
信息收集篇3——人脸识别系统渗透测试实战
摘要:本文介绍了对人脸识别门禁系统进行渗透测试的信息收集实战过程。通过实地考察获取了设备IP地址、后台登录界面、人像采集网站域名及统一身份认证服务等信息。采用nmap扫描、代码审计等技术手段,发现系统存在硬编码API密钥、半绕过漏洞以及nginx服务器漏洞(如CVE-2022-41741)等安全隐患。文章强调渗透测试应遵循检测而非破坏的原则,展示了网络侦察在网络安全中的关键作用,为后续渗透工作提供
这次的信息收集篇将把之前的两次信息收集篇的内容运用于实战,在对一个人脸识别系统进行渗透测试时,信息收集便是我们的第一要务,也是决定我们渗透进程走向的关键一步。
一、确认渗透目标


这是一个人脸识别的门禁,我们需要渗透的目标正是该人脸识别的门禁系统,确认目标后我们正式进入到信息收集的阶段。
二、IP、域名地址搜集
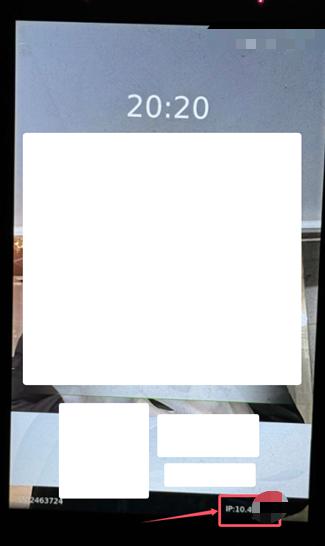
我们发现该设备的IP地址写在了右下角,我们就获取到了第一个IP地址信息10.41.x.x(涉及到保密信息,我无法展示全部的IP地址)
通过实地考察,我们发现了很多台人脸识别设备,形成了一个系统的人脸识别服务集群,这些设备的IP的地址属于同一个地址段。
我们可以在浏览器直接访问该IP地址:

就出现了如上图的人脸识别系统后台登录界面,默认的用户名是admin,密码的相关信息目前还没有收集到。
与此同时,我们通过登录到该公司的企业微信账户,里面有一个上传人脸的小工具(微信小程序),我们打开该小程序,发现有四个文件上传路径,其中第一个上传路径就对应着该人脸识别门禁系统的人像数据库。

