
深度学习之YOLO目标检测(2):数据标注&json文件转化&yolov3配置
接上文YOLOv3。
目录
接上文,YOLOv3
使用yolo进行目标检测,收集数据集之后我们还要对数据集进行标注得到json文件,然后转化为txt文件。
一、数据标注
1.标注工具的下载
数据标注所需要的工具:下载以下第三方库

第三方库下载过程中可能会出现一些问题,比如labelme回车不能启动。
不能启动的同时会给出错误理由,可以根据大模型自行解决。
2.标注工具的使用
输入回车后弹出一个窗口
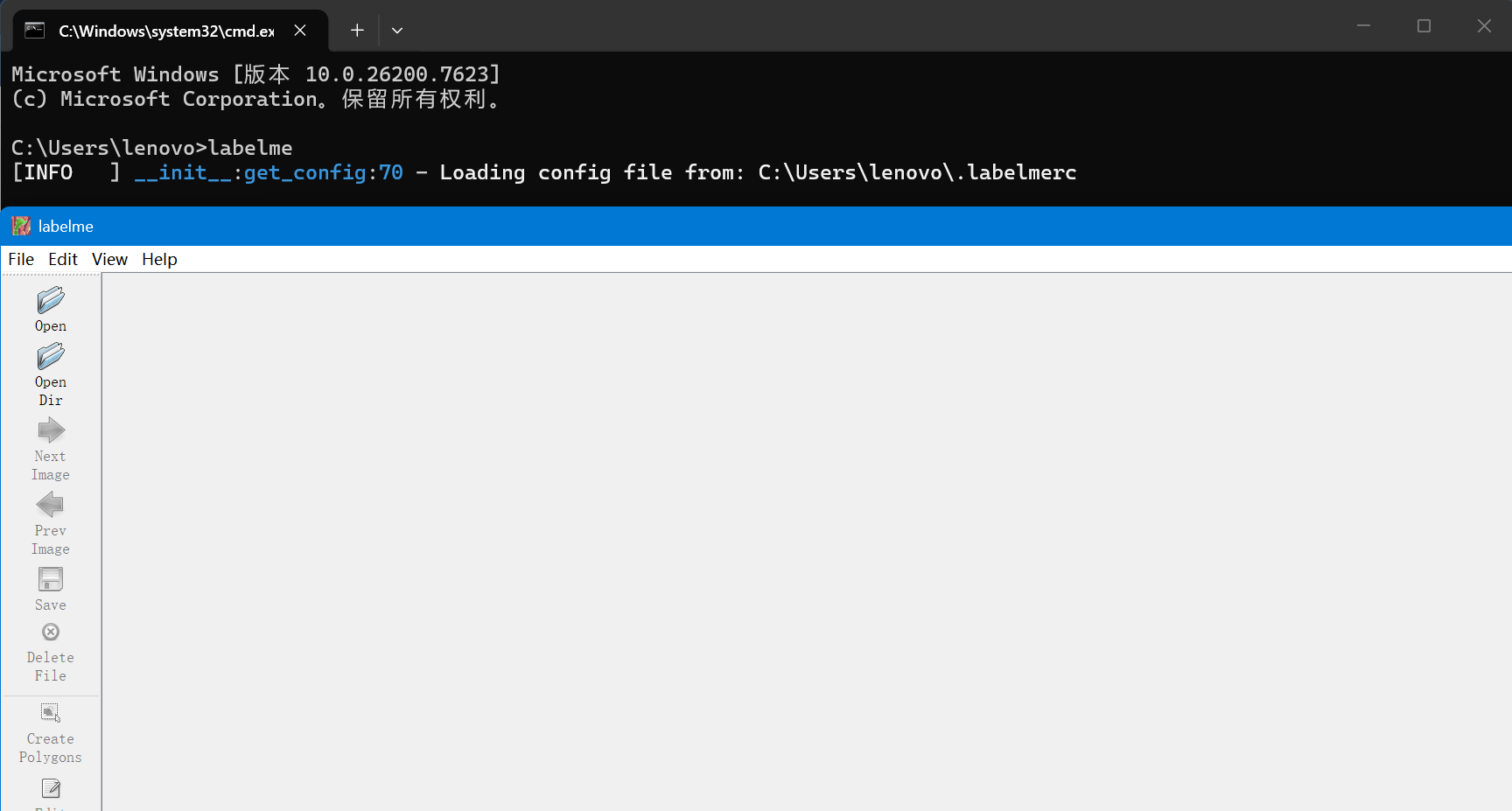
这个窗口就是我们进行图片数据标注的界面。
如果我们要进行一个猫狗检测的项目,收集了很多猫狗的图片那么就要对数据集图片进行猫狗的标注。
点击open打开图片,就会显示我们所点击的图片。就可以进行数据标注了
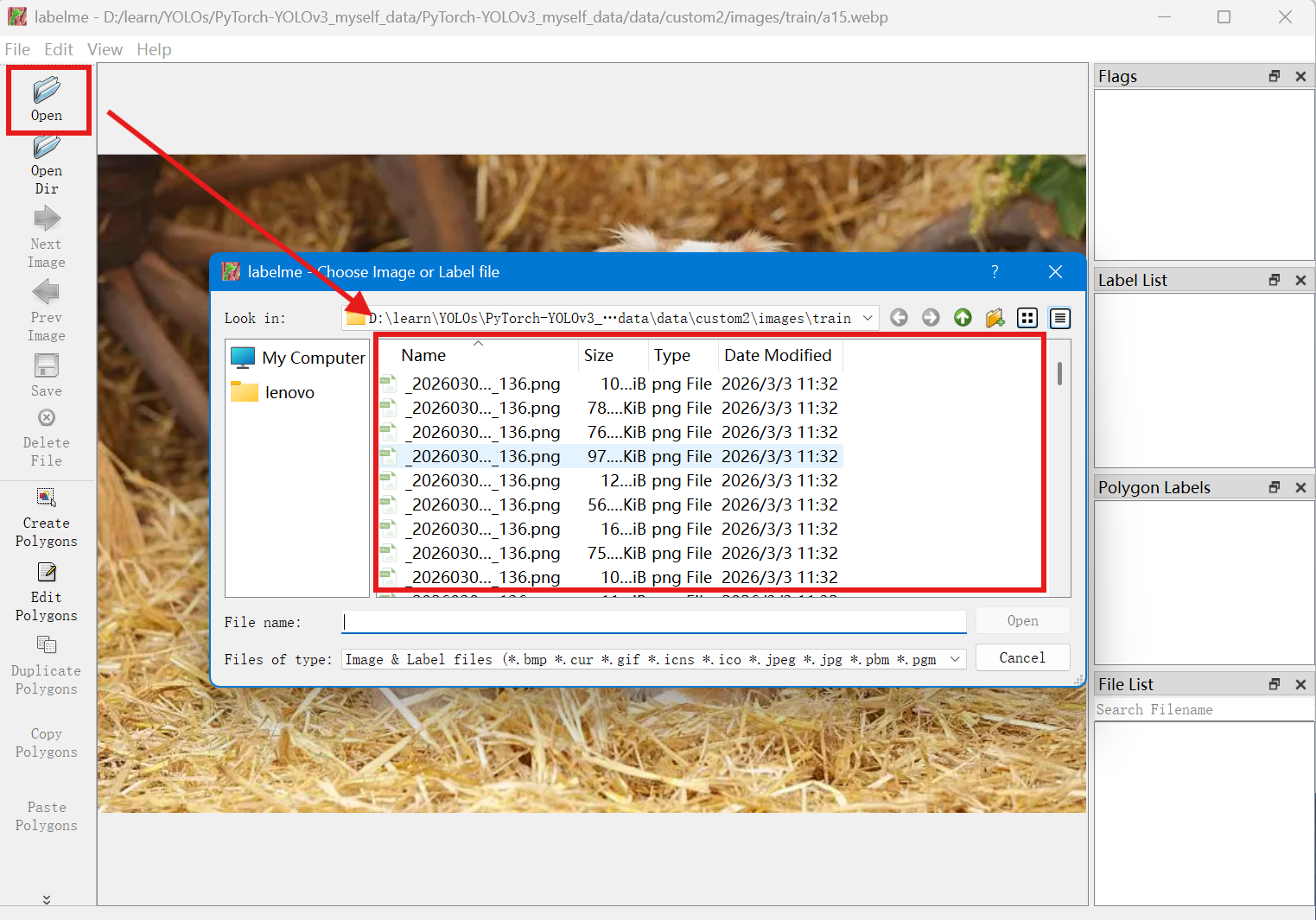
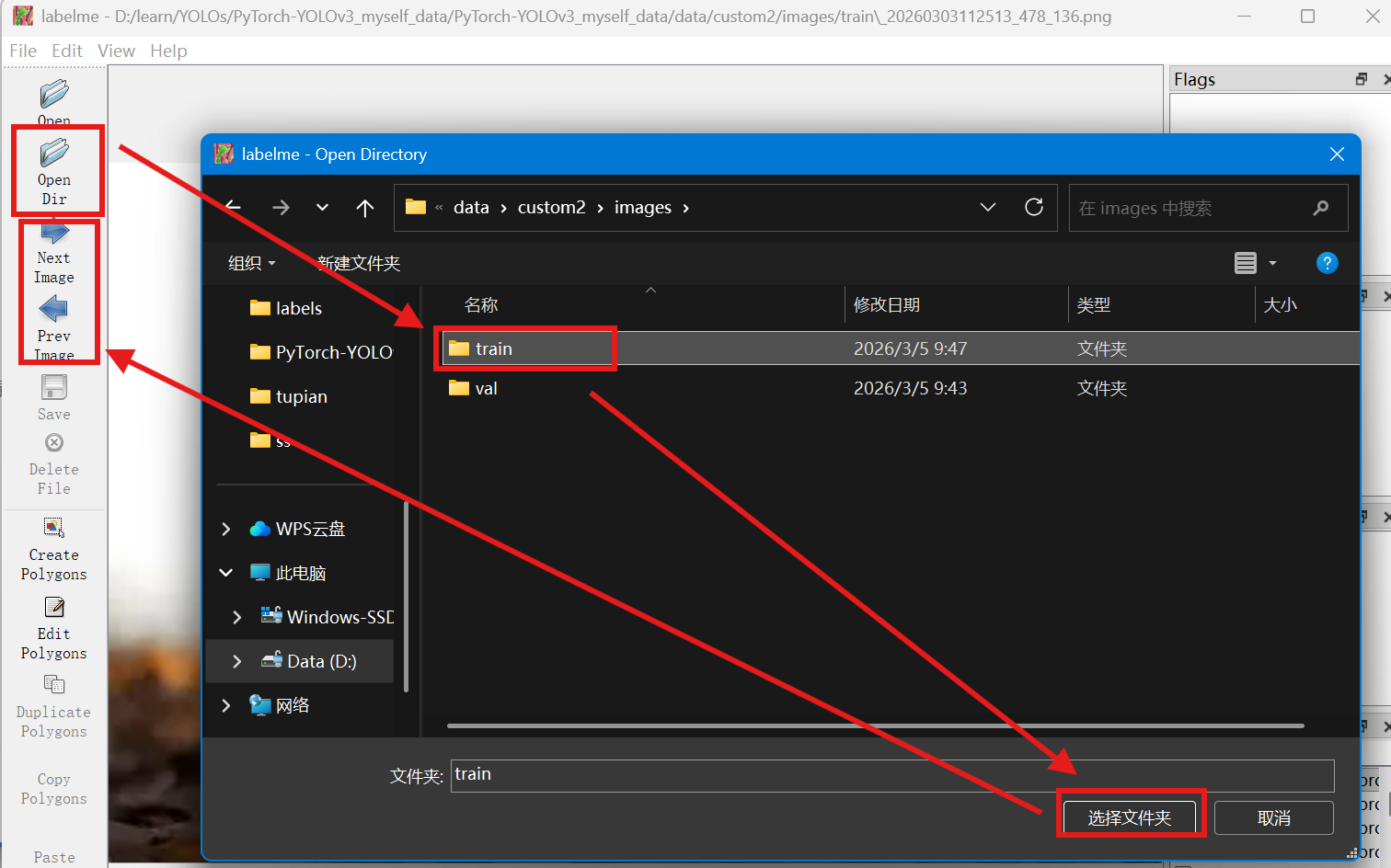
但一般情况下进行数据标注是需要标注很多图片。点开opendir就可以选择含有数据的文件夹,会自动读取到所有图片文件,箭头可以切换到上一张或者下一张图片。
