
YOLO深度学习(计算机视觉)—毕设笔记4(yolo训练优化和验证)
摘要:本文介绍了YOLO模型训练中的关键参数设置与验证方法。训练效率方面,重点分析了图片缩放尺寸(imgsz)、批次大小(batch)、缓存(cache)等参数的优化技巧,建议常规图片使用640尺寸,批次设为-1自动优化。模型选择方面,提供了从yolo11n.pt到yolo11x.pt不同规模的预训练权重选择策略。验证环节则阐述了TP/FP/FN等评估指标的计算原理,以及训练过程中自动验证的机制,
一、提升模型训练的【速度】的参数
前面我们学了这些参数可以调节模型训练的细节
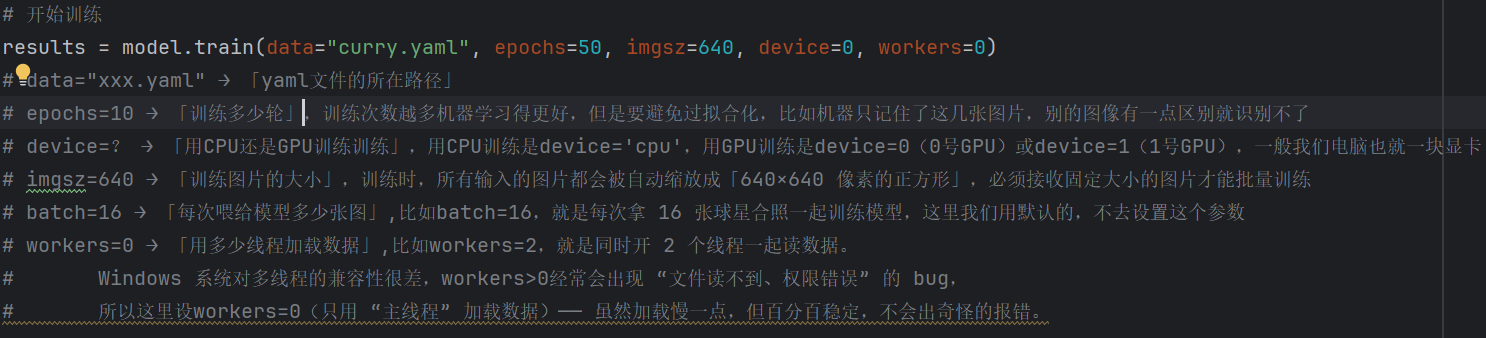

那么有几个细解参数会影响跑模型的效率:
1、imgsz图片缩放
简单说图片缩放越小,CPU或GPU读取运行的速度更快(最小32,必须是32的倍数)

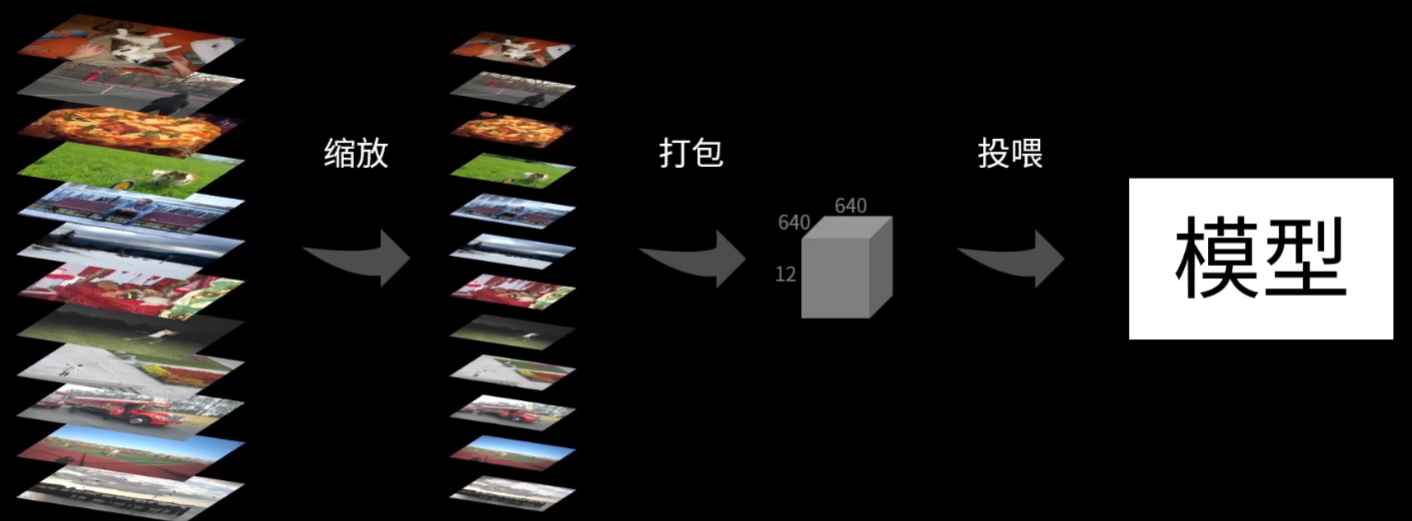
但是并非越小越好,图片的缩放也影响模型训练的最终的质量高低,比如


所以通常做法是,正常的图片统一设置成【640】即可
2、batch批次训练
batch这个参数就是指定一个批次取数据集取几个图片打包喂给电脑运行

直接说结论,batch太小会很慢,因为每次只投喂一点点数据量,CPU或GPU利用率低;batch太大也会影响效率,因为CPU或显存占用太高忙不过来了,直接爆了,所以我们要取一个适合的区间
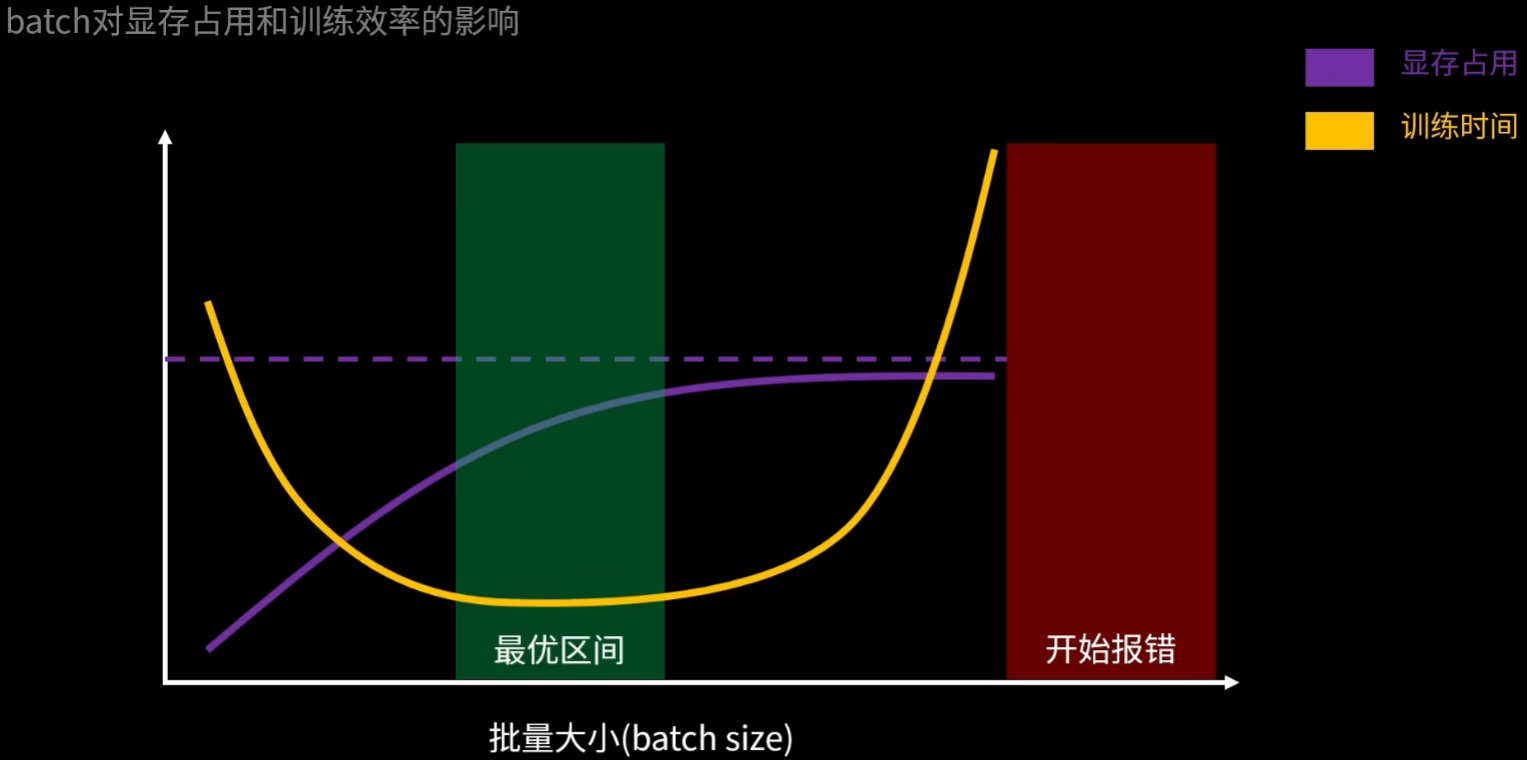
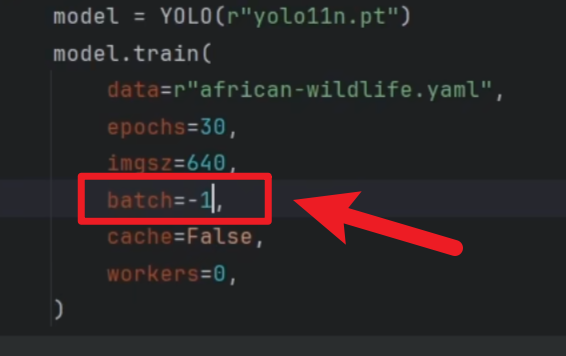
技巧就是:
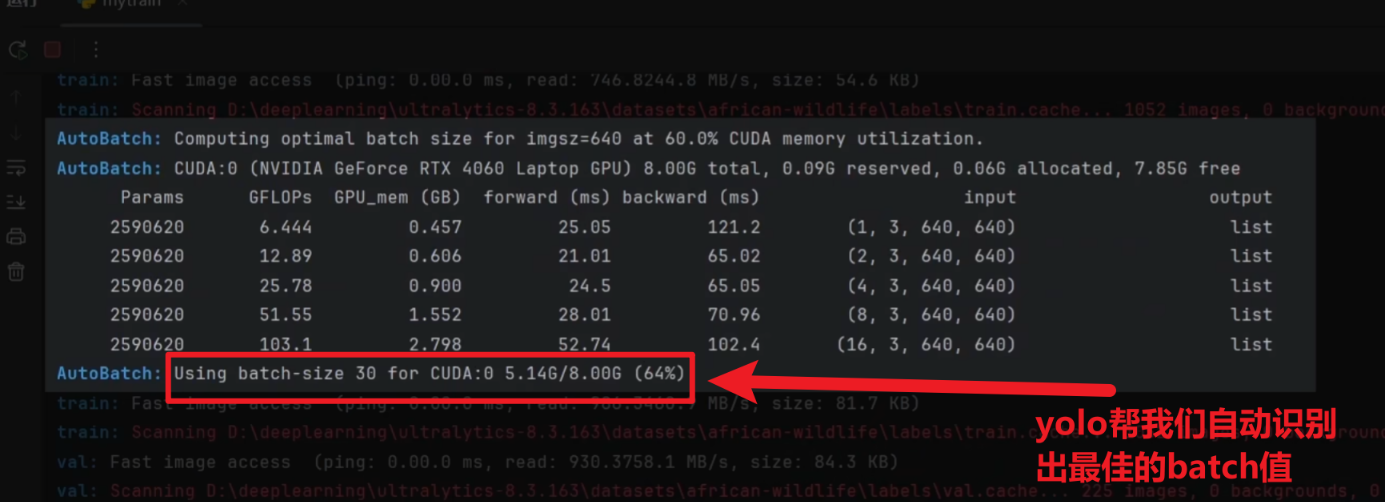
- 每次都设置【batch=-1】,这样YOLO就会自动为你选取一个最佳的batch区间值!!
- 你可以直接用batch=-1,也可以在给出的最佳值附近调一下试试找到更高效率的值
3、cache使用缓存参数
这个参数一般不用
只有你的数据集都是尺寸超级大的图片、而且你的内存够大的时候,才会感受到明显的飞速
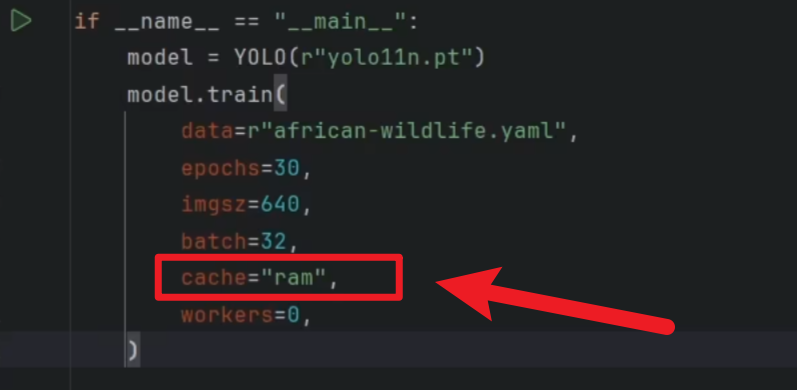
原理是学过408的都知道,调用磁盘、调用CPU、调用缓存....这些存取速度都是不一样的,越靠近CPU的存储器读取数据的越快,所以【cache="ram"】原理就是把图片调入内存来加快读取速度
那如果你内存不够大的话,可能会卡死。。。。
4、预训练model选什么比较好
预训练权重:
- yolo11n.pt(最小,速度快)、yolo11s.pt、yolo11m.pt、yolo11l.pt、yolo11x.pt(最大,精度高)
自定义结构:
- 自己编写的 YOLO11 yaml 文件(如my_yolo11.yaml)
调整建议:
- 通用场景:直接用官方预训练权重(如yolo11s.pt),利用迁移学习加速收敛。
# 使用pt文件创建模型 model = YOLO("yolo11n-obb.pt") results = model.train(data="对应数据集位置的那个.yaml", epochs=100, ...其他参数)- 特殊任务(如小目标检测):基于官方 yaml 修改网络结构后,指定自定义 yaml 文件。
# 自己自定义修改了官方的yolo11的那个yaml,那就按这个你yaml定的网络模型来训练 # 加载权重,依旧利用yolo11官方通用的已经被训练过的一些权重 model = YOLO("你改过后的网络模型配置.yaml").load("yolo11n-obb.pt")注意:【model = YOLO("网络模型配置.yaml")】和【results = model.train(data="对应数据集位置.yaml"】这两个yaml文件各有各的用,并不冲突
一个是在model定义的时候引入的【网络模型结构】yaml文件
一个是在开始用model.train()训练的时候指明的【数据集位置】yaml文件
二、提高模型训练【精度】的参数
1、依旧imgsz图片缩放
前面说过了,特殊图片比如 “遥感影像”,地面上的目标物体特别小而且模糊的时候,可以把imgsz调成【1280×1280】放大一下图片细节,但是训练速度会慢一点点(只能时间换准确性了)

