
【影像+基因组学+临床记录】多模态深度学习用于癌症预后预测,并结合临床信息提示集成
生存预测对于指导癌症治疗和评估治疗效果至关重,肿瘤的异质性带来了准确预后的挑战。多模态学习整合了影像学、基因组学和临床记录的数据,为这一复杂任务提供了有前景的方法。虽然近期研究主要聚焦于影像和基因组数据,但反映患者整体健康的临床信息因其离散、稀疏且低维特性而未被充分利用。我们提出SurvPGC,这是一种结合病理图像、基因组数据和临床记录的综合模型,用于癌症预后。临床信息通过文本模板和基础模型转化为
论文总结
1、对于临床记录的结构化表格信息,由于维数较低,作者创新性的,将表格信息用文本编码,转换成文本数据,然后再和影像以及基因组学数据融合;论文针对临床数据低维、离散的特点,设计了文本模板(如“The age is [AGE] years old.”),并用视觉-语言基础模型 CONCH 编码为高维向量.
2、使用了Co-attention模块,采用了双向交叉注意力(bidirectional cross-attention),分别对临床-病理和基因组-病理两条路径进行融合,得到四个融合向量后再拼接。这是对 SurvPath 的扩展,增加了临床模态。
3、有开源代码。https://github.com/Houjiaxin123/SurvPGC.git
摘要
生存预测对于指导癌症治疗和评估治疗效果至关重,肿瘤的异质性带来了准确预后的挑战。多模态学习整合了影像学、基因组学和临床记录的数据,为这一复杂任务提供了有前景的方法。虽然近期研究主要聚焦于影像和基因组数据,但反映患者整体健康的临床信息因其离散、稀疏且低维特性而未被充分利用。我们提出SurvPGC,这是一种结合病理图像、基因组数据和临床记录的综合模型,用于癌症预后。临床信息通过文本模板和基础模型转化为高维向量,通过交叉注意力模块实现整合。对癌症基因组图谱的三个数据集进行验证,表明该模型有效捕捉了特定模态特征,注意力可视化显示了不同数据类型的关注区域。这凸显了整合多元信息来源以提升生存预测的重要性。
引言
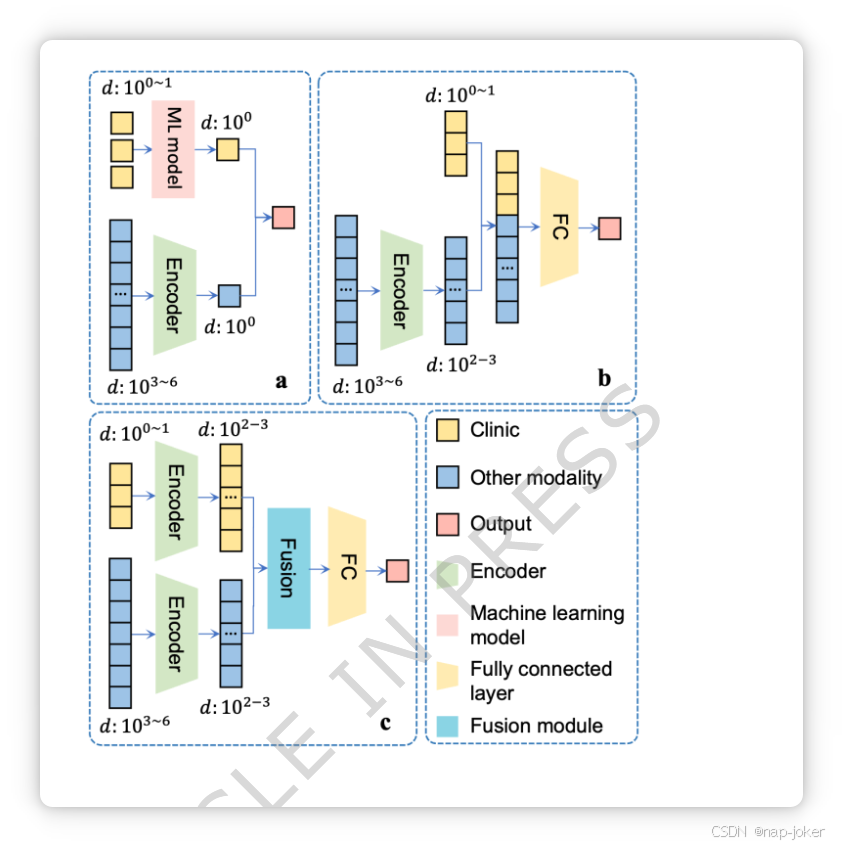
图1。三种常见的多模态学习方法,将临床信息与其他学习方式结合。 a. 构建临床特征及其他模态的独立模型,随后合并输出风险评分。 b. 将临床特征与其他模态的高维嵌入串接。c. 将低维临床数据编码为高维嵌入并与其他模态融合。D:维度。
