
基于 YOLOv8+ByteTrack 的车辆测速测距与多目标计数系统 车辆超速检测 智慧交通 车辆检测跟踪 交通管制 深度学习 计算机毕业设计✅
基于 YOLOv8+ByteTrack 的车辆测速测距与多目标计数系统 车辆超速检测 智慧交通 车辆检测跟踪 交通管制 深度学习 计算机毕业设计✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
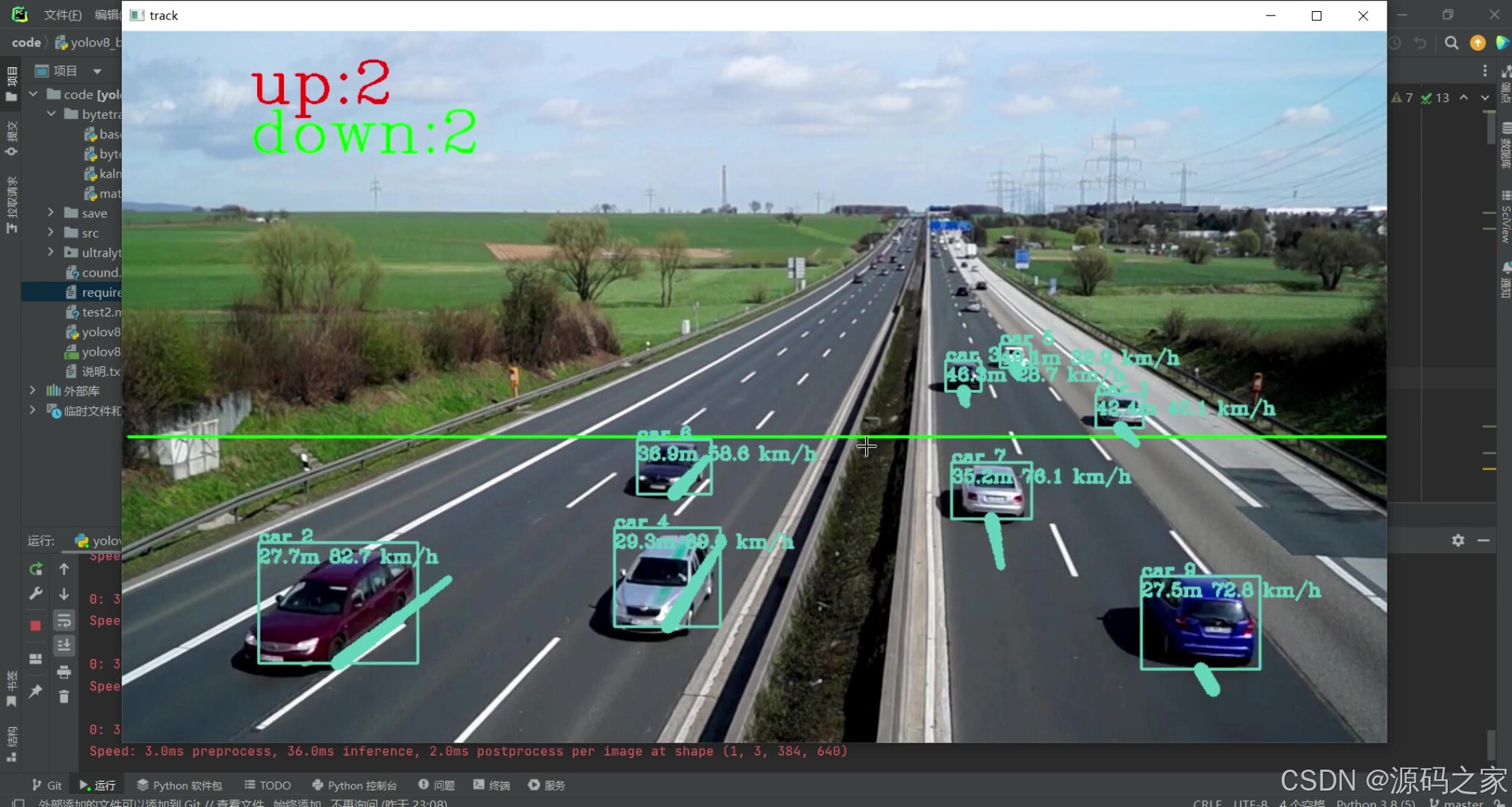
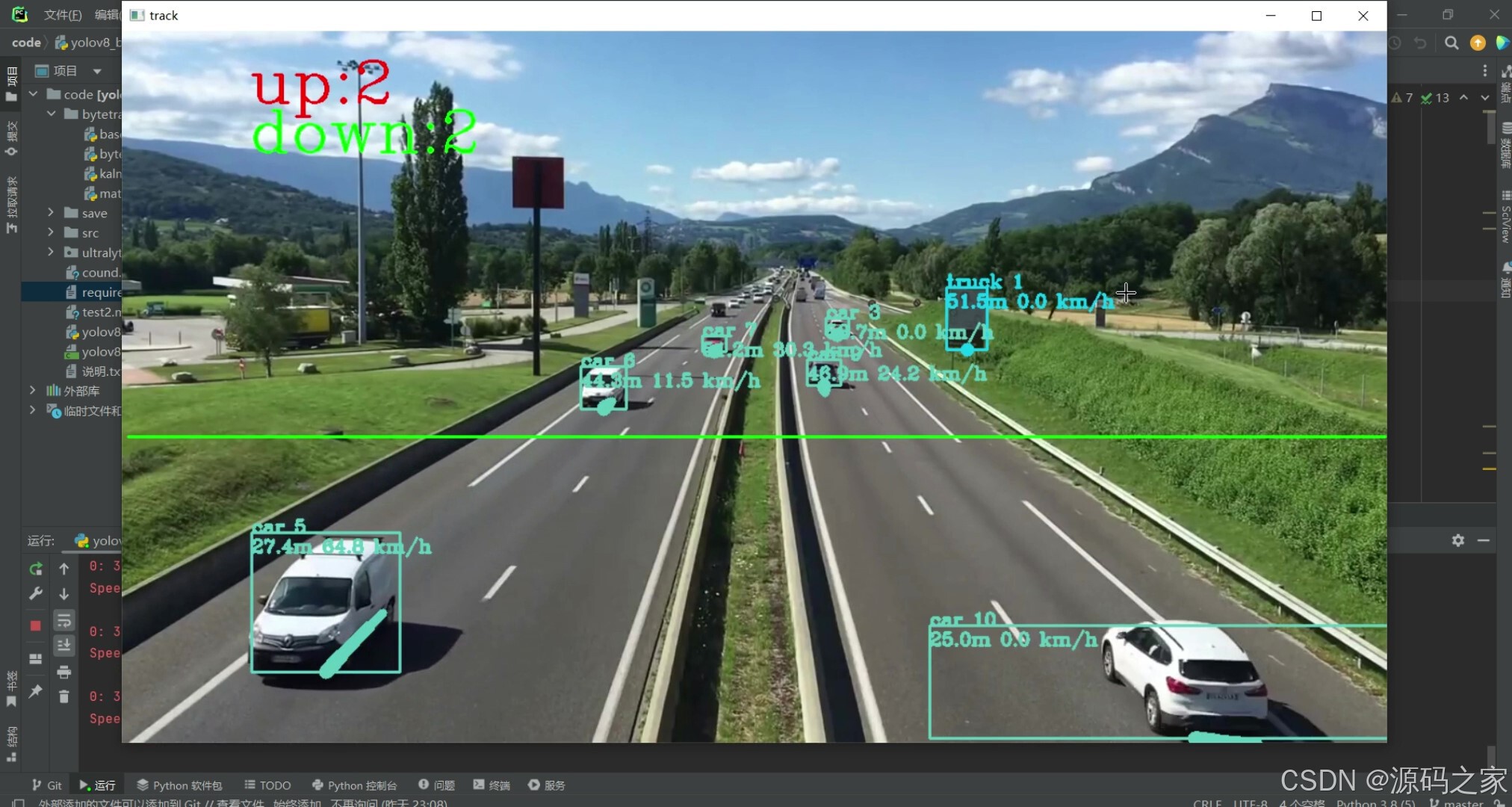
Python语言、YOLOv8、ByteTrack算法 YOLOv8测速+测距+车辆计数、目标计数+目标测速
本项目聚焦车辆检测场景的核心需求,以 Python 为开发语言,融合 YOLOv8 目标检测算法与 ByteTrack 多目标跟踪算法,打造集车辆检测、实时测速、精准测距、目标计数于一体的智能系统,适用于交通流量统计、道路管控等场景,兼具技术先进性与工程实用性。
技术层面,系统以 YOLOv8 作为核心检测器,其高效的目标识别能力可快速定位画面中车辆,为后续测速、测距提供精准目标坐标;针对传统跟踪算法漏检遮挡目标、轨迹碎片化问题,引入 ByteTrack 算法优化跟踪效果。ByteTrack 基于 tracking-by-detection 范式,突破 “仅关联高分检测框” 的局限,通过关联所有检测框,利用低分框与轨迹的相似性恢复遮挡目标、过滤背景干扰,同时结合卡尔曼滤波预测轨迹位置,以 IoU 为相似度指标,通过匈牙利算法完成匹配,无需 ReID 特征即可实现稳定跟踪,保障车辆运动轨迹连续性。
功能上,系统核心能力覆盖三方面:一是车辆测速与测距,基于 YOLOv8 检测的车辆坐标与 ByteTrack 跟踪的轨迹变化,计算车辆实时速度与与监测点的距离;二是多目标计数,对画面中车辆进行动态统计,精准记录通行数量;三是稳定跟踪,即使车辆出现遮挡等情况,ByteTrack 仍能维持轨迹完整性,避免计数遗漏。
整体而言,该系统通过 YOLOv8 与 ByteTrack 的协同,既保证检测精度,又解决跟踪痛点,可实时输出车辆速度、距离、计数数据,为交通管理提供可靠数据支撑,其技术方案简洁高效,在实际场景中具备较强的落地价值。
2、项目界面
(1)测速测距车辆计数界面1
(2)测速测距车辆计数界面2
(3)测速测距车辆计数界面3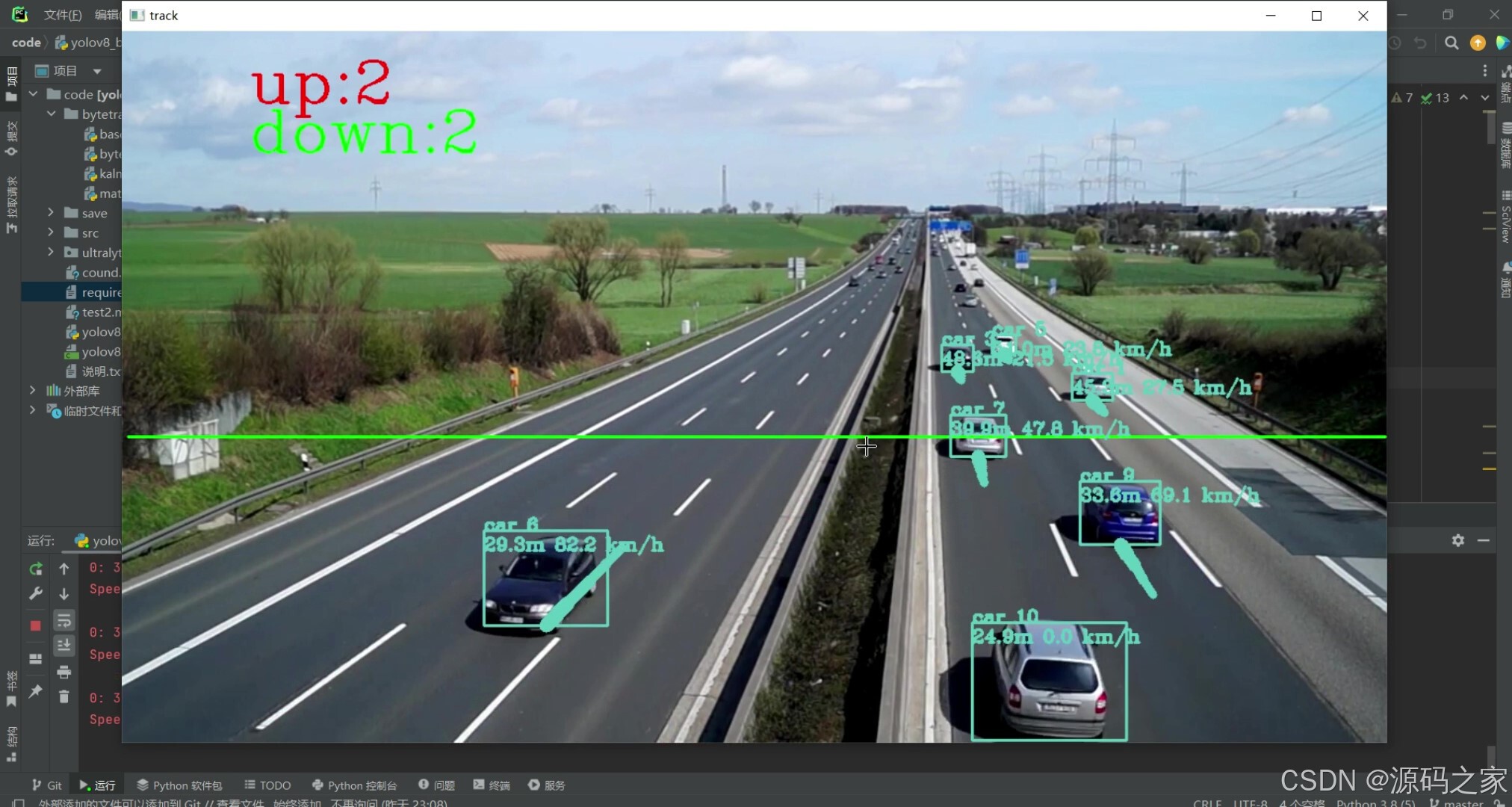
3、项目说明
技术栈:
Python语言、YOLOv8、ByteTrack算法 YOLOv8测速+测距+车辆计数、目标计数+目标测速
ByteTrack是基于tracking-by-detection范式的跟踪方法。大多数多目标跟踪方法通过关联分数高于阈值的检测框来获取目标ID。
对于检测分数较低的目标,例如遮挡目标,会被简单的丢弃,这带来了不可忽略的问题,
包括大量的漏检和碎片化轨迹。为了解决该问题,作者提出了一种简单、高效且通用的数据关联方法BYTE,
通过关联每个检测框而不仅仅是高分检测框来进行跟踪。对于低分检测框,利用它们与轨迹的相似性来恢复真实目标并过滤掉背景检测。
ByteTrack 使用当前性能非常优秀的检测器 YOLOX 得到检测结果。
在数据关联的过程中,和 SORT 一样,只使用卡尔曼滤波来预测当前帧的跟踪轨迹在下一帧的位置,
预测的框和实际的检测框之间的 IoU 作为两次匹配时的相似度,通过匈牙利算法完成匹配。
这里值得注意的是我们没有使用 ReID 特征来计算外观相似度
