
机器学习048:深度学习【经典神经网络】门控循环单元(GRU)-- 像人类一样学会“忘记”与“记住”的智能网络
摘要: 门控循环单元(GRU)是循环神经网络(RNN)的高效改进版,擅长处理时序数据(如语音、文本)。它通过更新门和重置门动态管理记忆,选择性地保留重要信息,解决了传统RNN的长程依赖问题。GRU结构比LSTM更简洁,训练更快,适用于机器翻译、语音识别、股票预测等任务,但在超长序列和并行计算上仍有局限。实际应用中,GRU已用于智能输入法、同声传译和视频分析等领域。示例代码展示了如何用PyTorch
想象一下,你正在看一部悬疑电影,为了理解剧情,你需要记住之前的关键线索(比如“凶手左撇子”),同时也要忘掉一些无关的细节(比如“主角早餐吃了什么”)。这种“选择性记忆”的能力,正是我们今天要认识的明星——门控循环单元(GRU) 所擅长的。
它就像一个更聪明、更高效的“记忆大师”,专门处理像语音、文字、股票价格这类按时间顺序发生的数据。下面,就让我们一起揭开GRU的神秘面纱,看看它是如何工作的,又能为我们的生活带来哪些改变。
一、 分类归属:GRU从何而来?
在我们开始具体了解GRU之前,先帮它找到在AI大家族里的“座位”。
- 从网络结构看:GRU属于循环神经网络(RNN) 这个大家庭中的一个重要改进型成员。你可以把RNN想象成一条“记忆项链”,信息像珠子一样按顺序穿过去,每个珠子(网络节点)都会接收新信息并结合之前的记忆。
- 从功能用途看:它是专门为处理序列数据而生的“时序模型专家”。什么是序列数据呢?就是那些顺序很重要的信息,比如一句话里的单词、一段音乐里的音符、一个月里每天的天气。
- 提出的背景:GRU由Cho等人在2014年提出。它的诞生是为了解决传统RNN的一个大麻烦:记不住太长的信息。比如,读一篇长篇小说,读到后面可能就忘了开头的人物关系。更早的改进版LSTM(长短期记忆网络)虽然解决了这个问题,但结构有点复杂。于是,GRU作为一个更简洁、训练更快的“LSTM简化高效版”被设计出来,效果却不相上下。
简单来说,GRU是一个结构更精巧、训练更高效的循环神经网络,专门用来理解和预测有时序关系的信息。
二、 底层原理:GRU的“记忆管理术”
理解GRU,核心是理解它的“门控机制”。别被这个词吓到,我们可以用一个非常生活化的场景来类比:管理你自己的手机相册。
你的手机相册就像GRU的“记忆单元”。每天你都会拍新照片(输入新信息),但手机内存有限,你必须决定:
- 记住哪些新照片?(哪些新信息是重要的?)
- 忘掉哪些旧照片?(哪些旧记忆可以清空了?)
- 最终保留下什么样的记忆?(结合新旧信息后的新记忆是什么?)