生存分析通过建模事件发生时间数据,以预测特定时间点事件发生的时间或概率[1]。准确的生存预测有助于避免医疗过度治疗,并为医生做出决策提供科学基础,有助于治疗计划和结果评估[2]。然而,由于多种影响因素,尤其是在高异质性癌症中,生存预测具有挑战性[3]。深度学习具备强大的特征提取和表示能力,能够有效建模复杂的非线性关系。因此,该技术被广泛应用于解决肿瘤存活预测的挑战,促成了众多模型的发展[4]–[10]。病理图像包含丰富的视觉信息,是癌症诊断的黄金标准。因此,它们是这些研究中关键的数据模式。然而,使用单模态数据限制了分析的全面性。为了提高预测准确性并更好地满足临床需求,多模态肿瘤存活预测模型已成为一种主流趋势。 多模态学习方法利用来自多种数据源的全面信息,适合解决如生存预测等复杂问题[11]。在大多数多模态预后研究[12]–[14]中,除了病理图像外,还常使用基因组数据,以揭示肿瘤发育中的分子机制。然而,现成的临床信息常被忽视或沦为辅助角色[11],尤其是在基于深度学习的模型中。 临床信息通过增强模型对患者整体健康的理解,为生存预测提供全面的背景[15]。然而,临床数据通常是离散且低维的,这限制了其在深度学习模型中的应用,而深度学习模型通常擅长高维特征[16]。图1展示了将临床信息与其他疗法整合的三种方法。方法A则分别利用临床特征和其他模态数据构建模型,然后融合所得风险评分,这限制了模态间特征交互的可能性。方法b将其他具有标准化临床特征的高维嵌入连接起来,形成维度差距,从而削弱临床信息的影响力[17][18]。方法c在融合前将模态对齐到同一维度,但在将低维临床信息编码为高维特征时遇到困难,且忽视了临床输入中的上下文信息[19]。 本研究借鉴了自然语言处理(NLP)[20]和图像-文本集成[21]以及图像-文本整合[21]的进展,本研究开发了临床信息的文本模板,并利用文本基础模型将临床文本提示转换为高维嵌入,促进临床信息在模型训练中的更深入参与。 特征的强表征能力和多模态的适当融合方法是多模态学习研究中的两个关键点[22]。随着基础模型的发展,它们提取的特征展现出强大的泛化能力,众多研究验证了基础模型嵌入在各种任务中总结数据的有效性[23]–[25]。因此,本文采用了不同的基础模型从数据中推导嵌入。关于多模态融合,特别是在肿瘤存活预测的背景下,这些研究[14]、[26]–[29]均采用特征级融合以实现跨模态信息交互,这代表了该方法相较于早期融合(数据级融合)和晚期融合(决策级融合)[30]的关键优势[30]。其中,SurvPath [29] 是一种最先进的(SOTA)方法,集成病理图像和基因组数据用于癌症存活预测。SurvPath采用跨模态注意力融合策略,不仅增强了模态间的信息交换,还将基因组数据与通路标记与病理图像中的特定区域连接起来,从而产生可解读的可视化结果。