右击图片会有选项,不同选项对应着标注使用不同的框,可以自行尝试
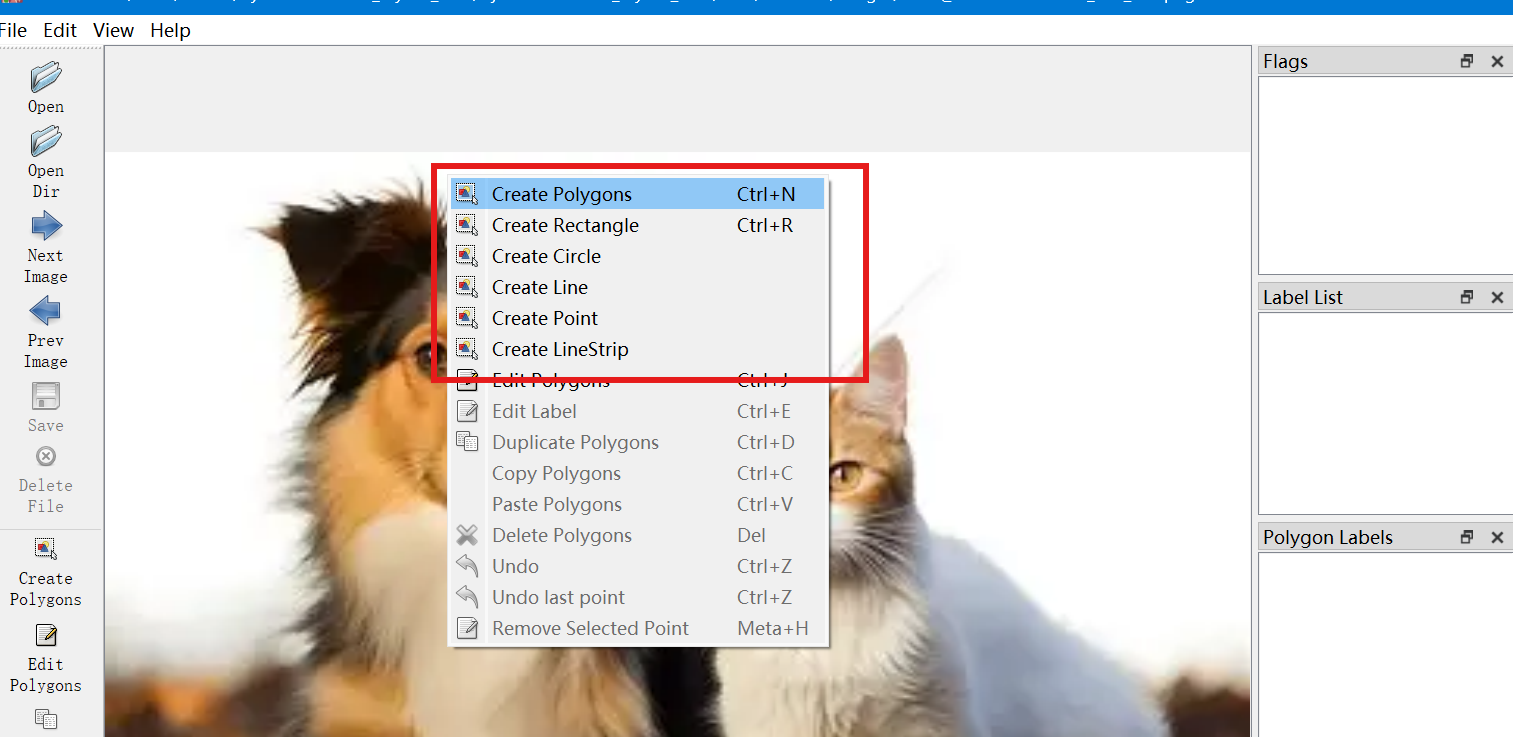
我们选择适合本次标注的框,rectangle,矩形框。输入该标注的类别,也就是dog点击确定,同样也标注上cat
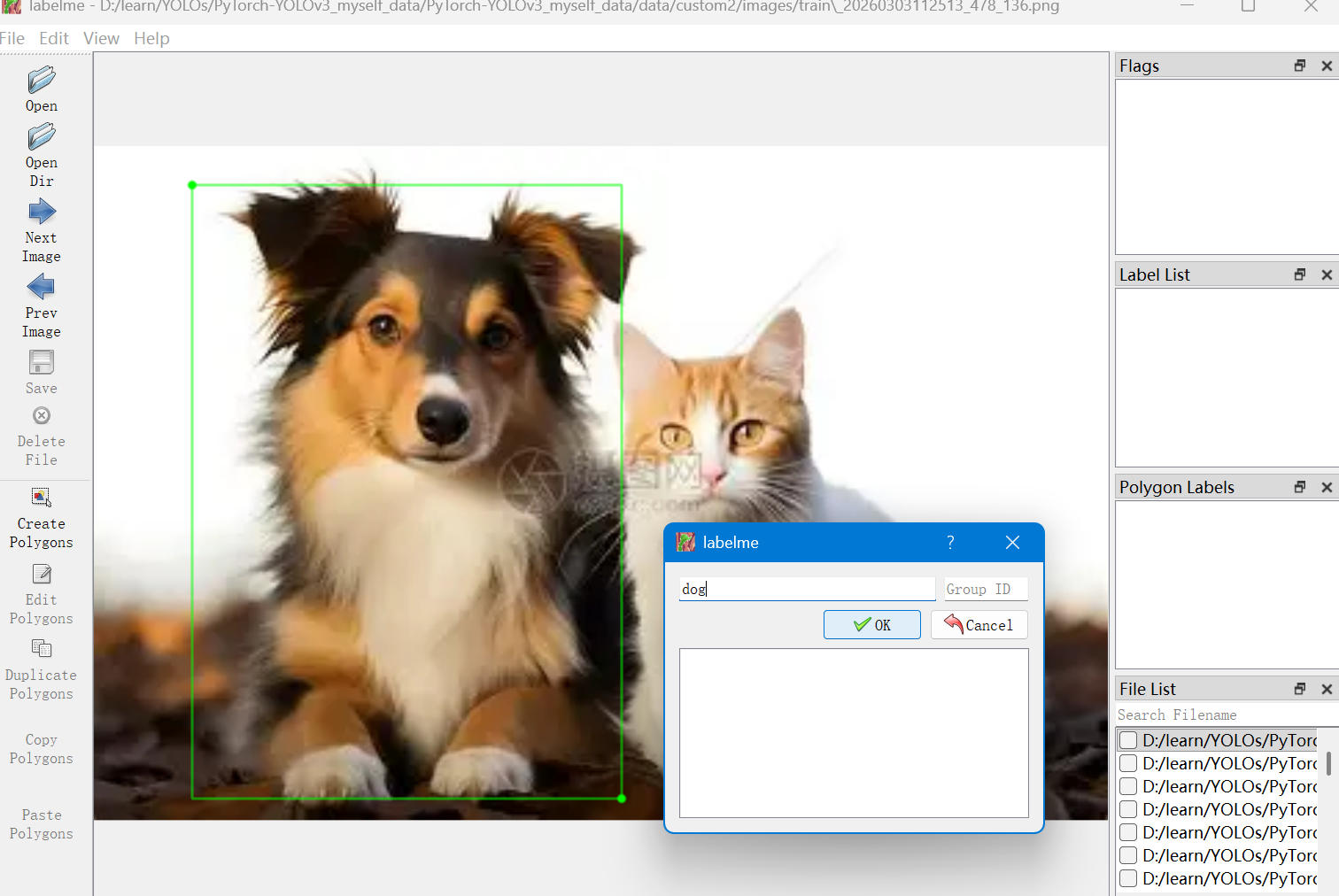
标注完之后可以把标注好的信息保存在自定义的文件夹下
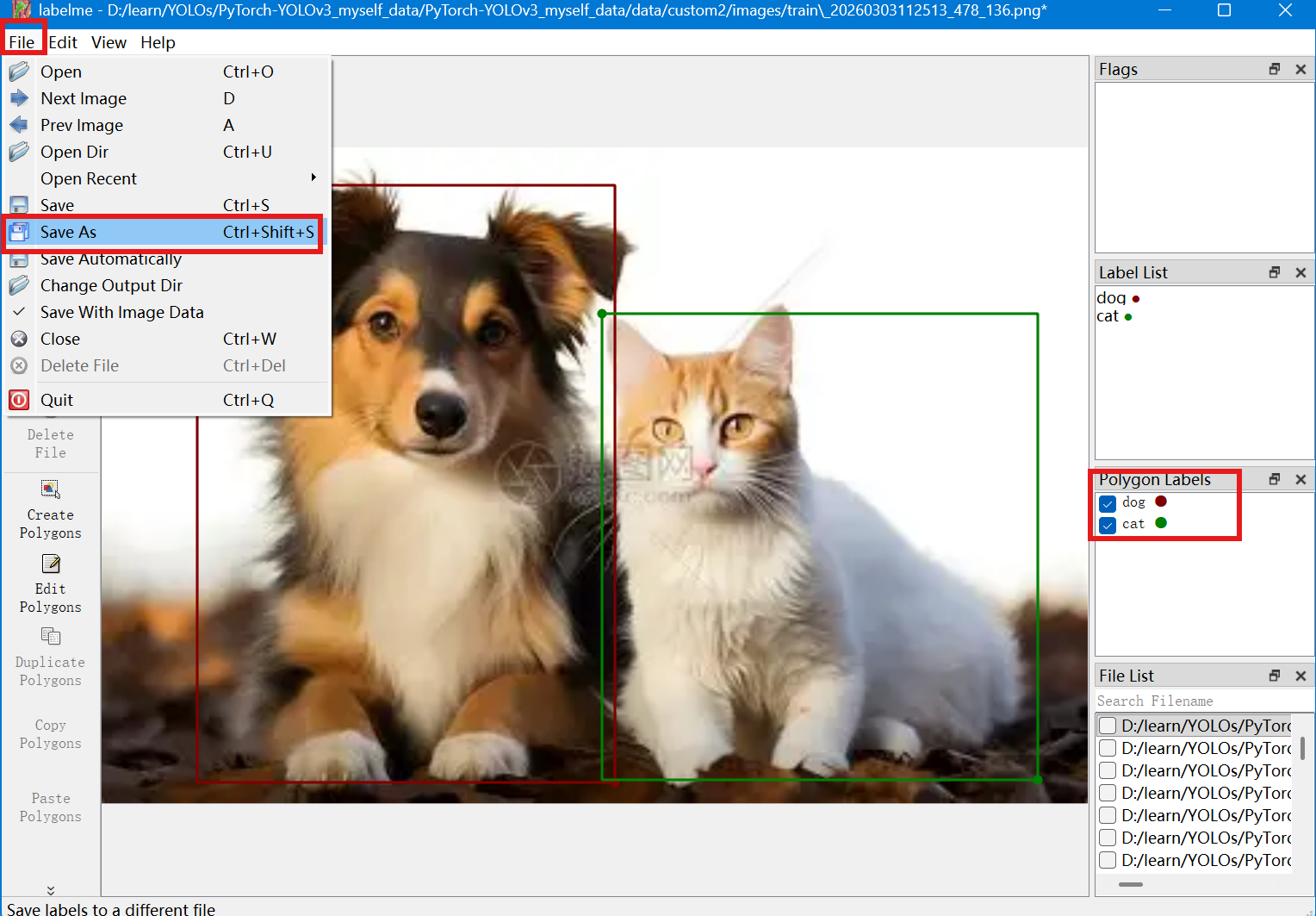
就会得到json为后缀的文件,进行训练的时候我们需要的是txt文件,所以还需要把json文件转化为txt文件
二、json转化为txt
转化代码:
1.首先要注意类别,在标注的时候会有label list。顺序不能混乱,要对应。
例如: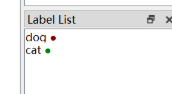
2.txtname中的txt保存路径需要修改为自己的,也就是我们转化的txt文件所在的文件夹
3.标注的时候我们使用的是rectangle,所以shape_type要对应
4.主程序中json_floder_path是我们存放json文件的文件夹
import json
import os
name2id = { 'dog':0, 'cat':1}#有多少个类别,在字典中就写多少个对应的就可以