2、epochs - 训练总轮数
作用:指定模型遍历整个训练集的次数,决定训练的总周期。
- 默认值:100,其实基本100次就刚刚好
调整建议:
- 小数据集(<1k 样本):50-80 epochs,避免过拟合(过拟合:训练集精度高但验证集精度下降)。
- 大数据集(>10k 样本):100-200 epochs,确保模型充分学习数据特征。
观察指标:
- 若验证集 mAP(平均精度)不再提升,可提前停止训练(YOLO11 支持自动早停,需配合patience参数)。
3、图像数据增强
1)augment=Ture开数据增强、以及自定义参数值
前面我们学过opencv的数据增强以及pytorch里tensorflow自带图像增强,但是通通不用管了(白学......),我们在train时设置一个参数【augment=Ture】,就会得到这些数据增强操作了哈哈.....
;
;
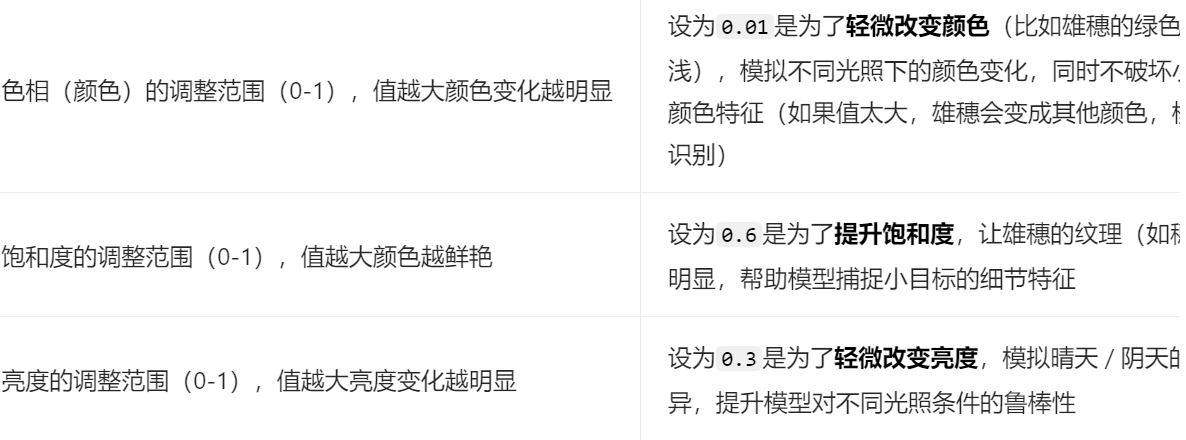
但是打开augment只是用yolo自带的默认值,对于图片色彩变化的值,我们可以自定义调整设置成我们自己的值:【hsv_h色相】、【hsv_s饱和度】、【hsv_v亮度】
还有【degree角度旋转】

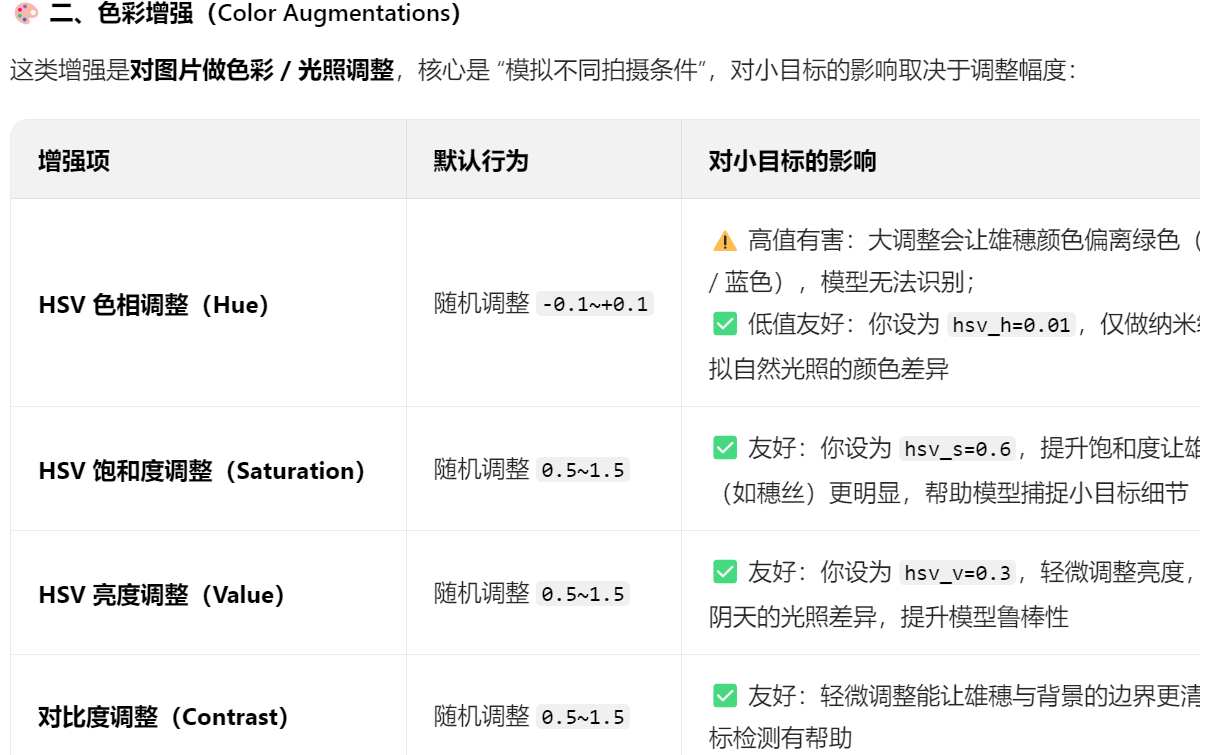


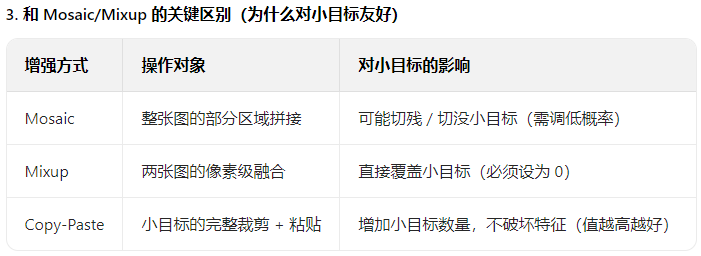
2)mosaic马赛克拼接
【augment=Ture】不包含这个操作,所以要我们单独设置这个参数
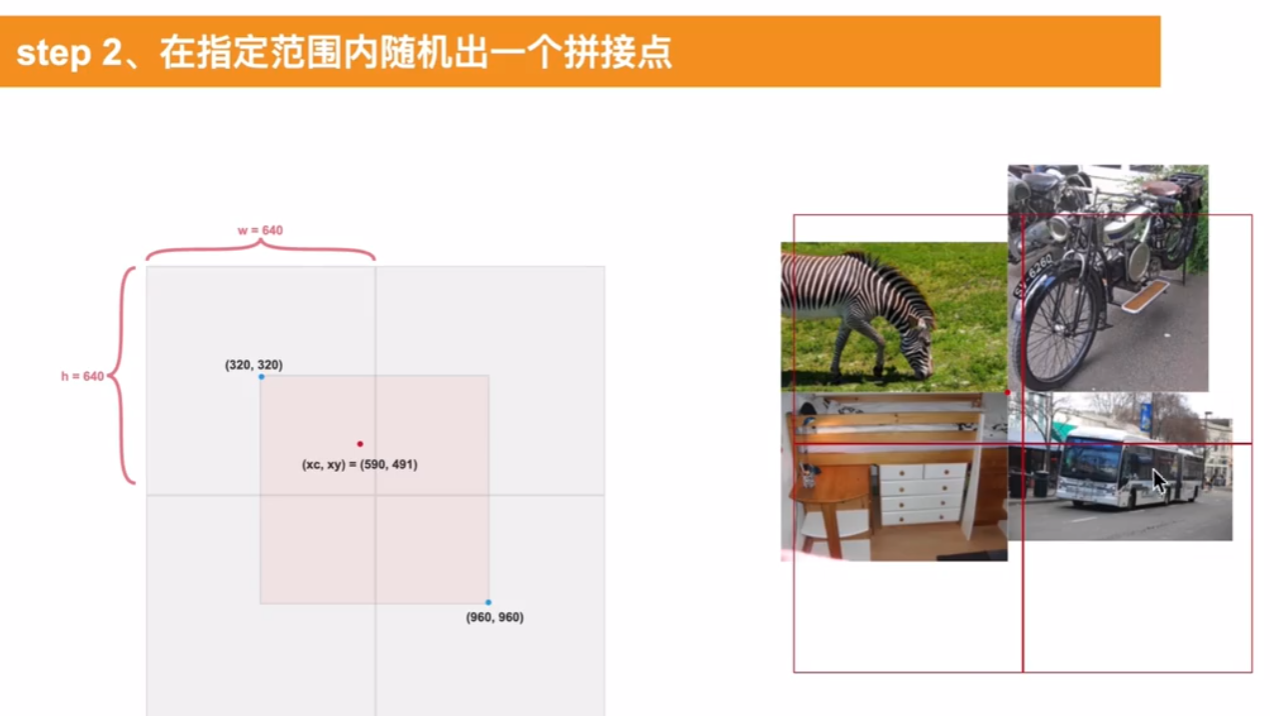
mosaic增强的原理就是随机取几张图拼接在一起
然后在指定范围内找个拼接点,割出设置的输入图像的尺寸大小
留白的地方把各个小图拉伸缩放,直到占满整个尺寸,成为一个混合拼接图
所以我们可以开启这个参数,相当于给我们的数据又增加了数据量和多样性
但是要注意mosaic的参数值,我们可以一点点往小调,看看每次训练的效果,我们只需取一小部分图像进行图像拼接即可,太多比例会增加过多【把实际目标切掉的无用图片】
另外





