
Python----深度学习(神经网络的可解释性与欠拟合)
神经网络的可解释性是指神经网络中每个决策或预测的可解释性。神经网络是一种黑 箱模型,其决策或预测的结果往往难以解释。因此,可解释性是神经网络中的一个重 要问题,它可以帮助我们理解神经网络的行为,发现网络中的问题,并提高网络的可 靠性和可信度。通过可解释性分析,可以更好地理解神经网络的行为,发现网络中的问题,改进网络 的性能和可靠性。同时,可解释性分析还可以帮助建立用户可信的神经网络系统,提 高用户
一、神经网络的可解释性
神经网络的可解释性是指神经网络中每个决策或预测的可解释性。神经网络是一种黑 箱模型,其决策或预测的结果往往难以解释。因此,可解释性是神经网络中的一个重 要问题,它可以帮助我们理解神经网络的行为,发现网络中的问题,并提高网络的可 靠性和可信度。
通过可解释性分析,可以更好地理解神经网络的行为,发现网络中的问题,改进网络 的性能和可靠性。同时,可解释性分析还可以帮助建立用户可信的神经网络系统,提 高用户对系统的信任度。
为了提高神经网络的可解释性,人们通常采用以下方法:
添加全连接层:在神经网络的输出层之前添加一个全连接层,可以解释神经网络 的决策过程。
添加Dropout层:通过随机失活神经元来避免过拟合,同时也可以增加神经网络 的可解释性。
添加归一化层:通过归一化处理,可以消除神经元之间的相关性和避免梯度消失 问题,同时也可以增加神经网络的可解释性。
添加注意力机制:注意力机制可以让神经网络更加关注与预测相关的的重要特 征,从而增加神经网络的可解释性。
神经网络的可解释性对于其应用非常重要,只有具有可解释性的神经网络才能让人们 更加信任其预测结果,并且更容易被应用。
二、欠拟合
欠拟合是指模型在训练集上无法很好地拟合数据的情况。在欠拟合的情况下,模型无 法捕捉到数据中的复杂关系和模式,导致训练误差和测试误差都较高。
造成欠拟合的原因通常有以下几个:
1. 数据量不足:当训练数据量较少时,模型无法从中学习到足够的特征和模式,从 而导致预测结果误差较大。
2. 模型过于简单:如果模型过于简单,无法充分描述数据,也会导致欠拟合。例 如,对于一个复杂的问题,使用一个过于简单的模型可能会忽略一些重要的细节 和特征,从而导致预测结果误差较大。
3. 正则化强度过大:过强的正则化可能会使得模型过于简单,无法充分描述数据, 导致欠拟合。后面的章节会介绍正则化的概念。
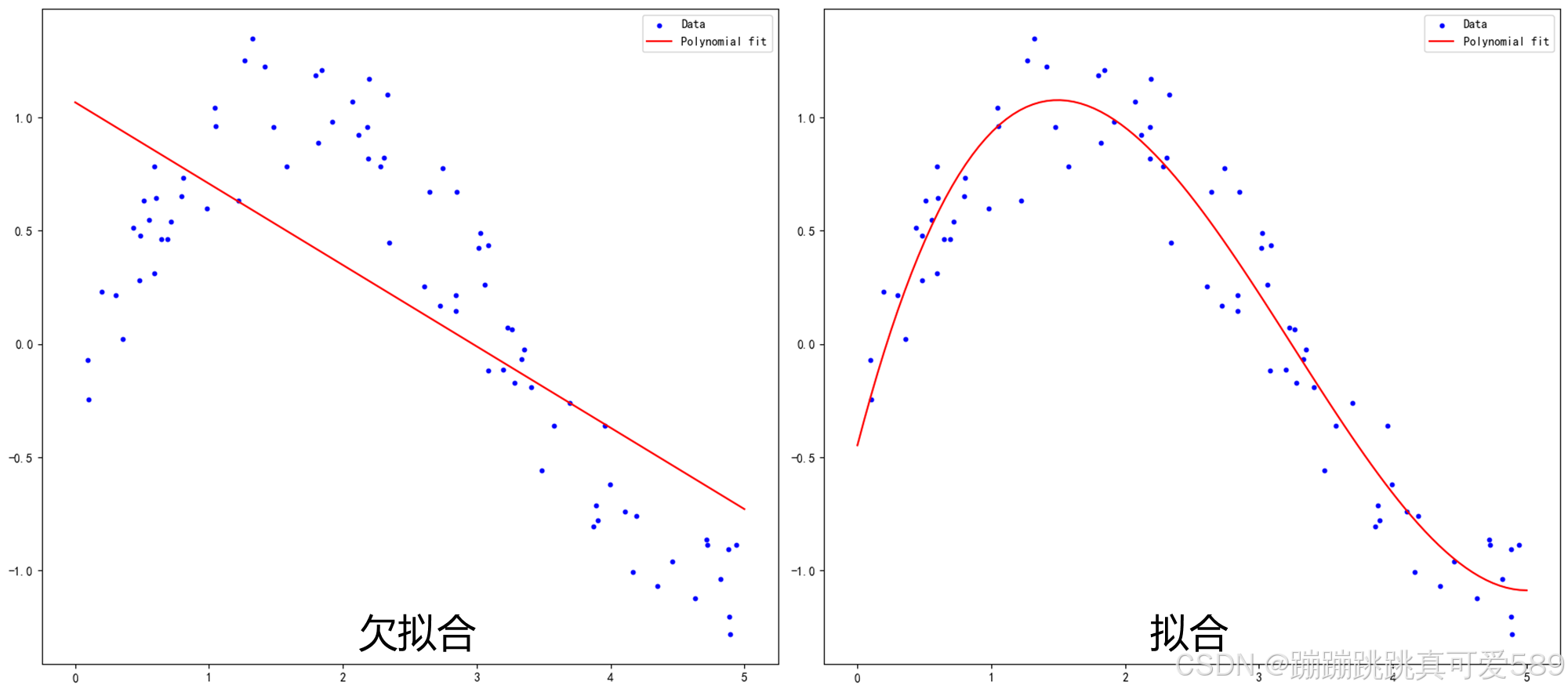
欠拟合的情况比较容易克服,常见解决方法有:
1. 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间
2. 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强
3. 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数
4. 使用非线性模型,比如核SVM 、决策树、深度学习等模型
5. 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力
6. 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging
三、设计思路
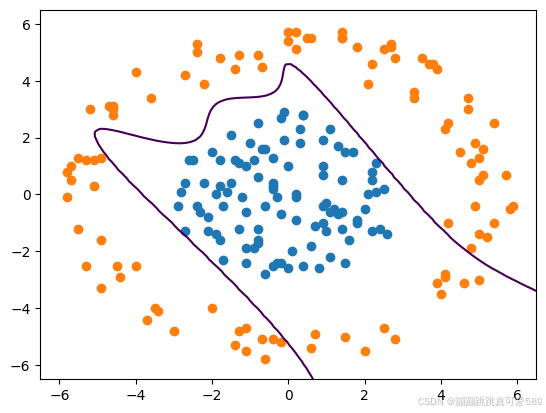
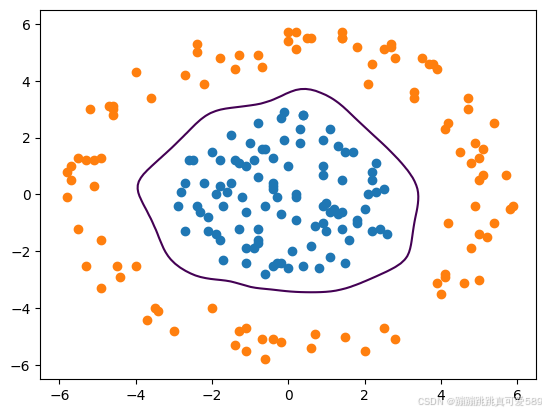
输入数据
import numpy as np
class1_points = np.array([[-2.8, 0.1], [0.4, 2.8], [-0.1, 1.9], [-2.0, 1.5], [-0.4, 0.4], [2.1, -0.0],
[-0.8, 0.6], [0.4, -2.5], [0.1, -2.0], [-0.6, 1.6], [-1.5, 2.1], [-0.9, 1.2],