GRU通过两个智能的“门”来自动完成这个决策过程:
1. 核心设计:两个智能门卫
GRU只有两个门,比它的前辈LSTM(三个门)更简洁。
-
更新门:决定“记忆更新程度”的总指挥
- 通俗解释:这个门像一个“融合比例调节器”。它看当前的新照片(新输入)和旧相册(旧记忆),然后决定:新照片要融入多少进旧相册,同时旧相册要保留多少。它输出一个0到1之间的数。如果接近1,意味着“多用旧记忆,少用新信息”;如果接近0,则意味着“多用新信息,重置旧记忆”。
- 作用:它巧妙地同时决定了“忘记多少”和“记住多少”,一举两得。
-
重置门:决定“忽略多少过去”的筛选员
- 通俗解释:这个门在看新照片时,会先回头检查一下旧相册。它决定:在理解这张新照片时,过去的哪些记忆是相关的、哪些是无关可以暂时忽略的? 比如,你今天在公园拍照(新信息),重置门可能会让你更多联想到旧相册里“户外”、“自然”相关的照片,而暂时忽略“办公室”、“会议”相关的照片。
- 作用:它筛选旧记忆,帮助网络更好地结合新旧信息来理解当前情况。
2. 信息传递方式:单向接力赛
标准的GRU是单向的,信息像接力棒一样,从序列的开头(比如一句话的第一个词)一步一步传递到结尾(最后一个词)。每一步,它都结合当前的新输入和上一步传来的记忆,形成新的记忆,再传给下一步。当然,也有双向GRU,可以同时从前向后和从后向前看,获得更全面的理解,就像两个人从一本书的开头和结尾一起读。
3. 训练的核心逻辑:学会“重要性判断”
GRU是如何学会管理记忆的呢?通过大量的数据训练。
我们给它看成千上万个句子(数据),并告诉它每个句子下一个词应该是什么(监督信号)。一开始,它的两个“门”乱决策。但通过一种叫反向传播的算法,网络会发现:“哦,上次我因为没记住主语,导致预测错了动词。下次遇到主语信息时,我的更新门应该把它牢牢记住。”就这样,通过无数次微调两个门内部的“判断标准”(即网络参数),GRU最终学会了自动判断序列中哪些信息关键、哪些可以淡化。
4. 原理图示与公式
我们可以用下面的流程图直观地看GRU在每一步是如何工作的: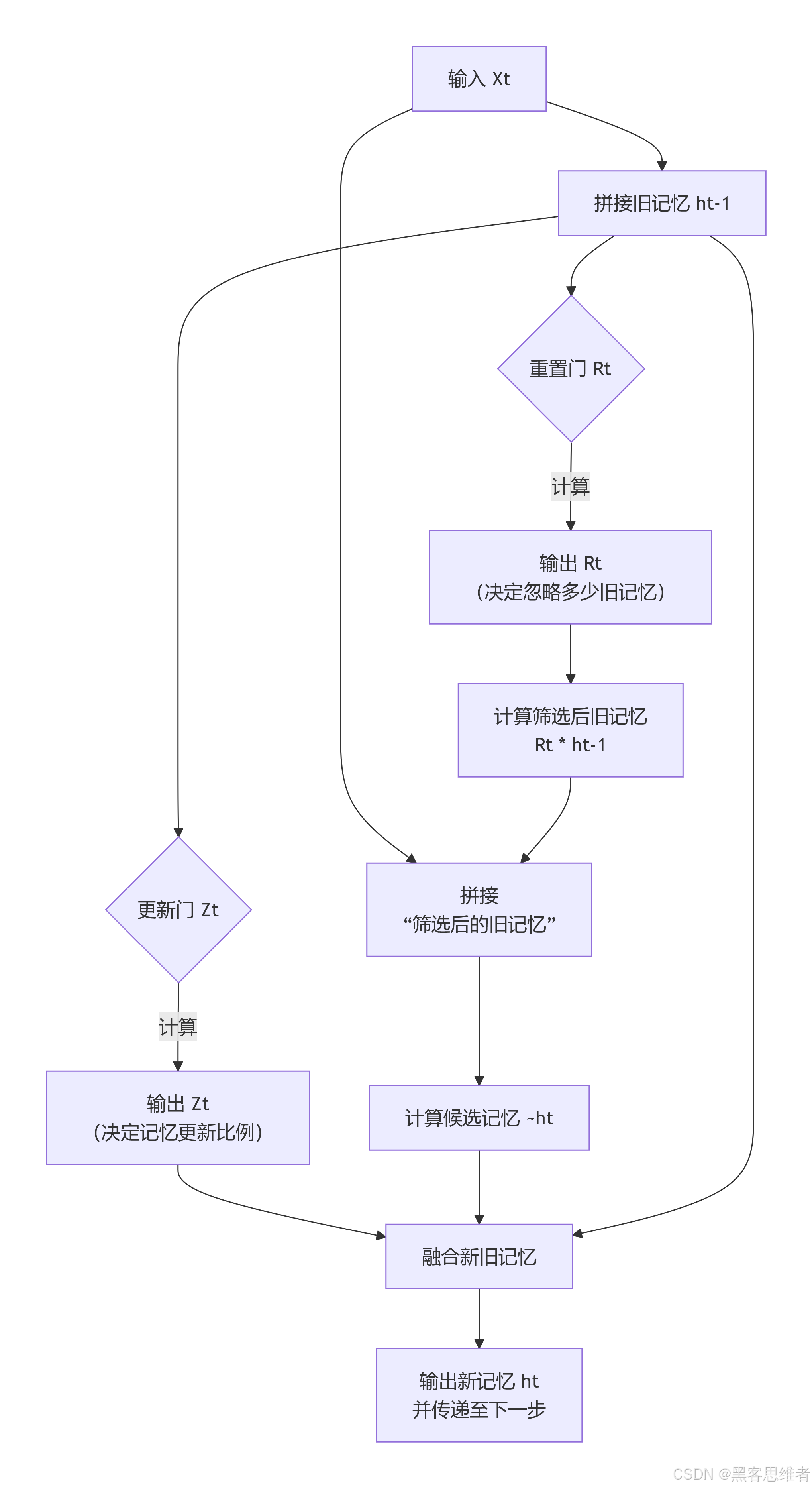
对应的核心公式(了解即可):
虽然我们用文字描述了逻辑,但公式是精确的数学表达。你不需要会计算,只需感受其对应关系:
- 重置门:
