
深度学习毕业设计基于TensorFlow卷积神经网络声纹识别系统
与部署:将训练好的CNN模型集成到一个完整的声纹识别系统中,包括语音输入模块、模型推理模块和结果输出模块等。模型评估与调优:使用独立的测试数据集对训练好的模型进行评估,计算模型的准确率、召回率等指标。同时,可以采用数据增强技术,如音频变速、变调等,提高模型的泛化能力。(CNN)的声纹识别系统是一种先进的身份认证技术,它通过分析语音信号中的声纹特征来识别说话人的身份。声纹识别,又称说话人识别,利用了
收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
一、项目介绍
基于TensorFlow卷积神经网络(CNN)的声纹识别系统是一种先进的身份认证技术,它通过分析语音信号中的声纹特征来识别说话人的身份。以下是对该系统的详细介绍:
一、系统概述
声纹识别,又称说话人识别,利用了每个人独特的语音特征,如声调、音质、语速等。随着人工智能和深度学习技术的飞速发展,声纹识别技术已广泛应用于身份认证、语音助手、智能家居等领域。基于TensorFlow框架和CNN技术构建的声纹识别系统,旨在提高识别的准确性和鲁棒性。
二、功能介绍
该系统主要包括以下几个部分:
数据准备:收集包含多个说话人语音的数据集,并进行标注。数据集应包括说话人的身份信息、语音内容等。同时,对语音数据进行必要的预处理操作,如降噪、分帧等。
模型构建:使用TensorFlow框架构建CNN模型。模型应包含多个卷积层、池化层和全连接层,以提取语音信号中的深层次特征并进行分类。
模型训练:将预处理后的语音数据输入到CNN模型中进行训练。在训练过程中,可以使用适当的损失函数和优化算法,如交叉熵损失函数和Adam优化算法,对模型进行优化。同时,可以采用数据增强技术,如音频变速、变调等,提高模型的泛化能力。
模型评估与调优:使用独立的测试数据集对训练好的模型进行评估,计算模型的准确率、召回率等指标。根据评估结果对模型进行调优,如调整模型结构、参数等,以提高模型的性能。
系统集成与部署:将训练好的CNN模型集成到一个完整的声纹识别系统中,包括语音输入模块、模型推理模块和结果输出模块等。系统应支持实时语音输入和识别,并能够将识别结果以可视化或文本形式输出给用户。
三、核心代码
部分代码:
import argparse
import functools
import shutil
import numpy as np
import tensorflow as tf
import os
import librosa.display
import matplotlib.pyplot as plt
import qdarkstyle
from utils.reader import load_audio
from utils.record import RecordAudio
from utils.utility import add_arguments, print_arguments
from PySide2.QtWidgets import QApplication, QInputDialog, QLineEdit, QFileDialog, QMainWindow
from PySide2.QtUiTools import QUiLoader
from PySide2.QtGui import QIcon
parser = argparse.ArgumentParser(description=__doc__)
add_arg = functools.partial(add_arguments, argparser=parser)
add_arg('audio_db', str, 'audio_db', '音频库的路径')
add_arg('input_shape', str, '(257, 257, 1)', '数据输入的形状')
add_arg('threshold', float, 0.7, '判断是否为同一个人的阈值')
add_arg('model_path', str, 'models/infer_model.h5', '预测模型的路径')
args = parser.parse_args()
print_arguments(args)
# 加载模型
model = tf.keras.models.load_model(args.model_path)
model = tf.keras.models.Model(inputs=model.input, outputs=model.get_layer('batch_normalization').output)
# 获取均值和标准值
input_shape = eval(args.input_shape)
# 打印模型
model.build(input_shape=input_shape)
model.summary()
person_feature = []
person_name = []
# 预测音频
def infer(audio_path):
data = load_audio(audio_path, mode='infer', spec_len=input_shape[1])
data = data[np.newaxis, :] # 形成一个张量
feature = model.predict(data)
return feature
# 加载要识别的音频库
def load_audio_db(audio_db_path):
audios = os.listdir(audio_db_path)
for audio in audios:
path = os.path.join(audio_db_path, audio)
name = audio[:-4]
feature = infer(path)[0]
person_name.append(name)
person_feature.append(feature)
print("Loaded %s audio." % name)
# 声纹识别
def recognition(path):
name = ''
pro = 0
feature = infer(path)[0]
for i, person_f in enumerate(person_feature):
dist = np.dot(feature, person_f) / (np.linalg.norm(feature) * np.linalg.norm(person_f)) # 值越接近1说明两个向量夹角越接近于0
if dist > pro:
pro = dist
name = person_name[i]
return name, pro
def judge(path, name_user):
pro = 0
feature = infer(path)[0]
for i, person_f in enumerate(person_feature):