[1.3, 1.7], [0.2, -0.0], [0.2, -0.1], [-2.1, -0.8], [-0.7, 1.6], [1.4, -1.2],
[-0.8, -1.6], [-1.3, 1.1], [-1.2, -0.1], [-2.9, -0.4], [2.4, -1.2], [-2.7, -1.3],
[-1.1, -1.9], [1.4, 0.5], [-1.0, 1.8], [2.2, 0.8], [0.9, 1.9], [1.8, -0.9],
[1.4, -0.6], [-0.2, -0.7], [-0.3, -2.4], [-1.5, 0.4], [1.2, -0.5], [-1.8, 1.2],
[-0.8, -1.7], [-1.7, -2.3], [-0.6, -0.4], [0.3, 1.8], [-0.9, -1.9], [1.6, -1.6],
[0.8, -2.6], [-2.6, 1.2], [1.8, -1.0], [0.2, -0.9], [-0.4, -2.5], [1.5, 1.5],
[2.2, -1.3], [-1.4, 1.2], [-0.4, 1.3], [-1.3, -1.2], [-2.2, 0.4], [-0.1, 2.9],
[1.5, -2.4], [1.1, 2.3], [0.4, 2.8], [-0.8, -1.2], [-2.7, 0.4], [2.3, 1.1],
[0.9, 1.0], [0.9, 0.7], [-1.8, 0.3], [-1.7, -0.4], [1.0, -0.3], [-1.1, -0.6],
[-2.4, -0.4], [2.6, -1.4], [1.3, -0.7], [-0.0, 1.0], [-1.1, -2.4], [2.0, -0.5],
[0.3, 2.3], [-0.6, -2.8], [0.6, -1.8], [0.9, -0.4], [1.0, -1.3], [-0.4, 0.2],
[2.3, 0.1], [2.2, 0.5], [2.5, 0.2], [-2.1, -1.3], [-1.1, 1.0], [1.7, 1.5],
[0.9, -1.0], [1.1, -2.2], [-0.2, -2.4], [0.7, -1.1], [-0.4, 0.3], [-0.0, -2.6],
[-0.3, -0.1], [-1.8, -1.6], [-0.8, 2.5], [-1.9, -1.4], [-2.5, 1.2], [-2.3, -0.6],
[-1.6, 0.1], [-1.9, 0.0], [1.1, -0.6], [-0.2, 2.7]])
class2_points = np.array([[5.1, 1.6], [-5.1, 1.2], [-4.6, 3.0], [-5.7, 0.5], [5.4, 2.5], [-4.5, -2.5],
[4.9, -0.4], [1.4, 5.5], [1.4, 5.7], [4.2, -1.0], [-1.3, -4.8], [-4.4, -2.9],
[-3.6, 3.4], [-3.4, -4.1], [-5.8, -0.1], [4.7, 3.0], [-1.4, 4.4], [2.5, -4.7],
[2.7, 5.3], [4.1, -2.8], [-4.0, -2.5], [5.0, 0.5], [-4.0, 4.3], [5.0, 1.3],
[3.3, 3.4], [2.2, 4.6], [2.8, 4.8], [4.0, -3.5], [4.6, -3.1], [0.5, 5.5],
[-4.7, 3.1], [-5.7, 1.0], [2.8, -5.1], [-1.3, 4.9], [2.7, 5.2], [-4.9, 1.3],