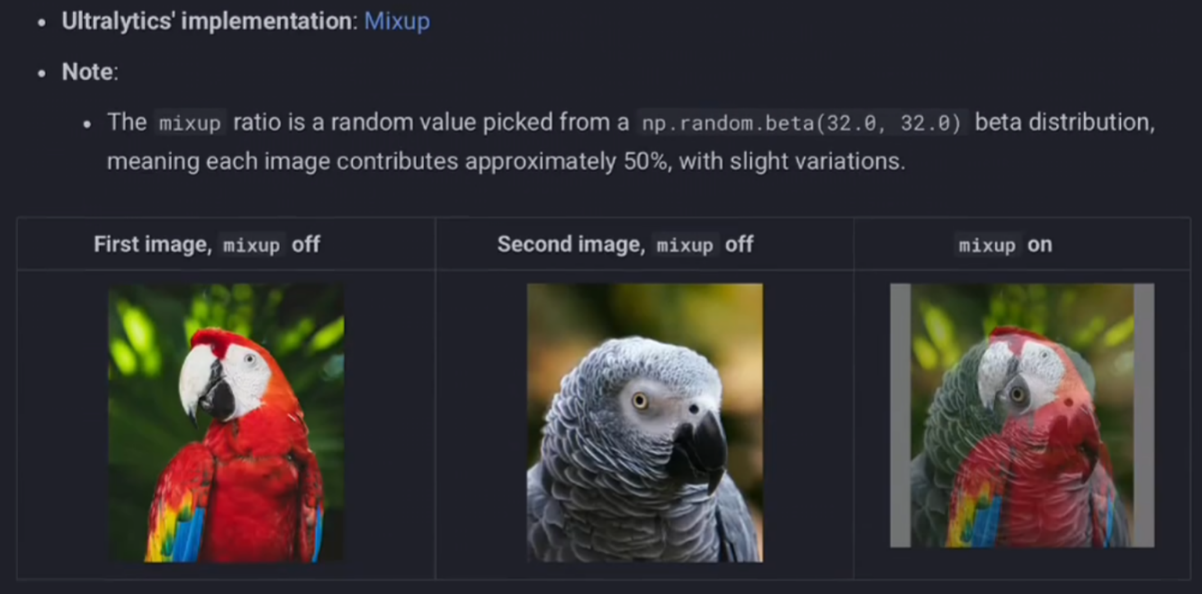
2)Mixup混合
【augment=Ture】不包含这个操作,所以要我们单独设置这个参数
混合,见名思意,多个图混在一次,我觉得是没什么意义,反而是给计算机增加“乱七八糟错误的学习资料”,所以一般是【Mixup=0】


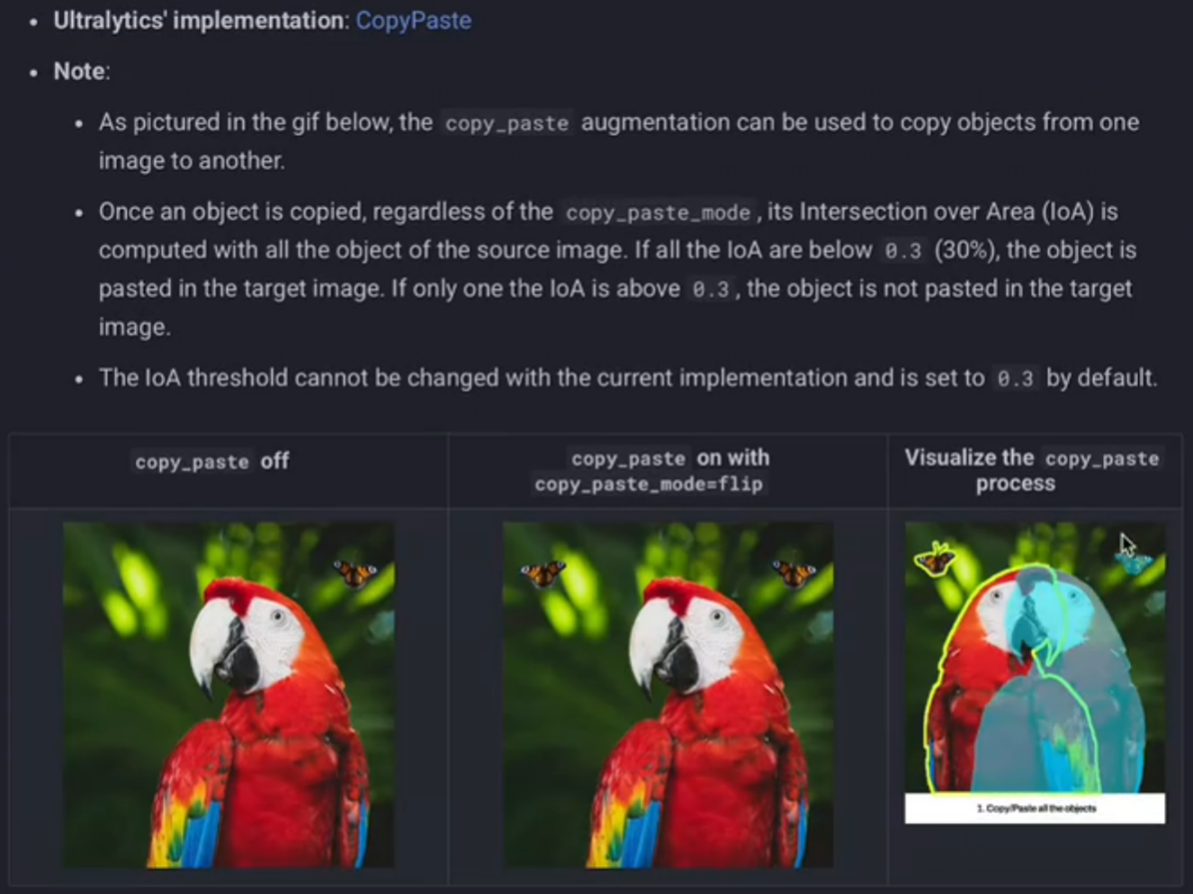
3)copy_paste复制粘贴
【augment=Ture】不包含这个操作,所以要我们单独设置这个参数
copy_paste的原理也很简单,大致就是把一个图片的目标物体(根据txt标签的标的框)抠下来复制到另一个图片上,只会比mosaic、mixup更为友好,尽可能保持了图片的完整性,能区分得出图片里的各个目标物体(下面是我的例子)

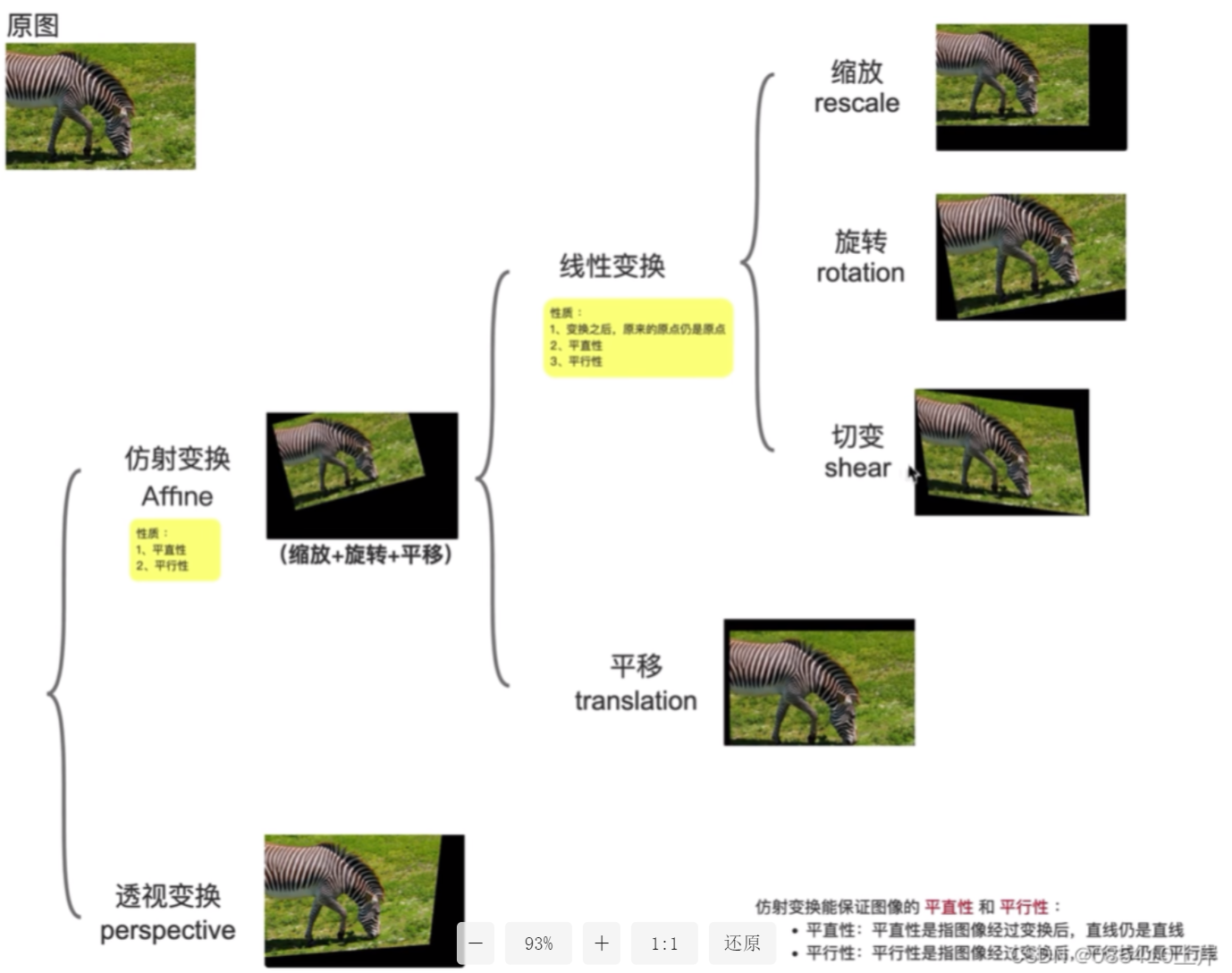
4)perspective透视变换
【augment=Ture】不包含这个操作,所以要我们单独设置这个参数(Affine仿射变化包含在augment=True所以不用单独设置)
就是对图片做轻微的 3D 透视变形,模拟不同拍摄角度下的目标形态
一般设置为极小值0.001,是为了轻微改变透视关系,既提升模型泛化能力,又不破坏原本小目标的原始形态(如果值太大,小目标会被拉伸变形,特征丢失)
6、patient早停
之前我的一个模型,AI建议我从50轮早停到60轮,就是因为:



7、box和cls权重
目标类别少的时候,box框的权重加大!!反之则加大cls分类权重




8、dropout 概率
作用:在网络中加入 dropout 层,防止过拟合(随机 “关闭” 部分神经元,降低模型对局部特征的依赖)。
- 默认值:0.0(YOLO11 默认不启用 dropout,官方测试表明其对检测任务增益有限)。
调整建议:
- 小数据集 + 过拟合严重:设为 0.1-0.2(轻微 dropout,平衡拟合与性能)。
- 大数据集:保持 0.0,无需 dropout 即可稳定训练
至于有的YOLO11的一些机制也比dropout更好用,可以参考AI给我的回答

9、lr0和lrf(学习率Linear Scaling Rule)
当 batch_size 放大 k 倍时,学习率lr0也放大 k 倍,可保持收敛性。
- 示例:
- batch=16 → lr0=0.01
- batch=64 → lr0=0.04
不过当0.01这么小还是训练效果不太好时,可以尝试继续进一步调低学习率,因为比如微小目标特征维度低、信息量少,高学习率会导致参数 “震荡”(损失函数导数下降不稳定,学了就忘);低学习率让参数缓慢更新,能学透小特征


总结
我个人某个玉米雄穗数据集的训练设置的参数参考
但是具体还是一次次训练后根据run/train里的模型评估结果对比来调整的
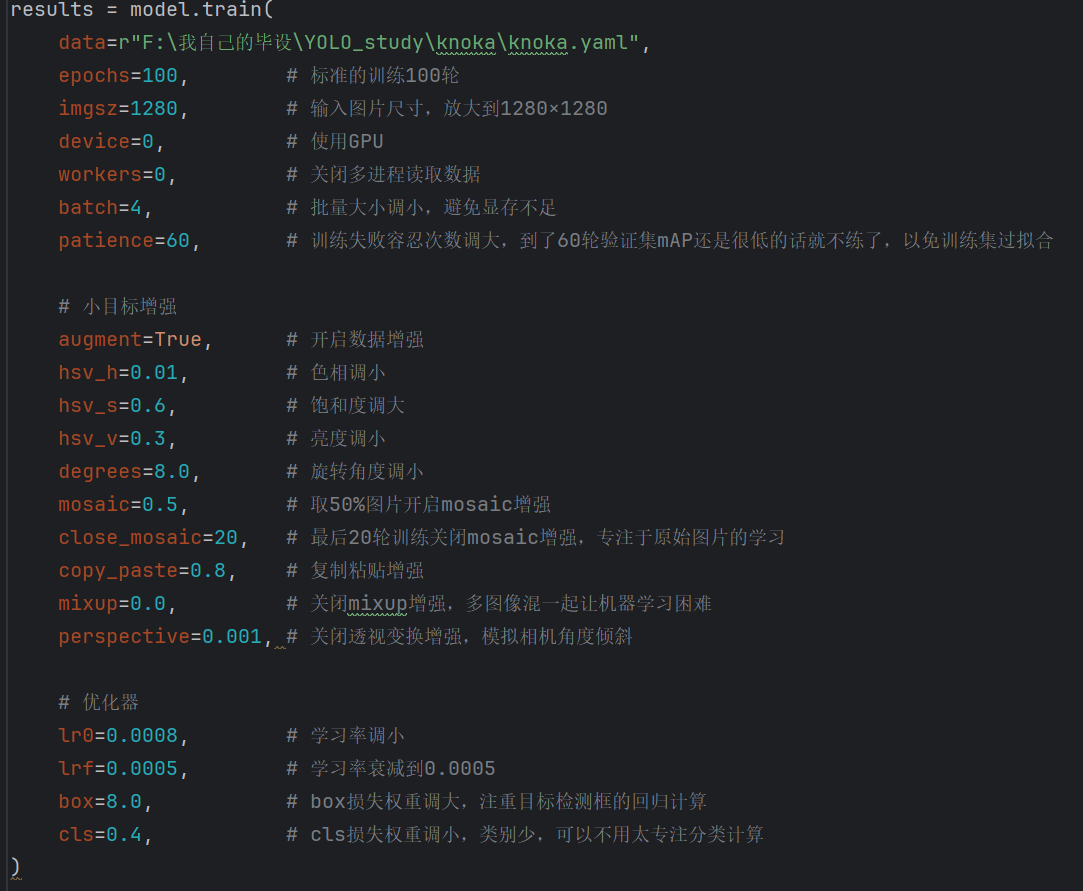
三、锚框定制
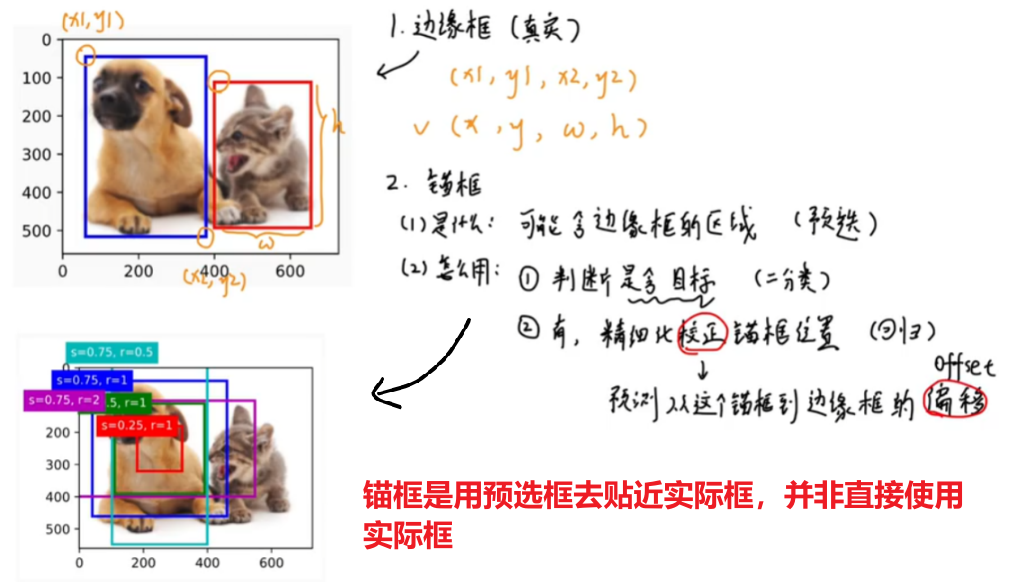
1、锚框大概原理
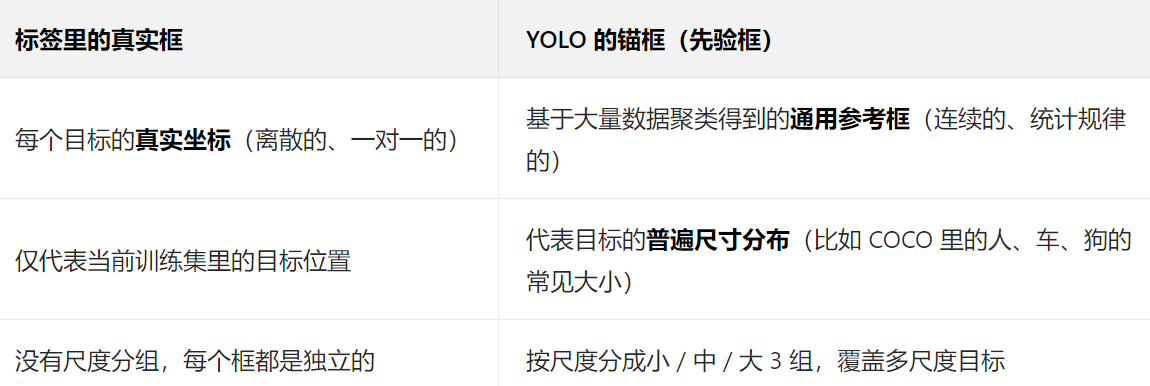
我们需要知道,YOLO的目标检测框叫 “锚框”,并不是按标签文件里的真实框定的,而是基于一个叫COCO的数据集预测到的 “通用框”,靠这个数据集训练的模型的锚框可以识别很多物体
于是面对新的数据集,YOLO也是先用预测框来计算,如果预选框里包含真实框的区域,那么再调整精算偏移量,进而更贴近真实框,这样做也是加快预测框计算的速度
;
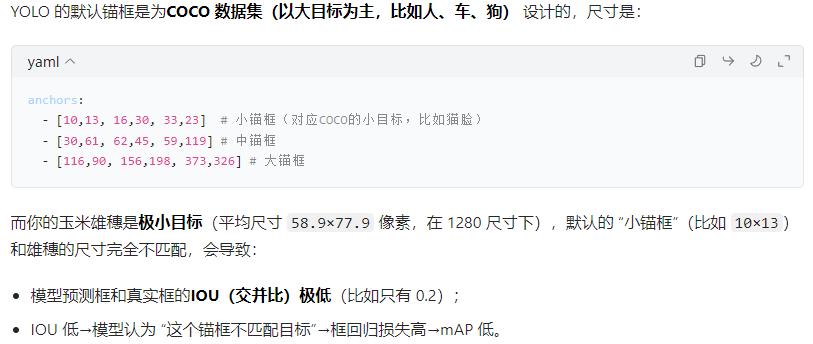
但是这样的弊端就是,基于COCO数据集的锚框可能并不适用所有数据集,比如我的训练的数据集是玉米雄穗,COCO数据集明显没有这种物体类别,所以我们还是应该用我们的标签真实框数据来计算锚框
2、修改自定义锚框代码
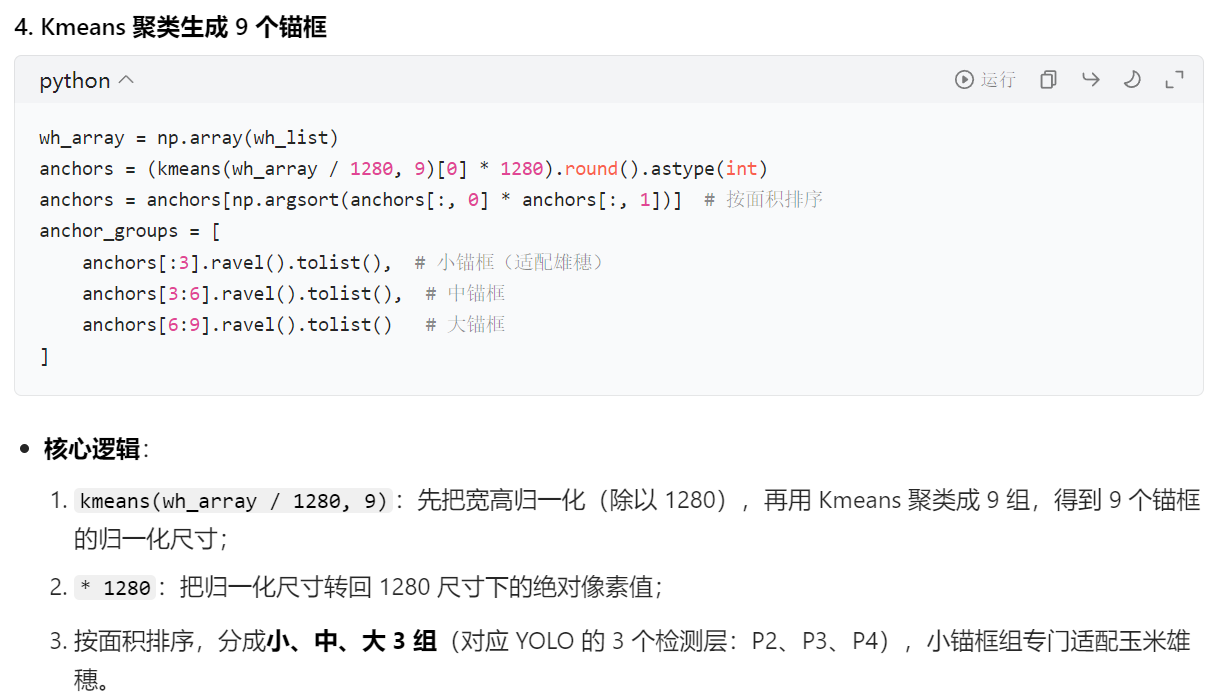
这里我用AI写了一个计算锚框的脚本,适用于极小目标物体、图片放大到1280尺寸的,如果不适用你的需求,可以用我的脚本喂给AI让它根据你的需求来修改调整
# calc_anchors.py - 纯通用代码,适配所有ultralytics 8.x版本 import os import yaml import numpy as np from scipy.cluster.vq import kmeans # 解决Windows冲突 os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # ===================== 1. 