
深度学习与神经网络小白学习路线:从零开始的深度探索
深度学习作为人工智能的核心技术,广泛应用于图像识别、语音识别、自然语言处理等领域。本文为初学者提供了深度学习与神经网络的学习路线,从基础概念到实践应用,逐步深入。首先,介绍了深度学习与神经网络的定义及其应用领域。接着,详细阐述了学习深度学习的三个阶段:基础阶段(了解基本概念)、进阶阶段(掌握编程与数学基础)、实践阶段(动手构建神经网络)。此外,还推荐了相关书籍、在线课程和资源,帮助学习者系统掌握深
前言
深度学习(Deep Learning)作为人工智能领域中最热门的技术之一,已经在图像识别、语音识别、自然语言处理等多个领域取得了突破性进展。从自动驾驶汽车到智能语音助手,深度学习的应用无处不在。然而,对于许多初学者来说,深度学习可能是一个陌生且复杂的领域。如果你对深度学习充满兴趣,但又不知从何下手,那么这篇文章将为你提供一份清晰的深度学习与神经网络小白学习路线,帮助你从零开始,逐步掌握深度学习的核心知识和技能。
一、什么是深度学习与神经网络?
(一)深度学习的定义
深度学习是机器学习的一个子领域,它通过构建多层神经网络来模拟人类大脑的信息处理方式,从而实现对复杂数据的自动特征提取和模式识别。深度学习的核心在于“深度”,即通过多层的神经网络结构来逐步提取数据的高层次特征。
(二)神经网络的定义
神经网络(Neural Network)是一种模仿生物神经元结构和功能的计算模型,由大量的神经元(节点)和连接这些神经元的权重组成。神经网络通过输入数据的训练,自动调整权重,从而实现对数据的分类、回归或其他复杂任务。
(三)深度学习的应用领域
-
图像识别:如人脸识别、物体检测、医学影像分析。
-
语音识别:如智能语音助手(Siri、小爱同学)、语音转文字。
-
自然语言处理:如机器翻译、情感分析、聊天机器人。
-
推荐系统:如Netflix、Amazon的个性化推荐。
-
自动驾驶:如车辆的环境感知、路径规划。
二、深度学习小白学习路线
学习深度学习的过程可以分为几个阶段,从基础理论到实践应用,逐步深入。
(一)基础阶段:了解深度学习的基本概念
1. 深度学习与神经网络的关系
-
神经网络:是深度学习的基础,通过构建多层神经网络实现复杂的数据处理。
-
深度学习:是神经网络的扩展,强调通过多层结构提取数据的高层次特征。
2. 深度学习的发展历程
-
早期阶段(20世纪40年代-80年代):感知机和多层感知机的初步探索。
-
统计学习阶段(20世纪90年代-2010年代初):支持向量机(SVM)、决策树等传统机器学习方法的发展。
-
深度学习阶段(2010年代至今):深度学习的兴起,尤其是卷积神经网络(CNN)和循环神经网络(RNN)在图像和语音领域的突破。
(二)进阶阶段:掌握核心技能
1. 编程基础
-
Python:深度学习领域最常用的编程语言,因其简洁易懂和强大的库支持而受到青睐。
2. 数学基础
-
线性代数:用于处理数据的表示和变换。
-
微积分:用于优化算法,如梯度下降。
-
概率论与数理统计:用于处理数据中的不确定性和噪声。
(三)实践阶段:动手实践项目
1. 使用深度学习框架
-
PyTorch:灵活的深度学习框架,适合研究和开发。
-
TensorFlow:强大的深度学习框架,适合大规模生产部署。
-
安装PyTorch:
bash复制
pip install torch torchvision torchaudio -
安装TensorFlow:
bash复制
pip install tensorflow
-
2. 构建简单的神经网络
-
使用PyTorch构建简单的全连接神经网络:
Python复制
import torch import torch.nn as nn import torch.optim as optim # 定义简单的全连接神经网络 class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(784, 128) # 输入层到隐藏层 self.fc2 = nn.Linear(128, 10) # 隐藏层到输出层 def forward(self, x): x = torch.relu(self.fc1(x)) # 激活函数 x = self.fc2(x) return x # 实例化网络 net = SimpleNN() # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01) # 示例数据 inputs = torch.randn(64, 784) # 64个样本,每个样本784维 labels = torch.randint(0, 10, (64,)) # 随机生成标签 # 训练过程 for epoch in range(10): # 迭代10次 optimizer.zero_grad() # 清空梯度 outputs = net(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播 optimizer.step() # 更新参数 print(f"Epoch {epoch+1}, Loss: {loss.item()}") -
使用TensorFlow构建简单的全连接神经网络:
Python复制
import tensorflow as tf from tensorflow.keras import layers, models # 定义简单的全连接神经网络 model = models.Sequential([ layers.Dense(128, activation='relu', input_shape=(784,)), layers.Dense(10, activation='softmax') ]) # 编译模型 model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 示例数据 inputs = tf.random.normal([64, 784]) # 64个样本,每个样本784维 labels = tf.random.uniform([64], minval=0, maxval=10, dtype=tf.int32) # 随机生成标签 # 训练模型 model.fit(inputs, labels, epochs=10)
(四)高级阶段:深入研究与应用
1. 卷积神经网络(CNN)
-
CNN的基本概念:卷积层、池化层、全连接层。
-
应用示例:图像分类、目标检测。
-
使用PyTorch构建CNN:
Python复制