[4.1, -2.9], [-4.9, -3.3], [-4.6, 2.8], [-4.6, 3.1], [-1.8, 4.8], [-2.4, 5.3],
[-5.2, 3.0], [-3.7, -4.4], [1.5, -5.0], [4.8, 1.1], [-0.6, -5.8], [0.7, -4.9],
[0.2, 5.7], [5.8, -0.5], [-2.0, -4.0], [3.9, -3.1], [0.2, 5.1], [4.5, 1.5],
[-1.4, -5.3], [5.0, -1.4], [5.1, 0.7], [5.0, -3.0], [-0.7, -5.1], [5.2, -1.5],
[-0.7, 4.5], [2.1, 3.9], [-2.4, 5.0], [-0.8, 4.9], [-5.1, 0.3], [3.3, 3.6],
[-0.4, -5.1], [3.8, 4.6], [-5.3, -2.5], [-5.5, -1.2], [0.6, 5.5], [-5.8, 0.8],
[-5.3, 1.2], [2.0, -5.5], [5.7, 0.7], [-1.1, -4.7], [-0.0, 5.7], [-3.0, -4.8],
[-3.5, -4.0], [4.9, 1.8], [-1.1, -5.5], [-2.7, 4.2], [-4.9, -1.6], [-0.2, -5.2],
[2.5, 5.1], [-0.0, 5.4], [3.9, 4.4], [3.5, 4.8], [4.8, -1.9], [5.4, -1.0],
[3.7, 4.6], [1.8, 5.2], [4.7, 3.4], [4.1, 2.3], [0.6, -5.4], [1.4, 5.5],
[-5.5, 1.3], [4.2, 2.5], [-2.2, 3.9], [5.9, -0.4]])
x_train=np.concatenate((class1_points,class2_points))
y_train=np.concatenate((np.zeros(len(class1_points)),np.ones(len(class2_points))))构建模型
import torch.nn as nn
class Moudel(nn.Module):
def __init__(self):
super().__init__()
self.liner1=nn.Linear(2,15)
self.liner2=nn.Linear(15,2)
def forward(self,x):
x=torch.tanh(self.liner1(x))
x=self.liner2(x)
x=torch.softmax(x,dim=1)
return x
model=Moudel()定义损失函数和优化器
import torch.nn as nn
from torch.optim import Adam
cri=nn.CrossEntropyLoss()
optim=Adam(model.parameters(),lr=0.1)训练模型
for epoch in range(1,3001):
inputs=torch.tensor(x_train,dtype=torch.float32)
labels=torch.tensor(y_train, dtype=torch.long)
outputs=model(inputs)
loss=cri(outputs,labels)
optim.zero_grad()
loss.backward()
optim.step()
if epoch%500==0 or epoch==1:
print(epoch,loss.item())可视化
xx,yy=np.meshgrid(np.linspace(-6.5,6.5,100),np.linspace(-6.5,6.5,100))