SurvPath在癌症基因组图谱(TCGA)的五个数据集中展现出优异性能,优于以往多模态生存预测方法。然而,SurvPath并未进一步探讨临床实践中更常见的患者特征。鉴于基因组数据比临床特征更难获得,本研究旨在探讨纳入临床信息是否能进一步提升多模态生存预测模型的性能,临床特征是否能发挥与基因组数据相当的作用,以及临床信息在强调病理图像区域方面与基因组数据的区别。由于TCGA数据集中的临床数据为低维表格数据,我们提出了一种构建临床提示并对其进行分词化的方法,从而实现高维互动的更高效参与。
总之,本文的主要贡献包括:
(1)设计临床信息文本模板,并将临床文本标记化为高维嵌入以支持生存预测;
(2)通过基础模型中多模态嵌入的交叉注意融合,提升生存预测性能;
(3) 验证TCGA肝细胞癌(LIHC)、乳腺浸润性癌(BRCA)、结肠腺癌(COAD)和直肠腺癌(READ)数据集上的生存预测模型SurvPGC。
结果
本研究提出了基于多模态数据的癌症总体生存预测工作流程,包括全片图像(WSI)、转录组学和临床信息的预处理和嵌入编码,以及双路径交叉注意力融合模型SurvPGC,如图2所示。
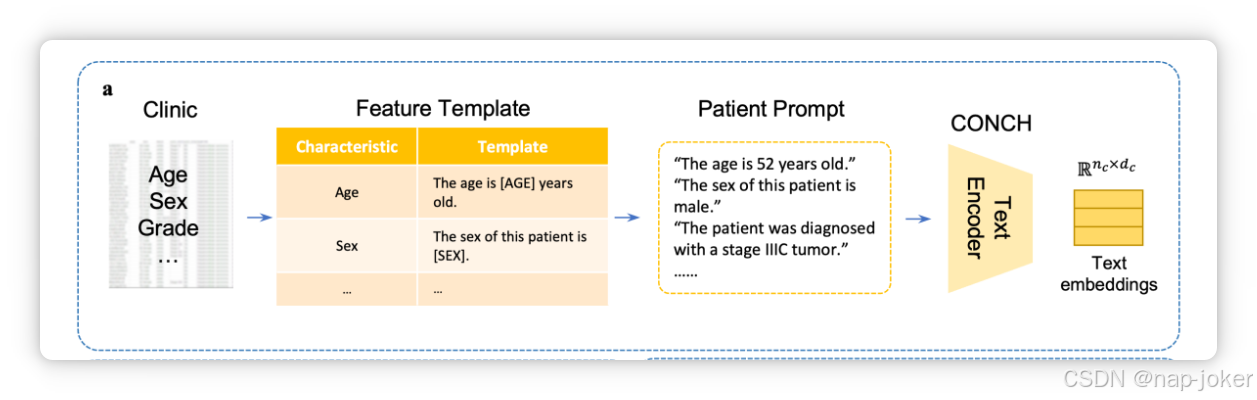
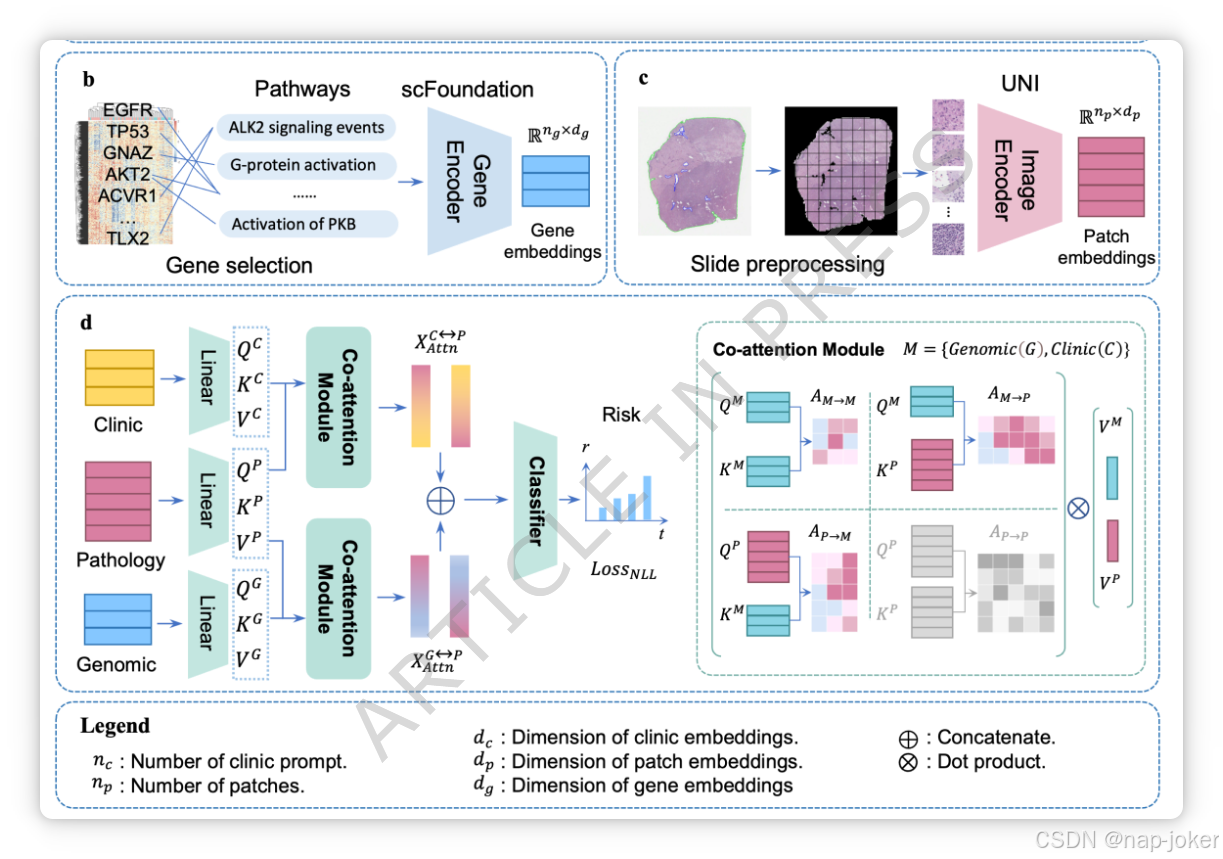
图2。拟议工作流程概述。a.诊所信息提示生成与嵌入编码。b.转录组数据预处理与嵌入编码。c. 整张幻灯片图像的预处理和编码嵌入。d. SurvPGC的双径交叉注意力融合结构。P:病理学,G:基因组学,C:临床。
数据集和实施细节
我们选择了TCGA-LIHC(354个案例)和TCGA-BRCA(1035个案例)数据集来评估模型,并采纳了TCGA-COADREAD(298个案例),该数据集在[29]中收集和整理,用于进一步的模型验证。案例选择过程见补充材料中的补充图1,概述了为确保数据质量和相关性的纳入和排除标准。3个数据集的审查比率见补充图2。我们将整体存活率作为记录最完整目标任务。采用了5折交叉验证,结果为5折的平均值。在模型训练过程中,损失通常在10个跨度后开始收敛。因此,我们将总历期数设为20个,并选择在第10至20个跨期验证中表现最佳的模型。其他实施细节见补充材料第4节。
单模法与多模法的对照指数(C-index)比较
