
强化学习实战——超级马里奥兄弟(Pytorch)
本人自动化专业,学习强化学习半年,想尝试做一个强化学习的实例,于是选择了super_mario_bros作为第一个demo。使用PPO算法玩“超级马里奥兄弟”-云社区-华为云张伟楠.《动手学强化学习》.人民邮电出版社,2022。动手学强化学习【强化学习玩超级马里奥【2022年3月最新】(学不会可以来打我)】强化学习玩超级马里奥【2022年3月最新】(学不会可以来打我)_哔哩哔哩_bilibili原
一、前言
本人自动化专业,学习强化学习半年,想尝试做一个强化学习的实例,于是选择了super_mario_bros作为第一个demo。
先附上参考资料:
张伟楠.《动手学强化学习》.人民邮电出版社,2022。动手学强化学习
【强化学习玩超级马里奥【2022年3月最新】(学不会可以来打我)】强化学习玩超级马里奥【2022年3月最新】(学不会可以来打我)_哔哩哔哩_bilibili
原本想直接运行别人的代码,但在实操过程中遇到诸多问题,特别是版本的不适配。nes_py和super_mario_bros是基于gym开发的,但是gym现在已经不再维护,现在更多使用的是gymnasium。而gymnasium在返回值结构等方面与gym不同,需要对马里奥环境进行封装。另外,stable_baselines3中有很多现成的包装器和算法,但也和nes_py、super_mario_bros不太兼容。
总之,经过诸多尝试,都没能成功运行代码。于是我决定较少地引用库,大部分都写代码实现;同时代码结构以及张量的形状和传播过程都更为清晰,方便学习和调试。
二、代码
首先给出我的anaconda环境中各个库的版本
Python version: 3.11.7
PyTorch version: 2.7.0+cu118
gym version: 0.23.0
nes_py version: 8.1.8
super_mario_bros version: 7.3.0代码开头当然是一些引用啦
import os
from tqdm import tqdm
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym.spaces import Box
from gym import Wrapper
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, COMPLEX_MOVEMENT, RIGHT_ONLY
import cv2
import matplotlib.pyplot as plt首先是对马里奥环境的一些处理。只使用gym_super_mario_bros的原始环境是不够的。这里给出原始环境的链接gym-super-mario-bros · PyPI。处理环境的代码参考了华为云。
JoypadSpace包装器规定了环境所能执行的所有动作(RIGHT/SIMPLE/COMPLEX)。各个aciton_type对应所有动作见此链接gym-super-mario-bros/gym_super_mario_bros/actions.py at master · Kautenja/gym-super-mario-bros。
CustomReward更改了执行动作所得reward,加入了得分变化、死亡和通关的奖励。原始环境已有的reward包括时间、向右移动和死亡的奖励值(详见原始环境的链接)。
CustomSkipFrame对state,也就是游戏画面进行了处理。包括改变图片尺寸、灰度处理以及帧处理。帧处理是对连续4帧的state执行相同的action,将最后两次的state融合成一张图片,再加入一个大小为4的队列中,得到张量的形状是(4,84,84)。这样既能减小运算量,又能让决策网络“感受到”状态变化的感觉。
# 创建环境
def create_train_env(world, stage, action_type):
# 创建基础环境
if action_type == "right":
actions = RIGHT_ONLY
elif action_type == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
env = gym_super_mario_bros.make("SuperMarioBros-{}-{}-v3".format(world, stage))
env = JoypadSpace(env, actions)
# 对环境自定义
env = CustomReward(env, world, stage, monitor=None)
env = CustomSkipFrame(env)
return env
# 对原始环境进行修改,以获得更好的训练效果
class CustomReward(Wrapper):
def __init__(self, env=None, world=None, stage=None, monitor=None):
