
深度学习处理时间系列(不同类型的时间序列任务)
(timeseries)是指定期测量获得的任意数据,比如每日股价、城市每小时耗电量或商店每周销售额。无论是自然现象(如地震活动、鱼类种群的演变或某地天气)还是人类活动模式(如网站访问者、国家GDP 或信用卡交易),时间序列都无处不在。与前面遇到的数据类型不同,处理时间序列需要了解系统的(dynamics),包括系统的周期性循环、系统随时间如何变化、系统的周期规律与突然激增等。目前,最常见的时间序列
不同类型的时间序列任务
时间序列(timeseries)是指定期测量获得的任意数据,比如每日股价、城市每小时耗电量
或商店每周销售额。无论是自然现象(如地震活动、鱼类种群的演变或某地天气)还是人类活
动模式(如网站访问者、国家GDP 或信用卡交易),时间序列都无处不在。与前面遇到的数据
类型不同,处理时间序列需要了解系统的动力学(dynamics),包括系统的周期性循环、系统随
时间如何变化、系统的周期规律与突然激增等。
目前,最常见的时间序列任务是预测:预测序列接下来会发生什么。比如提前几小时预测
用电量,以便于预计需求;提前几个月预测收入,以便于制订预算计划;提前几天预测天气,
以便于规划日程。预测是本章的重点内容。但实际上,你还可以对时间序列做很多其他事情。
- 分类:为时间序列分配一个或多个分类标签。例如,已知一名网站访问者的活动时间序
列,判断该访问者是机器人还是人类。 - 事件检测:识别连续数据流中特定预期事件的发生。一个特别有用的应用是“热词检测”,
模型监控音频流并检测像“Ok Google”或“Hey Alexa”这样的话。 - 异常检测:检测连续数据流中出现的异常情况。公司网络出现异常活动?可能是有攻击
者。生产线出现异常读数?是时候让人去查看一下了。异常检测通常是通过无监督学习
实现的,因为你通常不知道要检测哪种异常,所以无法针对特定的异常示例进行训练。
处理时间序列时,你会遇到许多特定领域的数据表示方法。例如,你可能听说过傅里叶变换,
它是指将一系列值表示为不同频率的波的叠加。对那些以周期和振荡为主要特征的数据(如声
音、摩天大楼的振动或人的脑电波)进行预处理时,傅里叶变换可以发挥很大作用。对于深度
学习而言,傅里叶分析(或相关的梅尔频率分析)与其他特定领域的表示可以用来做特征工程。
这是一种在训练模型之前准备数据的方式,以便让模型更容易运行。然而,本章不会介绍这些
技术,而是将重点放在构建模型上。
本章将介绍循环神经网络(recurrent neural network,RNN)及如何将其应用于时间序列预测。
温度预测示例
本章所有代码示例都针对同一个问题:已知每小时测量的气压、湿度等数据的时间序列(数
据由屋顶的一组传感器记录),预测24 小时之后的温度。你会发现,这是一个相当有挑战性的
问题。
利用这个温度预测任务,我们会展示时间序列数据与之前见过的各类数据集在本质上有哪
些不同。你会发现,密集连接网络和卷积神经网络并不适合处理这种数据集,而另一种机器学
习技术——循环神经网络——在这类问题上大放异彩。
我们将使用一个天气时间序列数据集,它由德国耶拿的马克斯• 普朗克生物地球化学研究
所的气象站记录。在这个数据集中,每10 分钟记录14 个物理量(如温度、气压、湿度、风向等),
其中包含多年的记录。原始数据可追溯至2003 年,但本例仅使用2009 年~ 2016 年的数据。
首先下载数据并解压,如下所示。
!wget https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip
!unzip jena_climate_2009_2016.csv.zip
下面我们来查看数据,如代码清单10-1 所示。
代码清单10-1 查看耶拿天气数据集
import os
fname = os.path.join("jena_climate_2009_2016.csv")
with open(fname) as f:
data = f.read()
lines = data.split("\n")