def convert(img_size, box):
dw = 1./ (img_size[0])
dh = 1./(img_size[1])
x = (box[0] + box[2])/2.0 - 1
y = (box[1] + box[3])/2.0 - 1
w = box[2]- box[0]
h = box[3] - box[1]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def decode_json(json_floder_path,json_name ) :
#转换好的标签路径,建议保存在data\custom\labels中
# txt_name = r'data\\custom2\\labels\\' + json_name[0:-5] + '.txt'
txt_name = r'data\\custom2\\labels\\' + json_name[0:-5] + '.txt'
txt_file = open(txt_name,'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r'))
img_w = data[ 'imageWidth' ]
img_h = data[ 'imageHeight' ]
for i in data[ 'shapes']:
label_name = i['label']
if ( i['shape_type' ] == 'rectangle' ):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1,y1,x2,y2)
bbox = convert((img_w,img_h),bb)
txt_file.write(str(name2id[label_name]) + " " +" ".join([str(a) for a in bbox]) + '\n')
txt_file.close()
if __name__ == "__main__" :
json_floder_path = './label2'
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path,json_name)yolo目标检测所需要的就是图片数据集合对应的txt文件。
三、YOLOv3的改进
yolov3的网络结构有很大的改进,v2时所用的是darknet19,而到v3的时候darknet53+残差结构residual,物体检测更精确。