在浏览器中打开该程序就拿到了该人像采集的域名,在进入人像采集界面之前,该公司还链接了一个统一身份认证的服务,该服务同样需要账号密码来认证公司内部的一个身份,同时也对应着上传文件到对应的用户ID下。
总结来说,我们拿到了该公司的人脸识别门禁的后台登录界面、该公司的人像采集网站的域名和端口、以及该公司相关的一个统一身份认证的服务。后面两个服务相关联,这可能是我们的突破口,亦可能是我们后面的难题。
紧接着需要我们通过工具来对该域名进行深度挖掘,试图找出该域名下是否还存在子域名,该域名是否还开放了其它端口,这些端口都对应哪些服务?
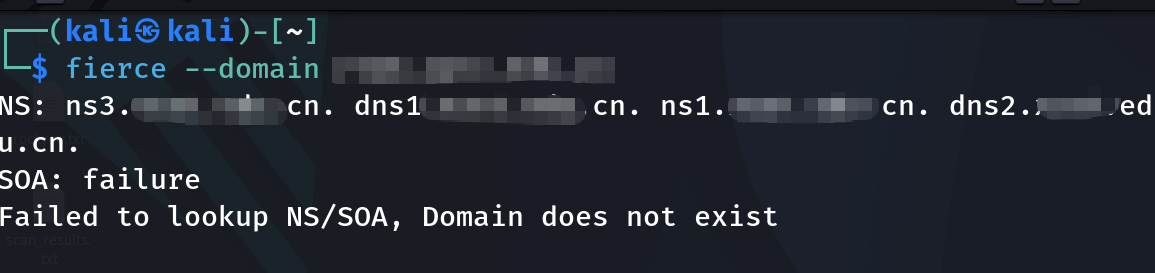
通过fierce去搜索该域名是否还有子域名,并没有什么发现,仅仅只发现了该公司的云DNS系统,通过访问该DNS系统,仍然跳出登录框进行认证才可以对其进行访问,我们可以暂时先放下这一发现。
接下来我们通过nmap去扫描该域名还开放了哪些端口,这一点尤为重要,当在一些端口处没有进展时,或许换一个端口访问就可以发现很多的重要信息。
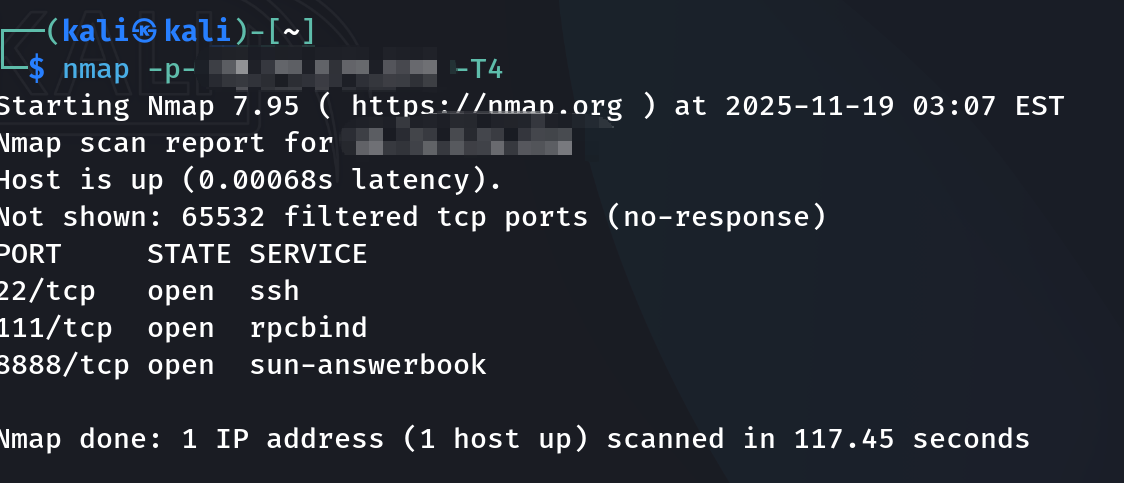
对这些端口进行进一步分析发现还是没有我们可以利用的信息,走到这里,我们已经做完最常规的信息收集,但是由于收集到的信息十分有限,我们规整一下自己的思路。由于目前发现的所有信息绕不开账户密码登录认证,这样的认证不难激起我们绕过的想法,这时的思路就有很多种:
1、最简单的想法就是对这些账户密码直接进行爆破,因为我们通过其它手段已经获取了该公司所有员工的工号(这一步涉及信息泄露,在本篇文章中不进行展示),包括人脸识别门禁系统的后台登录的默认账户admin,我们只需要对其密码进行爆破即可。
2、我们可以对所有已知的网页前端代码进行代码审计,看看是否还能找到他们前端安全配置不当的问题,才能有针对性的展开下一步信息收集,比如:API接口扫描,目录检索等,前端源码的不当配置很可能是支持我们绕过的最佳契机。