super(CustomReward, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(1, 84, 84))
self.curr_score = 0
self.current_x = 40
self.world = world
self.stage = stage
if monitor:
self.monitor = monitor
else:
self.monitor = None
def step(self, action):
state, reward, done, info = self.env.step(action)
if self.monitor:
self.monitor.record(state)
state = process_frame(state)
reward += (info["score"] - self.curr_score) / 40. # 分数差奖励
self.curr_score = info["score"]
if done:
if info["flag_get"]: # 获得旗子
reward += 50
else:
reward -= 50
if self.world == 7 and self.stage == 4:
if (506 <= info["x_pos"] <= 832 and info["y_pos"] > 127) or (
832 < info["x_pos"] <= 1064 and info["y_pos"] < 80) or (
1113 < info["x_pos"] <= 1464 and info["y_pos"] < 191) or (
1579 < info["x_pos"] <= 1943 and info["y_pos"] < 191) or (
1946 < info["x_pos"] <= 1964 and info["y_pos"] >= 191) or (
1984 < info["x_pos"] <= 2060 and (info["y_pos"] >= 191 or info["y_pos"] < 127)) or (
2114 < info["x_pos"] < 2440 and info["y_pos"] < 191) or info["x_pos"] < self.current_x - 500:
reward -= 50
done = True
if self.world == 4 and self.stage == 4:
if (info["x_pos"] <= 1500 and info["y_pos"] < 127) or (
1588 <= info["x_pos"] < 2380 and info["y_pos"] >= 127):
reward = -50
done = True # 针对这两个特定关卡
# if action in [2, 4]:
# reward += 0.5 # 跳跃小而正向的鼓励 针对simple_action
# # 卡住惩罚
# if info["x_pos"] == self.current_x:
# reward -= 0.3
self.current_x = info["x_pos"]
return state, reward / 10., done, info
def reset(self):
self.curr_score = 0
self.current_x = 40
return process_frame(self.env.reset())
def process_frame(frame):
if frame is not None:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) # 灰度处理
frame = cv2.resize(frame, (84, 84))[None, :, :] / 255. # 变尺寸
return frame
else:
return np.zeros((1, 84, 84))
class CustomSkipFrame(Wrapper):
def __init__(self, env, skip=4):
super(CustomSkipFrame, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(skip, 84, 84))
self.skip = skip
self.states = np.zeros((skip, 84, 84), dtype=np.float32)
def step(self, action):
total_reward = 0
last_states = []
for i in range(self.skip):
state, reward, done, info = self.env.step(action)