我们进行了与其他单模和多模方法的对比实验。结果见表1。单模:临床:Cox比例危害模型是最广泛使用的多变量生存预测模型之一[31],其将临床特征纳入风险因素。我们选择Cox模型作为基于临床的单模预测基线。多层感知器(MLP)[32]是一种基础神经网络架构,用于评估单模嵌入的预测能力。自规范化神经网络(SNN)将自规范化操作集成到MLP层级中,从而增强模型训练的稳定性[33]。在以往研究中,SNN也经常被用于评估单模特征的生存预测性能[12][27]。基因组学:对于基因组数据,利用MLP和SNN网络验证单模嵌入的生存预测能力。病理学:由于WSI体积大且标记特性较弱,计算通常采用多实例学习方法。与其他模态类似,MLP作为基线方法。在最终完全连接层之前,通过计算均值对补丁级输出进行聚合。基于注意力的多实例学习(ABMIL)[34]通过学习根据补丁的重要性赋予不同权重来改进补丁聚合。TransMIL [35]利用Transformer模块在聚合过程中整合补丁实例之间的相关性,使其成为多实例学习WSI的代表性方法之一。多模态:在多模态学习比较实验中,我们选择了三种中间融合方法。PORPOISE [27]通过双线性池化整合基因组和病理数据的特征向量,计算外部积以全面捕捉不同模态间的成对关系。MCAT [28] 采用注意力机制,利用基因编码载体构建查询(Q)载体,从而实现基因引导的跨模态注意力融合,并识别与不同基因功能相关的病理区域。SurvPath [29] 基于 MCAT,将单向模态引导融合转化为双向融合,并优化输入基因通路,进一步提升模型的预后表现。SurvPath 目前代表了该领域的 SOTA 方法。从单模模型的角度来看,临床信息和基因组数据的预后预测能力在不同数据集中存在差异。基于基因组数据的 TCGA-LIHC、SNN 和 MLP 模型相比基于临床特征的模型获得了更高的 Cindex 值。相比之下,在 TCGA-BRCA 和 TCGA-COADREAD 上,临床模型表现更优。病理图像的预测能力也因数据集而异。从多模态模型的角度来看,整合三种模态的SurvPGC表现优于仅包含两种模态的其他模型,其中TCGA-BRCA表现最大。Cindex作为衡量模型对患者风险排名能力的指标,评估正确预测对与队列中所有配对的比例,显示多模态模型在某些情况下在三个数据集中表现低于单模态模型。如果每对样本的预测结果与实际情况完全相反,C指数值很可能低于0.5。这也表明模型学错了方向。次优融合策略可能降低输入数据的预后能力。由于SurvPGC是SurvPath的扩展,并融入了临床信息,我们对两个模型风险输出中C指数值进行了自助抽样和统计差异检验。详细程序详见补充材料第6节。总之,在所有五个交叉验证环节中,两个模型之间C指数值的差异均具有统计学显著性。
