
原创!二次分解+深度学习!ICEEMDAN-Kmeans-VMD-CPO-CNN-BiLSTM一键实现多变量时序预测!
今天给大家带来一期绝对创新且工作量足够的代码,以往的分解大多只进行一次,对于高频项的挖掘不够充分,导致其预测精度较低。况且,目前的分解方法大多已经入不了审稿人的法眼,如果没有进一步的创新,很容易被拒稿。
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
今天给大家带来一期绝对创新且工作量足够的代码,以往的分解大多只进行一次,对于高频项的挖掘不够充分,导致其预测精度较低。况且,目前的分解方法大多已经入不了审稿人的法眼,如果没有进一步的创新,很容易被拒稿。
因此,今天给小伙伴带来一期二次分解+优化算法+深度学习的创新代码,其中的优化算法也可以任意替换!
当然,我们提出的这个模型,非常适合用来发文!目前,知网和WOS上都还没人用过!不信的小伙伴可以看下面截图:
知网:
WOS:
你先用,你就是创新!
您只需做的工作:替换自己的数据,运行main文件即可!非常适合新手小白!
数据输入方法
本期代码采用的案例数据是某地光伏功率数据,在实际处理时,由于光伏白天不发电,因此作者把功率为0的行都删除了!同时,由于时间关系,作者这边只选取了2022年1月份31天的功率数据进行预测,如图所示。
特征包括气温, 方位角, 云层不透明度, 露点温度, DHI(太阳散射辐射指数), DNI(太阳直接辐射指数), GHI(太阳总水平辐射), GTI(固定倾角辐射), GTI(跟踪倾角辐射), 大气可降水量, 相对湿度, 降雪深度, 地面气压, 高度10m风向, 高度10m风速, 天顶角,输出即为实际功率一列。
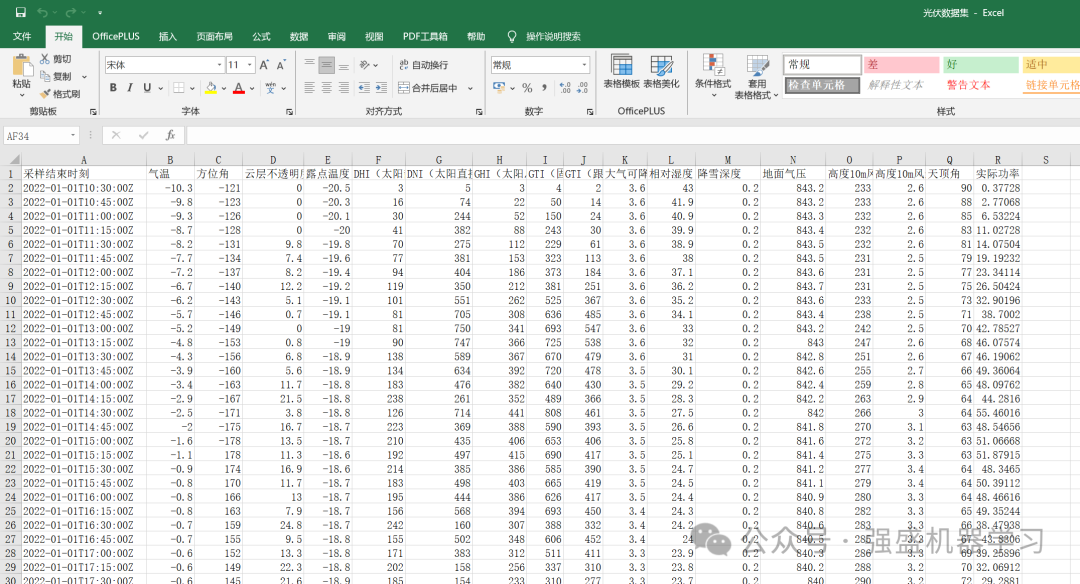
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可,特征数量不限,无需更改代码,非常方便!
