
【深度学习】Heterogeneous Graph Transformer (HGT)
Heterogeneous Graph Transformer (HGT) 是一种针对异构图的图神经网络模型,由Ziniu Hu等人在NeurIPS 2020提出。它通过类型感知的Transformer机制解决异构图中节点/边类型不一致的问题,为不同类型节点和边设计独立投影矩阵,利用多头注意力实现跨类型信息传递。相比GAT、HAN等模型,HGT能更好地建模类型语义差异,支持动态边权重学习,适用于学
Heterogeneous Graph Transformer (HGT) 是一种专为 异构图(heterogeneous graph) 设计的图神经网络模型,由 Ziniu Hu 等人 在 NeurIPS 2020 论文《Heterogeneous Graph Transformer》提出。
它旨在解决以下两个核心问题:
-
✅ 节点类型和边类型不一致(异构图中的常见问题);
-
✅ 信息传递需要考虑类型间的语义差异和方向性。
📌 一、背景与动机
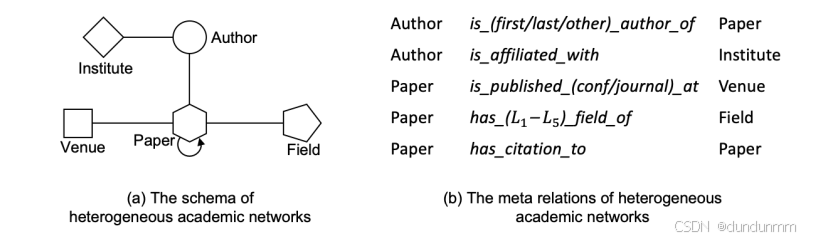
在异构图中,存在多种类型的节点和多种类型的边,例如学术网络中的:
-
节点类型:论文(Paper)、作者(Author)、机构(Institution)
-
边类型:作者-写-论文、论文-发表-会议、作者-属于-机构
🔺 挑战:
-
不同类型的邻居不能一视同仁;
-
不同类型的边语义不同,不能共享相同的聚合/更新方式;
-
图神经网络(GCN/GAT)无法直接迁移到异构图上。
🌟 二、HGT 核心思想
HGT 将异构图建模为一个多类型的图结构,并通过 类型感知的 Transformer 注意力机制 实现消息传递和节点表示更新。
核心包含:
| 模块 | 说明 |
|---|---|
| 节点类型编码(Node-type-specific projection) | 每种类型的节点拥有独立投影矩阵 |
| 边类型编码(Edge-type-specific transformation) | 每种边类型控制消息传递的方向与语义变换 |
| 时间编码(可选) | 用于处理动态图 |
| 多头注意力机制(Multi-head Attention) | 实现跨类型注意力聚合 |
🧠 三、HGT 模型结构详解
假设一个异构图 $\mathcal{G} = (\mathcal{V}, \mathcal{E})$,其中每个节点 $v \in \mathcal{V}$ 有类型 $\tau(v)$,每条边 $(u \xrightarrow{r} v)$ 有边类型 $r$。
Step 1:类型感知投影
每种节点类型 $t$ 对应一个输入投影矩阵 $W^t$,将初始表示 $h_v$ 映射到 Transformer 空间:
hv′=Wτ(v)
Step 2:边类型控制的注意力计算(Edge-specific attention)
边 $(u \xrightarrow{r} v)$ 上的注意力机制为:
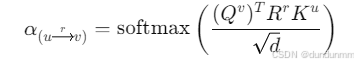
-
$Q^v$ 是目标节点 $v$ 的查询向量
-
$K^u$ 是源节点 $u$ 的键向量
-
$R^r$ 是边类型 $r$ 对应的可学习矩阵
-
支持 多头注意力
Step 3:边类型控制的消息变换
每条边类型 $r$ 有独立的消息变换矩阵 $T^r$:
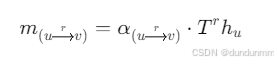
Step 4:聚合邻居信息,更新节点表示
对所有连接到节点 $v$ 的边进行聚合,最终更新表示:
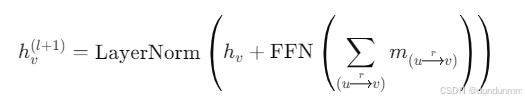
🔧 四、HGT 的特性与优势
| 特性 | 描述 |
|---|---|
| ✅ 类型感知投影 | 为不同节点/边类型设置独立的变换矩阵 |
| ✅ 多头注意力 | 学习类型间的重要性差异 |
| ✅ 动态边权重 | 基于结构与类型自动学习邻居重要性 |
| ✅ 可扩展 | 适用于大规模异构图(论文使用了 mini-batch + neighbor sampling) |
🔬 五、与其他模型对比(HGT vs GAT vs HAN vs GTN)
| 模型 | 节点类型建模 | 边类型建模 | 路径学习 | 基于注意力 |
|---|---|---|---|---|
| GAT | ❌ 同构图 | ❌ 无区分 | ❌ 无 | ✅ |
| HAN | ✅ 有 | ❌ 固定路径 | ✅ 人工路径 | ✅(两个层次) |
| GTN | ❌ | ✅ 自动组合 | ✅ 自动组合 | ❌(卷积选择) |
| HGT | ✅ 类型投影 | ✅ 边变换 | ✅ 多跳隐式 | ✅ 多头注意力 |
📈 六、应用场景
-
学术图谱(MAG)
-
知识图谱补全
-
推荐系统
-
企业图、金融欺诈检测
-
社交网络用户建模
📘 七、原始论文
-
Title: Heterogeneous Graph Transformer
-
Authors: Ziniu Hu, Yuxiao Dong, Kuansan Wang, Yizhou Sun
-
Conference: NeurIPS 2020
📊 八、可视化结构图(简略)
graph TD
A[节点 v(目标节点)] -->|边类型 r1| B1[邻居 u1]
A -->|边类型 r2| B2[邻居 u2]
A -->|边类型 r3| B3[邻居 u3]
B1 --> C[类型注意力 + 消息投影]
B2 --> C
B3 --> C
C --> D[聚合 + 更新 h_v]
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)