header = lines[0].split(",")
lines = lines[1:]
print(header)
print(len(lines))
从输出可以看出,共有420 451 行数据(每行数据是一个时间步,记录了1 个日期和14 个
与天气有关的值),输出还包含以下表头。
["Date Time",
"p (mbar)",
"T (degC)",
"Tpot (K)",
"Tdew (degC)",
"rh (%)",
"VPmax (mbar)",
"VPact (mbar)",
"VPdef (mbar)",
"sh (g/kg)",
"H2OC (mmol/mol)",
"rho (g/m**3)",
"wv (m/s)",
"max. wv (m/s)",
"wd (deg)"]
接下来,我们将所有420 451 行数据转换为NumPy 数组,如代码清单10-2 所示:一个数组
包含温度(单位为摄氏度),另一个数组包含其他数据。我们将使用这些特征来预测温度。请注
意,我们舍弃了"Date Time"(日期和时间)这一列。
代码清单10-2 解析数据

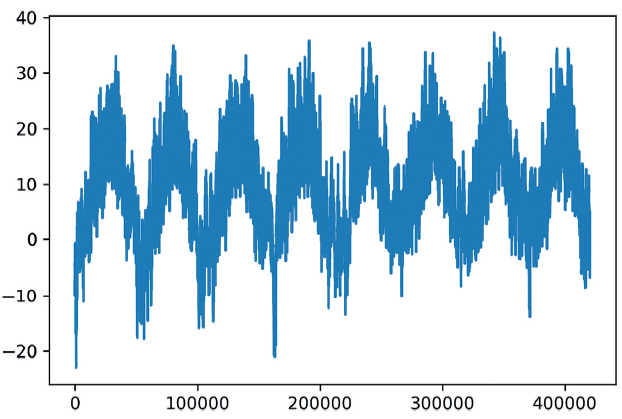
我们来绘制温度随时间的变化曲线(单位为摄氏度),如代码清单10-3 和图10-1 所示。在
这张图中,你可以清楚地看到温度的年度周期性变化,数据跨度为8 年。
代码清单10-3 绘制温度时间序列
from matplotlib import pyplot as plt
plt.plot(range(len(temperature)), temperature)
我们来绘制前10 天温度数据的曲线,如代码清单10-4 和图10-2 所示。由于每10 分钟记录
一次数据,因此每天有144 个数据点(24×6=144)
代码清单10-4 绘制前10 天的温度时间序列
plt.plot(range(1440), temperature[:1440])
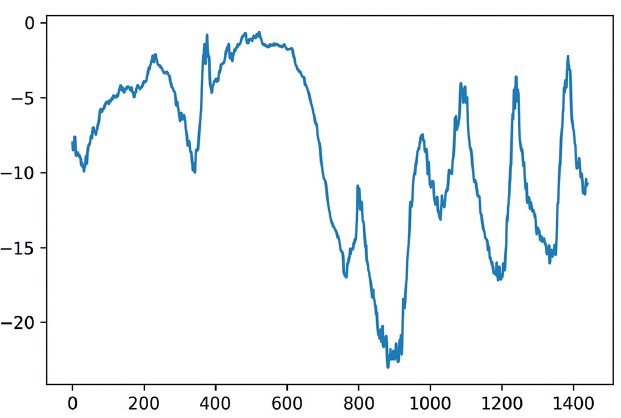
从图10-2 中可以看到每天的周期性变化,尤其是最后4 天特别明显。另外请注意,这10
天一定是来自于寒冷的冬季月份。
对于这个数据集,如果你想根据前几个月的数据来预测下个月的平均温度,那么问题很简
单,因为数据具有可靠的年度周期性。但如果查看几天的数据,那么你会发现温度看起来要混
乱得多。以天作为观察尺度,这个时间序列是可预测的吗?我们来寻找这个问题的答案。
在后续所有实验中,我们将前50% 的数据用于训练,随后的25% 用于验证,最后的25%
用于测试,如代码清单10-5 所示。处理时间序列数据时,有一点很重要:验证数据和测试数据
应该比训练数据更靠后,因为你是要根据过去预测未来,而不是反过来,所以验证/ 测试划分
应该反映这一点。如果将时间轴反转,有些问题就会变得简单得多。
代码清单10-5 计算用于训练、验证和测试的样本数
>>> num_train_samples = int(0.5 * len(raw_data))
>>> num_val_samples = int(0.25 * len(raw_data))
>>> num_test_samples = len(raw_data) - num_train_samples - num_val_samples
>>> print("num_train_samples:", num_train_samples)
>>> print("num_val_samples:", num_val_samples)
>>> print("num_test_samples:", num_test_samples)
num_train_samples: 210225
num_val_samples: 105112
num_test_samples: 105114
准备数据
这个问题的确切表述如下:每小时采样一次数据,给定前5 天的数据,我们能否预测24 小
时之后的温度?