grid_points=np.c_[xx.ravel(),yy.ravel()]
for epoch in range(1,1001):
inputs=torch.tensor(x_train,dtype=torch.float32)
labels=torch.tensor(y_train, dtype=torch.long)
outputs=model(inputs)
loss=cri(outputs,labels)
optim.zero_grad()
loss.backward()
optim.step()
if epoch%100==0 or epoch==1:
grid_points_tensor=torch.tensor(grid_points,dtype=torch.float32)
z=model(grid_points_tensor).detach().numpy()
z=z[:,1].reshape(xx.shape)
plt.cla()
plt.scatter(class1_points[:,0],class1_points[:,1])
plt.scatter(class2_points[:, 0], class2_points[:, 1])
plt.contour(xx,yy,z,levels=[0.5])
plt.show()完整代码
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 定义类别1的训练数据点
class1_points = np.array([
[-2.8, 0.1], [0.4, 2.8], [-0.1, 1.9], [-2.0, 1.5], [-0.4, 0.4],
[2.1, -0.0], [-0.8, 0.6], [0.4, -2.5], [0.1, -2.0], [-0.6, 1.6],
[-1.5, 2.1], [-0.9, 1.2], [1.3, 1.7], [0.2, -0.0], [0.2, -0.1],
[-2.1, -0.8], [-0.7, 1.6], [1.4, -1.2], [-0.8, -1.6], [-1.3, 1.1],
[-1.2, -0.1], [-2.9, -0.4], [2.4, -1.2], [-2.7, -1.3], [-1.1, -1.9],
[1.4, 0.5], [-1.0, 1.8], [2.2, 0.8], [0.9, 1.9], [1.8, -0.9],
[1.4, -0.6], [-0.2, -0.7], [-0.3, -2.4], [-1.5, 0.4], [1.2, -0.5],
[-1.8, 1.2], [-0.8, -1.7], [-1.7, -2.3], [-0.6, -0.4], [0.3, 1.8],
[-0.9, -1.9], [1.6, -1.6], [0.8, -2.6], [-2.6, 1.2], [1.8, -1.0],
[0.2, -0.9], [-0.4, -2.5], [1.5, 1.5], [2.2, -1.3], [-1.4, 1.2],
[-0.4, 1.3], [-1.3, -1.2], [-2.2, 0.4], [-0.1, 2.9], [1.5, -2.4],
[1.1, 2.3], [0.4, 2.8], [-0.8, -1.2], [-2.7, 0.4], [2.3, 1.1],
[0.9, 1.0], [0.9, 0.7], [-1.8, 0.3], [-1.7, -0.4], [1.0, -0.3],
[-1.1, -0.6], [-2.4, -0.4], [2.6, -1.4], [1.3, -0.7], [-0.0, 1.0],
[-1.1, -2.4], [2.0, -0.5], [0.3, 2.3], [-0.6, -2.8], [0.6, -1.8],