YOLOv3 核心进步:多尺度检测 + 更深网络,彻底解决了 v1/v2 小物体差、精度低的问题;
YOLOv3 最大短板:速度牺牲、算力需求高,定位精度和超小物体检测仍有优化空间;
它是YOLO 系列的里程碑,奠定了后面所有 YOLO 版本的基础架构。
四、YOLOv3的相关配置的修改
例:猫狗目标检测训练
yolo是一个框架,可以在github网站内下载v3,文件:PyTorch-YOLOv3_myself_data.rar
链接: https://pan.baidu.com/s/1mqwMkiFEXfmrDUcKs4IToA?pwd=r7j8 提取码: r7j8
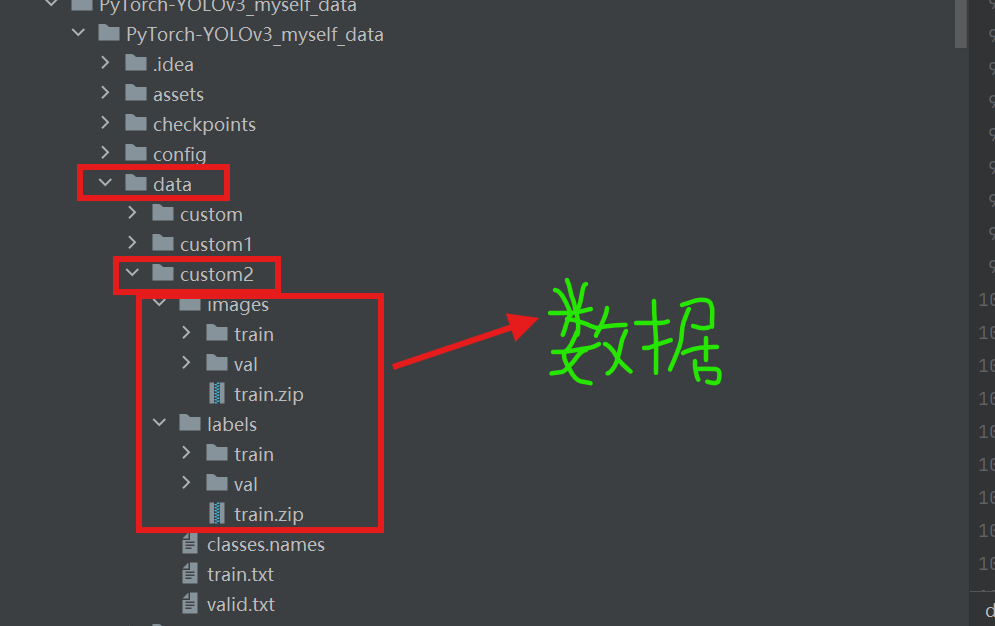
1.数据
把图片放在data文件下下自建 的custom2文件夹。images是图片,train是训练集图片,val是验证集图片;labels用来存放生成的txt文件train是训练集txt,val是验证集txt
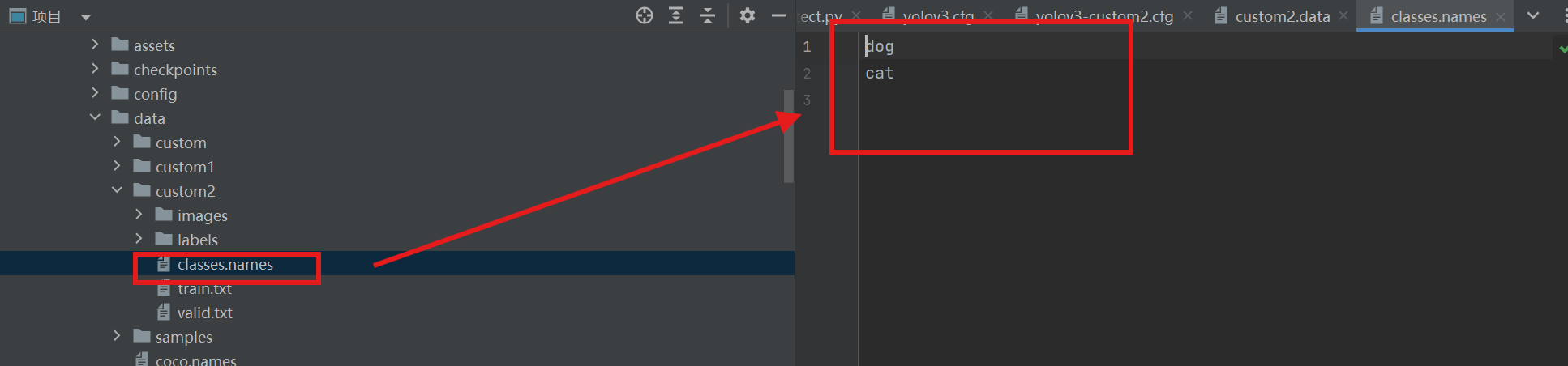
2.classes.names文件的创建
在data文件夹custom2下,和images和labels同级创建一个文本文件,编辑我们类别的标签,顺序严格对应,输入最后一个类别之后一定要回车留出空白一行