首先,我们对数据进行预处理,将其转换为神经网络可以处理的格式。这很简单。因为数据
已经是数值型的,所以不需要做向量化。但数据中的每个时间序列位于不同的范围,比如气压
大约在1000 毫巴(mbar)a,而水汽浓度(H2OC)大约为3 毫摩尔/ 摩尔(mmol/mol)。我们
将对每个时间序列分别做规范化,使其处于相近的范围,并且都取较小的值,如代码清单10-6
所示。我们使用前210 225 个时间步作为训练数据,所以只计算这部分数据的均值和标准差。
代码清单10-6 数据规范化
mean = raw_data[:num_train_samples].mean(axis=0)
raw_data -= mean
std = raw_data[:num_train_samples].std(axis=0)
raw_data /= std
接下来我们创建一个Dataset 对象,它可以生成过去5 天的数据批量,以及24 小时之后
的目标温度。由于数据集中的样本是高度冗余的(对于样本N 和样本N+1,二者的大部分时间
步是相同的),因此显式地保存每个样本将浪费资源。相反,我们将实时生成样本,仅保存最初
的数组raw_data 和temperature。
我们可以轻松地编写一个Python 生成器来完成这项工作,但也可以直接利用Keras 内置的
数据集函数(timeseries_dataset_from_array()),从而减少工作量。一般来说,你可以
将这个函数用于任意类型的时间序列预测任务。
我们将使用timeseries_dataset_from_array() 来创建3 个数据集,分别用于训练、
验证和测试,如代码清单10-7 所示。
我们将使用以下参数值。
- sampling_rate = 6:观测数据的采样频率是每小时一个数据点,也就是说,每6 个
数据点保留一个。 - sequence_length = 120:给定过去 5 天(120 小时)的观测数据。
- delay = sampling_rate * (sequence_length + 24 - 1):序列的目标是序列
结束24 小时之后的温度。
创建训练数据集时,我们传入start_index = 0 和end_index = num_train_samples,
只使用前50% 的数据。对于验证数据集,我们传入start_index = num_train_samples 和
end_index = num_train_samples + num_val_samples,使用接下来25% 的数据。最后对于测试数据集,我们传入start_index = num_train_samples + num_val_samples,使用
剩余数据。
代码清单10-7 创建3 个数据集,分别用于训练、验证和测试
sampling_rate = 6
sequence_length = 120
delay = sampling_rate * (sequence_length + 24 - 1)
batch_size = 256
train_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=0,
end_index=num_train_samples)
val_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples,
end_index=num_train_samples + num_val_samples)
test_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples + num_val_samples)

每个数据集都会生成一个元组(samples, targets),其中samples 是包含256 个样本
的批量,每个样本包含连续120 小时的输入数据;targets 是包含相应的256 个目标温度的
数组。请注意,因为样本已被随机打乱,所以一批数据中的两个连续序列(如samples[0] 和
samples[1])不一定在时间上接近。我们来查看数据集的输出,如代码清单10-8 所示。
代码清单10-8 查看一个数据集的输出
>>> for samples, targets in train_dataset:
>>> print("samples shape:", samples.shape)
>>> print("targets shape:", targets.shape)
>>> break
samples shape: (256, 120, 14)
targets shape: (256,)
基于常识、不使用机器学习的基准
在开始使用像黑盒子一样的深度学习模型解决温度预测问题之前,我们先尝试一种基于常
识的简单方法。它可以作为一种合理性检查,还可以建立一个基准,更高级的机器学习模型需
要超越这个基准才能证明其有效性。对于一个尚没有已知解决方案的新问题,这种基于常识的
基准很有用。一个经典的例子是不平衡分类任务,其中某些类别比其他类别更常见。如果数据
集中包含90% 的类别A 样本和10% 的类别B 样本,那么对于分类任务,一种基于常识的方法
就是对新样本始终预测类别A。这种分类器的总体精度为90%,因此任何基于机器学习的方法
的精度都应该高于90%,才能证明其有效性。有时候,这样的简单基准可能很难超越。
在本例中,我们可以放心地假设:温度时间序列是连续的(明天的温度很可能接近今天
的温度),并且具有每天的周期性变化。因此,一种基于常识的方法是,始终预测24 小时之
后的温度等于现在的温度。我们用平均绝对误差(MAE)指标来评估这种方法,这一指标的
定义如下。
np.mean(np.abs(preds - targets))
评估循环如代码清单10-9 所示。
代码清单10-9 计算基于常识的基准的MAE