Rt = σ(Wr * [ht-1, Xt] + br)σ是Sigmoid函数,能把值压到0-1之间,代表“开合程度”。Wr和br是网络要学习的参数,可以理解为“判断规则”。[ht-1, Xt]表示把旧记忆和当前输入拼接在一起。
- 更新门:
Zt = σ(Wz * [ht-1, Xt] + bz) - 候选记忆:
~ht = tanh(Wh * [Rt * ht-1, Xt] + bh)Rt * ht-1就是被重置门筛选后的旧记忆。tanh是另一个激活函数,让值在-1到1之间,帮助稳定网络。
- 最终记忆(输出):
ht = (1 - Zt) * ht-1 + Zt * ~ht- 这是最精妙的一步!
(1 - Zt)和Zt是互补的。更新门Zt直接控制了新旧记忆的融合比例。
- 这是最精妙的一步!
三、 局限性:GRU并非万能
尽管GRU很强大,但它也有自己的“能力边界”。了解这些,能帮助我们更好地使用它。
-
处理超长序列仍可能“力不从心”
- 问题:虽然GRU通过门控机制很大程度上缓解了传统RNN的“梯度消失”(可以理解为记忆随着步骤增多而严重衰减)问题,但当面对极其长的序列(比如一本几百页的书、长达数小时的音频)时,它仍然可能难以捕捉到非常遥远步骤之间的依赖关系。
- 为什么:信息在一步步传递中,即使有门控保护,也难免会有衰减。门控机制更像是“减缓了遗忘的速度”,而非“永不遗忘”。
- 解决方案:对于超长序列,可以结合注意力机制(让网络学会在需要时直接“回顾”序列中任何位置的信息),或者使用更更新的Transformer架构。
-
顺序计算的“速度瓶颈”
- 问题:GRU必须像串珠子一样,一步一步处理序列。这导致它无法进行并行计算,训练速度比可以并行处理的CNN或Transformer慢,尤其当序列很长时。
- 为什么:因为第2步的计算必须等第1步完成,依赖性强。
- 解决方案:在实际中,可以通过“批次训练”等技巧部分优化,但根本性的顺序依赖无法改变。
-
对空间结构信息不敏感
- 问题:GRU是时序专家,但对像图片中像素之间的二维空间关系、社交网络中人物之间的连接关系等,并不擅长直接处理。
- 为什么:它的设计初衷就是处理一维的、有前后关系的数据流。
- 解决方案:处理图像通常用CNN,处理图数据用GNN(图神经网络)。有时会将它们与GRU结合,比如先用CNN从视频每一帧提取特征,再用GRU理解帧与帧之间的时序变化。
四、 使用范围:何时该请GRU出马?