比较多模态方法在不同时间点的预测能力和患者分层能力
除了评估模型对患者风险进行排名的能力外,我们还利用积分曲线下面积(iAUC)评估了多模态模型在临床相关时间点(1年、3年和5年)的预测准确性。多模态方法的iAUC值及各具体时间点的AUC汇总于表2。结果表明SurvPath在iAUC评估中优于其他多模态方法;但其在每个具体时间点的表现并非最高。总体而言,每个模型的AUC在较短时间区间内通常较高。随着时间推移,被审查患者的比例和有效样本量均减少(补充图2),这给准确的风险预测带来了更大挑战。TCGA-LIHC的审查率约为65%,TCGA-BRCA为86%,TCGACOADREAD为81%。此外,TCGA-LIHC和TCGA-COADREAD的队列规模相对较小。因此,TCGA-COADREAD的预测任务更具挑战性,其iAUC和AUC表现相对低于另外两个数据集。与其他多模态方法相比,SurvPGC包含临床信息,使模型提供了更全面的患者特征,并改善了AUC值。图3展示了TCGA-LIHC数据集上单模态和多模态方法的Kaplan-Meier(KM)曲线比较。基于临床特征的Cox模型显示了有效的风险分层。临床信息嵌入和病理图像均显示出强的分层能力,而基因组数据则表现出相对较弱的分层性能。在多模态模型中,PORPOISE和SurvPGC展现出稳健的分层表现。在考虑表1中的C指数和表2中的iAUC值时,PORPOISE的排名和预测准确率较低,但分层能力依然强劲。SurvPath在排名和预测表现上相对较强,但患者分层较弱。SurvPGC在所有评估指标上均取得持续优异的成绩。TCGA-BRCA和TCGA-COADREAD上单模态和多模态方法的KM曲线见补充材料的补充图3和图4。
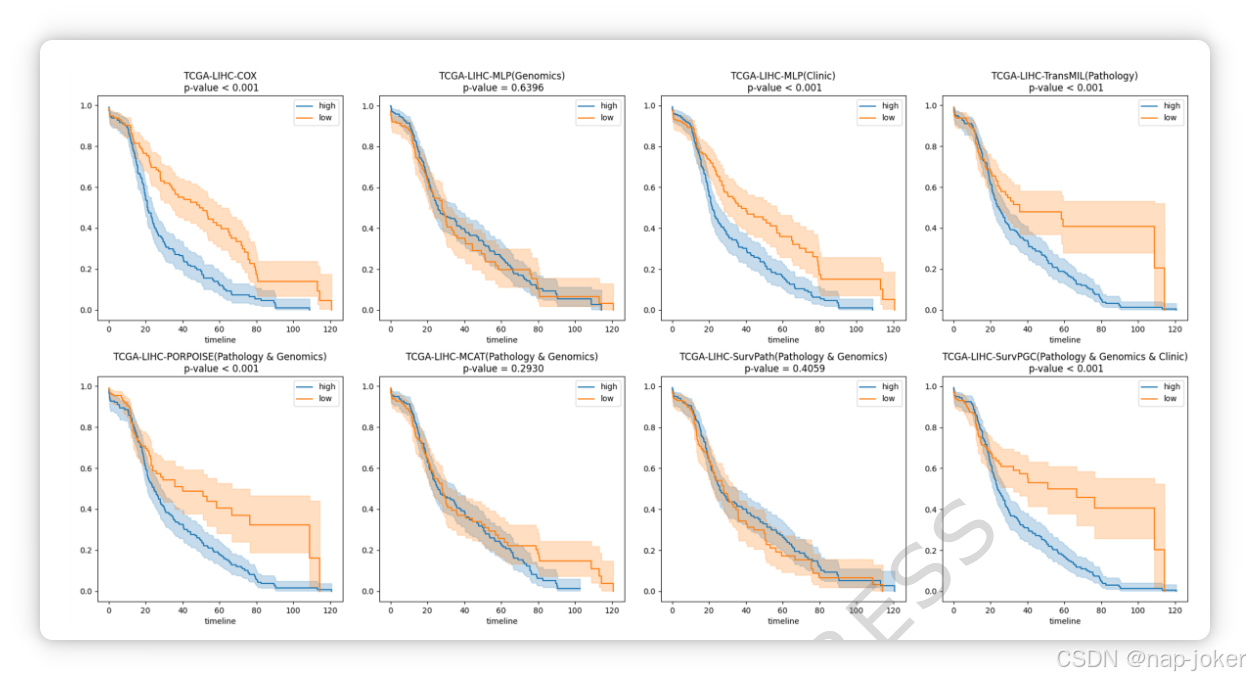
图3。TCGA-LIHC数据集上的单峰和多模法Kaplan-Meier曲线。橙色表示低风险组,蓝色表示高风险组。对数秩检验小于0.05的p值被认为具有统计学显著性。
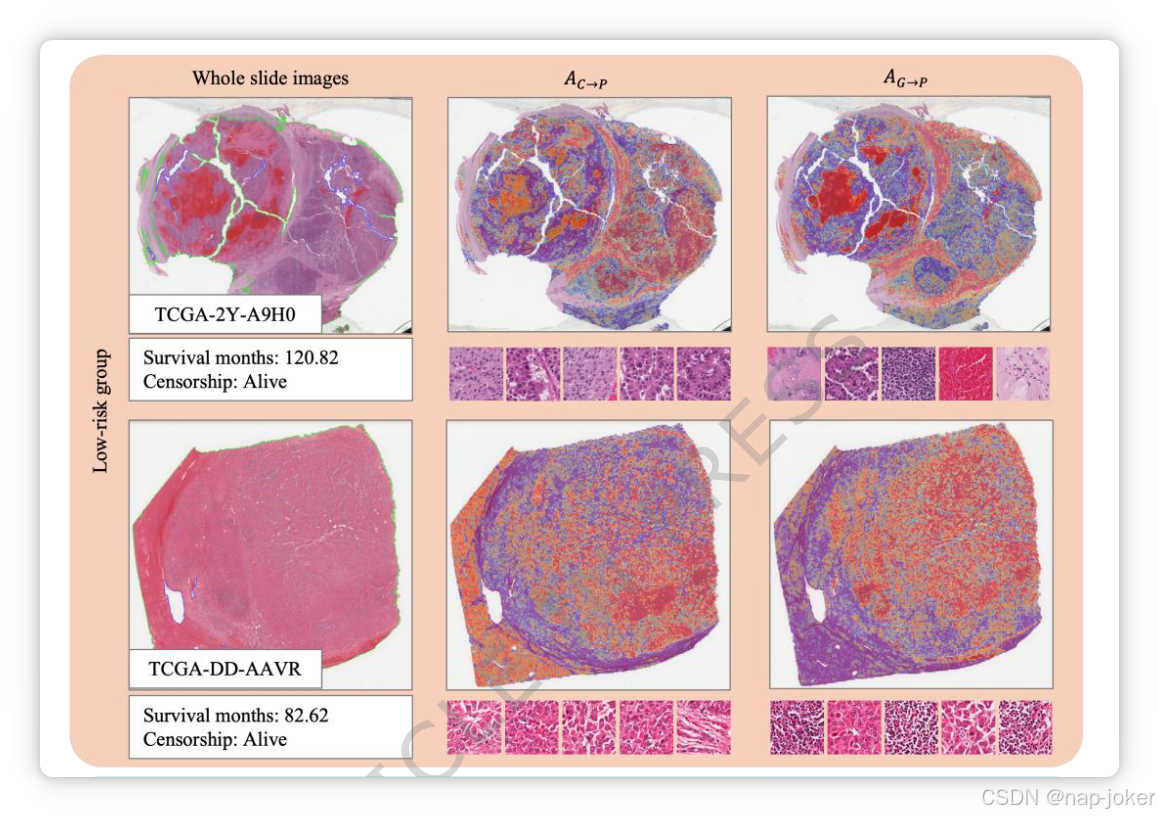
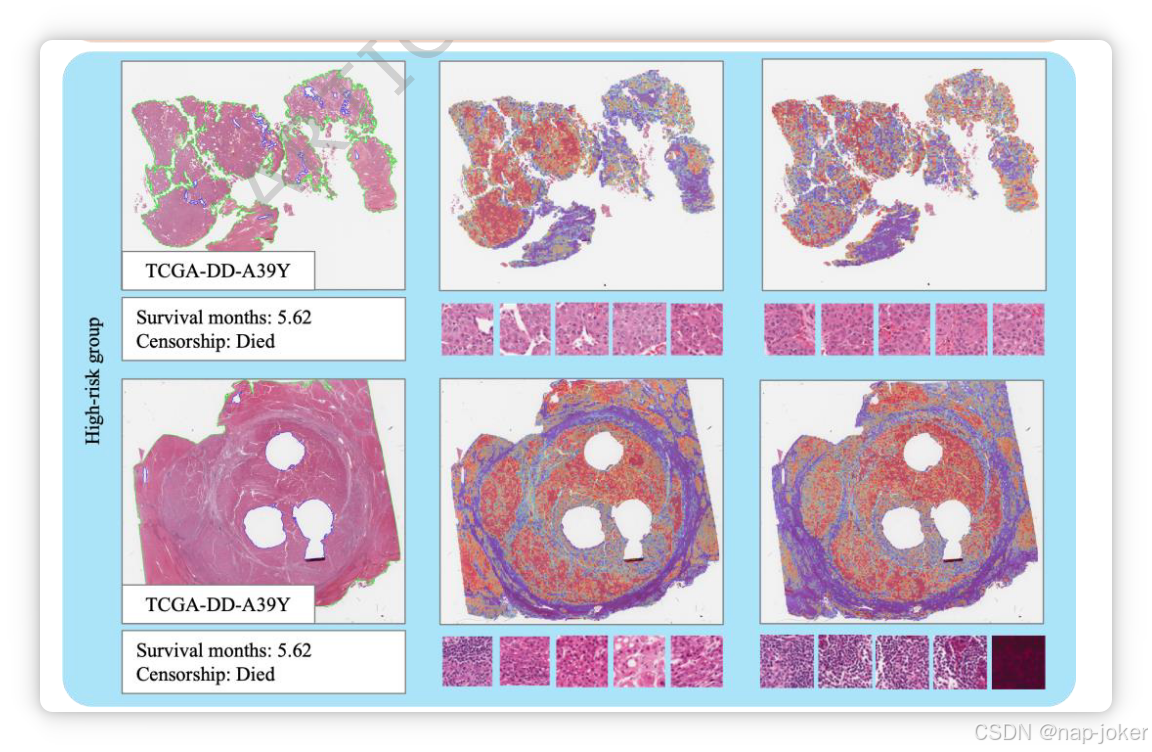
图4。LIHC患者的可解释性可视化。左列显示WSI的缩略图。中间列显示注意力矩阵AC→P的热图,该矩阵根据临床特征突出显示感兴趣的组织区域。右列展示了注意力矩阵AG→P的热图,该矩阵基于转录组数据识别感兴趣的组织区域。对于每种情况,根据AC→P和AG→P的累计注意力值选出的顶层斑块会显示在对应的热图下方。