实现了一个基于YOLO目标检测和ByteTrack跟踪算法的视频分析系统,主要用于检测视频中的目标(如车辆或行人)、跟踪它们的运动轨迹,并计算它们的速度和流量(如进入和离开的计数)。
实现原理和步骤的详细描述:
- 参数解析**
代码使用argparse模块解析命令行参数,这些参数包括:
- 检测模型权重路径(
--weights)。 - 输入视频路径(
--source)。 - 输出保存路径(
--save)。 - 检测和跟踪相关的阈值(如置信度阈值
--conf_thre、IoU阈值--iou_thre、跟踪阈值--track_thresh等)。 - 相机参数(如高度
--H、角度--alpha、相机内参--calib)。
这些参数为后续的目标检测、跟踪和距离计算提供了必要的配置。
- 相机内参解析**
相机内参--calib以字符串形式输入,代码将其转换为一个3×3的numpy数组,用于后续的深度计算。
- 目标检测**
代码使用ultralytics的YOLO模型进行目标检测:
- 加载YOLO模型(
YOLO(weight_path))。 - 对每一帧图像使用YOLO模型进行检测,获取检测框(
boxes)、置信度(confidences)和类别(class_preds)。 - 将检测结果传递给跟踪模块。
- 目标跟踪**
代码使用ByteTrack跟踪算法对检测到的目标进行跟踪:
- 初始化
BYTETracker对象,设置跟踪相关的参数(如track_thresh、track_buffer、match_thresh)。 - 跟踪模块会根据检测结果更新目标的轨迹,并为每个目标分配唯一的跟踪ID(
tid)。
- 轨迹绘制与流量统计**
- 轨迹绘制:代码为每个目标维护一个轨迹队列(
self.trajectories[tid]),记录目标的运动轨迹,并在图像上绘制轨迹线。 - 流量统计:通过设置一条虚拟的计数线(
self.pointlist),代码判断目标是否穿过这条线,从而统计进入(self.id_in)和离开(self.id_out)的数量。
- 距离和速度计算**
- 深度计算:代码通过相机模型和目标在图像中的位置(
u, v),结合相机高度(H)和角度(alpha),计算目标在相机坐标系下的深度(zc_cam_other)。 - 速度计算:通过目标在连续两帧中的深度变化和时间间隔(
time_interval),计算目标的速度(单位:公里/小时)。
- 图像可视化**
- 在图像上绘制检测框、类别、跟踪ID、速度信息以及计数结果。
- 如果设置了
--vis参数,会显示可视化结果。
- 视频处理**
- 使用
cv2.VideoCapture读取输入视频。 - 对每一帧调用
detect_image方法进行处理。 - 将处理后的帧写入输出视频文件。
- 总结**
这段代码的核心功能是: - 使用YOLO模型检测视频中的目标。
- 使用ByteTrack算法跟踪目标的运动轨迹。
- 计算目标的速度和流量。
- 可视化检测和跟踪结果,并保存到输出视频中。
它结合了目标检测和多目标跟踪技术,适用于交通监控、人群分析等场景。
4、核心代码
import cv2
import torch
from ultralytics import YOLO
import os
import argparse
from bytetrack_tracker.byte_tracker import BYTETracker
from collections import deque
import numpy as np
import math
parser = argparse.ArgumentParser()
# 检测参数
parser.add_argument('--weights', default=r"yolov8m.pt", type=str, help='weights path')