模型原理与流程
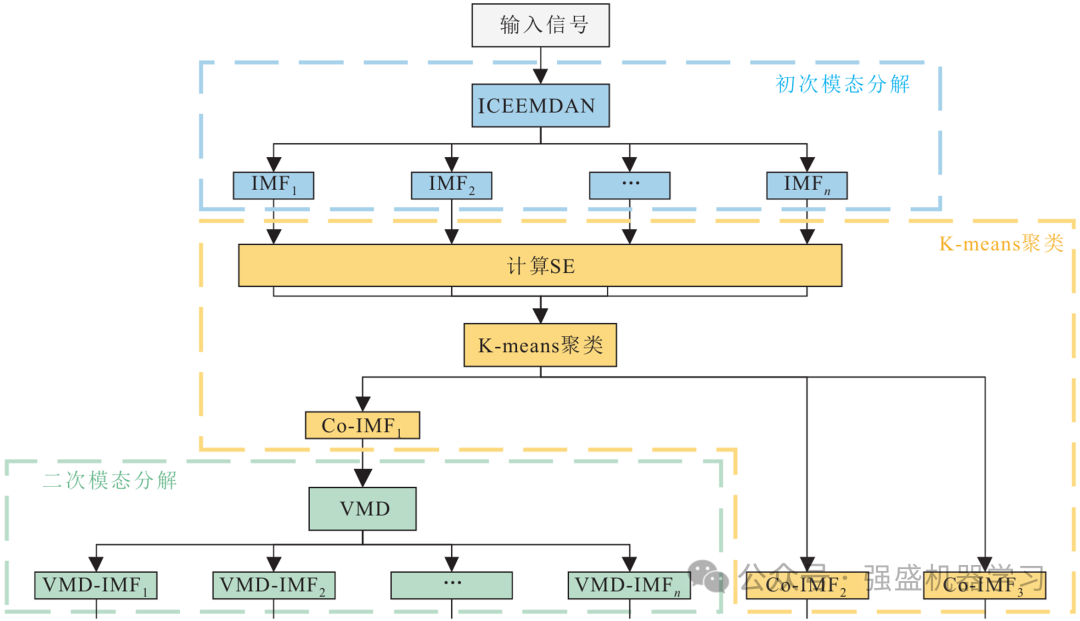
简单来说,我们首先利用ICEEMDAN先进行第一次分解,再利用Kmeans聚类和VMD分解方法进行第二次分解,最后融合得到的分量,利用CPO优化后的CNN-BiLSTM深度学习模型对每个分量进行预测,最后相加得到预测结果!
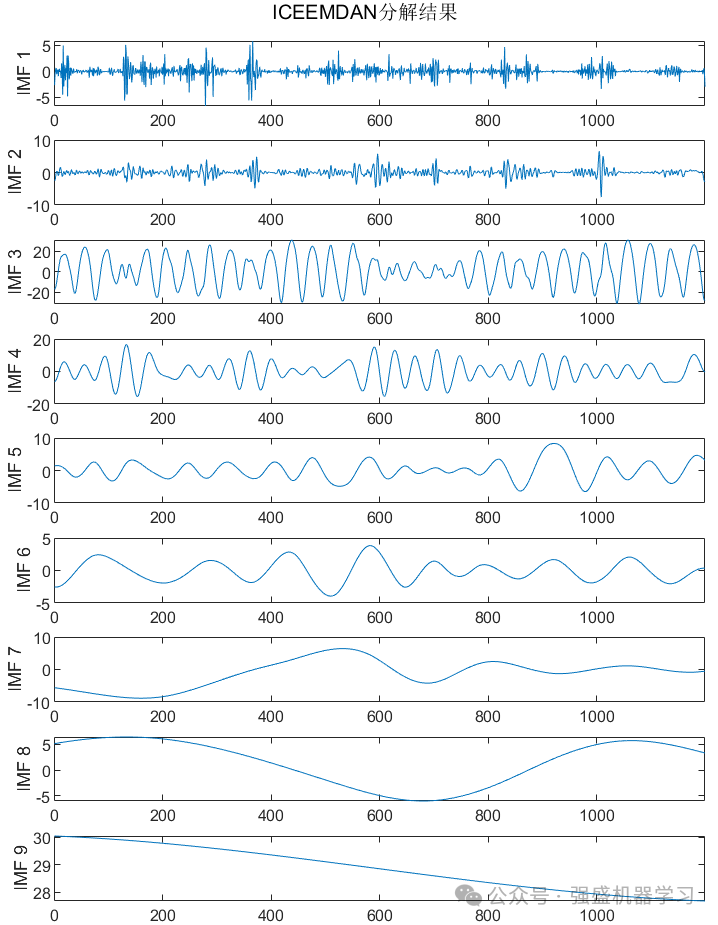
1)初次模态分解:通过ICEEMDAN算法将输入时间序列分解为若干IMF分量,初步降低原始时间序列的复杂度。
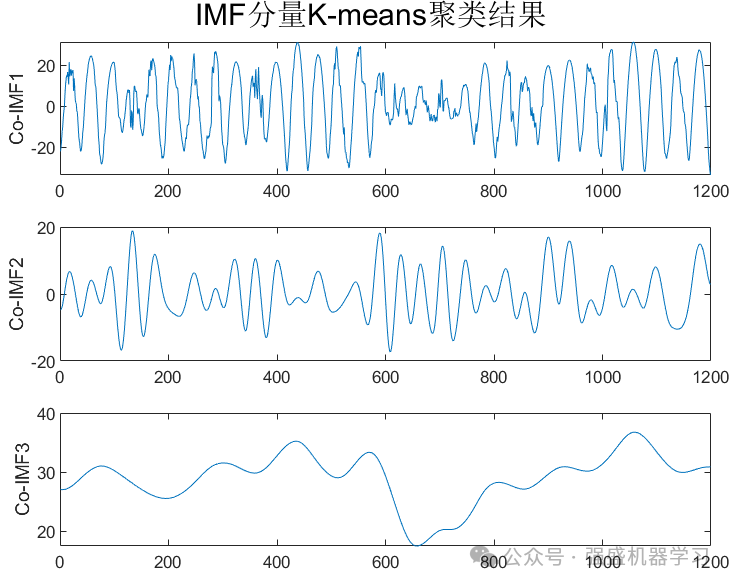
2)K-means聚类:计算步骤1)得到的若干IMF分量的样本熵,并根据各样本熵值的大小将所有的IMF分量通过K-means聚类为高频、中频和低频3个IMF时间子序列。
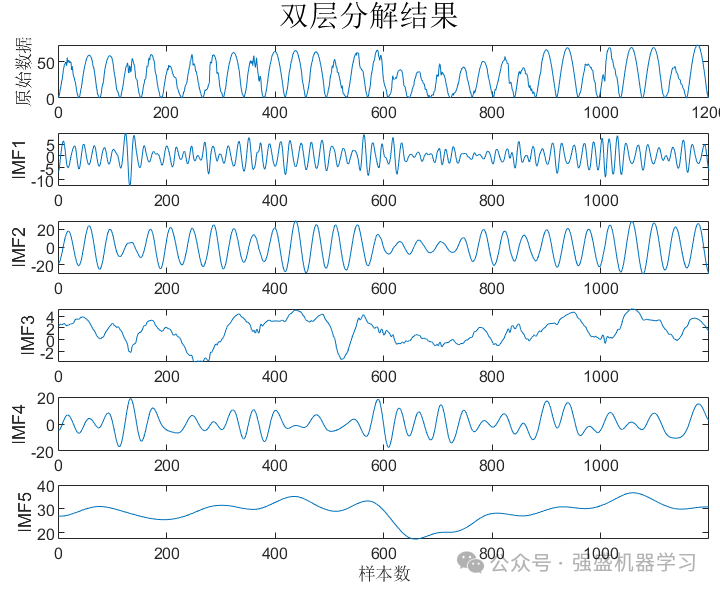