手动加载并处理数据集yaml(完全通用) ===================== data_yaml_path = r"你自己数据集位置配置的yaml文件路径" with open(data_yaml_path, "r", encoding="utf-8") as f: data_cfg = yaml.safe_load(f) # 拼接训练集图片的绝对路径(基于yaml里的path字段) dataset_root = data_cfg["path"] # 从yaml里取path train_img_relative = data_cfg["train"] # 从yaml里取train相对路径 train_img_path = os.path.join(dataset_root, train_img_relative) # 拼接训练集标注文件的绝对路径(YOLO标注默认在labels文件夹) train_label_path = os.path.join(dataset_root, "labels", os.path.basename(train_img_relative)) # ===================== 2. 直接读取标注文件统计目标尺寸(绕开ultralytics的坑) ===================== wh_list = [] # 遍历所有训练集图片对应的标注文件 for img_file in os.listdir(train_img_path): # 获取对应标注文件的路径(图片名转txt名) label_file = os.path.splitext(img_file)[0] + ".txt" label_file_path = os.path.join(train_label_path, label_file) # 跳过不存在的标注文件 if not os.path.exists(label_file_path): continue # 读取标注文件(YOLO格式:class x y w h) with open(label_file_path, "r", encoding="utf-8") as f: for line in f: line = line.strip() if not line: continue # 解析标注:class, x(归一化), y(归一化), w(归一化), h(归一化) parts = line.split() if len(parts) != 5: continue _, x_norm, y_norm, w_norm, h_norm = parts # 转换为1280尺寸下的绝对宽高 w_abs = float(w_norm) * 1280 h_abs = float(h_norm) * 1280 # 过滤极小目标 if w_abs > 2 and h_abs > 2: wh_list.append([w_abs, h_abs]) # ===================== 3. 生成锚框并输出 ===================== if not wh_list: print("❌ 未统计到目标框!检查:") print(f"1. 数据集根目录:{dataset_root} 是否存在?") print(f"2. 训练集图片路径:{train_img_path} 是否有图片?") print(f"3. 