3、最复杂且最直接的办法,直接对该系统背后的服务器进行扫描,通过扫描到该服务器的漏洞看看是否有我们可以利用的现成攻击框架或一键式攻击模块,这样的效率或许是最高的,破坏也是最大最直接的。
第一条思路在这里就不进行演示了,本篇文章主要分享的是信息收集的思路。但不得不说的一句是,通过爆破的尝试,我们发现该公司的统一身份认证装了WAF防火墙,并且对IP的频繁访问做了并发请求限制,我们很难在第一天思路上找到突破,这里就直接进行第二条思路。
三、代码审计
这里我们通过F12打开开发者工具,我们直接将目光定位到该界面的JS文件上,从它的config.js文件中,我们发现了一个内网IP和其开放的端口:

这很有可能是该系统背后的服务器IP,值得关注的是后面的bio_platform这个目录,通过搜集资料发现该目录很可能对应存放着一些生物识别信息,正好和我们渗透的该人脸识别系统有关。
对于我们一直苦恼的认证绕过,我们在代码审计的过程中有了一些发现:

这里我们使用curl来查询该网页下的关键js文件,我们根据它给予我们的反馈进行寻找,果然找到了包含认证信息的js文件。而且在我进行代码审计的过程中,发现了该js文件里写入了一个硬编码的APIkey:
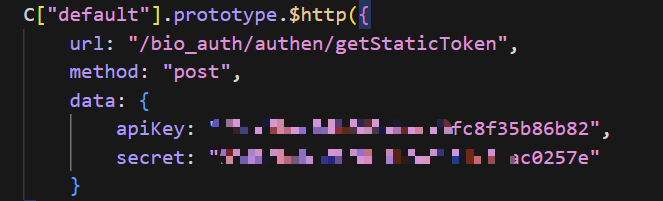
这里给出了请求的路径是getStaticToken,说明该APIkey和secret可以直接用于形成token,这样对key进行硬编码的前端配置很可能有着极其之大的安全隐患,这里若是可以生成静态token甚至可能直接影响到通过认证的机制。