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms # 定义卷积神经网络 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2) self.fc1 = nn.Linear(16 * 14 * 14, 10) def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = x.view(-1, 16 * 14 * 14) x = self.fc1(x) return x # 实例化网络 net = CNN() # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01) # 数据预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) # 加载MNIST数据集 train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) # 训练模型 for epoch in range(10): for inputs, labels in train_loader: optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() print(f'Epoch {epoch+1}, Loss: {loss.item()}')
-
2. 循环神经网络(RNN)
-
RNN的基本概念:循环层、长短期记忆网络(LSTM)、门控循环单元(GRU)。
-
应用示例:文本生成、机器翻译。
-
使用PyTorch构建RNN:
Python复制
import torch import torch.nn as nn import torch.optim as optim # 定义简单的RNN class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.rnn = nn.LSTM(input_size, hidden_size, num_layers=1, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device) c0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device) out, _ = self.rnn(x, (h0, c0)) out = self.fc(out[:, -1, :]) return out # 实例化网络 input_size = 10 hidden_size = 128 output_size = 10 net = RNN(input_size, hidden_size, output_size) # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001) # 示例数据 inputs = torch.randn(64, 10, input_size) # 64个样本,序列长度为10,每个时间步的特征维度为input_size labels = torch.randint(0, output_size, (64,)) # 随机生成标签 # 训练模型 for epoch in range(10): optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() print(f'Epoch {epoch+1}, Loss: {loss.item()}')
-
3. Transformer架构
-
Transformer的基本概念:自注意力机制、编码器-解码器架构。
-
应用示例:机器翻译、文本生成。
-
使用Hugging Face Transformers库:
Python复制
from transformers import BertTokenizer, BertForSequenceClassification import torch # 加载预训练的BERT模型和分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForSequenceClassification.from_pretrained('bert-base-uncased') # 示例文本 text = "I love natural language processing" inputs = tokenizer(text, return_tensors='pt') # 预测 with torch.no_grad(): outputs = model(**inputs) logits = outputs.logits predicted_class = torch.argmax(logits).item() print("Predicted class:", predicted_class)
-
三、学习资源推荐
在学习深度学习的过程中,以下资源可以帮助你更快地掌握知识:
(一)书籍
-
《深度学习》(Ian Goodfellow, Yoshua Bengio, Aaron Courville):深度学习领域的权威教材,详细介绍了深度学习的基础知识和高级技术。
-
《Python深度学习》(Francois Chollet):通过Keras和TensorFlow介绍深度学习的实践应用。
-
《动手学深度学习》(Aston Zhang, Zachary C. Lipton, Mu Li, Alex J. Smola):结合PyTorch和MXNet介绍深度学习的基础知识和实践应用。
(二)在线课程
-
Coursera上的“深度学习专项课程”(DeepLearning.AI):由Andrew Ng团队开发的深度学习课程,涵盖了从基础到高级的深度学习知识。
-
edX上的“深度学习”课程(哥伦比亚大学):由哥伦比亚大学开发的深度学习课程,适合有一定基础的学习者。
-
Udacity上的“深度学习纳米学位课程”:通过项目驱动的方式学习深度学习的基础知识和应用。
(三)在线资源
-
PyTorch官方文档:提供了详细的深度学习教程和API文档。
-
TensorFlow官方文档:提供了丰富的深度学习教程和API文档。
-
Kaggle:提供了丰富的深度学习竞赛和数据集,适合初学者通过实践提升技能。
-
GitHub:有许多开源的深度学习项目和教程,可以通过阅读和参与这些项目来提升实践能力。
四、总结
深度学习是一个充满挑战和机遇的领域,掌握深度学习的基础知识和技能是进入这一领域的关键。通过本文提供的学习路线,从基础的深度学习概念,到编程和数学基础,再到神经网络的构建和优化,你可以逐步建立起对深度学习的全面理解。希望这篇文章能够帮助你开启深度学习的学习之旅,探索更多有趣的应用场景。如果你在学习过程中有任何问题,欢迎在评论区留言,我们一起交流和进步!