训练集标注路径:{train_label_path} 是否有对应的txt文件?") else: wh_array = np.array(wh_list) # Kmeans聚类生成9个锚框 anchors = (kmeans(wh_array / 1280, 9)[0] * 1280).round().astype(int) anchors = anchors[np.argsort(anchors[:, 0] * anchors[:, 1])] # 按面积排序 anchor_groups = [ anchors[:3].ravel().tolist(), # 小锚框(适配雄穗) anchors[3:6].ravel().tolist(), # 中锚框 anchors[6:9].ravel().tolist() # 大锚框 ] print("\n✅ 你的数据集专属锚框(复制到yolo11.yaml):") print("anchors:") for g in anchor_groups: print(f" - {g}") print(f"\n📊 统计信息:") print(f"目标总数:{len(wh_list)} 个") print(f"平均尺寸:{np.mean(wh_array, axis=0).round(1)} 像素")重点部分在这,有兴趣可以自己去了解
;
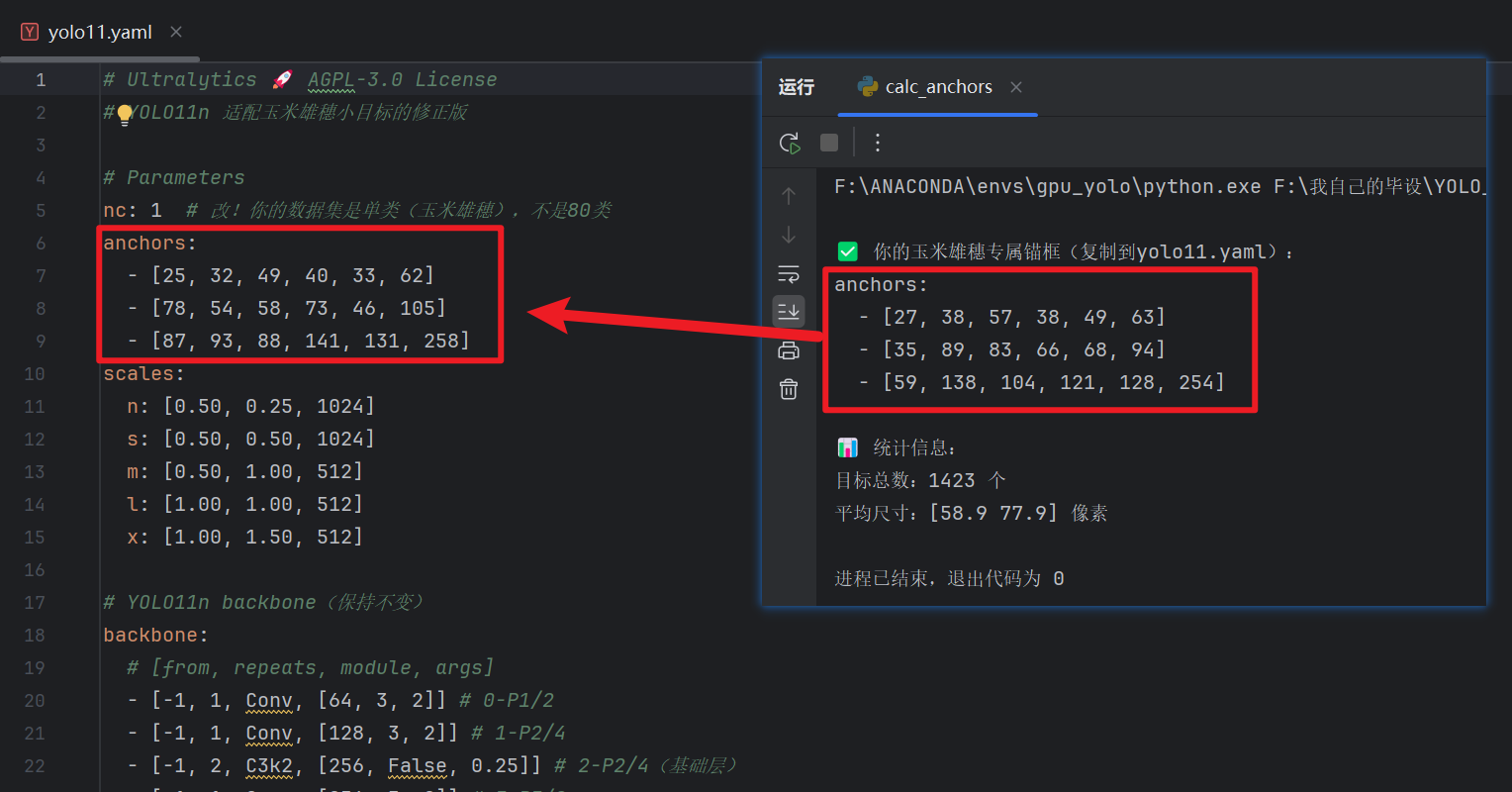
然后把这脚本运行后计算的锚框,复制到yolo11.yaml文件里
(yolo11.yaml是专门用来配置yolo11网络模型权重的,你可以去原文件里改,但是尽量复制到你的项目里改,train训练的时候也是指定这个复制的yaml)
四、yolo验证
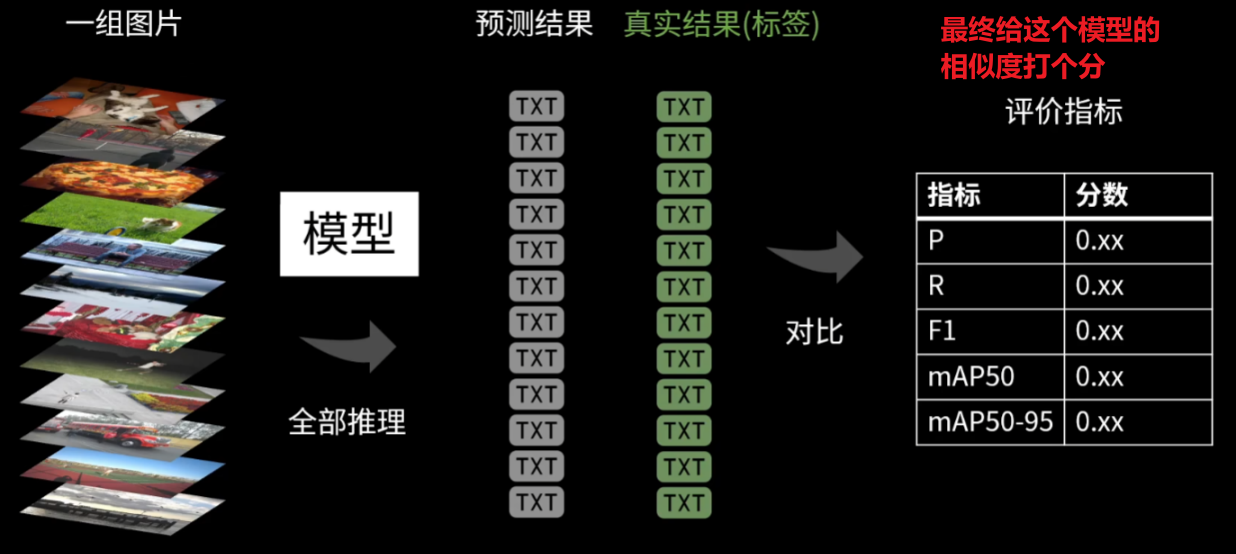
前面我们讲了【数据集准备Datasets】、【模型预测Predict】、【模型训练Train】,现在该讲一下【模型验证Validated】了
其实验证就是去数据集(一般是验证集,当然别的测试集也行)取一组图像给模型predict预测一下,然后得到的【预测结果】去和【我们原始的真实标签结果】对比,相当于把做完的试卷对一下答案,最终打个分——得出这个模型的评价标准
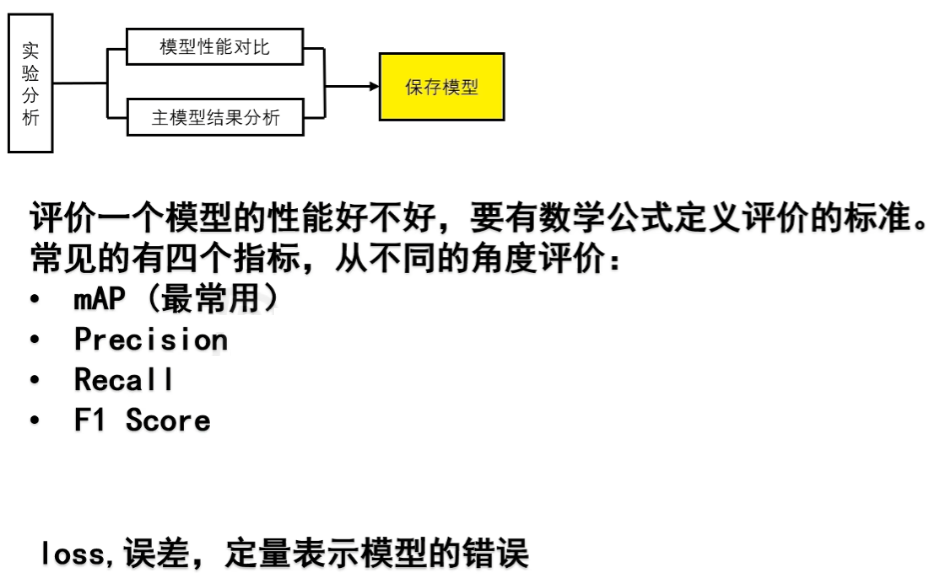
1、模型评估指标原理回顾(重要!!)
而模型的评价标准,我们前面第一篇其实讲过了,回顾一下
;
4个小术语:
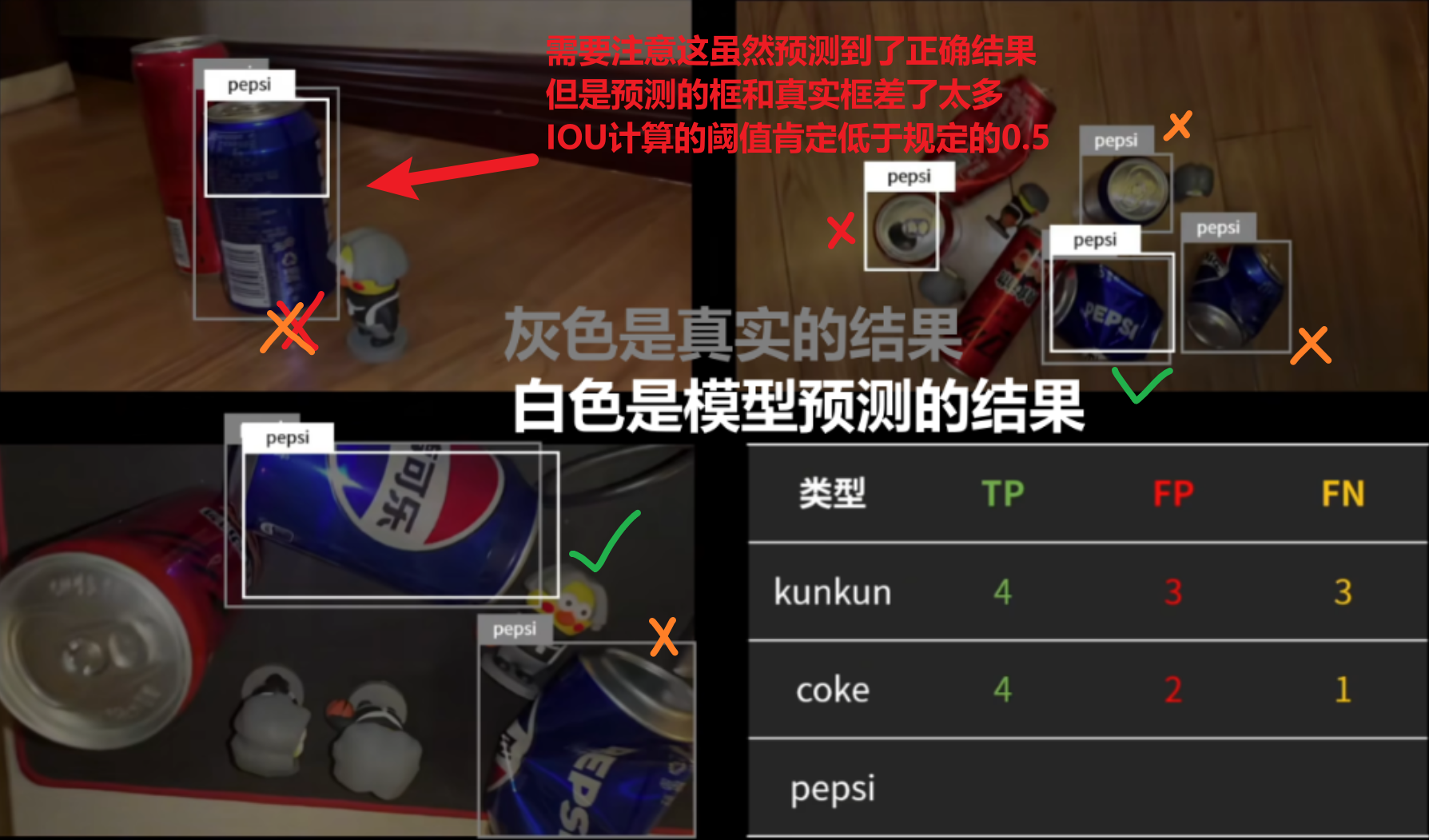
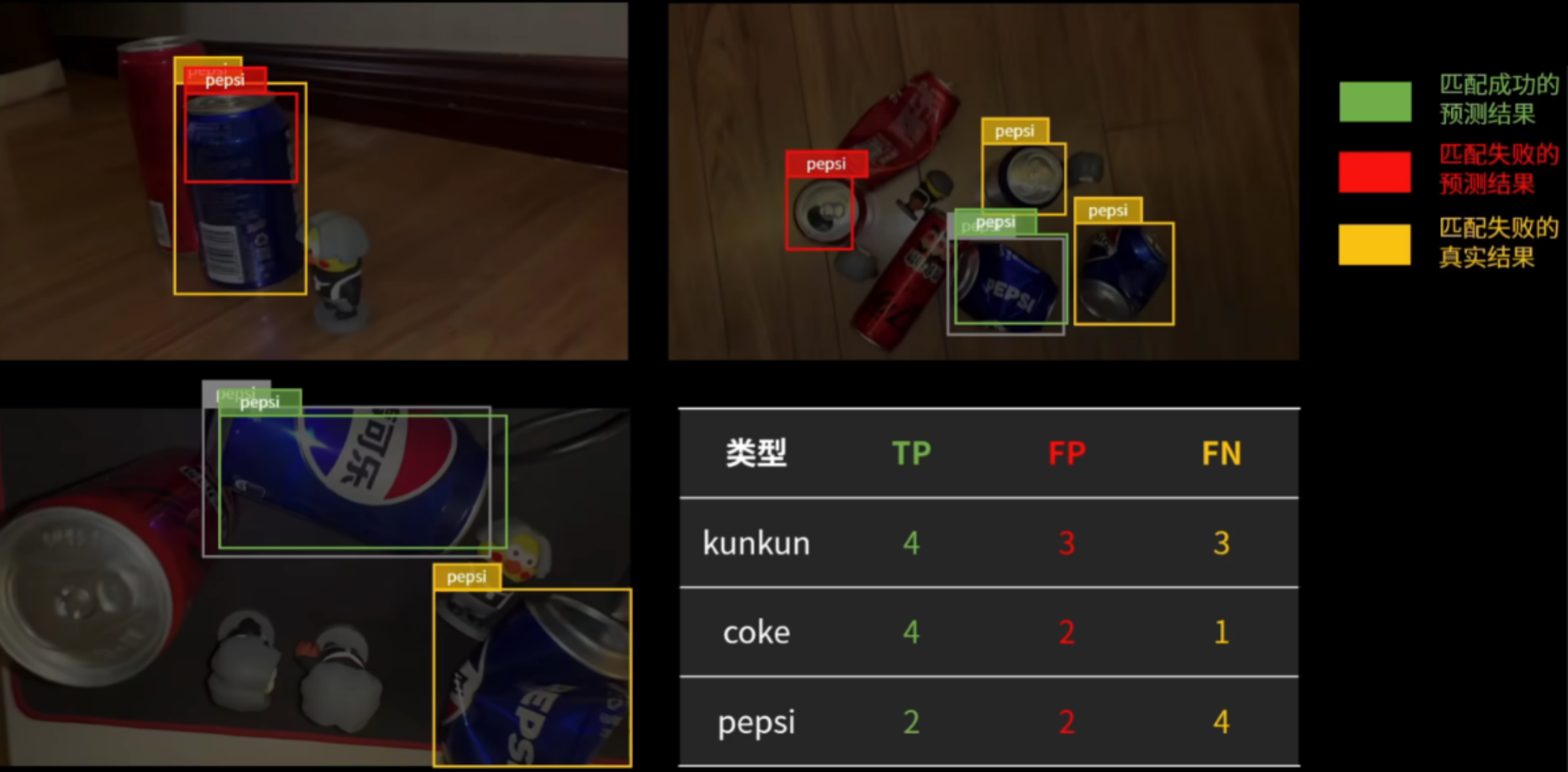
- TP正检:【是小汽车且被正确预测到】
- FP错检:【不是小汽车却被预测成小汽车】
- FN漏检:【是小汽车但是没被预测出来】
TN负检(一般没用)
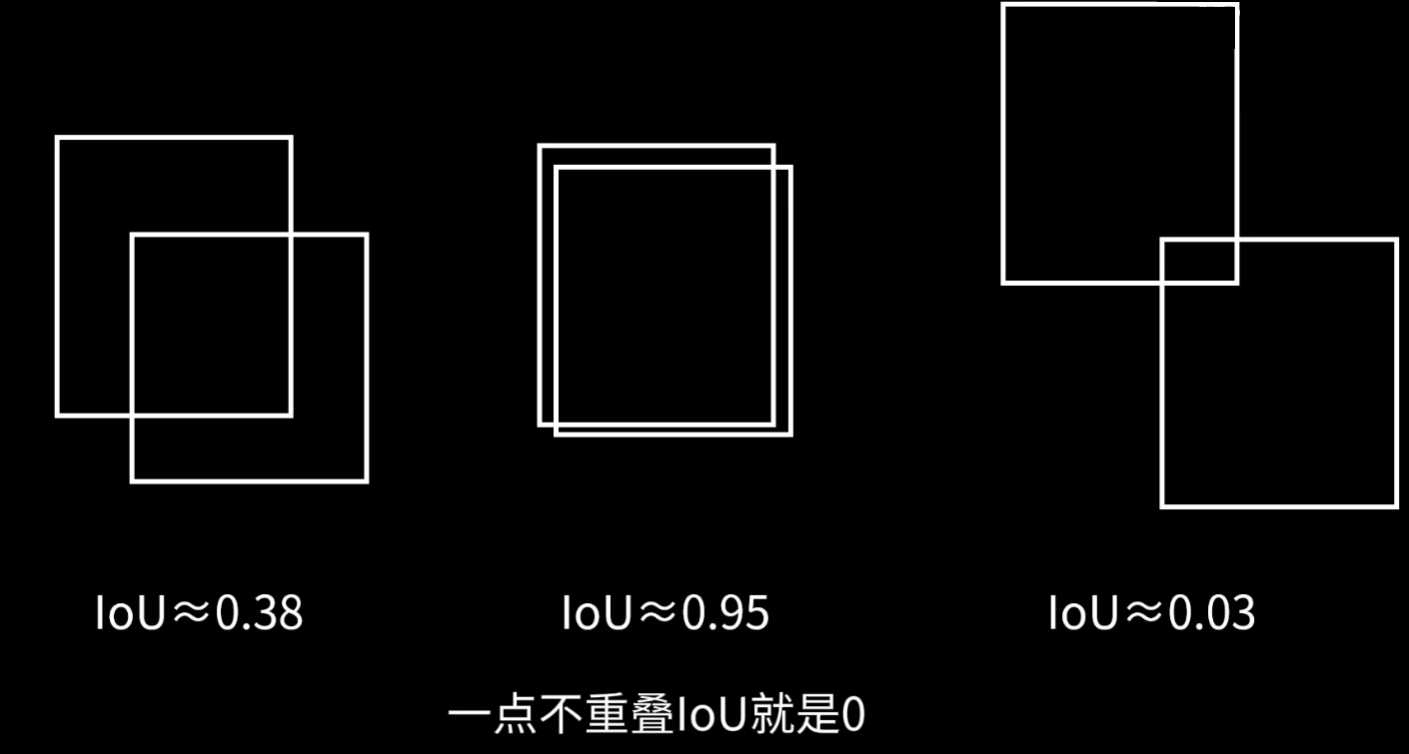
需要注意这几个值是基于我们设定的【IOC值】来判断的,也就是预测框和实际框的差值是否符合阈值内,而不是预测出了这个目标就是对了
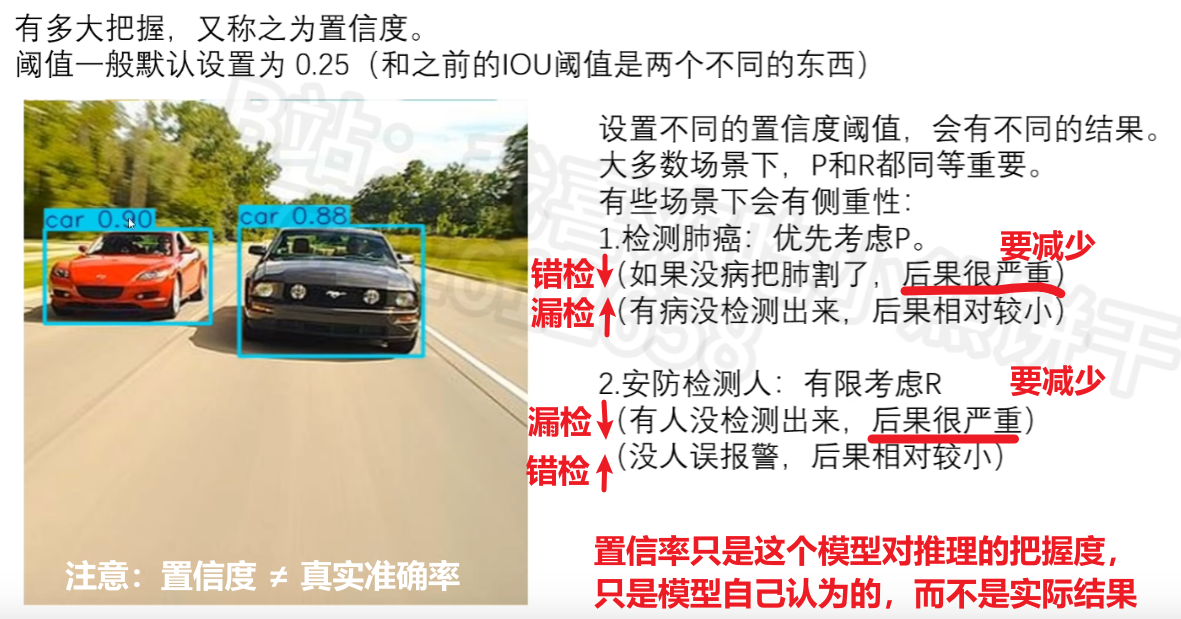
有了TP / FP / FN,就可以计算出Precision、Recall这两个指标值,也称P值、R值
P曲线、R曲线、AP的含义
mAP、F1的含义
其实说白了AP、mAP、F1.......都是在综合考察【P和R】的指标