total_reward += reward
if i >= self.skip / 2:
last_states.append(state)
if done:
self.reset()
return self.states.astype(np.float32), total_reward, done, info
max_state = np.max(np.concatenate(last_states, 0), 0)
self.states[:-1] = self.states[1:]
self.states[-1] = max_state
return self.states.astype(np.float32), total_reward, done, info # 输出shape是(4,84,84)
def reset(self):
state = self.env.reset()
self.states = np.concatenate([state for _ in range(self.skip)], 0)
return self.states.astype(np.float32)策略网络和价值网络,参考了华为云。
class ConvBaseNet(nn.Module):
def __init__(self, num_inputs):
super(ConvBaseNet, self).__init__()
self.conv1 = nn.Conv2d(num_inputs, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.linear = nn.Linear(32 * 6 * 6, 512)
self._initialize_weights()
def _initialize_weights(self):
for module in self.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
nn.init.orthogonal_(module.weight, nn.init.calculate_gain('relu'))
nn.init.constant_(module.bias, 0)
def forward_conv(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.linear(x.view(x.size(0), -1))
return x
class PolicyNet(ConvBaseNet):
def __init__(self, num_inputs, num_actions):
super(PolicyNet, self).__init__(num_inputs) # num_inputs是父类需要的参数
self.actor_linear = nn.Linear(512, num_actions)
def forward(self, x):
x = self.forward_conv(x)
return F.softmax(self.actor_linear(x), dim=1)
class ValueNet(ConvBaseNet):
def __init__(self, num_inputs):
super(ValueNet, self).__init__(num_inputs)
self.critic_linear = nn.Linear(512, 1)
def forward(self, x):
x = self.forward_conv(x)
return self.critic_linear(x)GAE计算优势函数,参考了《动手学》。
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)PPO算法,参考了《动手学》。
class PPO:
''' PPO算法,采用截断方式 '''
def __init__(self, state_dim, action_dim, actor_lr, critic_lr,
lmbda, epochs, eps, gamma, device):
self.actor = PolicyNet(state_dim, action_dim).to(device)
self.critic = ValueNet(state_dim).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr)
self.gamma = gamma
self.lmbda = lmbda
self.epochs = epochs # 一条序列的数据用来训练轮数
self.eps = eps # PPO中截断范围的参数
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
td_target = rewards + self.gamma * self.critic(next_states) * (1 -