if person_name[i] == name_user:
pro = np.dot(feature, person_f) / (np.linalg.norm(feature) * np.linalg.norm(person_f)) # 值越接近1说明两个向量夹角越接近于0
return pro
# 声纹注册
def register(path, user_name):
save_path = os.path.join(args.audio_db, user_name + os.path.basename(path)[-4:])
shutil.move(path, save_path)
feature = infer(save_path)[0]
person_name.append(user_name)
person_feature.append(feature)
load_audio_db(args.audio_db)
record_audio = RecordAudio()
# 声纹频域特征
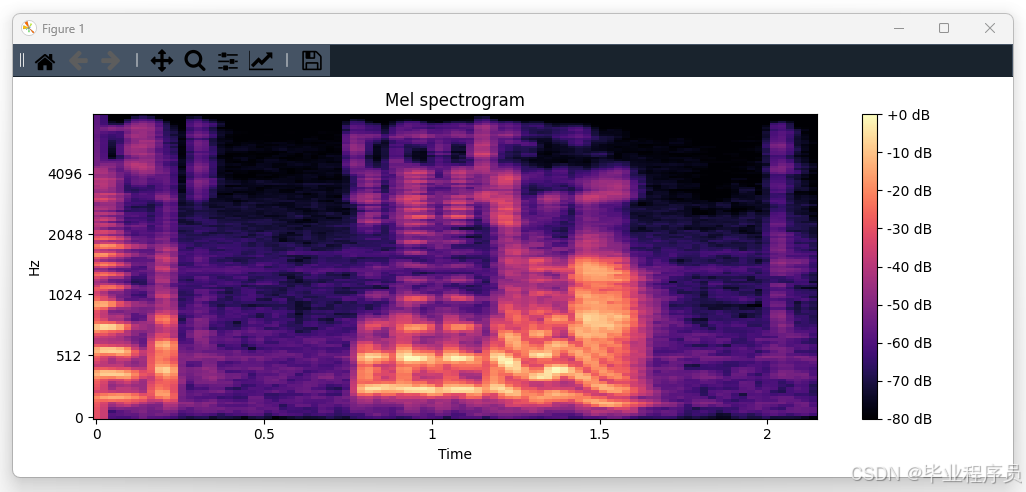
def audio_feature_frequency(audio_path, name):
y, sr = librosa.load(str(audio_path), sr=16000)
D = np.abs(librosa.stft(y)) ** 2
S = librosa.feature.melspectrogram(S=D)
plt.figure(figsize=(10, 4))
librosa.display.specshow(librosa.power_to_db(S, ref=np.max), y_axis='mel', fmax=8000, x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel spectrogram')
plt.tight_layout()
if name == 'temp':
plt.show()
else:
plt.savefig('audio_feature_frequency/{}.png'.format(name))
plt.close()