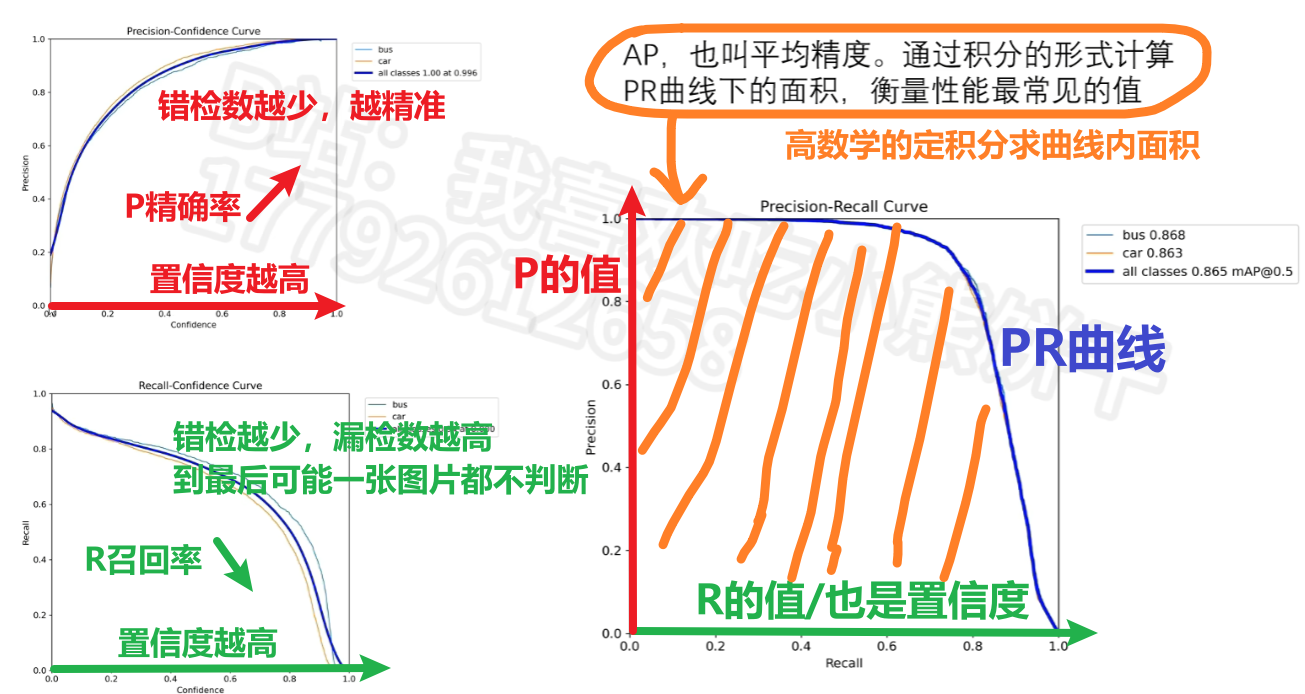


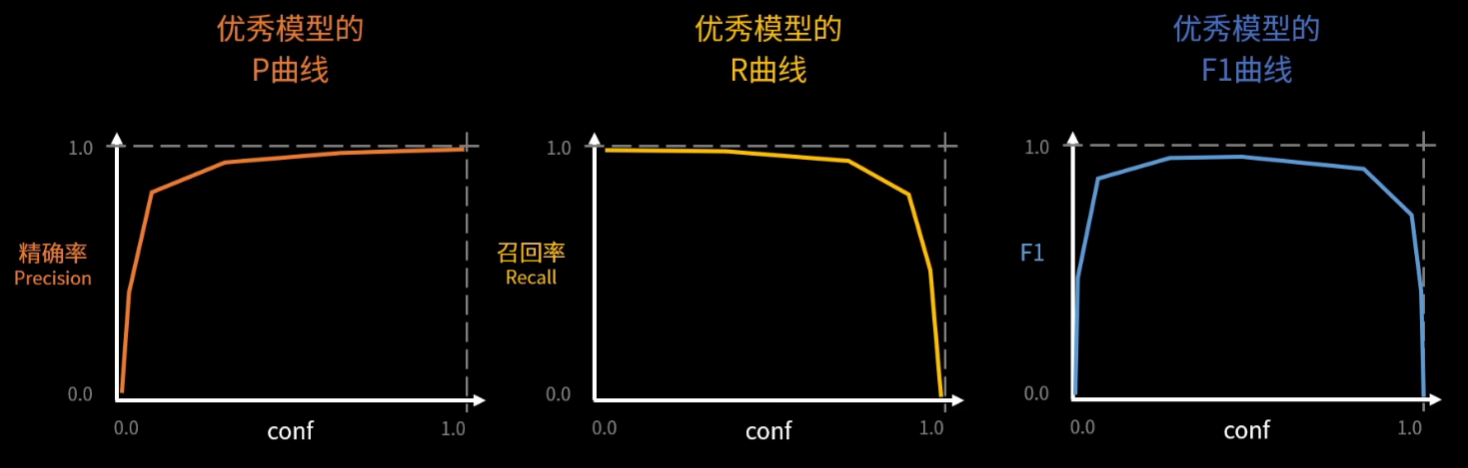
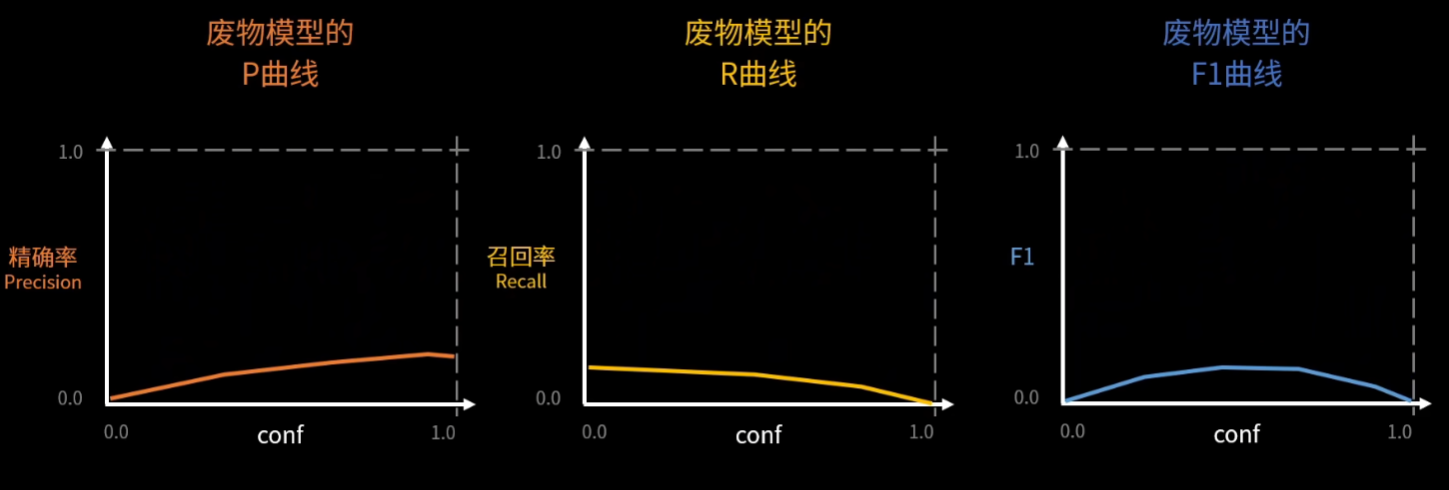
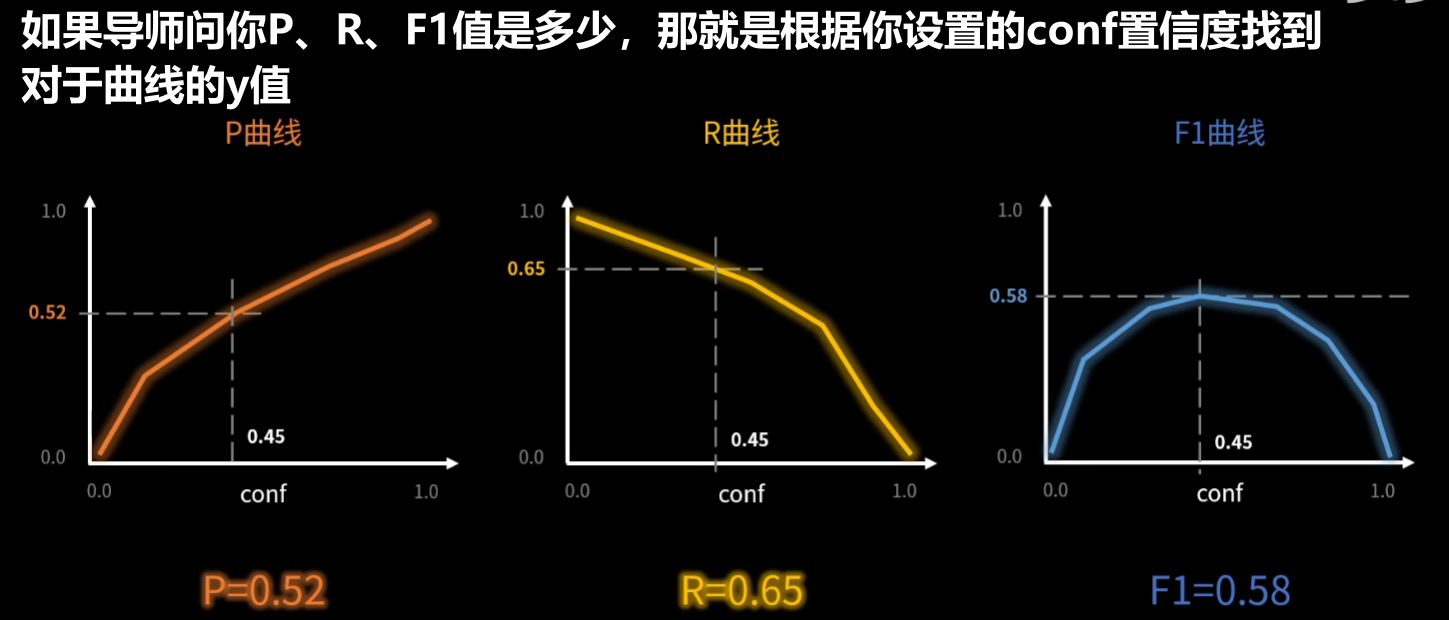
2、训练和验证原理
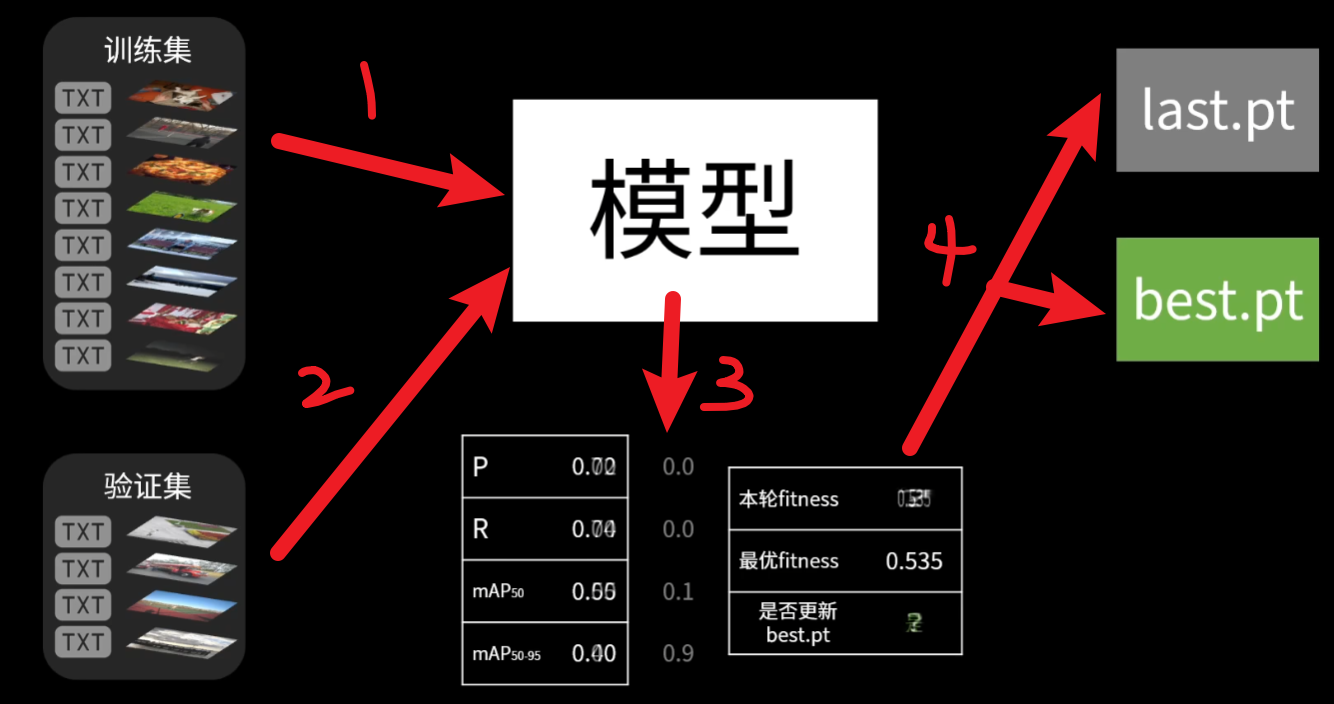
那么我们训练的过程其实就已经在自动验证了,每一轮训练的时候,模型先从【训练集】那一组图片学习,然后再去【验证集】拿一组图片验证刚刚学习的结果,会得到这一轮的4个评估结果:P、R、mAP50、mAP50~95(控制台的每一轮的进度条会看到),然后4个值进行加权平均数计算后得到一个【本轮适应度fitness】,然后更新到【last.pt】,而【best.pt】则是每一轮都跟上一轮对比,如果没有上一轮的适应度好就不会更新,所以为什么叫他best,顾名思义。
