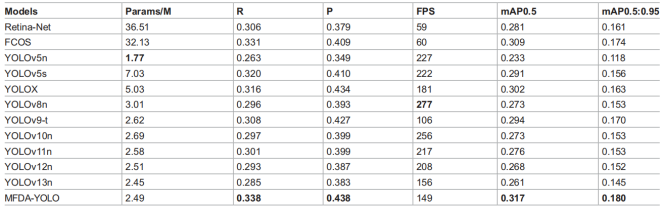
实验结果显示:Retina-Net和FCOS因参数量较多,不适用于无人机实时目标检测;MFDA-YOLO在参数量与检测精度间实现了更好的平衡——仅2.49M参数量,却达到了0.317的mAP0.5和0.180的mAP0.5:0.95,性能优于YOLOv12n、YOLOv13n等近期YOLO变体。同时,其轻量化设计增强了无人机场景下的小目标检测能力,实现了149 FPS的实时性能,且精确率提升4.5个百分点。
为可视化MFDA-YOLO模型在解决漏检和误检问题上的有效性,我们将其与YOLOv8n的混淆矩阵进行了对比,结果如图8和图9所示。
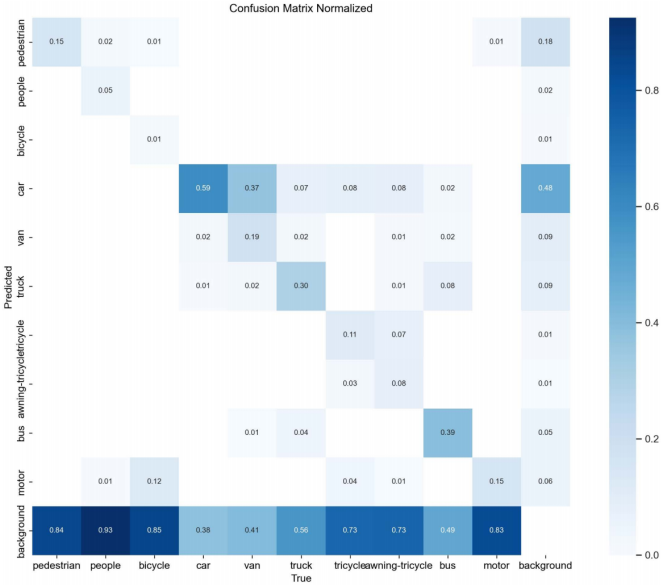
图8
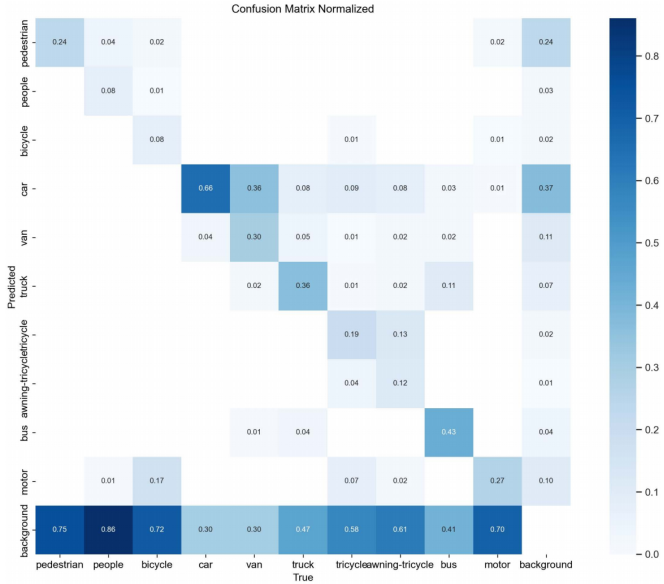
图9
为全面评估目标检测模型在无人机场景中的可靠性与灵活性,我们开展了系统的多环境测试。

图10
图10展示了MFDA-YOLO模型在各类复杂环境下的目标检测能力。通过对不同地理位置、不同无人机飞行高度下的检测结果进行详细可视化分析,我们发现:MFDA-YOLO在复杂环境中对密集型、小型目标的检测精度较高。
MFDA-YOLO模型在密集环境中表现出优异的检测性能,非常适用于无人机目标检测场景。在密集人群与车辆场景中,我们发现该模型能有效识别行人、摩托车等小目标(这些目标常被YOLOv8n和YOLOv11n模型遗漏),同时还成功减少了车辆类别的误分类问题。 为验证MFDA-YOLO模型在红外环境下的性能,我们对YOLOv8n、YOLOv11n和MFDA-YOLO进行了全面的热成像图分析,结果如图11所示。
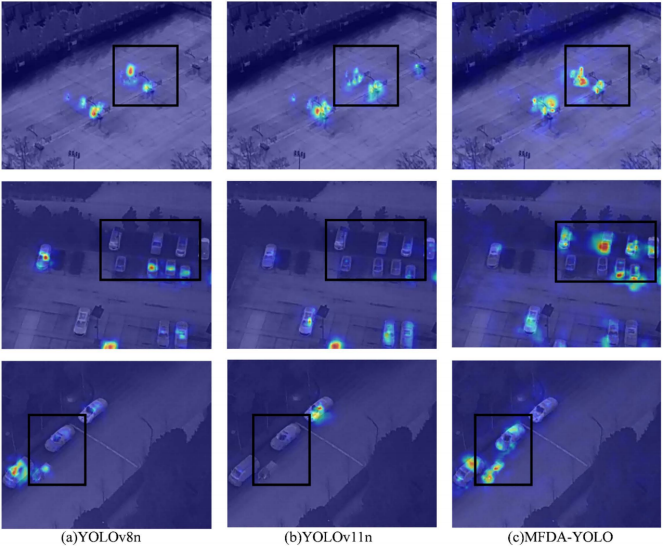
图11
在第一排图像中,MFDA-YOLO模型能够检测到更多小目标;在第二排图像中,YOLOv8n处理密集场景时明显注意力不足,导致漏检率高且存在误检;在第三排图像中,YOLOv8n和YOLOv11n均出现漏检,而MFDA-YOLO模型检测到了大部分目标,减少了漏检与误检。
总体而言,MFDA-YOLO模型能更关注细粒度细节,检测范围更广,相比YOLOv8n和YOLOv11n展现出更优的检测性能。
有相关需求的你可以联系我们!


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗
更多推荐
 20
20 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)