[0.9, -0.4], [1.0, -1.3], [-0.4, 0.2], [2.3, 0.1], [2.2, 0.5],
[2.5, 0.2], [-2.1, -1.3], [-1.1, 1.0], [1.7, 1.5], [0.9, -1.0],
[1.1, -2.2], [-0.2, -2.4], [0.7, -1.1], [-0.4, 0.3], [-0.0, -2.6],
[-0.3, -0.1], [-1.8, -1.6], [-0.8, 2.5], [-1.9, -1.4], [-2.5, 1.2],
[-2.3, -0.6], [-1.6, 0.1], [-1.9, 0.0], [1.1, -0.6], [-0.2, 2.7]
])
# 定义类别2的训练数据点
class2_points = np.array([
[5.1, 1.6], [-5.1, 1.2], [-4.6, 3.0], [-5.7, 0.5], [5.4, 2.5],
[-4.5, -2.5], [4.9, -0.4], [1.4, 5.5], [1.4, 5.7], [4.2, -1.0],
[-1.3, -4.8], [-4.4, -2.9], [-3.6, 3.4], [-3.4, -4.1], [-5.8, -0.1],
[4.7, 3.0], [-1.4, 4.4], [2.5, -4.7], [2.7, 5.3], [4.1, -2.8],
[-4.0, -2.5], [5.0, 0.5], [-4.0, 4.3], [5.0, 1.3], [3.3, 3.4],
[2.2, 4.6], [2.8, 4.8], [4.0, -3.5], [4.6, -3.1], [0.5, 5.5],
[-4.7, 3.1], [-5.7, 1.0], [2.8, -5.1], [-1.3, 4.9], [2.7, 5.2],
[-4.9, 1.3], [4.1, -2.9], [-4.9, -3.3], [-4.6, 2.8], [-4.6, 3.1],
[-1.8, 4.8], [-2.4, 5.3], [-5.2, 3.0], [-3.7, -4.4], [1.5, -5.0],
[4.8, 1.1], [-0.6, -5.8], [0.7, -4.9], [0.2, 5.7], [5.8, -0.5],
[-2.0, -4.0], [3.9, -3.1], [0.2, 5.1], [4.5, 1.5], [-1.4, -5.3],
[5.0, -1.4], [5.1, 0.7], [5.0, -3.0], [-0.7, -5.1], [5.2, -1.5],
[-0.7, 4.5], [2.1, 3.9], [-2.4, 5.0], [-0.8, 4.9], [-5.1, 0.3],
[3.3, 3.6], [-0.4, -5.1], [3.8, 4.6], [-5.3, -2.5], [-5.5, -1.2],
[0.6, 5.5], [-5.8, 0.8], [-5.3, 1.2], [2.0, -5.5], [5.7, 0.7],
[-1.1, -4.7], [-0.0, 5.7], [-3.0, -4.8], [-3.5, -4.0], [4.9, 1.8],
[-1.1, -5.5], [-2.7, 4.2], [-4.9, -1.6], [-0.2, -5.2], [2.5, 5.1],
[-0.0, 5.4], [3.9, 4.4], [3.5, 4.8], [4.8, -1.9], [5.4, -1.0],
[3.7, 4.6], [1.8, 5.2], [4.7, 3.4], [4.1, 2.3], [0.6, -5.4],
[1.4, 5.5], [-5.5, 1.3], [4.2, 2.5], [-2.2, 3.9], [5.9, -0.4]
])