临床信息对生存预测的影响
为评估双径融合嵌入对SurvPGC最终决策的贡献,我们采用了整合梯度(IG)来评估这些嵌入在进入最终分类模块前的影响。结果如表3所示,基因组病理学和临床病理学的融合嵌入均做出了显著贡献。我们在病理图像上可视化了注意力矩阵Ac→p(临床到病理学)和Ag→p(基因组学到病理学),以探讨基因组和临床相关的区域。图4展示了TCGALIHC的典型病例,红色表示高度关注,蓝色表示低关注度。病例根据生存时间分为高风险组和低风险组,高风险与较短生存时间相关。此外,我们比较了根据Ac→p和Ag→p累计注意力值选出的前50个补丁。在TCGA-LIHC(图4)中,临床和基因组数据主要聚焦于WSI(末端细胞)内的肿瘤细胞区域。此外,基因组数据还会关注淋巴细胞和坏死等区域,而这些区域很少被Ac→p选择。然而,基因组数据更容易受到噪声影响,可能不恰当地关注无关的伪影,如手写或扫描阴影。在TCGA-BRCA(补充图5)中,临床和基因组数据的注意力模式与TCGA-LIHC相似:两种方法都强调肿瘤区域,而基因组通路也集中于含有肿瘤基质和淋巴细胞的斑块,且更易受噪声影响。在TCGA-COADREAD(补充图6)中,模式相反:基因组数据主要聚焦肿瘤细胞区域,而临床特征则突出更广泛的区域,包括肿瘤、淋巴细胞和基质。尽管临床和基因组数据的主要关注领域在不同数据集中有所不同,但总体上是互补的。在以往与病理图像和生存预测相关的研究中,Shirazi A等人将特定病理组织区域与与生存结果相关的基因表达谱关联起来,间接建立了组织形态与生存之间的联系[36]。Li H等人证明了肿瘤周围胶原结构紊乱与乳腺癌预后和转移之间的关联[37]。肿瘤区域反映恶性程度,而肿瘤周围基质区域表示肿瘤转移和侵袭的可能性——这些因素与患者存活密切相关,包括复发和转移。因此,临床和基因组数据从不同角度突出的这些组织区域中的关键信息已被有效纳入模型计算,积极促进生存预测。更多可视化示例可见代码资源页面链接(https://github.com/Houjiaxin123/SurvPGC)。
讨论
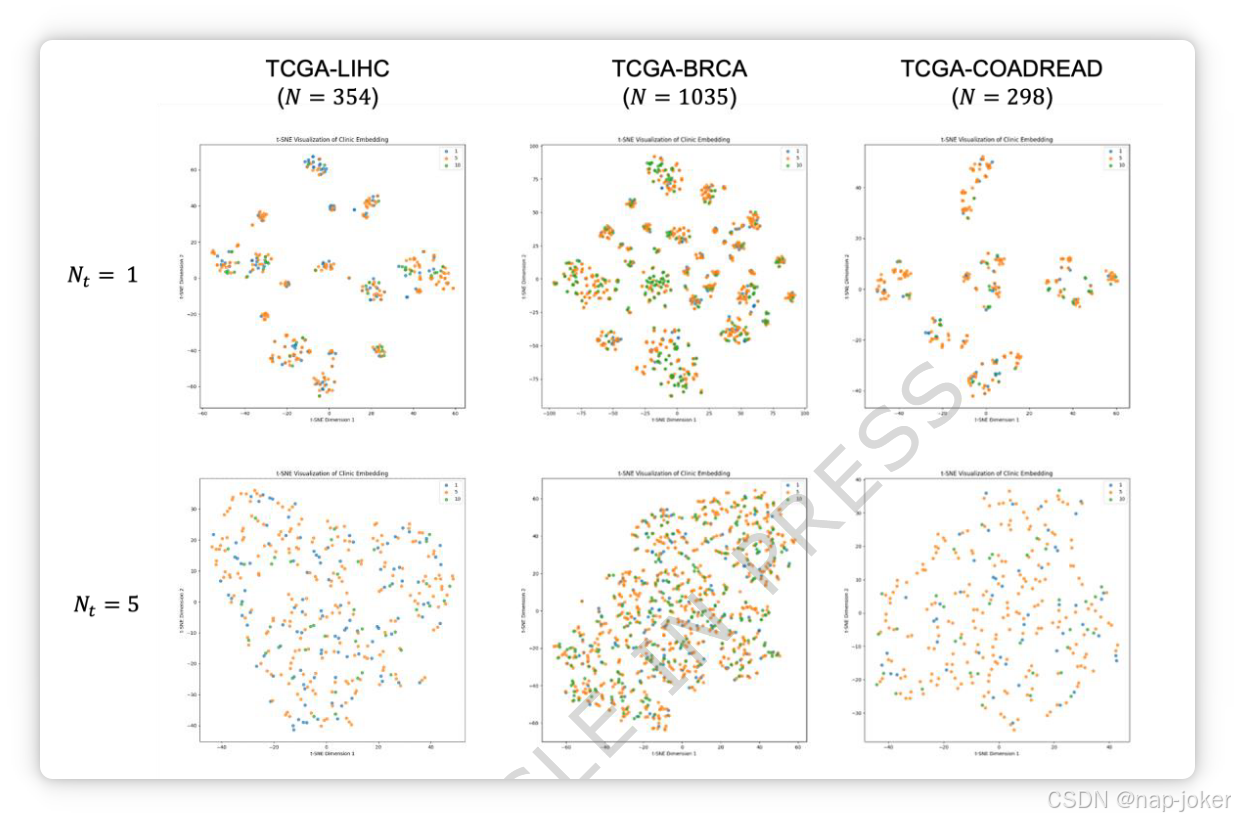
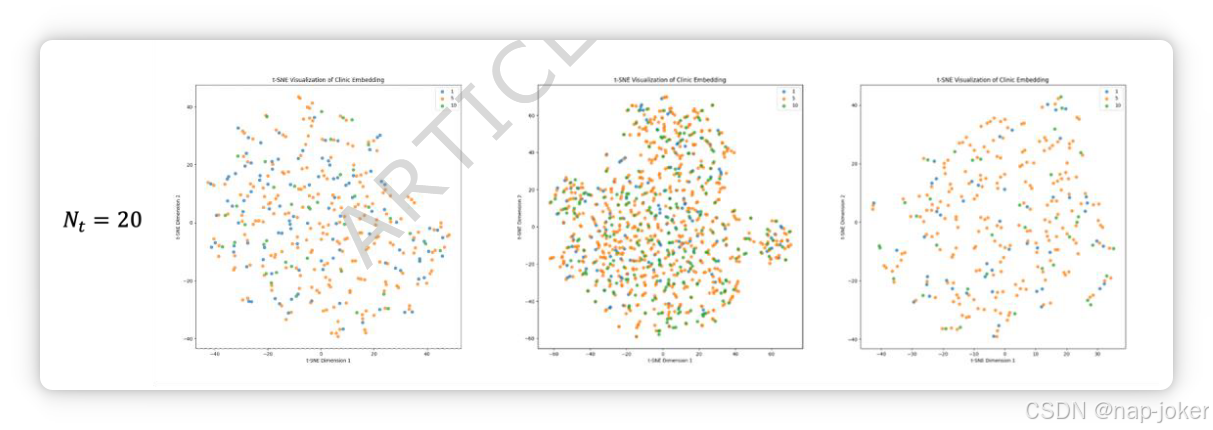
图5。使用不同数量同义模板生成的临床嵌入的t-SNE可视化结果。 蓝色点表示记录的生存时间少于1年的患者;黄色点表示患者生存时间在1至5年之间;绿色点表示生存时间超过5年的患者。nt 表示临床提示生成过程中同义模板的数量。N 表示每个数据集的样本量。
