
毕业设计:基于知识图谱的电影推荐问答系统
毕业设计:基于知识图谱电影推荐问答系统结合了深度学习和自然语言处理技术,利用电影知识图谱构建和语义推理,为用户提供个性化、智能化的电影推荐服务。我们通过构建丰富的电影知识图谱,将电影信息进行结构化表示,并应用深度学习算法对用户问题进行语义理解和知识推理。为计算机毕业设计提供了一个创新的方向,结合了深度学习和自然语言处理技术,为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于知识图谱电影推荐问答系统
课题背景和意义
电影推荐系统在当前的娱乐和文化产业中扮演着重要角色。然而,传统的电影推荐系统主要基于用户的历史行为和电影元数据,往往无法准确地理解用户的需求和偏好。而基于知识图谱的电影推荐问答系统能够利用结构化的电影知识图谱,结合深度学习和自然语言处理技术,实现对用户问题的语义理解和知识推理,从而为用户提供个性化、精准的电影推荐服务。这种系统不仅可以大大提高电影推荐的准确性和用户满意度,还有助于推动电影产业的创新和发展。
实现技术思路
一、算法技术理论
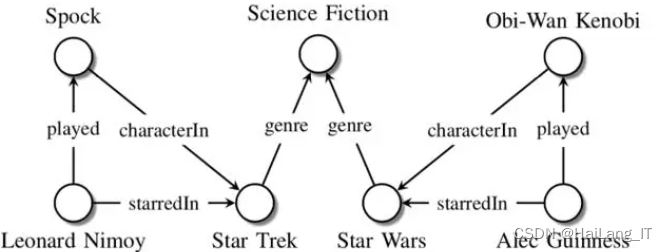
1.1 知识图谱
知识图谱是一种表示客观世界中各种实体、概念及其关联关系的知识库。本质上知识图谱不仅局限于某个公司,而是以类似于人类认知方式的形式呈现知识。它可以被视为一个庞大的语义网络,其中节点代表概念或实体,而边表示实体之间的关系。随着信息的爆炸性增长和互联网的发展,知识图谱的定义已经广义上指代各种大规模的知识库。
知识图谱由相互连接的实体及其属性组成,每个知识可以表示为SPO(主体-谓词-客体)三元组的形式。构建和应用大规模知识库需要多种技术支持,包括知识提取、知识表示、知识融合和知识推理等技术。知识提取技术用于从各种数据库中提取实体、关系和属性等知识要素。知识表示技术则用于对构成知识图谱的知识要素进行表示。知识融合的目的是消除歧义,生成高质量的知识库。知识推理则基于现有知识库深入挖掘潜在知识,得到更全面、有价值的知识库。
1.2 卷积神经网络
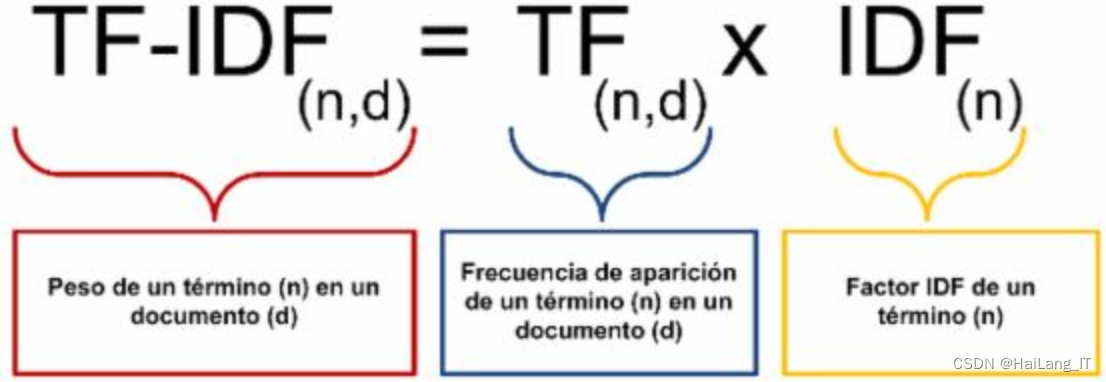
TF-IDF是一种常用的文本特征表示方法,通过考虑词频(TF)和逆文档频率(IDF)来衡量一个词对于文档集合中特定文档的重要程度。TF表示词在文档中的出现频率,IDF衡量词在整个文档集合中的普遍重要性。TF-IDF模型将TF和IDF相乘,得到词在文档中的重要性权重。该模型被广泛应用于文本挖掘、信息检索和文本分类等任务,可用于特征提取、相似度计算和关键词提取等应用场景。通过综合考虑词频和普遍重要性,TF-IDF模型能够准确地捕捉词语在文档中的重要性,帮助理解和分析文本数据。
朴素贝叶斯分类器是一种基于贝叶斯定理和特征条件独立性假设的分类方法。它通过计算给定特征条件下每个类别的后验概率来进行分类。具体而言,朴素贝叶斯分类器假设所有特征之间相互独立,然后根据训练数据中的特征和类别的统计信息计算先验概率和条件概率,最终通过比较后验概率确定样本的类别。该分类器简单高效,适用于文本分类、垃圾邮件过滤等应用场景。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建朴素贝叶斯分类器
model = GaussianNB()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)1.3 余弦相似度算法
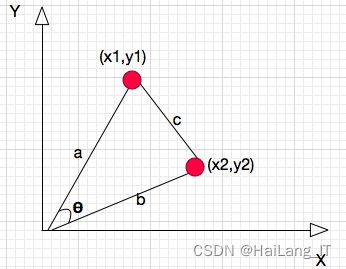
余弦相似度算法是一种常用的相似度度量方法,用于比较两个向量之间的相似程度。它基于向量的内积和向量的模长来计算两个向量之间的夹角余弦值。余弦相似度算法的计算过程如下:
- 将两个向量表示为特征空间中的向量。
- 计算两个向量的内积,即将两个向量对应位置的元素相乘并求和。
- 分别计算两个向量的模长,即将向量中每个元素的平方相加,并对结果进行开方。