# 合并类别1和类别2的训练数据
x_train = np.concatenate((class1_points, class2_points))
y_train = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points))))
# 定义一个简单的神经网络模型
class Moudel(nn.Module):
def __init__(self):
super().__init__()
# 第一层线性层,将2维输入映射到15维
self.liner1 = nn.Linear(2, 15)
# 第二层线性层,将15维输入映射到2维(输出类别)
self.liner2 = nn.Linear(15, 2)
def forward(self, x):
# 第一层后进行tanh激活
x = torch.tanh(self.liner1(x))
# 第二层输出
x = self.liner2(x)
# softmax激活,输出概率分布
x = torch.softmax(x, dim=1)
return x
# 实例化模型
model = Moudel()
# 定义损失函数和优化器
cri = nn.CrossEntropyLoss() # 交叉熵损失函数
optim = torch.optim.Adam(model.parameters(), lr=0.1) # Adam优化器,学习率为0.1
# 创建网格点,用于绘制决策边界
xx, yy = np.meshgrid(np.linspace(-6.5, 6.5, 100), np.linspace(-6.5, 6.5, 100))
grid_points = np.c_[xx.ravel(), yy.ravel()] # 将网格点连接为N x 2的数组
# 训练模型
for epoch in range(1, 1001):
# 将输入和标签转换为Tensor
inputs = torch.tensor(x_train, dtype=torch.float32)
labels = torch.tensor(y_train, dtype=torch.long)
# 前向传播,计算输出
outputs = model(inputs)
# 计算损失
loss = cri(outputs, labels)
# 反向传播并更新参数
optim.zero_grad() # 清零梯度
loss.backward() # 计算梯度
optim.step() # 更新参数
# 每100次迭代输出一次损失,并绘制决策边界
if epoch % 100 == 0 or epoch == 1:
print(epoch, loss.item())
grid_points_tensor = torch.tensor(grid_points, dtype=torch.float32)
z = model(grid_points_tensor).detach().numpy() # 计算网格点的输出
z = z[:, 1].reshape(xx.shape) # 获取类别1的概率,并重塑为网格形状
plt.cla() # 清空当前图
# 绘制类别1的点
plt.scatter(class1_points[:, 0], class1_points[:, 1], label='Class 1', color='blue')
# 绘制类别2的点
plt.scatter(class2_points[:, 0], class2_points[:, 1], label='Class 2', color='orange')
# 绘制决策边界
plt.contour(xx, yy, z, levels=[0.5], colors='green')
# 显示最终图形
plt.show() 更多推荐
 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)