此外我们需要把训练集和测试集图片的路径生成文本,也就是这里的train.txt和valid.txt,注意路径中不要有中文。
图片的格式会有很多种,比如jpg,png等,这些情况都要考虑到
import os
# 把这里改成你的图片文件夹路径!
image_dir = r"D:\learn\YOLOs\PyTorch-YOLOv3_myself_data\PyTorch-YOLOv3_myself_data\data\custom2\images\val"#train
# 保存的 train.txt 会生成在 代码所在文件夹
save_txt = r"D:\learn\YOLOs\PyTorch-YOLOv3_myself_data\PyTorch-YOLOv3_myself_data\data\custom2\valid.txt"#train
# 支持的图片格式(你可以自己加)
img_suffix = [".jpg", ".jpeg", ".png", ".bmp", ".webp"]
with open(save_txt, "w", encoding="utf-8") as f:
# 遍历文件夹里所有文件
for filename in os.listdir(image_dir):
# 判断是不是图片
if any(filename.endswith(suf) for suf in img_suffix):
# 拼接完整路径
img_path = os.path.join(image_dir, filename)
# 写入 txt
f.write(img_path + "\n")
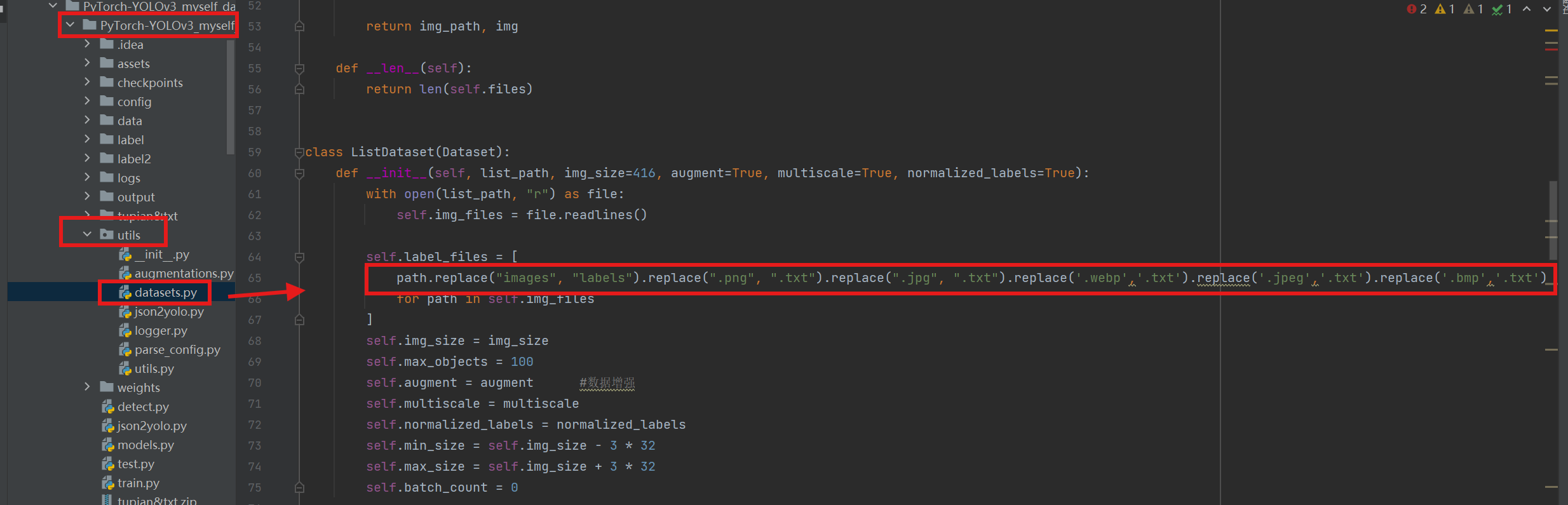
print(f"生成成功! 已保存,共 {len(os.listdir(image_dir))} 张图片")如果我们收集的图片中有各种格式,还需要改一处代码
找到utils文件夹中的dataset.py文件,找到对应代码行,把所有图片文件格式全部都添加上以防后续图片格式不同而出错。
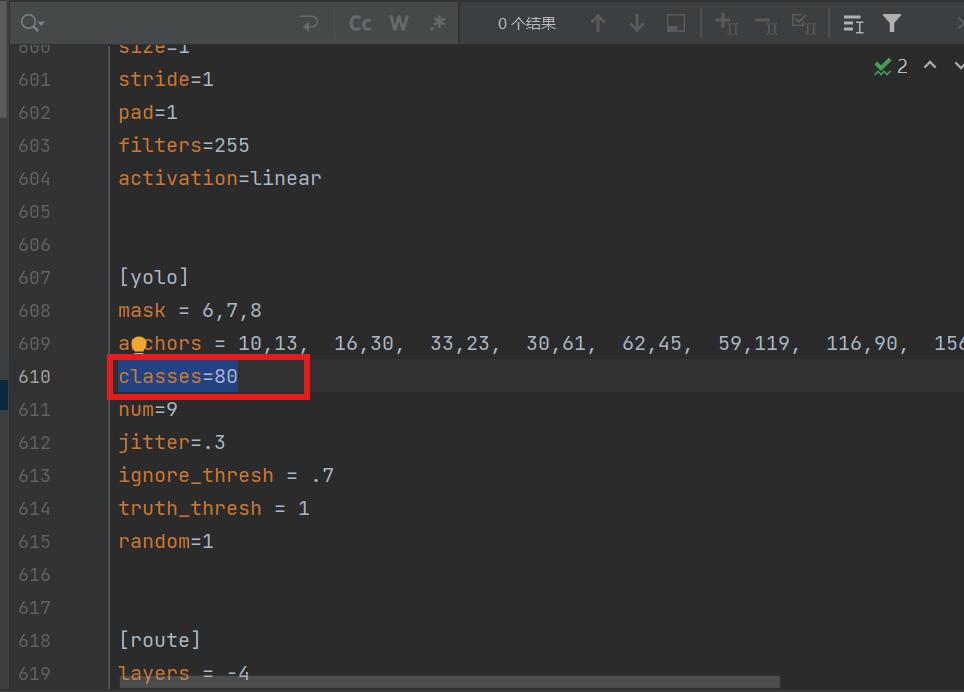
3.config中的yolo文件配置信息
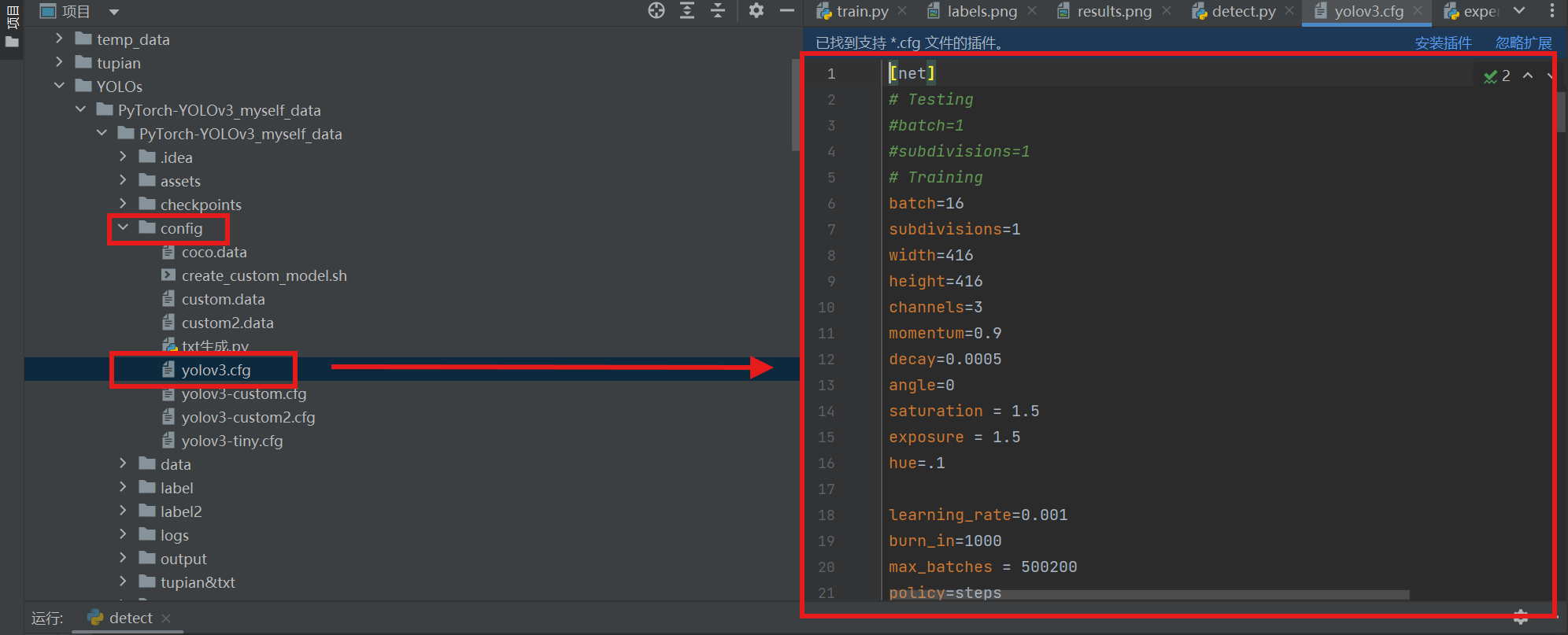
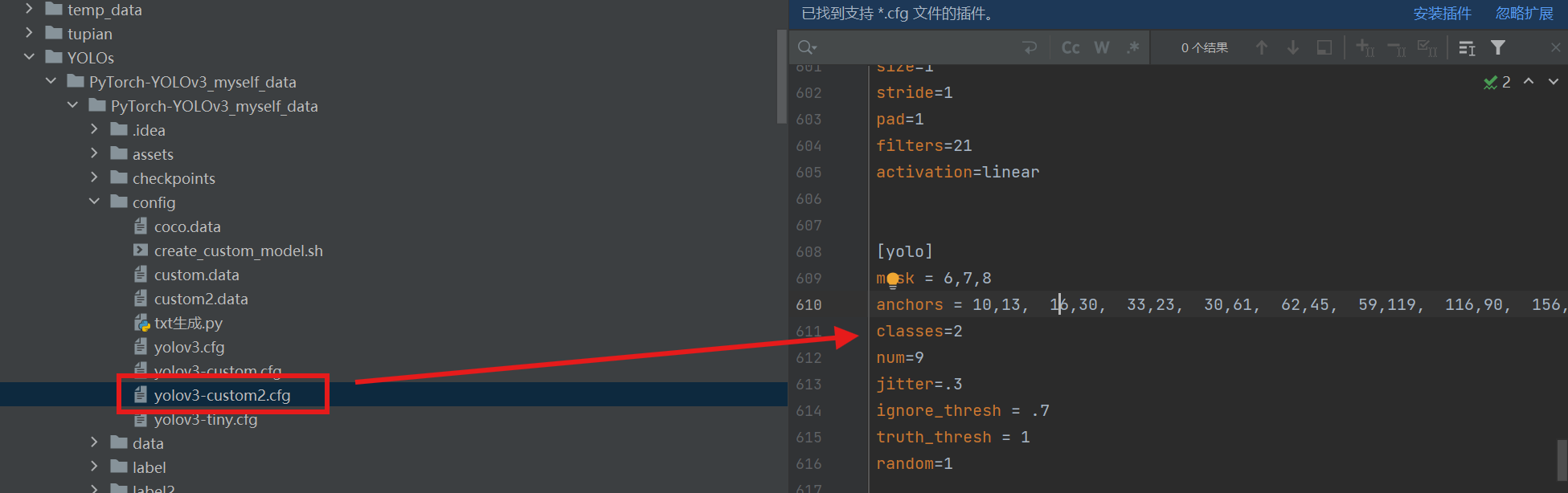
找到三层yolo层,把类别这里改成我们项目的类别个数,这里是猫狗目标检测,那么就为2。可以不修改这个原yolo文件复制一份修改