总结一下,GRU是一位特定的专家,请根据“病情”下“处方”。
-
适合GRU解决的问题(核心适用场景):
- 自然语言处理任务:机器翻译、文本生成、情感分析、问答系统。因为语言天生就是顺序的。
- 语音处理任务:语音识别、语音合成。声音信号是随时间变化的波形。
- 时间序列预测:股票价格预测、天气预测、电力负荷预测、产品销售预测。这些数据都是按时间点记录的。
- 视频分析:理解视频中动作的连续性(通常结合CNN使用)。
-
不适合用GRU解决的问题:
- 单张图像分类识别(如猫狗识别):请找卷积神经网络(CNN)。
- 非序列的结构化数据预测(如根据身高、体重、年龄预测患病风险):请找全连接神经网络或树模型(如XGBoost)。
- 需要处理全局依赖的超长文本(如整篇文档的摘要):可以考虑 Transformer(如BERT)。
- 处理图结构数据(如社交网络推荐、分子结构分析):请找图神经网络(GNN)。
五、 应用场景:GRU在我们身边
理论说了这么多,GRU到底在哪里默默为我们服务呢?
-
智能输入法与聊天机器人(文本生成与预测)
- 作用:当你用手机打字时,输入法能智能预测你下一个想打的词(“你好,今天天_” -> “气”)。聊天机器人能生成连贯的回复。这背后通常是GRU(或LSTM)在工作,它根据你已经输入的文字序列,学习语言规律,预测出概率最高的下一个词或生成整句回复。
-
同声传译与会议转录(机器翻译与语音识别)
- 作用:在国际会议或看外语视频时,实时显示翻译字幕。系统首先用GRU处理音频序列,将其转化为文字(语音识别),然后再用另一个GRU(或Transformer)将一种语言的文字序列转换为另一种语言的文字序列(机器翻译)。GRU在这里完美地建模了语言和语音的时序特性。
-
股票趋势分析与预警(金融时间序列预测)
- 作用:金融机构利用GRU分析股票历史的价格、成交量等按时间排列的数据序列,试图找出模式,对未来短期的价格走势进行预测或进行风险评估。GRU的门控机制能帮助它判断哪些历史信息(如一周前的暴跌)对当前预测更重要,哪些噪音可以忽略。
-
智能家居与能耗管理(物联网传感器数据分析)
- 作用:家里的智能温控系统通过学习你过去一段时间内调节温度的时序习惯(比如晚上睡觉前调低,早上起床前调高),并结合室外温度序列,可以自动预调节室内温度,实现节能舒适。GRU在这里处理的是传感器产生的时间序列数据。
-
视频行为识别与描述(视频理解)
- 作用:在安防监控或视频内容分析中,系统需要理解视频中人在做什么。通常先用CNN分析每一帧画面,提取出特征(如人的姿势、物体),然后将这些特征按帧顺序输入GRU。GRU通过分析这些特征的连续变化,来判断这是一个“走路”、“跑步”还是“摔倒”的动作,甚至生成一段文字描述。
六、 动手实践:用GRU预测文本情感
光说不练假把式,让我们通过一个最简单的Python代码示例,看看如何用GRU来实现一个情感分析任务:判断一段电影评论是正面还是负面。
我们将使用流行的深度学习库 PyTorch 和一个简单的公开数据集。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
# 1. 模拟准备数据(实际中应从文件加载并做文本向量化)
# 假设我们有1000条评论,每条评论被表示为长度为20的整数序列(每个数字代表一个词)
# 标签:1代表正面,0代表负面
num_samples = 1000
seq_length = 20
vocab_size = 10000 # 假设词汇表有10000个词
embedding_dim = 128 # 词向量的维度
hidden_dim = 64 # GRU隐藏层的维度
# 生成模拟数据
X_data = np.random.randint(0, vocab_size, size=(num_samples, seq_length))
y_data = np.random.randint(0, 2, size=(num_samples,))
# 转换为PyTorch张量
X_tensor = torch.LongTensor(X_data)
y_tensor = torch.LongTensor(y_data)
# 创建数据加载器
dataset = TensorDataset(X_tensor, y_tensor)
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 2. 定义GRU模型
class SentimentGRU(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
super().__init__()
# 词嵌入层:将整数索引的词转换为稠密向量
self.embedding = nn.Embedding(vocab_size, embed_dim)
# GRU层:处理序列
self.gru = nn.GRU(embed_dim, hidden_dim, batch_first=True)
# 全连接层:将GRU的最终输出映射为正面/负面两类
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
# text形状: [batch_size, seq_length]
embedded = self.embedding(text) # 形状: [batch_size, seq_length, embed_dim]
# 将整个序列输入GRU
output, hidden = self.gru(embedded)
# 我们取最后一个时间步的隐藏状态作为整个序列的表示
# hidden形状: [1, batch_size, hidden_dim]
hidden = hidden.squeeze(0)
# 通过全连接层分类
prediction = self.fc(hidden) # 形状: [batch_size, output_dim]
return prediction
# 初始化模型
model = SentimentGRU(vocab_size, embedding_dim, hidden_dim, output_dim=2)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,用于分类
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 训练模型(简化训练循环,仅展示流程)
num_epochs = 5
for epoch in range(num_epochs):
total_loss = 0
for batch_X, batch_y in train_loader:
# 前向传播
predictions = model(batch_X)
loss = criterion(predictions, batch_y)
# 反向传播与优化
optimizer.zero_grad() # 清空过往梯度
loss.backward() # 计算当前梯度
optimizer.step() # 更新模型参数
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f'Epoch {epoch+1}, Average Loss: {avg_loss:.4f}')
print("训练完成!")