# 声纹时域特征
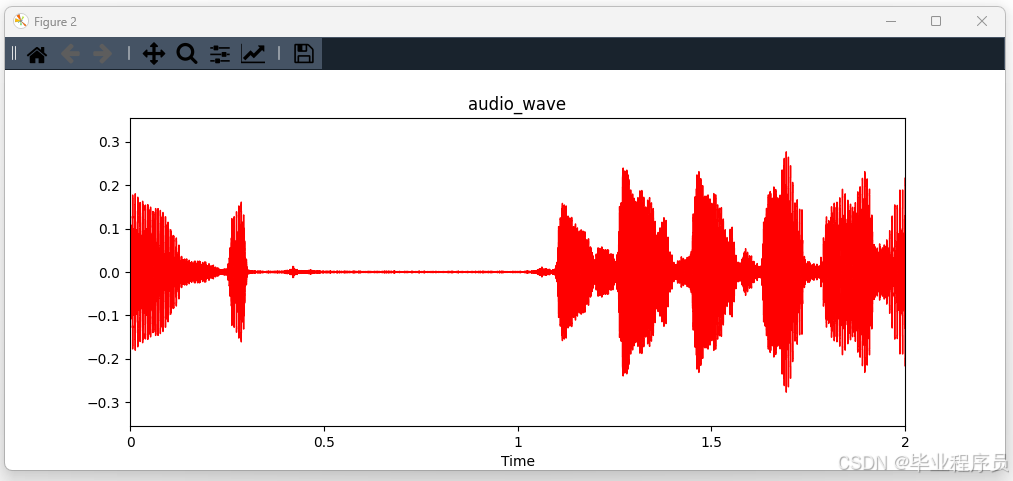
def audio_feature_time(audio_path, name):
y, sr = librosa.load(str(audio_path), sr=16000)
plt.figure(figsize=(10, 4))
librosa.display.waveshow(y, sr=16000, color='red')
plt.title('audio_wave')
plt.xlim(0, 2)
if name == 'temp':
plt.show()
else:
plt.savefig('audio_feature_time/{}.png'.format(name))
plt.close()
def handle_frequency():
directory = QFileDialog.getOpenFileName(QMainWindow(), "频域特征列表", "audio_feature_frequency")
plt.figure(figsize=(10, 6))
im = plt.imread(directory[0])
plt.imshow(im)
plt.axis('off')
plt.show()
def handle_time():
directory = QFileDialog.getOpenFileName(QMainWindow(), "时域特征列表", "audio_feature_time")
plt.figure(figsize=(10, 6))
im = plt.imread(directory[0])
plt.imshow(im)
plt.axis('off')
plt.show()
class Voice:
def __init__(self):
self.ui = QUiLoader().load('GUI/gui_1.ui')
self.ui.button_start.clicked.connect(self.handle_start)
self.ui.button_true_or_fake.clicked.connect(self.handle_true_or_fake)