dones)
td_delta = td_target - self.critic(states)
advantage = compute_advantage(self.gamma, self.lmbda,
td_delta.cpu()).to(self.device)
old_log_probs = torch.log(self.actor(states).gather(1,
actions)).detach()
for _ in range(self.epochs):
log_probs = torch.log(self.actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps,
1 + self.eps) * advantage # 截断
actor_loss = torch.mean(-torch.min(surr1, surr2)) # PPO损失函数
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()使用PPO进行on_policy的训练,参考了《动手学》提供的rl_utils.py。输入state的形状是(batchsize,4,84,84),batchsize和步数有关。添加了save和load模型的部分(这里设定250轮后才开始保存),这样可以在上一次中断的位置继续训练。
def train_on_policy_agent(env, agent, num_episodes, save_dir, num_local_steps, resume=False,
actor_model_path=None, critic_model_path=None):
return_list = []
saved_models_info = [] # 用于记录每次保存模型时的 (episode_num, return)
start_episode = 0
# 加载指定模型
if resume:
if actor_model_path and critic_model_path:
agent.actor.load_state_dict(torch.load(actor_model_path))
agent.critic.load_state_dict(torch.load(critic_model_path))
print(f"Resumed training from provided model files:\n- Actor: {actor_model_path}\n- Critic: {critic_model_path}")
# 尝试从路径中提取 episode 编号(可选优化)
try:
start_episode = int(os.path.basename(actor_model_path).split('_')[-1].split('.')[0])
except Exception as e:
print("Warning: Failed to parse episode number from filename. Start_episode set to 0.")
start_episode = 0
else:
raise ValueError("To resume training, both actor_model_path and critic_model_path must be provided.")
for i in range(start_episode // (num_episodes // 10), 10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
current_episode_num = int(num_episodes / 10) * i + i_episode + 1
if current_episode_num <= start_episode:
pbar.update(1)
continue
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state = env.reset()
done = False
step_count = 0
while not done and step_count < num_local_steps:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
step_count = 0
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
if (current_episode_num) >= 250:
torch.save(agent.actor.state_dict(), f'{save_dir}/ppo_mario_actor_{current_episode_num}.pth')