3)二次模态分解:将步骤2)中的高频时间序列进行VMD二次模态分解,降低高频IMF分量的复杂度,并将VMD分解的IMF与CEEMDAN算法分解得到的中、低频时间序列组成新的IMF分量集合。
4)CPO算法优化:将各IMF分量分别输入到CPO优化算法中,分别得出最优的L2正则化系数、初始学习率、隐藏层节点数三个CNN-BiLSTM超参数组合。
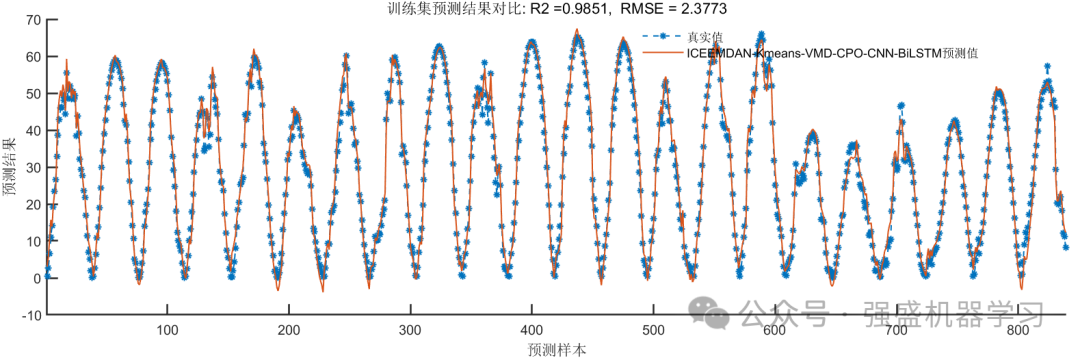
5)CNN-BiLSTM模型训练与预测:将步骤4)得到的最优超参数分别代入CNN-BiLSTM模型中进行训练预测,并将各预测结果融合为最终的预测结果。
创新点
①创新点一:最新优化算法自动参数调优
冠豪猪优化算法(CPO)于2024年发表在中科院1区顶级SCI期刊《Knowledge-Based Systems》上!实验结果表明,CPO算法在大部分函数上均取得了最优结果!