# 设置检测的视频路径
parser.add_argument('--source', default=r"cound.mp4", type=str, help='img or video(.mp4)path')
# parser.add_argument('--source', default=r"test2.mp4", type=str, help='img or video(.mp4)path')
parser.add_argument('--save', default=r"./save", type=str, help='save img or video path')
parser.add_argument('--vis', default=True, action='store_true', help='visualize image')
parser.add_argument('--conf_thre', type=float, default=0.5, help='conf_thre')
parser.add_argument('--iou_thre', type=float, default=0.5, help='iou_thre')
# 跟踪参数
parser.add_argument('--track_thresh', type=float, default=0.5, help='track_thresh')
parser.add_argument('--track_buffer', type=int, default=70, help='track_buffer')
parser.add_argument('--match_thresh', type=float, default=0.8, help='match_thresh')
# 添加高度(H)、角度(alpha)和相机内参(calib)参数
parser.add_argument('--H', type=float, default=6.5, help='Height of the camera from the ground')
parser.add_argument('--alpha', type=int, default=8, help='Angle of the camera view')
parser.add_argument('--calib', type=str, default='2900,0.0,640; 0.0,2900,360; 0.0,0.0,1.0',
help='Camera intrinsic parameters')
# 解析参数
opt = parser.parse_args()
# 将字符串形式的 calib 转换为 numpy 数组
calib_values = [float(x) for x in opt.calib.replace(';', ',').split(',')]
opt.calib = np.array(calib_values).reshape(3, 3)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
class Detector(object):
def __init__(self, weight_path, conf_threshold=0.5, iou_threshold=0.5):
self.device = device
self.model = YOLO(weight_path).to(self.device)
self.conf_threshold = conf_threshold