# 4. 使用模型进行预测(示例)
# 假设有一条新评论,已被转换为索引序列
test_review = torch.LongTensor([[10, 25, 100, 5, 300, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) # 实际中需填充到相同长度
model.eval() # 切换到评估模式
with torch.no_grad(): # 不计算梯度,节省资源
prediction = model(test_review)
# 获取概率最高的类别
predicted_class = torch.argmax(prediction, dim=1)
sentiment = "正面" if predicted_class.item() == 1 else "负面"
print(f"模型预测这条评论的情感是: {sentiment}")
代码解读:
- 数据准备:评论被转换成数字序列,并打上标签。
- 模型定义:
Embedding层:将数字变成有意义的向量(让网络理解词义)。GRU层:核心!按顺序处理词向量序列,捕捉上下文。Linear层:根据GRU最终的理解(隐藏状态)做二分类判断。
- 训练过程:模型不断查看数据,通过损失函数判断预测对错,利用反向传播算法自动调整GRU“门”和其他所有参数,让它越来越擅长区分正负面情感。
- 预测:输入一条新评论,模型输出它的情感判断。
通过这个简单例子,你可以看到GRU是如何作为一个核心组件,被嵌入到一个完整的自然语言处理任务流程中的。
七、 总结与思维导图
恭喜你!现在你已经对GRU有了一个比较全面的认识。让我们最后用一句话概括:
GRU,通过其精巧的“更新门”和“重置门”,学会了像人类一样对序列信息进行动态的、有选择性的记忆与遗忘,从而成为处理时序数据的强大而高效的工具。
为了帮助你更好地梳理和记忆本文的全部内容,我将核心知识点总结成下面的思维导图:
mindmap
root(GRU门控循环单元)
归属与起源
循环神经网络(RNN)改进型
2014年由Cho等人提出
背景:解决RNN长程依赖问题
定位:更简洁高效的LSTM变体
核心原理 (记忆管理术)
类比:管理手机相册
两个核心门控
更新门:控制记忆融合比例
重置门:筛选相关旧记忆
信息传递:单向顺序传递
训练逻辑:反向传播调整门参数
优点
缓解梯度消失/爆炸
结构简单,训练较快
擅长捕捉序列依赖
局限性
超长序列仍有遗忘风险
顺序计算,训练较慢
不擅空间/图结构数据
适用场景
自然语言处理
(机器翻译、文本生成)
语音处理
(语音识别、合成)
时间序列预测
(股票、天气、销量)
视频分析(结合CNN)
应用案例
智能输入法预测
同声传译字幕
股票趋势分析
智能家居温控
视频行为识别
学习GRU的重点,在于理解其 “门控”思想如何优雅地解决了序列建模中的核心矛盾——长期记忆与信息筛选。当你今后遇到任何与“时间”、“顺序”、“连续”相关的问题时,不妨想一想:是不是可以请GRU这位专家来帮忙呢?
希望这篇科普能为你打开循环神经网络世界的一扇窗。人工智能的学习之旅就像GRU处理序列一样,一步一个脚印,不断积累和更新自己的“记忆”。加油!
更多推荐
 38
38 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)