传统生存分析常使用Cox比例风险模型来估算生存时间并评估风险因素[38]。随着数据分析的进步,研究人员越来越多地将自然语言处理模型纳入电子病历中的非结构化文本,用于生存预测[39]。结构化临床数据,如表格统计数据,也可以转换为文本以添加上下文信息,从而提升模型的可解释性[40]。这凸显了有效利用临床文本进行预测任务的重要性日益增长。在多模态学习中,融入临床信息可以显著提升预测准确性。例如,我们之前的研究将临床数据与基于图像的风险评分和转录组特征整合,形成了一个更准确的Cox模型[41]。J. Yang等人利用ResNet50从病理图像中提取特征,并利用多模态紧凑双线性池(MCB)将部分临床特征与图像特征融合[42],这是一种基于外积的方法,能够以相对较低的计算复杂度实现乳腺癌复发和转移的预测准确率[43]。然而,这些方法在处理临床信息时通常精度有限,临床与其他模式之间特征维度的差异可能限制整体预测性能。如引言所述,将临床信息整合进多模态学习主要涉及两个关键挑战:编码策略和融合方法。这通常可分为图1所示的三种类型。为评估不同编码和融合工作流程对临床信息预后预测能力的影响,我们在三个数据集中进行了实验。结果总结于表4,补充材料第5节提供了方法a、b和c的详细描述。显然,所提工作流——基础模型编码与双向交叉注意力结合——在支持特征级交互的条件下,能够实现最高的C-指数。用于生成临床提示的模板多样性对模型性能的影响也是一个值得讨论的话题。受图像文本对比学习研究[21]的启发,我们设计了文本模板将临床信息转化为捕捉语境语义的句子。以往研究探讨了对比学习中的文本增强,即使用大型语言模型重写与图像相关的说明。在模型训练过程中,随机选择原始文本或重写文本,表明增加文本多样性可以提升模型性能[44]。因此,针对每个特征,我们设计了以关键信息为中心的描述文本模板,并使用GPT-4o mini生成了Nt同义模板。每个特征随机选择一个模板,生成每个案例六个描述句子。模板详见补充表8。为确定同义句的最佳数量,我们进行了实验,比较当Nt = 1,3,5,10,20时MLP模型与临床嵌入的存活预测表现。部分实验结果见表5。此外,我们通过t分布随机邻居嵌入(t-SNE)方法可视化了基于Nt模板生成的临床嵌入。结果表明,当Nt=1时,不同生存期患者的嵌入表现出最佳的辨别和聚类表现。部分可视化结果见图5。综合考虑C指数和t-SNE可视化结果,最终选择Nt = 1生成多模态生存预测的临床文本。完整的实验结果见补充材料第1节。基础模型在庞大数据集上训练,展现出强的泛化性和鲁棒性,支持单次或少数次任务的执行。