self.ui.button_remove.clicked.connect(self.handle_remove)
self.ui.button_register.clicked.connect(self.handle_register)
self.ui.button_remove_result.clicked.connect(self.handle_remove_result)
self.ui.button_time.clicked.connect(handle_time)
self.ui.button_frequency.clicked.connect(handle_frequency)
self.wavelib = os.listdir('audio_db')
for k in range(len(self.wavelib)):
self.ui.textBrowser_2.append(str(self.wavelib[k]))
def handle_remove(self):
self.ui.textBrowser_2.clear()
shutil.rmtree('audio_db')
os.mkdir('audio_db')
shutil.rmtree('audio_feature_frequency')
os.mkdir('audio_feature_frequency')
shutil.rmtree('audio_feature_time')
os.mkdir('audio_feature_time')
def handle_remove_result(self):
self.ui.textBrowser.clear()
def handle_register(self):
audio_path = record_audio.record(self.ui)
name, ok = QInputDialog.getText(self.ui, 'Text Input Dialog', '请输入该音频用户的名称:', QLineEdit.Normal)
register(audio_path, name)
audio_feature_frequency('audio_db/{}.wav'.format(name), name)
audio_feature_time('audio_db/{}.wav'.format(name), name)
self.ui.textBrowser_2.append(name)
def handle_start(self):
audio_path = record_audio.record(self.ui)
name, p = recognition(audio_path)
audio_feature_frequency('audio/temp.wav', 'temp')
audio_feature_time('audio/temp.wav', 'temp')
if p > args.threshold:
self.ui.textBrowser.append("识别说话的为:%s,相似度为:%f" % (name, p))
self.ui.textBrowser.ensureCursorVisible()
else:
self.ui.textBrowser.append("音频库没有该用户的语音")
self.ui.textBrowser.ensureCursorVisible()
def handle_true_or_fake(self):
audio_path = record_audio.record(self.ui)
name, ok = QInputDialog.getText(self.ui, 'Text Input Dialog', '你是谁?', QLineEdit.Normal)
p = judge(audio_path, name)
audio_feature_frequency('audio/temp.wav', 'temp')
audio_feature_time('audio/temp.wav', 'temp')
if p > 0:
if p > args.threshold:
self.ui.textBrowser.append("你是%s,相似度为:%f" % (name, p))
self.ui.textBrowser.ensureCursorVisible()
else:
self.ui.textBrowser.append("你不是%s,相似度为:%f" % (name, p))
self.ui.textBrowser.ensureCursorVisible()
else:
self.ui.textBrowser.append("注册库里没有您的名字" )
self.ui.textBrowser.ensureCursorVisible()
app = QApplication([])
stats = Voice()
app.setWindowIcon(QIcon('logo.ico'))
app.setStyleSheet(qdarkstyle.load_stylesheet_pyside2())
stats.ui.show()
app.exec_()
四、效果图
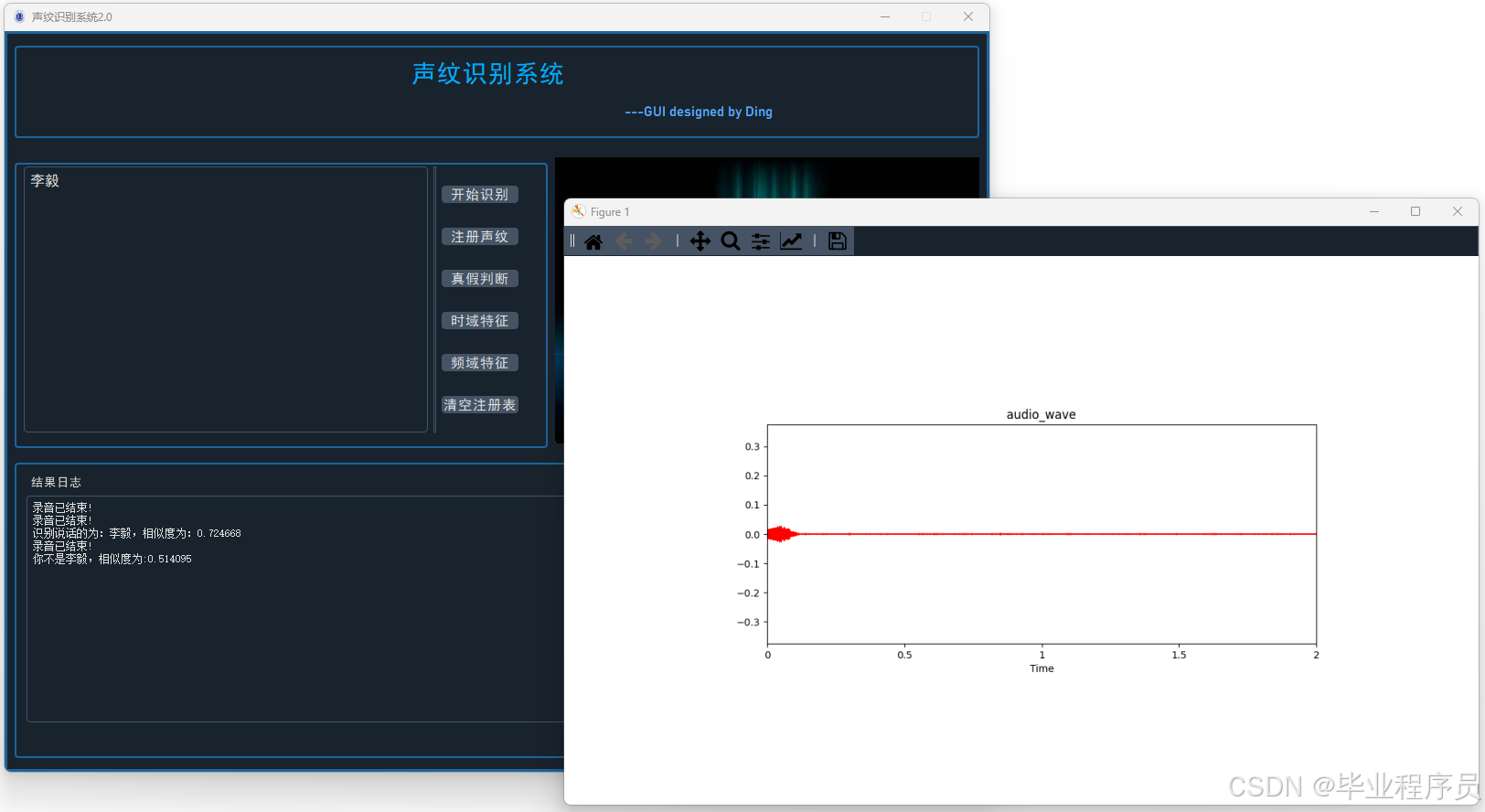
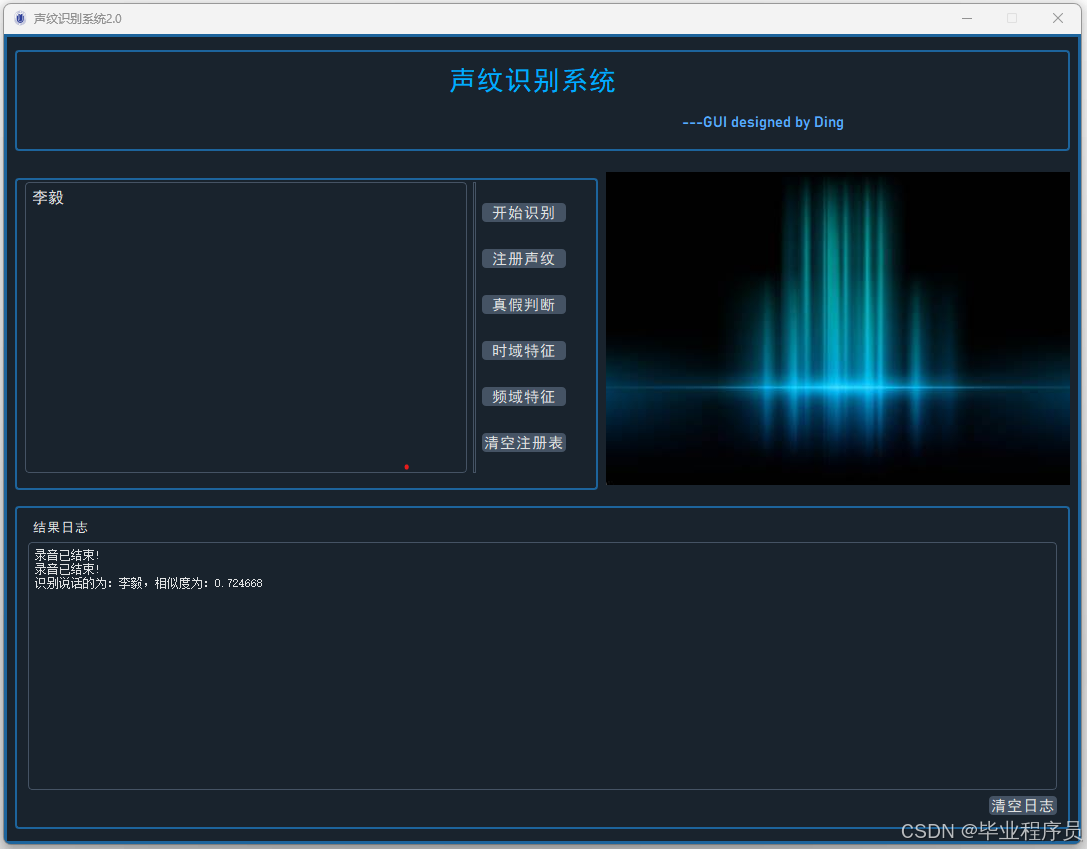
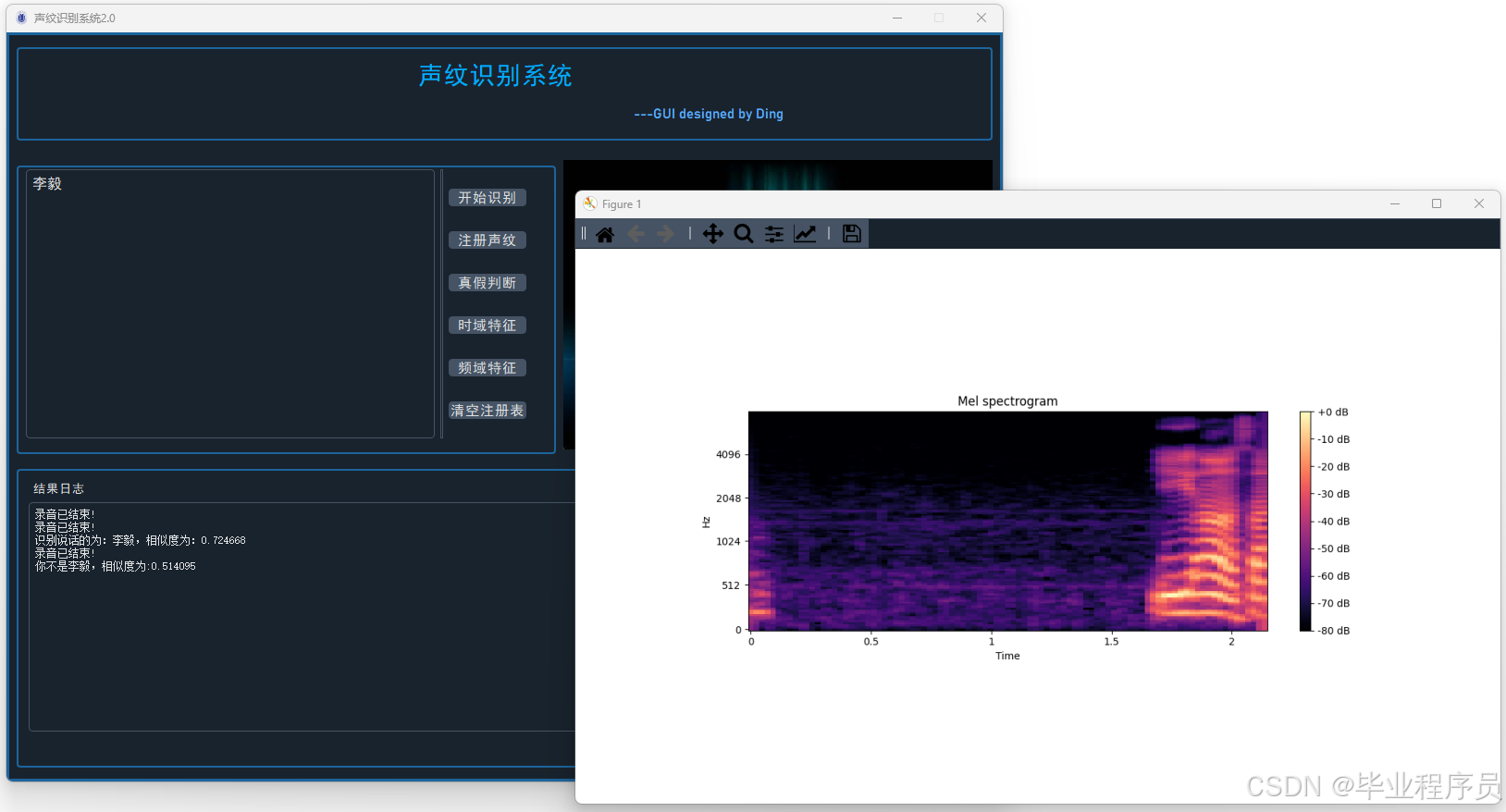
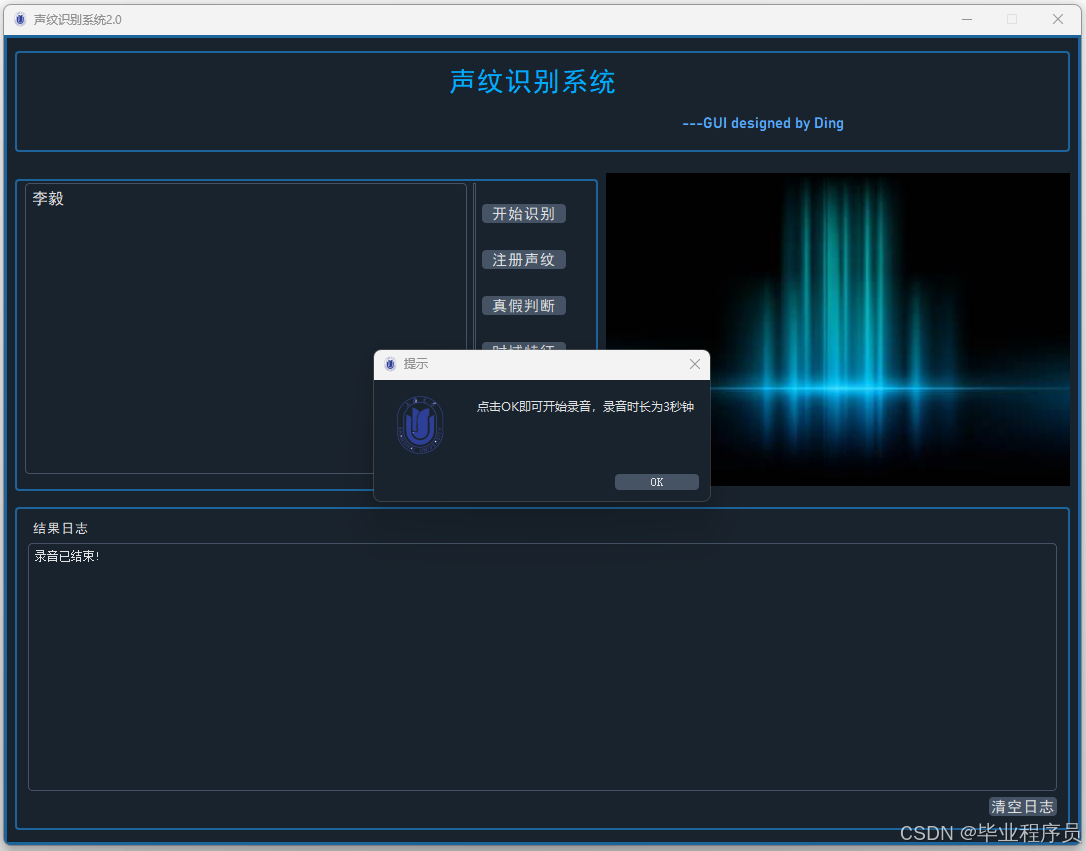
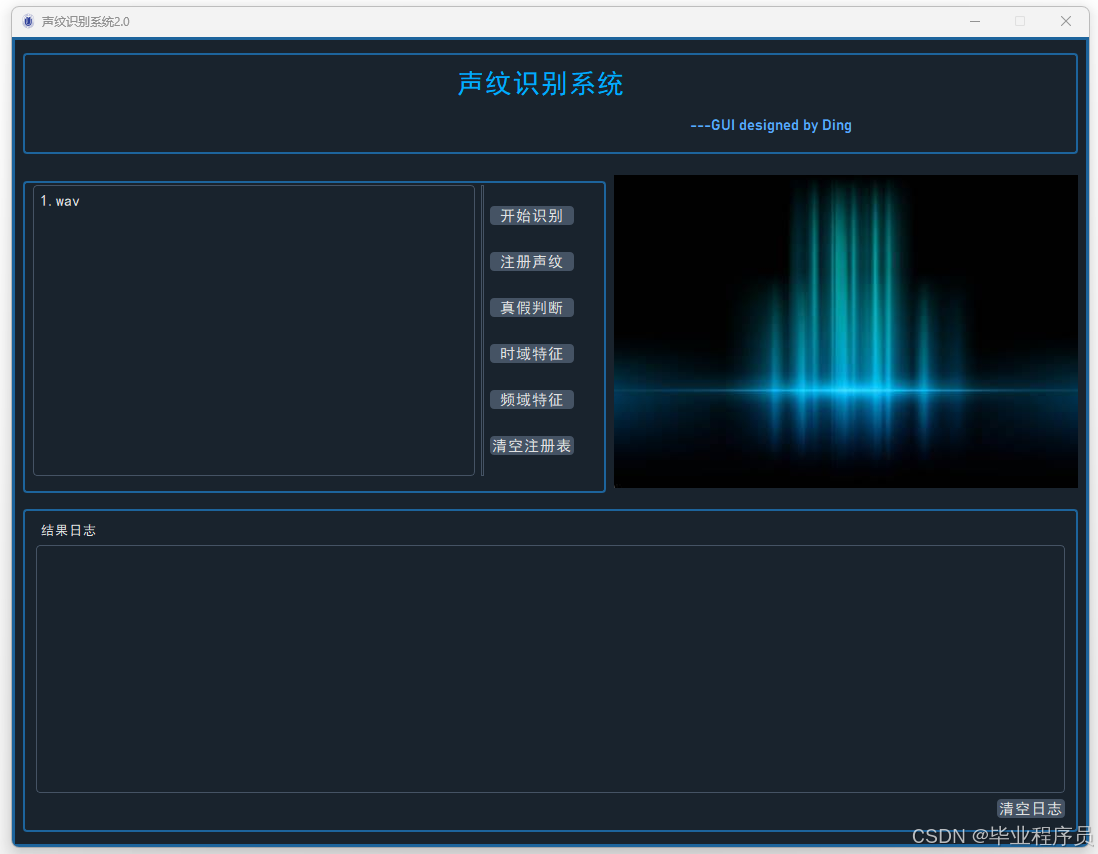
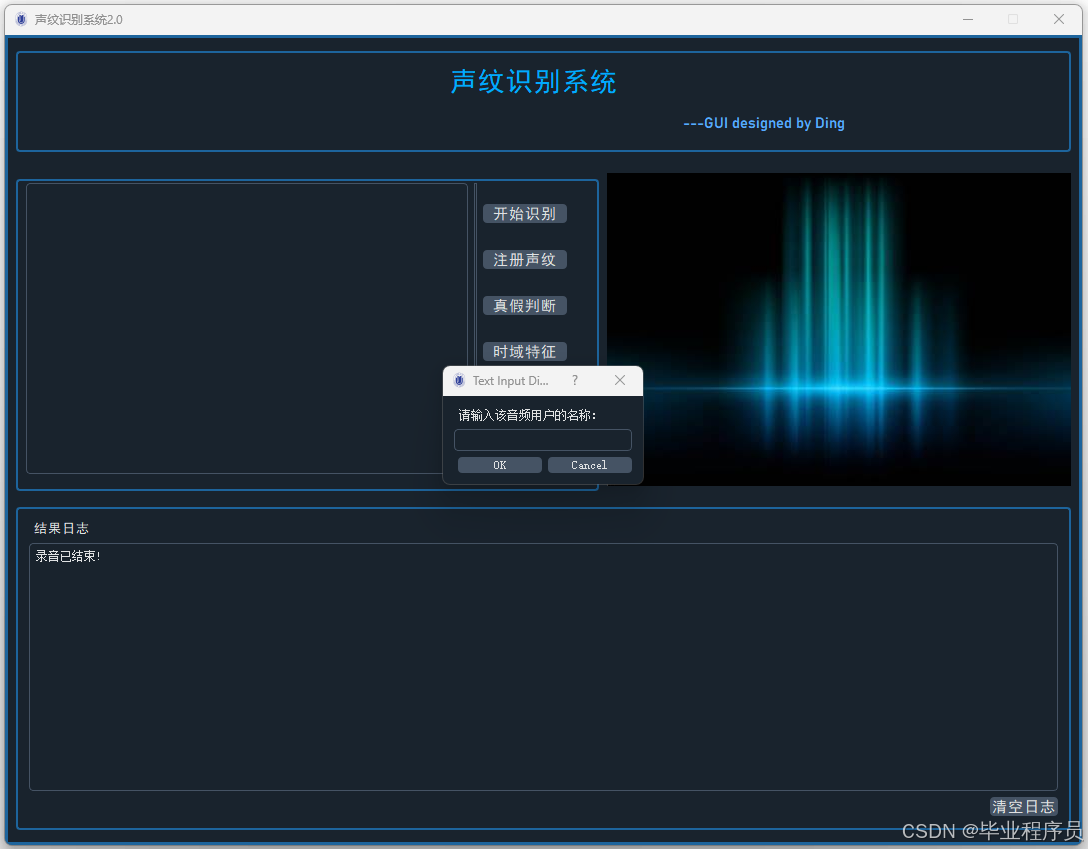
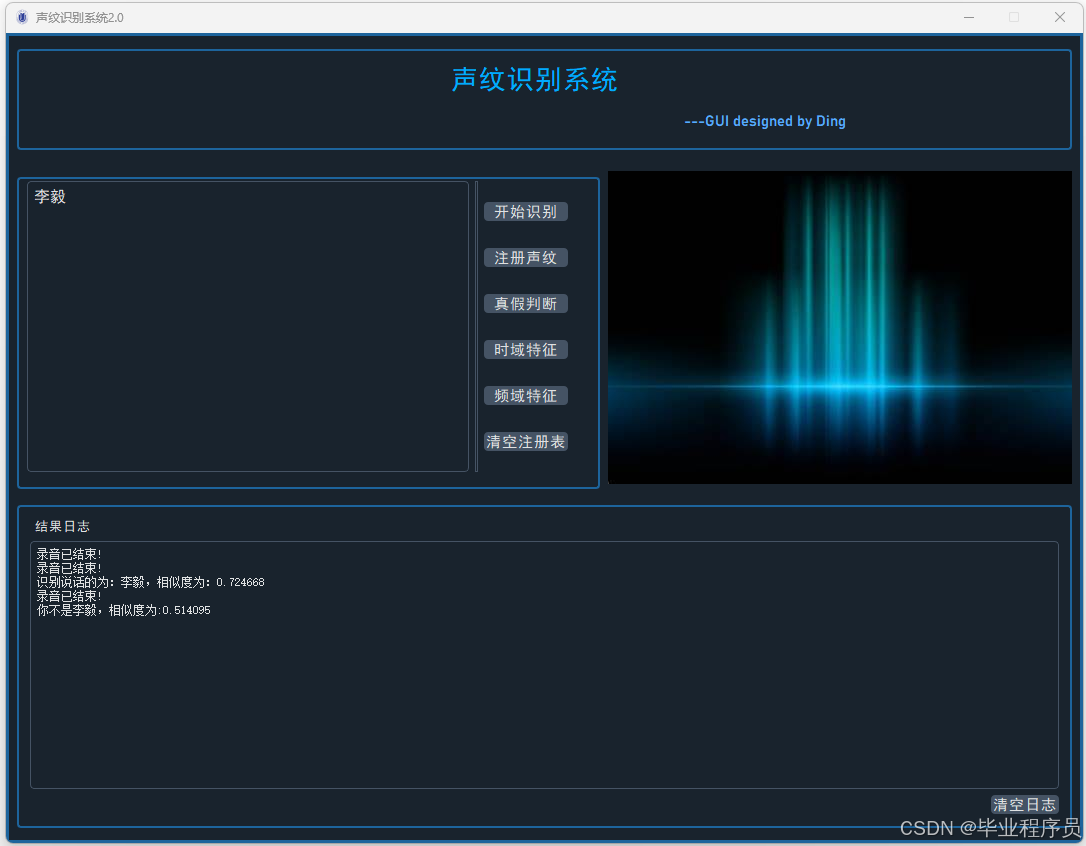
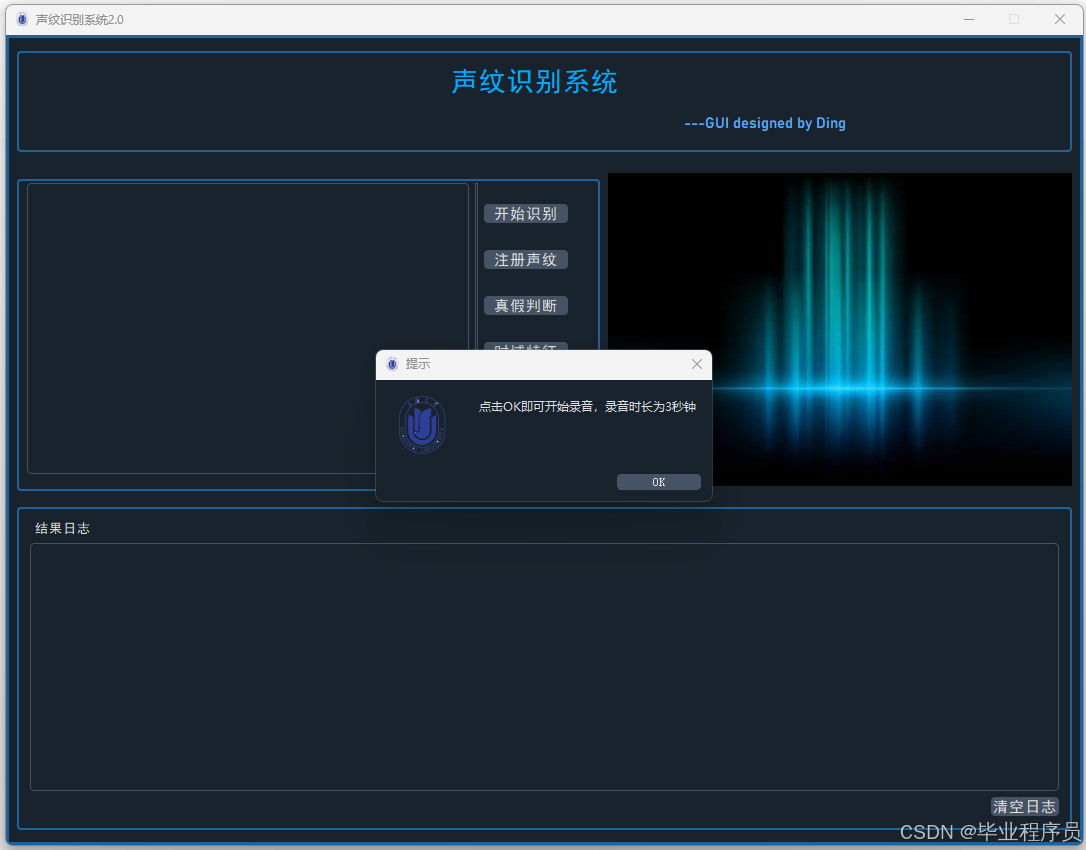
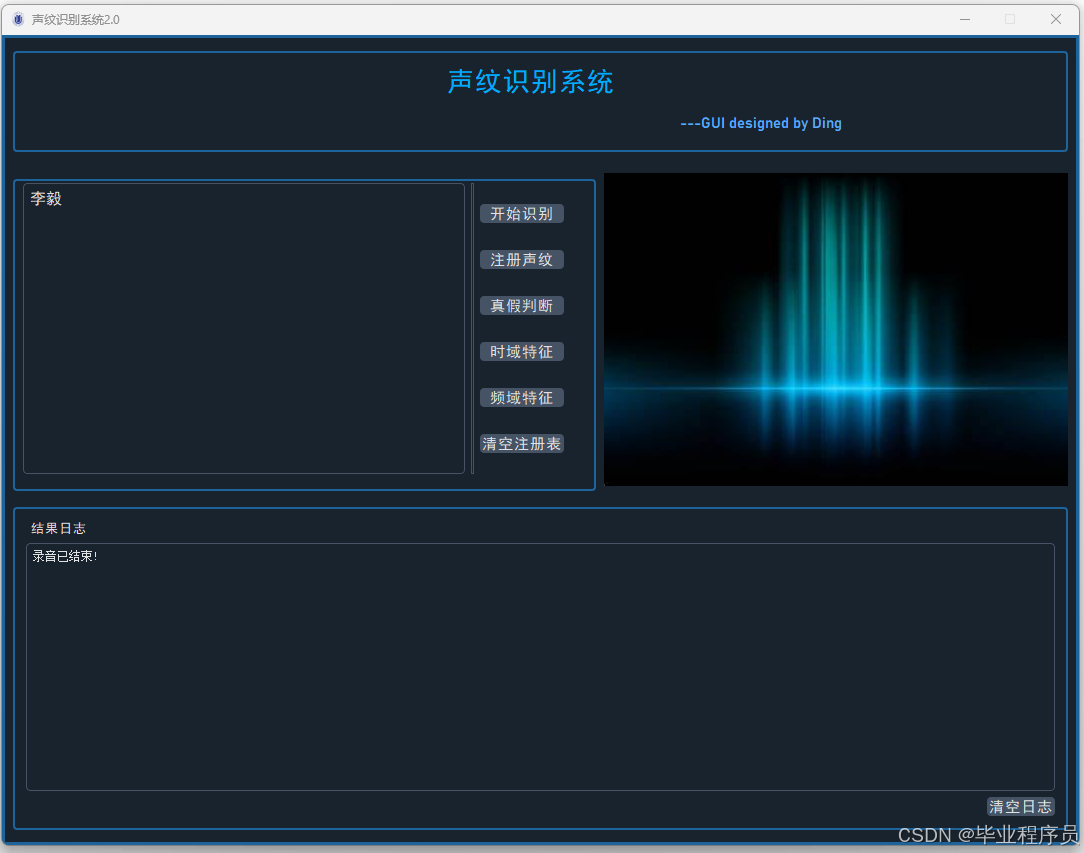
五、文章目录
目 录
1 绪 论 1
1.1 选题的背景 1
1.2 国内外研究现状 1
1.3 选题的目的和意义 1
1.4主要研究内容 3
2 相关技术介绍 5
2.1 卷积神经网络 5
2.2 系统开发相关技术 9
3 数据获取及预处理 14
3.1 数据集的获取及简介 14
3.2 数据预处理 17
4 模型训练与评估 18
4.1 模型选择 14
3.2 模型训练 17
4.3 模型评估 17
5 模型优化 18
5.1 优化器选择 14
5.2 效果对比分析 17
6 系统部署 19
6.1 需求分析 14
6.2 系统设计与实现 17
6.3 系统测试 17
7 总结与展望 29
7.1 总结 29
7.2 展望 29
参考文献 30
致 谢 33
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)