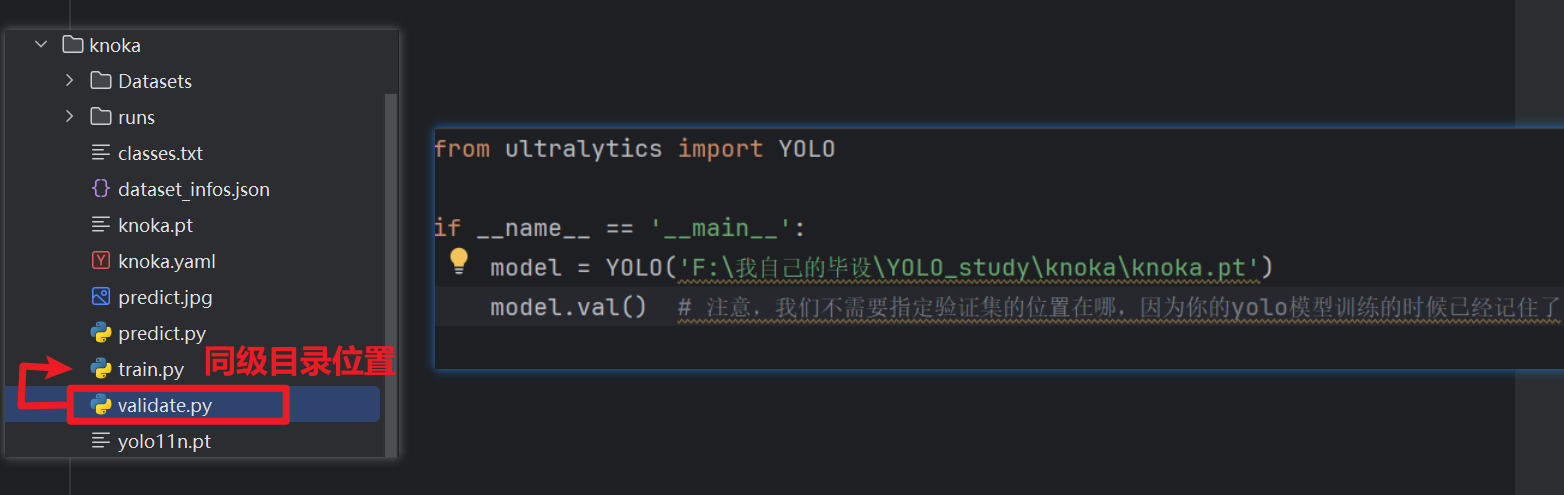
3、手动验证
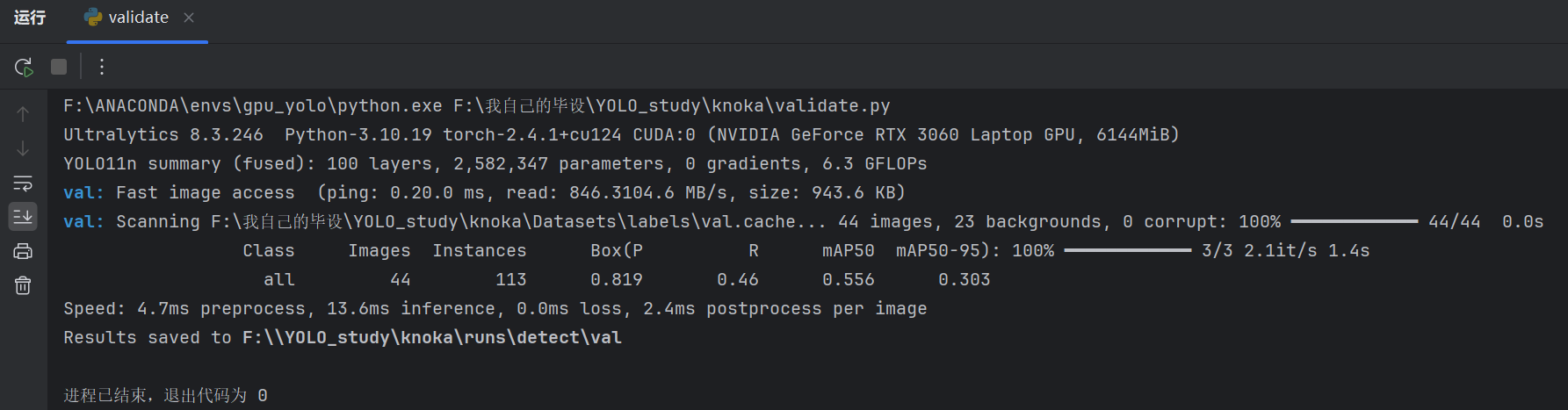
当然我们也可以手动验证,只需要在【和训练模型的py文件同级别的目录下】创建一个验证代码py文件,然后协商这样的代码(注意不需要写验证集的位置这些参数了,因为训练的时候模型已经记住了你验证集的位置)
;
就会得到前面我们说到的P、R、mAP.....这些数据统计图,也就是验证后的模型评估指标
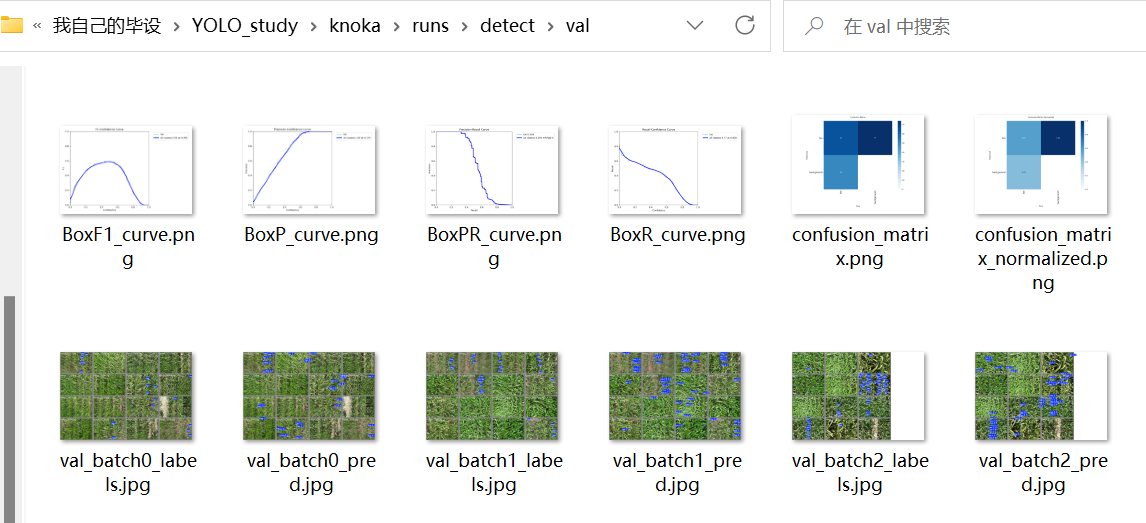
下一篇讲YOLO项目实战
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)