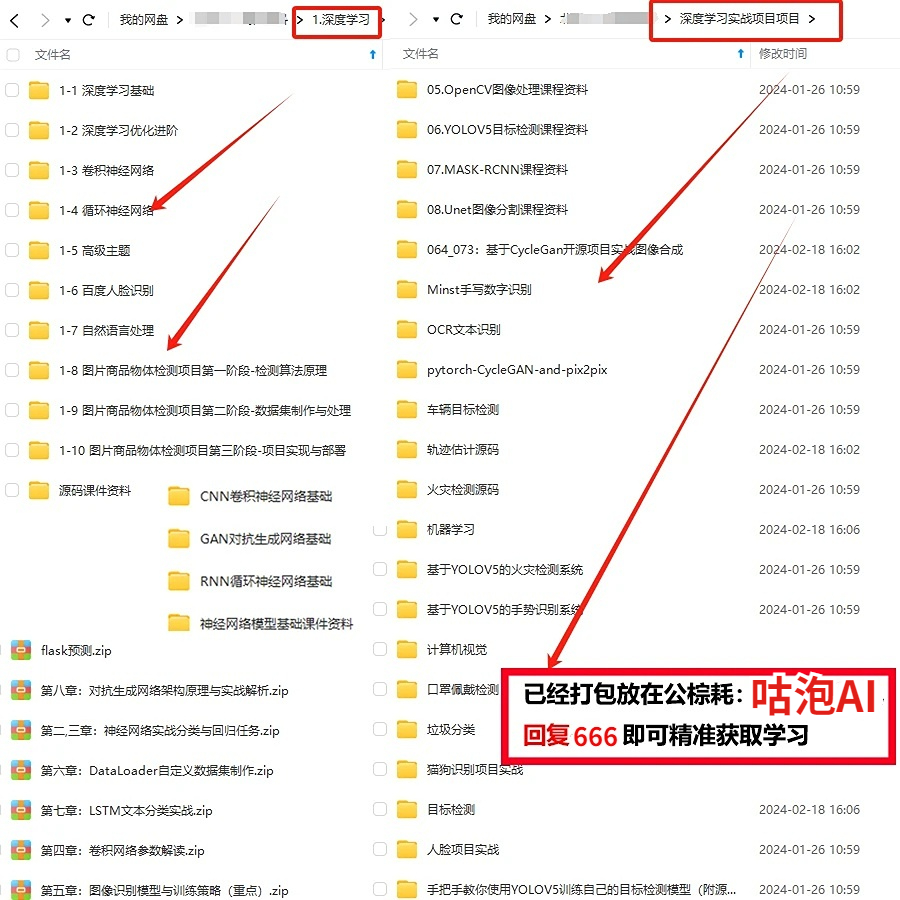
免费分享一些我整理的人工智能学习资料给大家,包括一些AI常用框架实战视频、图像识别、OpenCV、NLQ、机器学习、pytorch、计算机视觉、深度学习与神经网络等视频、课件源码、国内外知名精华资源、AI热门论文、行业报告等。
下面是部分截图,关注VX公众号【咕泡AI】发送暗号 666 领取
更多推荐


 19
19 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)