我们现在需要知道该网页具体的认证机制,所以我们用burp进行抓包,这里我们进行一个上传照片的操作:
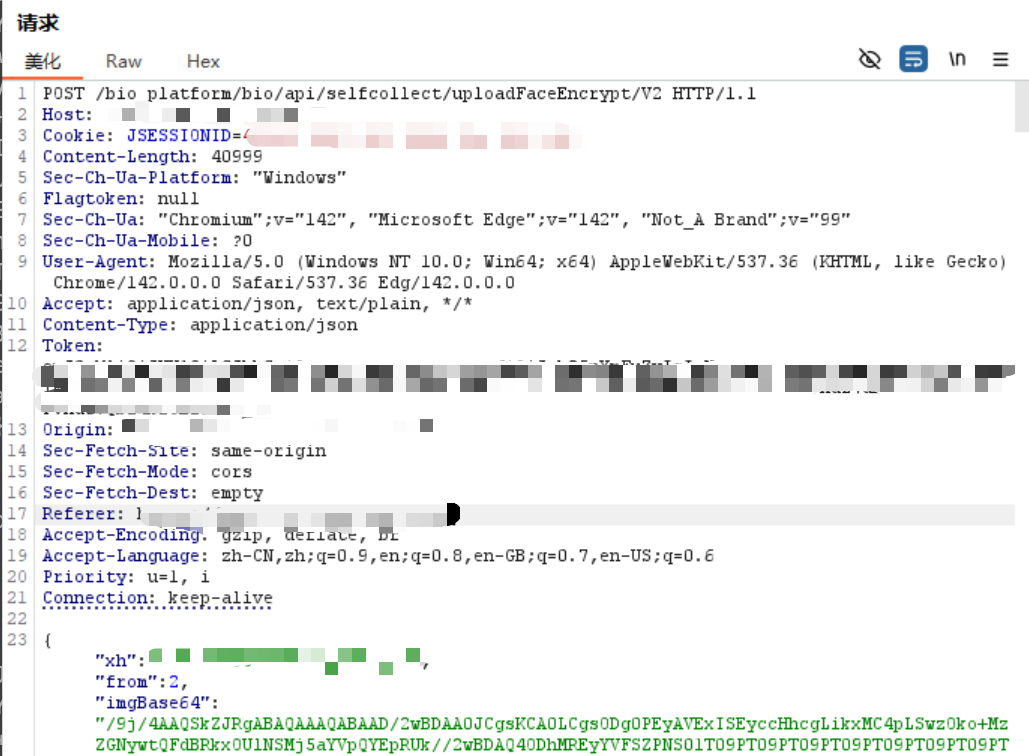
这个包的内容相对较多,我们发现参与认证的数据有cookie、token以及对应个人身份的"xh(学号)",这样的多重认证机制我们暂时难以绕过,但是我们发现了该网站硬编码在前端的APIkey以生成的token确实参与了认证,这里我们需要的认证参数或许只有cookie。
继续我们上述的猜想,我们现在要做的信息收集是扫描该网页的所有API接口,或许存在某个接口不需要我们进行认证,或者只依赖于静态token进行认证的话,我们就可以在渗透测试报告中对该硬编码的APIKey评定为中危乃至高危漏洞,当然这样的情况相对理想。
我们通过使用dirb内置的字典并未发现该网站下的常见目录,但是我们在代码审计的过程中发现了一些非常见目录,都于一家生物识别公司相关,这些API接口应该作用于该公司的技术调用手段,对于我们进行认证绕过并没有实质性帮助。
但是我们通过扫描该门禁系统的后台,在system.asp目录下进入,我们通过抓包很明显地发现在这条目录下我们完成了绕过,但是正常访问的时候会跳转回登录界面,这说明我们进行了半绕过:
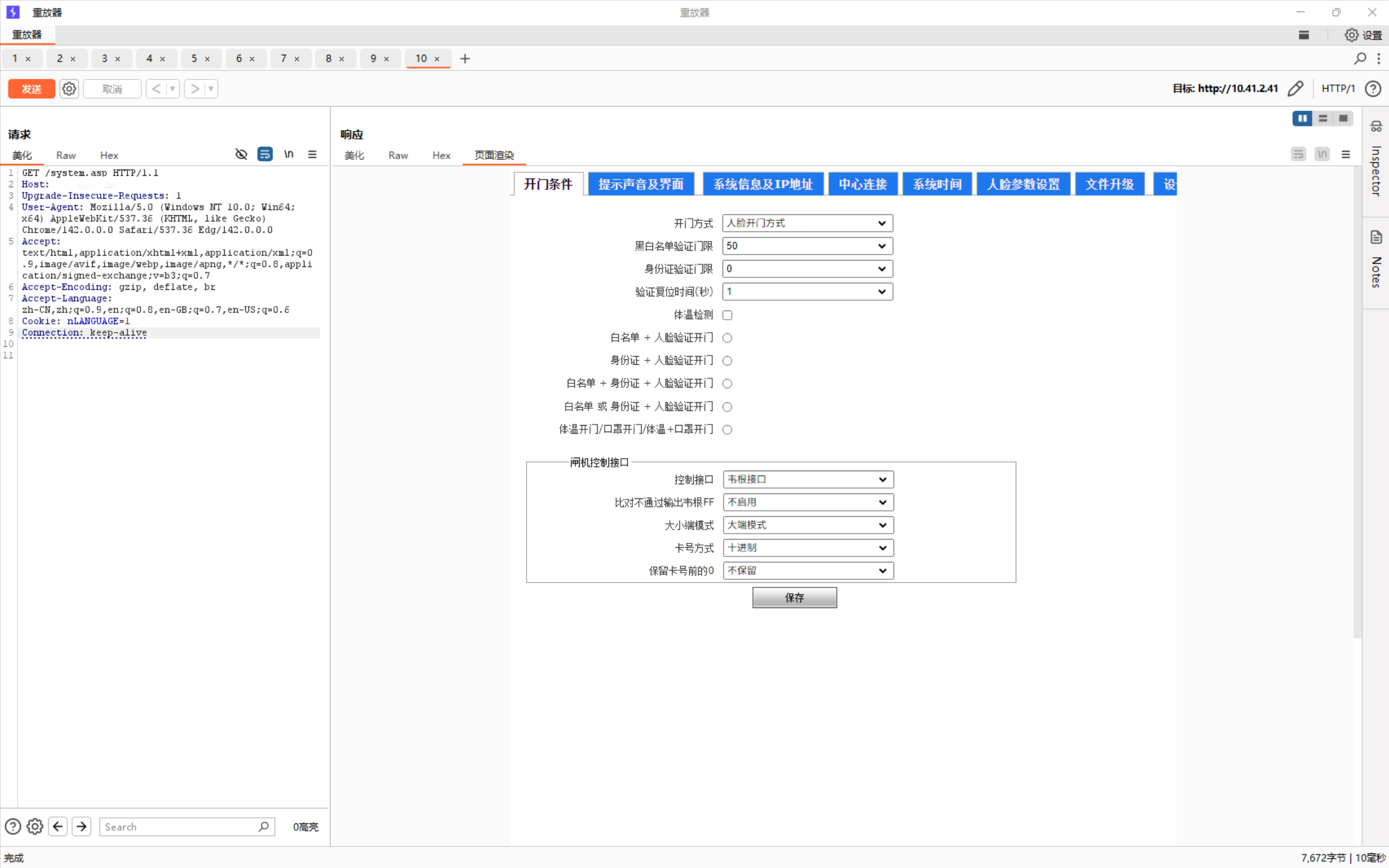
这对于我们的工作来说是重大发现,后续的渗透工作可以抓住这一弱点完成全部绕过。
四、漏洞扫描
在前文中我对于漏扫的描述是最直接的办法,事实上也是如此,我们若是直接扫描该网站后端的服务器漏洞,直接攻击服务器从而拿到权限,这样的渗透才更具有观赏性,正如同我之前复现的永恒之蓝漏洞一样。
我们直接用nmap的漏扫功能对该域名和端口进行扫描:
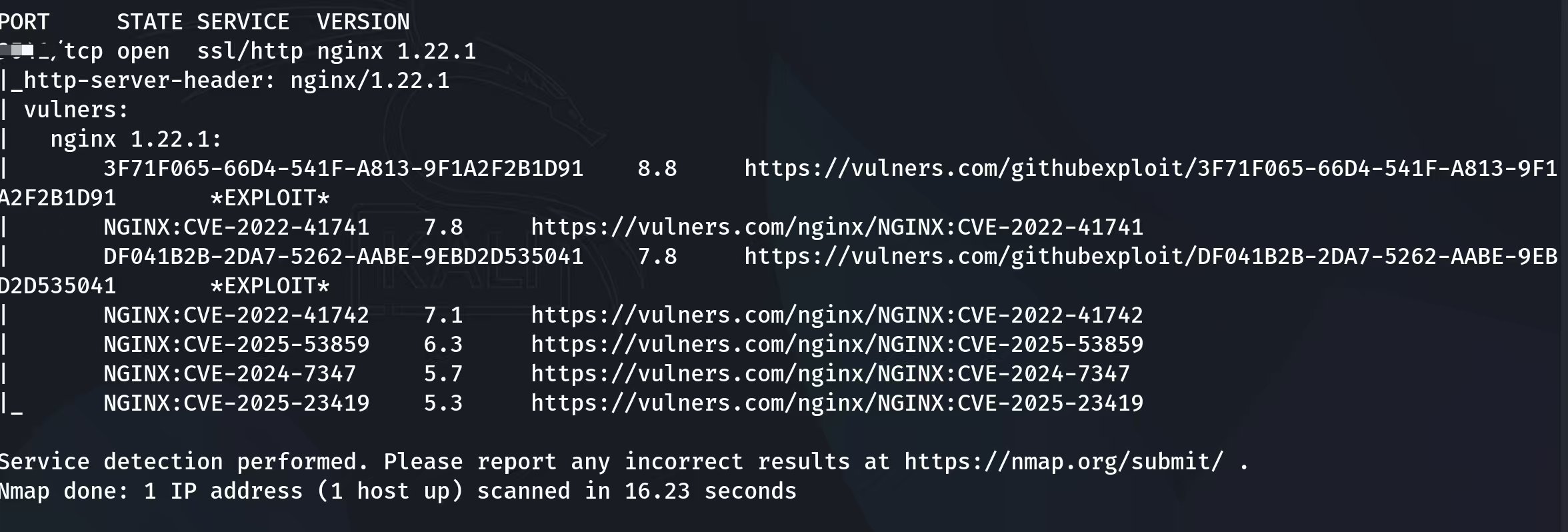