torch.save(agent.critic.state_dict(), f'{save_dir}/ppo_mario_critic_{current_episode_num}.pth')
saved_models_info.append((current_episode_num, episode_return)) # 保存模型信息
pbar.update(1)
# 输出 return 最好的模型保存点
if saved_models_info:
best_model = max(saved_models_info, key=lambda x: x[1])
print(f"Best model saved at episode {best_model[0]} with return {best_model[1]:.3f}")
else:
print("No models were saved.")
return return_list 在得到return_list后,对returns曲线进行平滑处理,参考了《动手学》中rl_utils.py。
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))参数设置和运行。GPT说这样的参数设置没什么问题(笑哭),要真正通关可能需要训练2000~5000个episode(GPT说的)。要注意的是要设置每一轮episode最多的运行步数num_local_steps = 512,不然如果马里奥卡住的话,既没有到达终点也没有死亡,每一轮会跑很长时间。
# PPO_para
actor_lr = 1e-3
critic_lr = 1e-2
num_episodes = 500
gamma = 0.98
lmbda = 0.95
epochs = 10
eps = 0.2
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
print(device)
# env_para
world = 1
stage = 1
action_type = "simple"
# train_on_policy
save_dir = './model' # 模型保存目录
os.makedirs(save_dir, exist_ok=True)
num_local_steps = 512
resume = True # False
actor_model_path = './model/ppo_mario_actor_250.pth' # None
critic_model_path = './model/ppo_mario_critic_250.pth' # None
env= create_train_env(world, stage, action_type)
env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = PPO(state_dim, action_dim, actor_lr, critic_lr, lmbda,
epochs, eps, gamma, device)
return_list = train_on_policy_agent(env, agent, num_episodes, save_dir, num_local_steps, resume, actor_model_path, critic_model_path)
最后对绘出各个episode的returns曲线,查看训练情况和收敛情况。
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('PPO on {}'.format("SuperMarioBros-{}-{}-v3".format(world, stage)))
plt.show()
mv_return = moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('PPO on {}'.format("SuperMarioBros-{}-{}-v3".format(world, stage)))
plt.show()最后使用训练出的策略模型,放入环境进行测试。将环境可视化,观察玩游戏的效果。这里为了录gif设置了一直循环,大家可以在done或者到达最大步数时关闭窗口。
import time
def test_model(test_actor_dir, test_world, test_stage, test_num_steps):
env = create_train_env(test_world, test_stage, action_type="simple")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
actor = PolicyNet(state_dim, action_dim).to(device)