性能非常不错,解决了CNN-BiLSTM模型参数难以人工准确设定的问题!之前推文有做过CPO和23年新算法RIME的比较,效果显而易见!链接如下:
2024年新算法-冠豪猪优化算法(CPO)-公式原理详解与性能测评 附赠Matlab代码
②创新点二:熵值引导的K-means聚类
利用样本熵对IMF分量进行特征刻画,并以此为依据进行K-means聚类,解决了以往凭经验人工选取IMF分量类别的盲目性,提升了聚类结果的客观性与准确性。
③创新点三:多尺度预测融合
模型采用多IMF分量分别建模预测后再叠加,充分发挥了多尺度信息融合的优势,整体预测性能得到显著提高,避免了单一尺度预测的不足。
实验结果展示
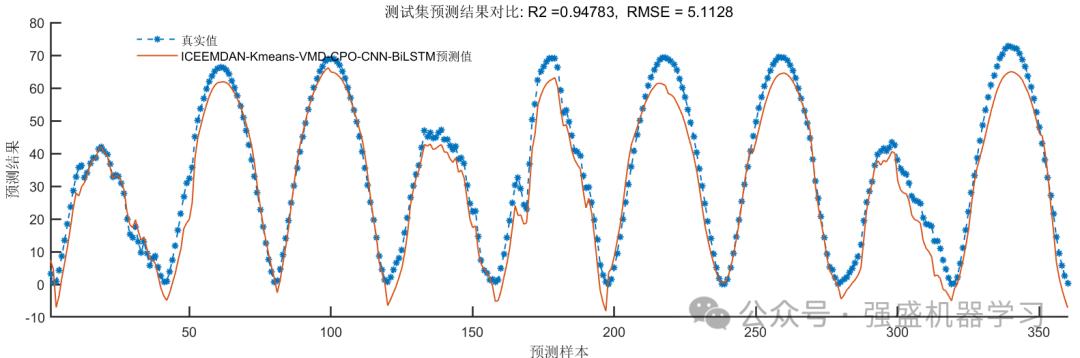
利用刚刚的光伏数据集,得到的预测结果如下所示(由于ICEEMDAN、优化算法、Kmeans算法均具有随机性,因此每次运行结果会略有不同,属于正常现象):