这样就直观扫描出了该服务器的版本是nginx 1.22.1,存在的漏洞编号也一并列出,其中CVE-2022-41741和CVE-2022-41742这两个漏洞危险系数最高,主要表现为内存漏洞,其中也有在github上收录的exp,我们可以直接对其进行攻击模块部署,同时也要注意的是,我们此次渗透测试的初衷,不是去进行肆意的破坏而是检测其有什么安全隐患,模拟黑客的攻击但不心怀黑客的恶意,这才是渗透的初衷。
同时关于nginx 1.22.1扫描出来的漏洞其实有CVE-2025-53859关于修复邮件模块、CVE-2025-23419主要影响使用 TLS 会话恢复 和 SSL 会话缓存 的配置,我们并未在网页中发现有这两种服务,这只能说明一个问题,该nginx 1.22.1其实是一台代理服务器,被置于网页与后端服务器之间,其不仅仅服务于人脸识别系统,可能兼顾于其它服务,倘若我们无法绕过该服务器去看到隐藏在它后面的那台服务器本身,我们即便拿到该服务器的最高权限也无法获取到根本的用户信息数据库。与此同时,我们发现的关于内存和文件的漏洞虽然很可能适用于人脸识别系统的服务,但是我们依然无法通过这些漏洞来拿取权限,我们可能只可以通过一些恶意的脚本去导致它的内存瘫痪,这样的破坏行为亦不符合我们渗透测试的初衷。
以上就是关于对人脸识别系统的实战项目进行渗透测试的实战信息收集阶段,我们或许并没有完全利用前两个信息收集篇的所有工具,但是我们收集信息的一般流程和思路是不会变的,通过这样的一次信息收集实战,希望大家也能明白网络侦察在网络安全领域是一项多么重要的能力,这也是我给信息收集设立专栏的原因。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)