self.iou_threshold = iou_threshold
self.tracker = BYTETracker(track_thresh=opt.track_thresh, track_buffer=opt.track_buffer,
match_thresh=opt.match_thresh)
self.pointlist = [(6, 410), (1278, 410)]
self.trajectories = {}
self.max_trajectory_length = 5
self.id_in = 0
self.id_in_list = []
self.id_out = 0
self.id_out_list = []
@staticmethod
def get_color(idx):
idx = idx * 3
color = ((37 * idx) % 255, (17 * idx) % 255, (29 * idx) % 255)
return color
def draw_measure_line(self, H, calib, u, v, alpha):
alpha = alpha # 角度a
# 相机焦距
fy = calib[1][1]
# 相机光心
u0 = calib[0][2]
v0 = calib[1][2]
pi = math.pi
Q_pie = [u - u0, v - v0]
gamma_pie = math.atan(Q_pie[1] / fy) * 180 / np.pi
beta_pie = alpha + gamma_pie
if beta_pie == 0:
beta_pie = 1e-2
z_in_cam = (H / math.sin(beta_pie / 180 * pi)) * math.cos(gamma_pie * pi / 180)
return z_in_cam
def detect_image(self, img_bgr):
results = self.model(img_bgr, conf=self.conf_threshold, iou=self.iou_threshold)
# Extracting the necessary details from the results
boxes = results[0].boxes.xyxy.cpu().numpy() # xyxy format
confidences = results[0].boxes.conf
class_preds = results[0].boxes.cls
confidences_expanded = confidences.unsqueeze(1)
class_preds_expanded = class_preds.unsqueeze(1)
boxes_tensor = torch.from_numpy(boxes).to(class_preds_expanded.device)
result = torch.cat((boxes_tensor, confidences_expanded, class_preds_expanded), dim=1)
online_targets = self.tracker.update(result.cpu(), [results[0].orig_shape[0], results[0].orig_shape[1]])
cv2.line(img_bgr, self.pointlist[0], self.pointlist[1], (0, 255, 0), 2)
for t in online_targets:
speed_km_per_h = 0
tlwh = t.tlwh
xmin, ymin, xmax, ymax = tlwh[0], tlwh[1], tlwh[0] + tlwh[2], tlwh[1] + tlwh[3]
tid = t.track_id
cls = t.cls.item()
class_pred = int(cls)
color = self.get_color(class_pred + 2)
bottom_center = (int(tlwh[0] + tlwh[2] / 2), int(tlwh[1] + tlwh[3]))
bbox_label = results[0].names[class_pred]
cv2.rectangle(img_bgr, (int(xmin), int(ymin)), (int(xmax), int(ymax)), color, 2)
zc_cam_other = self.draw_measure_line(opt.H, opt.calib, int(tlwh[0] + tlwh[2] / 2), int(tlwh[1] + tlwh[3]),
opt.alpha)
if tid not in self.trajectories:
self.trajectories[tid] = deque(maxlen=self.max_trajectory_length)
trajectory_point = {
'bottom_center': bottom_center,
'zc_cam_other': zc_cam_other
}
self.trajectories[tid].appendleft(trajectory_point)
# 截断轨迹长度
if len(self.trajectories[tid]) > self.max_trajectory_length:
self.trajectories[tid] = self.trajectories[tid][:self.max_trajectory_length]
for i in range(1, len(self.trajectories[tid])):
if self.trajectories[tid][i - 1] is None or self.trajectories[tid][i] is None:
continue
thickness = int(np.sqrt(64 / float(i + 1)) * 2.5)
cv2.line(img_bgr, self.trajectories[tid][i - 1]['bottom_center'],
self.trajectories[tid][i]['bottom_center'], color,
thickness)
# 通过阈值判断是竖线还是横线,若x2和x1之间的差值小于20 判断为竖线 否则为横线
"""
例如:如下垂线上下两点的x保持不变,y存在变化 所以垂线的x2-x1=0
*
*
*
*
如下横线左右两点的y保持不变,x存在变化 所以横线的y2-y1=0
***********
"""
if abs(self.pointlist[1][0] - self.pointlist[0][0]) < 20:
# 通过判断同一个目标上下两帧是否过线 来进行计数
# self.trajectories[tid][i - 1][0]代表上一帧 self.trajectories[tid][i][0]代表当前帧
if ((self.trajectories[tid][i - 1]['bottom_center'][0] <= self.pointlist[0][0]) and