对于这个基于常识的基准,验证MAE 为2.44 摄氏度,测试MAE 为2.62 摄氏度。因此,
如果假设24 小时之后的温度总是与现在相同,那么平均会偏差约2.5 摄氏度。这个结果不算太
差,但你可能不会基于这种启发式方法来推出天气预报服务。接下来,我们将利用深度学习知
识来得到更好的结果。
基本的机器学习模型
在尝试机器学习方法之前,建立一个基于常识的基准是很有用的。同样,在开始研究复杂
且计算代价很大的模型(如RNN)之前,尝试简单且计算代价很小的机器学习模型(比如小型的密集连接网络)也是很有用的。这样做可以保证进一步增加问题复杂度是合理的,能够带来
真正的好处。
代码清单10-10 给出了一个全连接模型:首先将数据展平,然后是两个Dense 层。请注意,
最后一个Dense 层没有激活函数,这是回归问题的典型特征。我们使用均方误差(MSE)作
为损失,而不是平均绝对误差(MAE),因为MSE 在0 附近是光滑的(而MAE 不是),这对梯
度下降来说是一个有用的属性。我们在compile() 中监控MAE 这项指标。
代码清单10-10 训练并评估一个密集连接模型

我们来绘制训练和验证的损失曲线,如代码清单10-11 和图10-3 所示。
代码清单10-11 绘制结果
import matplotlib.pyplot as plt
loss = history.history["mae"]
val_loss = history.history["val_mae"]
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, "bo", label="Training MAE")
plt.plot(epochs, val_loss, "b", label="Validation MAE")
plt.title("Training and validation MAE")
plt.legend()
plt.show()
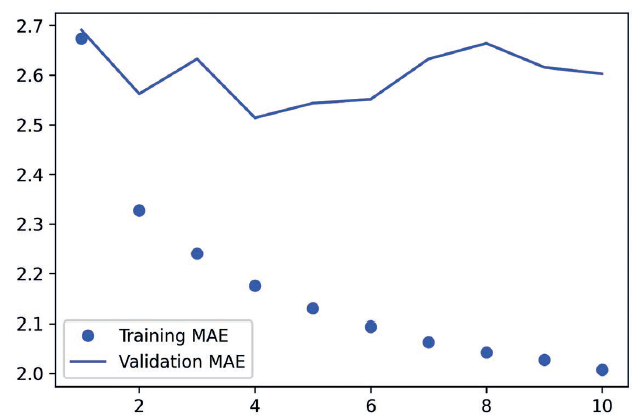
部分验证损失接近不使用机器学习的基准方法,但并不稳定。这也展示了首先建立基准的
优点,事实证明,要超越这个基准并不容易。我们的常识中包含大量有价值的信息,而机器学
习模型并不知道这些信息。
你可能会问,如果从数据到目标之间存在一个简单且表现良好的模型(基于常识的基准),
那么我们训练的模型为什么没有找到它并进一步改进呢?我们在模型空间(假设空间)中搜索
解决方案,这个模型空间是具有我们所定义架构的所有双层网络组成的空间。基于常识的启发
式方法只是这个空间所表示的数百万个模型中的一个。这就好比大海捞针。从技术上说,假设
空间中存在一个好的解决方案,但这并不意味着你可以通过梯度下降找到它。
总体来说,这是机器学习的一个重要限制:如果学习算法没有被硬编码为寻找某种特定类
型的简单模型,那么有时候算法无法找到简单问题的简单解决方案。这就是好的特征工程和架
构预设非常重要的原因:你需要准确告诉模型它要寻找什么。
一维卷积模型
说到利用正确的架构预设,由于输入序列具有每日周期性的特征,或许卷积模型可能有效。
时间卷积神经网络可以在不同日期重复使用相同的表示,就像空间卷积神经网络可以在图像的
不同位置重复使用相同的表示。
你已经学过Conv2D 层和SeparableConv2D 层,它们通过在二维网格上滑动的小窗口来查
看输入。这些层也有一维甚至三维的版本:Conv1D 层、SeparableConv1D 层和Conv3D 层a。
Conv1D 层是在输入序列上滑动一维窗口,Conv3D 层则是在三维输入物体上滑动三维窗口。
因此,你可以构建一维卷积神经网络,它非常类似于二维卷积神经网络。它适用于遵循平
移不变性假设的序列数据。这个假设的含义是,如果沿着序列滑动一个窗口,那么窗口的内容
应该遵循相同的属性,而与窗口位置无关。
我们在温度预测问题上试一下一维卷积神经网络。我们选择初始窗口长度为24,这样就可
以每次查看24 小时的数据(一个周期)。我们对序列进行下采样时(通过MaxPooling1D 层),
也会相应地减小窗口尺寸。
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Conv1D(8, 24, activation="relu")(inputs)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 12, activation="relu")(x)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 6, activation="relu")(x)
x = layers.GlobalAveragePooling1D()(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_conv.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_conv.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")
得到的训练曲线和验证曲线如图10-4 所示。
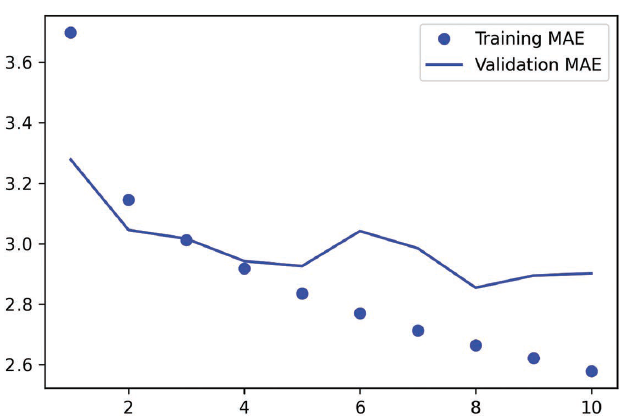
事实证明,这个模型的性能甚至比密集连接模型更差。它的验证MAE 约为2.9 摄氏度,比
基于常识的基准差很多。出了什么问题?有以下两个原因。
- 首先,天气数据并不完全遵循平移不变性假设。虽然数据具有每日周期性,但早晨的数
据与傍晚或午夜的数据具有不同的属性。天气数据只在某个时间尺度上具有平移不变性。 - 其次,数据的顺序很重要。要想预测第 2 天的温度,最新的数据比 5 天前的数据包含更
多的信息。一维卷积神经网络无法利用这一点。特别是,最大汇聚层和全局平均汇聚层
在很大程度上破坏了顺序信息。
第一个RNN 基准