ICEEMDAN分解图:
Kmeans聚类后的结果,分为高频/中频/低频分量:
合并VMD分解高频分量与Co_IMF2;Co_IMF3分量:
预测结果图:
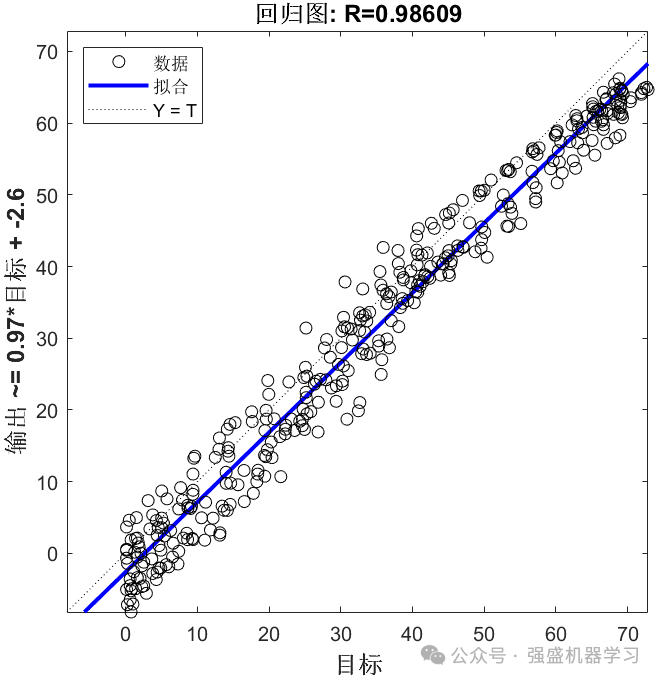
回归拟合图:
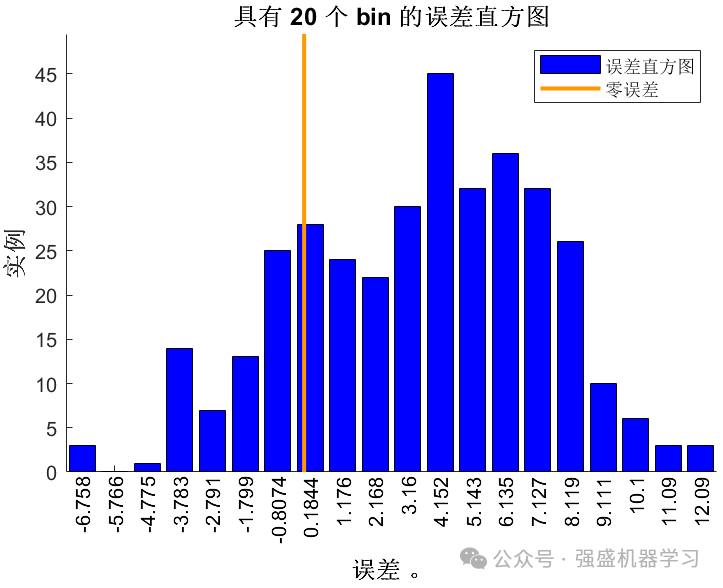
误差直方图:
文件夹内也非常清晰,没有什么乱七八糟的文件!
以上所有图片,替换Excel后均可一键运行main生成,Matlab无需配置环境!比Python什么方便多了!非常适合新手小白!
完整代码获取
如果需要以上完整代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
二次分解
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)