(self.trajectories[tid][i]['bottom_center'][0] > self.pointlist[0][0])) and \
((self.trajectories[tid][i]['bottom_center'][1] > self.pointlist[1][
1]) and # 设置目标的撞线范围 不得超线
(self.trajectories[tid][i]['bottom_center'][1] < self.pointlist[0][1])):
# 如果目标ID已经计数过,则忽略
if tid in self.id_in_list:
continue
# 否则,增加进入计数,并将ID添加到已计数列表中
else:
self.id_in += 1
self.id_in_list.append(tid)
if ((self.trajectories[tid][i - 1]['bottom_center'][0] >= self.pointlist[0][0]) and
(self.trajectories[tid][i]['bottom_center'][0] < self.pointlist[0][0])) and \
((self.trajectories[tid][i]['bottom_center'][1] > self.pointlist[1][1]) and
(self.trajectories[tid][i]['bottom_center'][1] < self.pointlist[0][1])):
if tid in self.id_out_list:
continue
else:
self.id_out += 1
self.id_out_list.append(tid)
else:
if ((self.trajectories[tid][i - 1]['bottom_center'][1] >= self.pointlist[0][1]) and
(self.trajectories[tid][i]['bottom_center'][1] < self.pointlist[0][1])) and \
((self.trajectories[tid][i]['bottom_center'][0] > self.pointlist[0][0]) and
(self.trajectories[tid][i]['bottom_center'][0] < self.pointlist[1][0])):
if tid in self.id_in_list:
continue
else:
self.id_in += 1
self.id_in_list.append(tid)
if ((self.trajectories[tid][i - 1]['bottom_center'][1] <= self.pointlist[0][1]) and
(self.trajectories[tid][i]['bottom_center'][1] > self.pointlist[0][1])) and \
((self.trajectories[tid][i]['bottom_center'][0] > self.pointlist[0][0]) and
(self.trajectories[tid][i]['bottom_center'][0] < self.pointlist[1][0])):
if tid in self.id_out_list:
continue
else:
self.id_out += 1
self.id_out_list.append(tid)
time_interval = 1 / fps