- 将步骤2中的内积结果除以步骤3中计算的两个向量的模长的乘积。
- 得到的结果即为两个向量的余弦相似度值,值的范围在-1到1之间。值越接近1,表示两个向量越相似;值越接近-1,表示两个向量越不相似;值接近0表示两个向量之间没有明显的相似性。
二、 数据集
2.1 数据集
由于网络上没有现有的合适的电影推荐数据集,我决定自己去收集数据以支持基于知识图谱的电影推荐问答系统的研究。我收集了大量的电影信息,包括电影名称、演员、导演、类型、剧情简介等。通过对这些数据进行整理和标注,我得到了一个自制的电影知识图谱数据集。此外,我还从公开的电影评分网站获取了用户对电影的评分和评论数据,以了解用户的喜好和观影体验。通过自制的数据集,我能够构建一个全面、结构化的电影知识图谱,并为电影推荐问答系统提供准确、可靠的数据支持。
2.2 数据扩充
为了进一步提升基于知识图谱的电影推荐问答系统的性能和泛化能力,我计划对数据集进行扩充。首先,我将收集更多的电影信息,包括新上映的电影、经典的老电影以及各种类型的电影。这将使得知识图谱更加全面和丰富。其次,我还计划收集用户的实时反馈数据,包括用户的观影历史、评分和评论。这些反馈数据将有助于系统更好地理解用户的兴趣和偏好,提供更加个性化和精准的推荐。此外,我还将考虑引入其他数据源,如社交媒体数据和专家评价,以进一步丰富电影推荐的内容和多样性。
三、实验及结果分析
问答系统基于知识图谱,使用了MySQL和Neo4j数据库相结合的方式进行数据存储和查询。为了实现自然语言处理和人机器学习算法的设计,选择了Python语言,并借助PyCharm集成开发工具进行系统开发。通过这样的组合,系统能够有效地处理自然语言输入,从数据库中匹配相关知识,并利用机器学习算法提供准确的答案。Python和PyCharm的选择为系统开发提供了灵活性和便捷性,使得开发过程更加高效和可靠。总的来说,该问答系统利用MySQL、Neo4j、Python和PyCharm等技术工具的优势,实现了一个基于知识图谱的功能强大的问答系统。
相关代码示例:
from sklearn.feature_extraction.text import TfidfVectorizer
# 文本数据
documents = [
"I love programming and coding.",
"Natural language processing is interesting.",
"Machine learning is a subset of artificial intelligence.",
"Python is a popular programming language."
]
# 创建TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 对文本数据进行向量化处理
tfidf_matrix = vectorizer.fit_transform(documents)
# 获取特征词列表
feature_names = vectorizer.get_feature_names()
# 打印每个文本的关键词和对应的TF-IDF值
for i in range(len(documents)):
doc_features = tfidf_matrix[i]
print("Document", i+1, "Keywords:")
for j in doc_features.nonzero()[1]:
print(feature_names[j], ":", doc_features[0, j])
print("-------------------------------------")最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
更多推荐
 29
29 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)