全连接网络和卷积神经网络的效果都不是很好,但这并不意味着机器学习不适用于这个问
题。密集连接网络首先将时间序列展平,这从输入数据中去除了时间的概念。卷积神经网络对
每段数据都用同样的方式处理,甚至还应用了汇聚运算,这会破坏顺序信息。我们来看一下数
据本来的样子:它是一个序列,其中因果关系和顺序都很重要。
有一类专门处理这种数据的神经网络架构,那就是RNN,其中,长短期记忆(Long Short
Term Memory,LSTM)层长期以来一直很受欢迎。我们稍后会介绍这种模型的工作原理,但我
们先来试用一下LSTM 层,如代码清单10-12 所示。
代码清单10-12 基于LSTM 的简单模型
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(16)(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_lstm.keras")
print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")
如图10-5 所示,该模型的结果比之前的模型好多了!验证MAE 低至2.36 摄氏度,测试MAE
为2.55 摄氏度。基于LSTM 的模型终于超越了基于常识的基准(尽管目前只超越了一点点),
这证明了机器学习在这项任务上的价值。
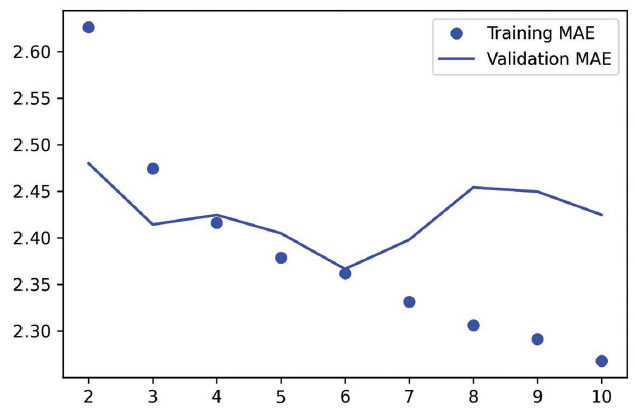
为什么LSTM 模型的性能明显好于密集连接网络或卷积神经网络呢?我们又该如何进一步
完善该模型呢?为了回答这些问题,我们来仔细看一下RNN。
完整代码
import os
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 1. 下载数据
#!wget https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip
#!unzip jena_climate_2009_2016.csv.zip
# 加载和查看数据
# 获取项目根目录路径
project_root = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
fname=os.path.join(project_root, "jena_climate_2009_2016.csv")
with open(fname) as f:
data=f.read()
lines=data.split("\n")
header=lines[0].split(",")
lines=lines[1:]
# 移除空行
lines = [line for line in lines if line.strip()]
print("表头:",header)
print("数据行数:",len(lines))
# 解析数据
raw_data=np.zeros((len(lines),len(header)-1))
temperature=np.zeros((len(lines),))
for i,line in enumerate(lines):
values = line.split(",")
# 跳过空值或无效行
if len(values) < len(header):
continue
# 解析数值数据,跳过第一列(日期时间)
numeric_values = []
for j in range(1, len(header)):
try:
numeric_values.append(float(values[j]))
except ValueError:
numeric_values.append(0.0) # 如果转换失败,使用默认值
raw_data[i,:]=numeric_values
temperature[i]=numeric_values[1] # 温度是第2列(索引1)
print("数据形状:",raw_data.shape)
print("温度数据形状:",temperature.shape)
# 绘制温度时间系列
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(range(len(temperature)),temperature)
plt.title("整个时间范围内的温度")
plt.xlabel('时间点')
plt.ylabel('温度')
plt.subplot(1,2,2)
plt.plot(range(1440),temperature[:1440])
plt.title("前10天的温度")
plt.xlabel('时间点 (10分钟间隔)')
plt.ylabel('温度 (摄氏度)')
plt.tight_layout()
plt.show()
# 划分训练、验证和测试集
num_train_samples=int(0.5*len(raw_data))
num_val_samples=int(0.25*len(raw_data))
num_test_samples=len(raw_data)-num_train_samples-num_val_samples
print(f"总样本数: {len(raw_data)}")
print(f"训练样本数: {num_train_samples}")
print(f"验证样本数: {num_val_samples}")
print(f"测试样本数: {num_test_samples}")
# 数据规范化
mean=raw_data[:num_train_samples].mean(axis=0)
raw_data-=mean
std=raw_data[:num_train_samples].std(axis=0)
raw_data/=std
# 创建数据集
sampling_rate=6
sequence_length=120