actor.load_state_dict(torch.load(test_actor_dir, map_location=device))
actor.eval()
state = env.reset()
total_reward = 0
done = False
step_count = 0
while 1:
env.render()
time.sleep(0.02)
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device) # (1, 4, 84, 84)
with torch.no_grad():
probs = actor(state_tensor)
action = torch.argmax(probs).item()
state, reward, done, info = env.step(action)
total_reward += reward
step_count += 1
if done or step_count >= test_num_steps:
state = env.reset()
step_count = 0
env.close()
print(f'Total reward: {total_reward}')
运行test,查看玩游戏的情况。
test_actor_dir = './model/ppo_mario_actor_470.pth'
test_world = 1
test_stage = 1
test_num_steps = 200
test_model(test_actor_dir, test_world, test_stage, test_num_steps)
三、结果
训练时process_bar的效果如图所示

由于在本地训练过于费时(如果每个episode跑满512步),没有得到return曲线(轻薄本3050已经燃尽了)。一是训练效果不是很好,详细说明见讨论部分。二是从process_bar也可以看到,因为探索的原因,马里奥很容易死亡或卡住,return并不是很稳定,return曲线在本例中没太大意义,最后通关才是目标。
最后test得到马里奥运行的可视化结果
下图为训练250个episode得到的效果,可以看到马里奥能越过一些障碍。但在柱子的位置卡住。
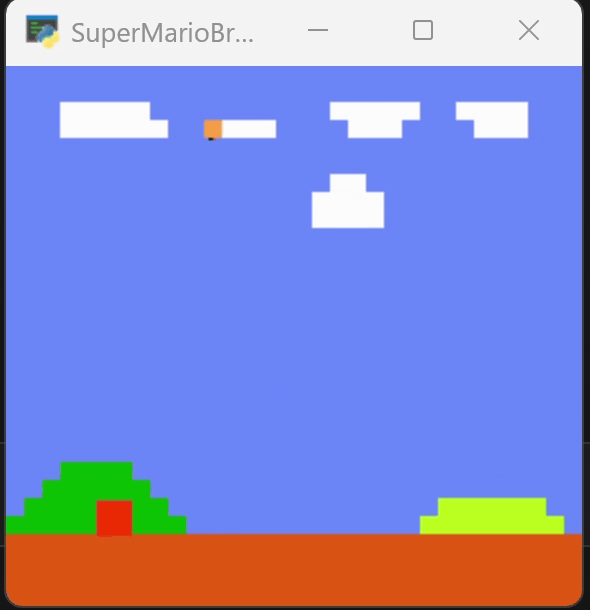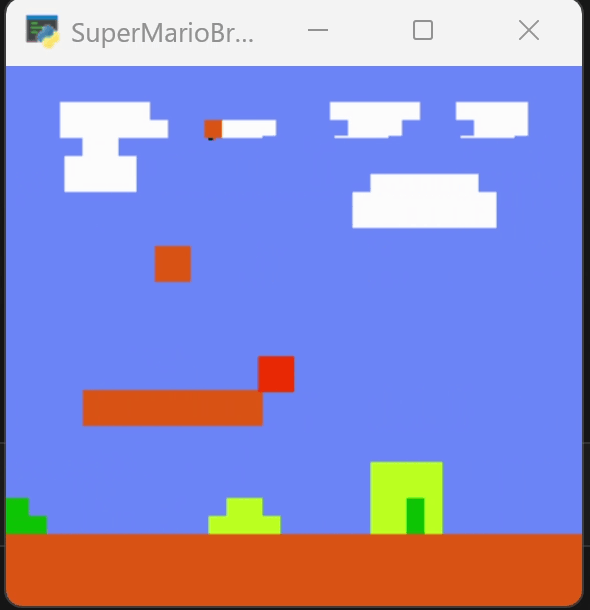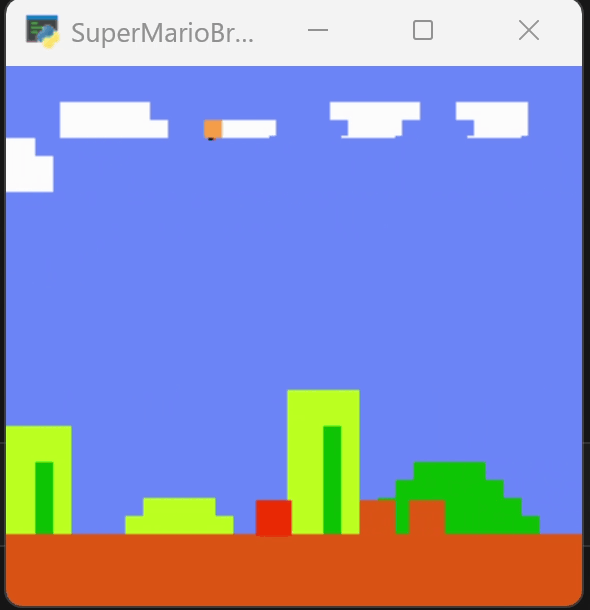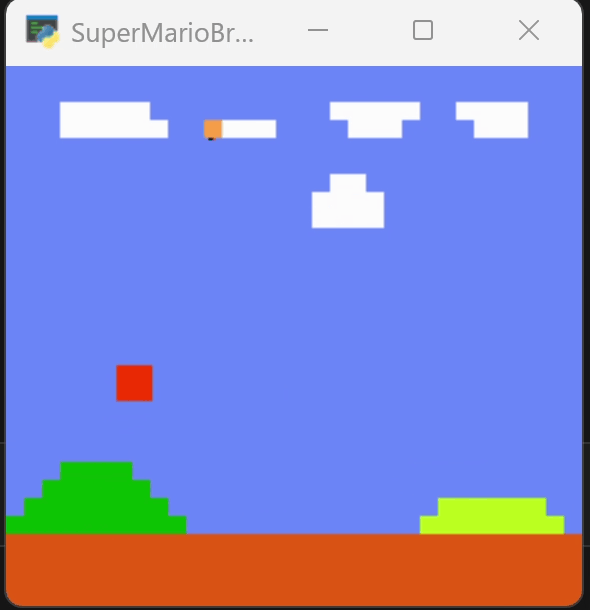
为了尝试跳过障碍,我增加了对跳跃动作的奖励,在250轮的模型上继续训练到400轮,效果如下图。它改变了行动的路径,但仍然在柱子处卡住。
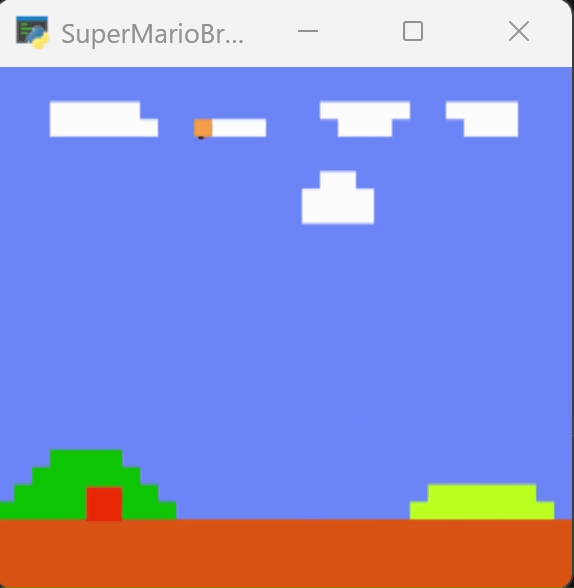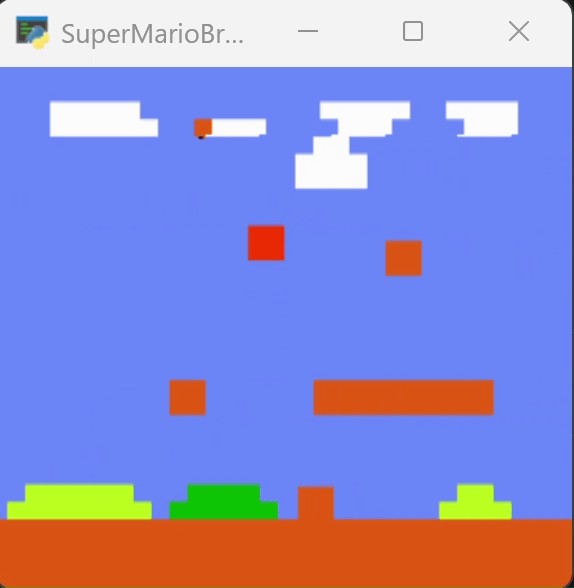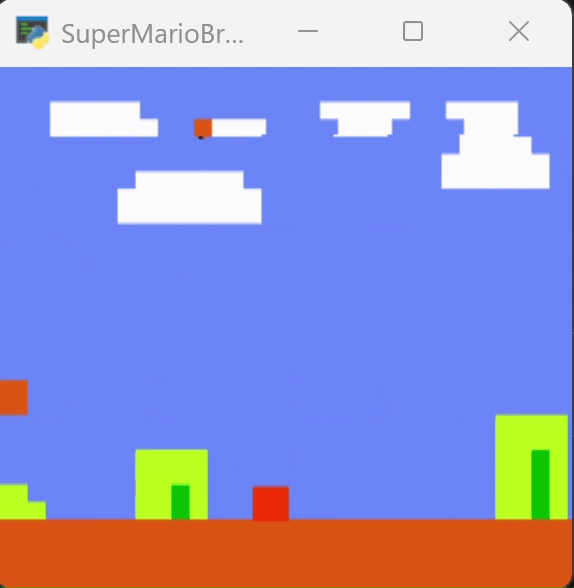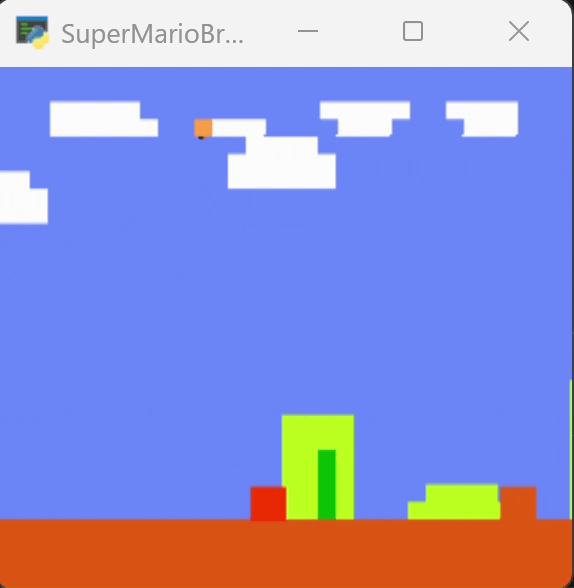
四、一些讨论
首先是马里奥在柱子的位置卡住的问题
一些可能的原因:
1.它不能两连跳(甚至在第二个gif,不能跳过矮的障碍),在障碍前不能执行跳跃动作(环境本身有问题?),可能是帧处理合并的帧数太多(我也尝试了减少skip,效果也不理想),导致不能很精细地执行动作。
2.训练轮数不足(理论上只要训练足够长时间,一定能找到通关的策略),但在训练过程中容易发现它可能在连续几百轮的训练中都选择了同一策略,这样感觉上对寻找更优的策略不是很有帮助。
3.对环境的reward设置不合理。
改进
在恰当的版本,使用现成的库是更好的选择。SB3能提供更好的包装器和算法。
另外华为的教程中的代码是在华为云上运行的,选择在服务器上运行也比在本地更好。
一些感受
在之前学习RL理论时,更多是在学习算法。但在实战中更多考虑的是其他的细节,对环境的设置、参数设置、调试、可视化等等。
在《动手学》中一直有提及,强化学习算法对超参数设置不太敏感。虽然说强化学习算法的理论比较严谨,但在实践中仍有不好解释的部分,需要大量的调试。至少在这个demo中,我感觉最终结果的好坏很大程度上取决于环境的理解程度。
学习经验
最后附上我入门强化学习的的经历
1.理论基础:《强化学习的数学原理》赵世钰,以及赵老师的网课,适合理论的入门。
2.算法和代码:《动手学强化学习》。代码写得非常清晰,可能数学理论比较略,我同时结合了算法对应的论文进行学习。
代码和模型
最后附上jupyter notebook格式的代码,和训练出的模型
https://github.com/Alpha1st/RL-supermario/
刚入门强化学习不久,还请大佬们多多指教。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)