4.config中coco文件配置信息
在config文件下有一个coco文件,同样可以先复制一份自定义文件名
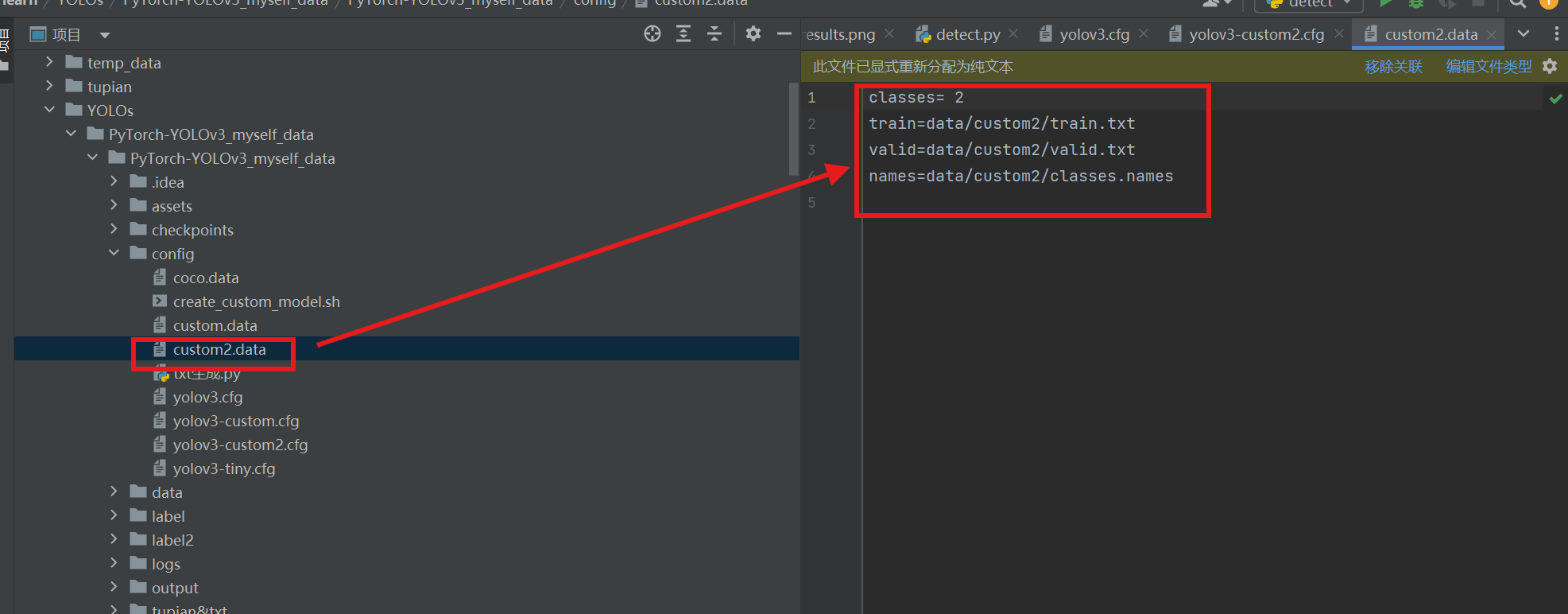
custom2就是我自定义的文件名,这个文件里面写的是类别个数,图片数据集的路径,以及classes.names文件的路径
5.配置训练参数
打开train.py文件右击配置参数,这里根据自己的路径进行修改。
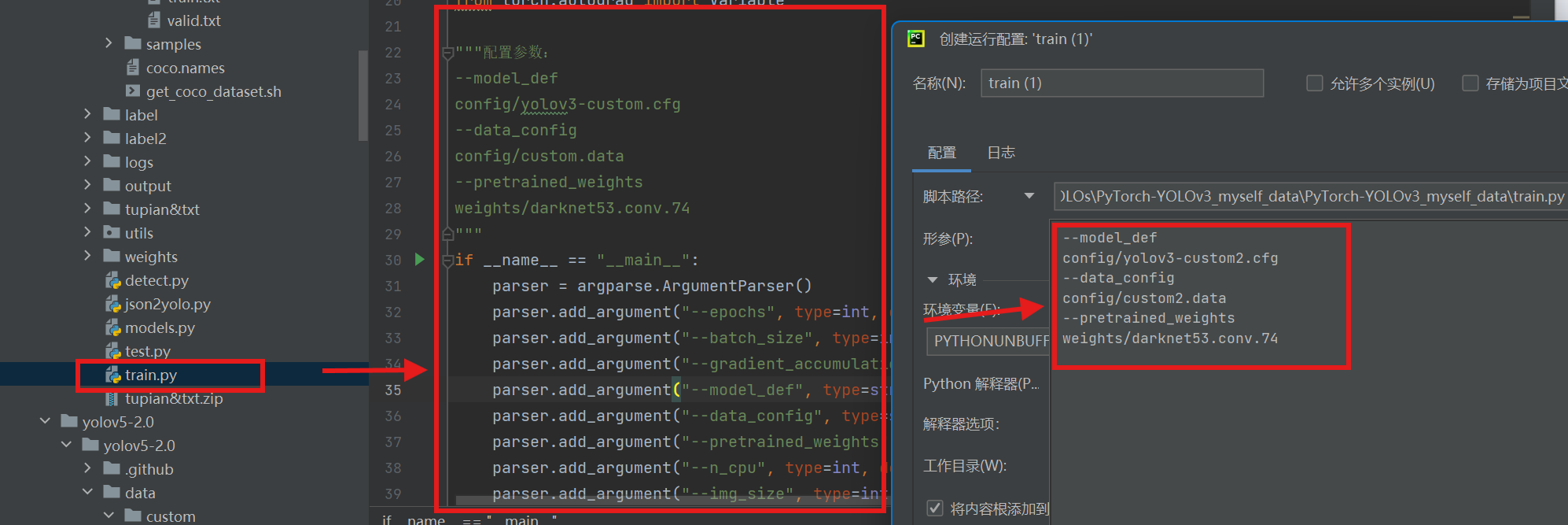
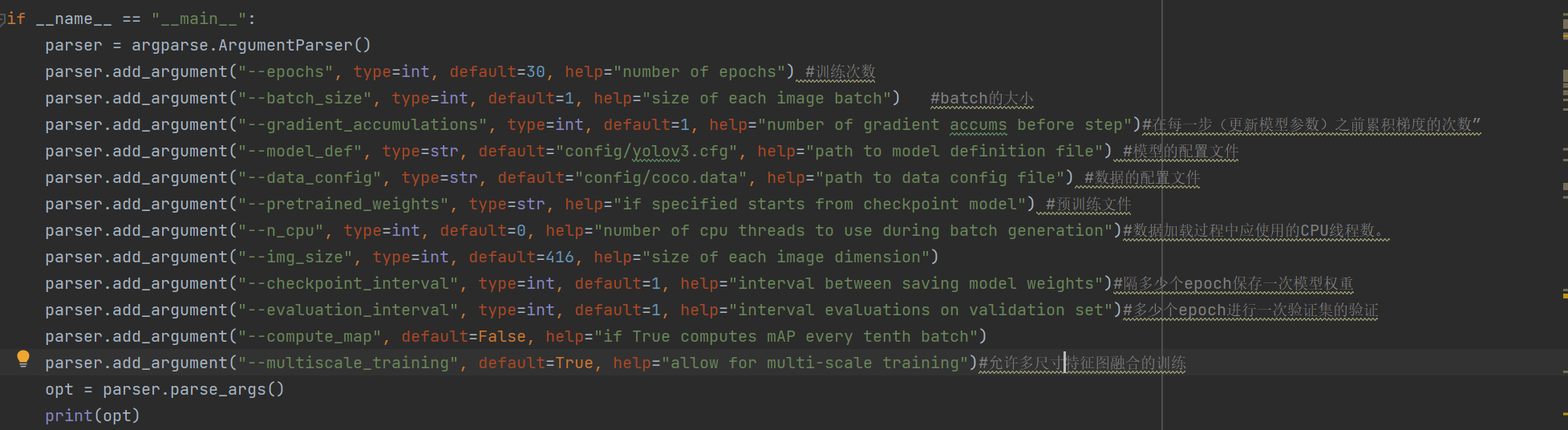
全部的参数及参数含义
6.其他
checkpoints中是我们训练每一轮的数据
weights是权重文件,在配置训练文件参数时可设置
detect.py是检测识别,也需要配置相关参数
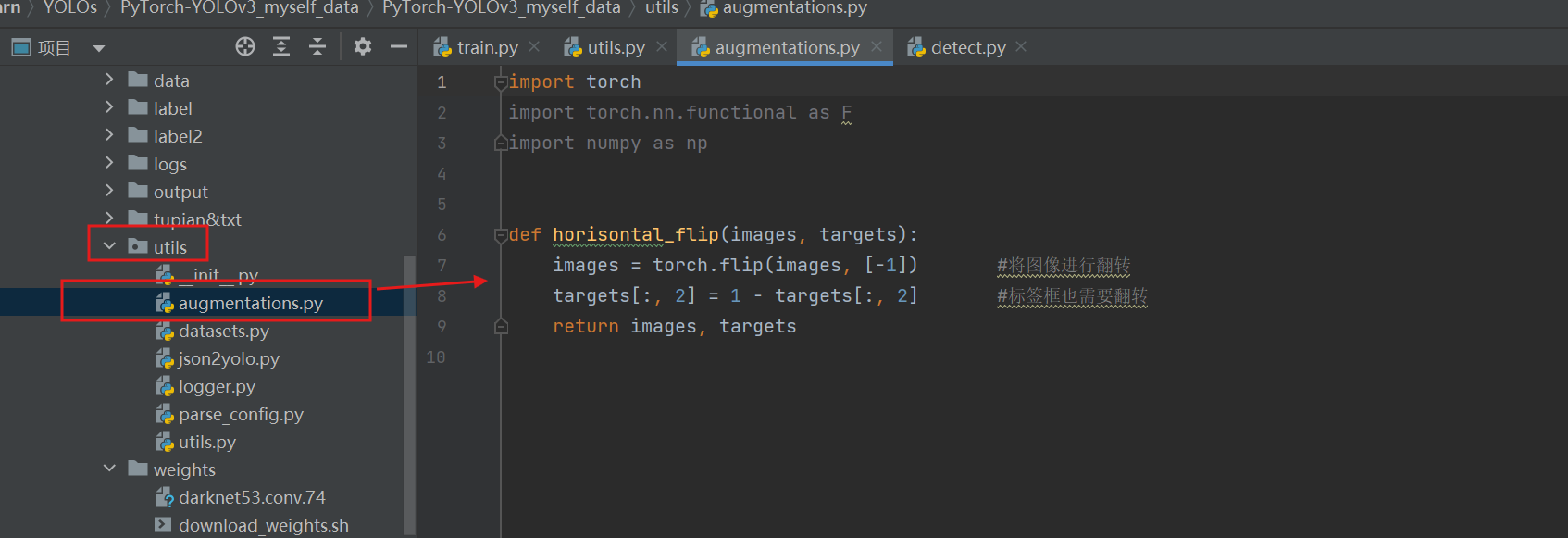
v3没有数据增强,所以这个文件里面只有一个图片翻转
除了以上操作,还会出现其他我们需要解决的问题,比如说第三方库的安装,都会遇到问题,可以结合大模型自行解决。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)