delay=sampling_rate*(sequence_length+24-1)
batch_size=256
print(f"Delay: {delay}")
# 保证有足够的数据用于创建时间序列
min_required_length = delay + sequence_length
if len(raw_data) < min_required_length:
raise ValueError(f"数据长度不足。至少需要 {min_required_length} 个样本,但只有 {len(raw_data)} 个。")
# 重新计算划分点,确保不超出范围
train_end_index = num_train_samples - delay - 1
val_start_index = num_train_samples
val_end_index = num_train_samples + num_val_samples - delay - 1
test_start_index = num_train_samples + num_val_samples
test_end_index = len(raw_data) - delay - 1
# 确保索引有效
train_end_index = max(0, min(train_end_index, len(raw_data) - delay - 1))
val_end_index = max(val_start_index, min(val_end_index, len(raw_data) - delay - 1))
test_end_index = max(test_start_index, min(test_end_index, len(raw_data) - delay - 1))
print(f"训练集索引范围: 0 到 {train_end_index}")
print(f"验证集索引范围: {val_start_index} 到 {val_end_index}")
print(f"测试集索引范围: {test_start_index} 到 {test_end_index}")
train_dataset=keras.utils.timeseries_dataset_from_array(
raw_data,
targets=temperature,
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=0,
end_index=train_end_index
)
val_dataset=keras.utils.timeseries_dataset_from_array(
raw_data,
targets=temperature,
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=val_start_index,
end_index=val_end_index
)
test_dataset=keras.utils.timeseries_dataset_from_array(
raw_data,
targets=temperature,
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=test_start_index,
end_index=test_end_index
)
# 查看数据集形状
for samples,targets in train_dataset:
print("样本形状:",samples.shape)
print("目标形状:",targets.shape)
break
# 基于常识的基准方法
def evaluate_naive_method():
batch_maes=[]
for samples,targets in test_dataset:
preds=samples[:,-1,1]*std[1]+mean[1]
mae=np.mean(np.abs(preds-targets))
batch_maes.append(mae)
print(np.mean(batch_maes))
print("基于尝试基准的测试MAE:")
evaluate_naive_method()
# 密集连接模型
def build_and_train_dense_model():
inputs=keras.Input(shape=(sequence_length,raw_data.shape[-1]))
x=layers.Flatten()(inputs)
x=layers.Dense(16,activation="relu")(x)
outputs=layers.Dense(1)(x)
model=keras.Model(inputs,outputs)
model.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])
callbacks=[
keras.callbacks.ModelCheckpoint("jena_dense.keras",save_best_only=True)
]
history=model.fit(
train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks
)
# 加载最佳模型并评估
model=keras.models.load_model("jena_dense.keras")
test_mse,test_mae=model.evaluate(test_dataset)
print(f"密集连接模型测试MAE:{test_mae:.2f}")
# 绘制训练曲线
plt.figure(figsize=(8,5))
loss=history.history["mae"]