speed_m_per_s = abs(self.trajectories[tid][i]['zc_cam_other'] - self.trajectories[tid][i - 1][
'zc_cam_other']) / time_interval
speed_km_per_h = speed_m_per_s * 3.6 # 转换为公里/小时
# 显示类名和跟踪ID
cv2.putText(img_bgr, f"{bbox_label} {int(tid)}",
(int(tlwh[0]), int(tlwh[1])), cv2.FONT_HERSHEY_COMPLEX, 0.6, color, 2)
# 显示速度,纵坐标比类名和跟踪ID的位置稍低一些
cv2.putText(img_bgr, f"{zc_cam_other:.1f}m {speed_km_per_h:.1f} km/h",
(int(tlwh[0]), int(tlwh[1]) + 20), cv2.FONT_HERSHEY_COMPLEX, 0.6, color, 2)
cv2.putText(img_bgr, str(f"down:{self.id_in}"),
(int(img_bgr.shape[1] * 0.1), int(img_bgr.shape[0] * 0.17)), cv2.FONT_HERSHEY_COMPLEX,
2,
(0, 255, 0), 2)
cv2.putText(img_bgr, str(f"up:{self.id_out}"),
(int(img_bgr.shape[1] * 0.1), int(img_bgr.shape[0] * 0.1)), cv2.FONT_HERSHEY_COMPLEX,
2,
(0, 0, 255), 2)
return img_bgr
# Example usage
if __name__ == '__main__':
model = Detector(weight_path=opt.weights, conf_threshold=opt.conf_thre, iou_threshold=opt.iou_thre)
capture = cv2.VideoCapture(opt.source)
fps = capture.get(cv2.CAP_PROP_FPS)
size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
outVideo = cv2.VideoWriter(os.path.join(opt.save, os.path.basename(opt.source).split('.')[-2] + "_out.mp4"), fourcc,
fps, size)
while True:
ret, frame = capture.read()
if not ret:
break
img_vis = model.detect_image(frame)
outVideo.write(img_vis)
img_vis = cv2.resize(img_vis, None, fx=1, fy=1, interpolation=cv2.INTER_NEAREST)
cv2.imshow('track', img_vis)
cv2.waitKey(30)
capture.release()
outVideo.release()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
更多推荐
 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)