val_loss=history.history["val_mae"]
epochs=range(1,len(loss)+1)
plt.plot(epochs,loss,"bo",label="训练MAE")
plt.plot(epochs,val_loss,"b",label="验证MAE")
plt.title("密集连接网络 - 训练和验证MAE")
plt.legend()
plt.show()
return history
print("\n训练密集连接模型:")
dense_history=build_and_train_dense_model()
# 一堆卷积模型
def build_and_train_conv1d_model():
inputs=keras.Input(shape=(sequence_length,raw_data.shape[-1]))
x=layers.Conv1D(8,24,activation="relu")(inputs)
x=layers.MaxPooling1D(2)(x)
x=layers.Conv1D(8,12,activation="relu")(x)
x=layers.MaxPooling1D(2)(x)
x=layers.Conv1D(8,6,activation="relu")(x)
x=layers.GlobalAveragePooling1D()(x)
outputs=layers.Dense(1)(x)
model=keras.Model(inputs,outputs)
callbacks=[
keras.callbacks.ModelCheckpoint("jena_conv.keras",save_best_only=True)
]
model.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])
history=model.fit(
train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks
)
model=keras.models.load_model("jena_conv.keras")
test_mse,test_mae=model.evaluate(test_dataset)
print(f"一堆卷积模型测试MAE:{test_mae:.2f}")
# 绘制训练曲线
plt.figure(figsize=(8,5))
loss=history.history["mae"]
val_loss=history.history["val_mae"]
epochs=range(1,len(loss)+1)
plt.plot(epochs,loss,"bo",label="训练MAE")
plt.plot(epochs,val_loss,"b",label="验证MAE")
plt.title("一堆卷积网络 - 训练和验证MAE")
plt.xlabel("Epochs")
plt.ylabel("MAE")
plt.legend()
plt.show()
return history
print("\n训练一堆卷积模型")
conv_history=build_and_train_conv1d_model()
# LSTM模型
def build_and_train_lstm_model():
inputs=keras.Input(shape=(sequence_length,raw_data.shape[-1]))
x=layers.LSTM(16)(inputs)
outputs=layers.Dense(1)(x)
model=keras.Model(inputs,outputs)
callbacks=[
keras.callbacks.ModelCheckpoint("jena_lstm.keras",save_best_only=True)
]
model.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])
history=model.fit(
train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks
)
model=keras.models.load_model("jena_lstm.keras")
test_mse,test_mae=model.evaluate(test_dataset)
print(f"LSTM模型测试MAE:{test_mae:.2f}")
# 绘制训练曲线
plt.figure(figsize=(8,5))
loss=history.history["mae"]
val_loss=history.history["val_mae"]
epochs=range(1,len(loss)+1)
plt.plot(epochs,loss,"bo",label="训练MAE")
plt.plot(epochs,val_loss,"b",label="验证MAE")
plt.title("LSTM网络 - 训练和验证MAE")
plt.xlabel("Epochs")
plt.ylabel("MAE")
plt.legend()
plt.show()
return history
print("\n训练LSTM模型:")
lstm_history=build_and_train_lstm_model()
# 比较所有模型性能
print("\n=== 模型性能比较 ===")
print("基于常识基准: ~2.62°C")
print("密集连接模型: 需要查看具体输出")
print("一维卷积模型: 需要查看具体输出")
print("LSTM模型: 需要查看具体输出")
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)