这些模型广泛应用于数据预处理中,以提高效率。在医学领域,各种基础模型处理不同的数据模态,如基因测序数据的scFoundation[45]、全幻灯片图像的UNI[46]、图像-文本对的CONCH[24]和MUSK [47]。在多种任务场景下,这些基础模型作为高效且快速的数据预处理工具,从数据中捕捉关键信息。此外,适当应用基础模型还能解决在训练较小、专业深度学习模型时遇到的数据不足问题。模态融合是多模态学习中的关键问题。根据融合阶段,可分为早期融合、晚期融合和中间融合[16]。早期融合受数据形式限制,而晚期融合缺乏模态间交互。中间融合将模态统一到共享的高维空间,有效利用多模态优势。大多数研究都深入研究了多模融合方法[48],范围从简单连接或基于元素的计算融合[49],到双线性池[27]及相关改进以降低计算负载[42],再到基于注意力机制的融合方法[50]和Transformer[28]、[29]、[51]。这些方法用于多模式连接的仿真能力逐渐提升。根据数据特性和处理程序,也有研究采用多种融合方法的组合[7]、[52]。 自Transformer架构引入以来,注意力机制已成为多模态研究的焦点[53]。它使模型能够为输入的不同部分分配自适应权重,从而强调对当前任务最相关和关键的信息。在多模态环境中,注意力评分是基于不同模态输入计算的,这意味着计算明确考虑了跨模态信息。 基于注意力的特征融合尤其擅长捕捉不同模态间的上下文关系,已成为特征级融合的广泛采用方法[26]、[28]、[54],在多种多模态任务中表现优于其他融合策略[48]。 本研究采用基于注意力的融合策略,分析融合过程中的注意力矩阵,建立了模型计算与视觉解释之间的联系。表征学习是多模态学习的另一个核心组成部分。此外,它与模态融合密不可分,尤其是在端到端深度学习框架中[55][56]。在癌症存活预测的背景下,大多数现有研究侧重于整合病理和基因组数据,但对如何有效将临床信息纳入模态融合以及如何构建多模态关系的探索有限。为弥补这一空白,本研究提出了一种解决方案,即设计文本模板以编码上下文信息,并通过跨模态注意力机制实现与其他模态的交互。 此外,这项研究存在若干局限性。首先,文本模板和临床特征的选择是手动设置的。一种自动化生成临床文本模板的方法,有助于工作流程的更广泛应用。其次,基础模型的应用未被广泛探讨。不同的嵌入编码器会影响模型的预测性能,因此为特定任务选择更合适的编码器仍是一个重要考虑因素。虽然基础模型强调跨多样数据的泛化,但增强嵌入针对特定模态和任务的判别能力同样至关重要。第三,尽管SurvPGC获得了相对较高的C指数并表现出强劲的风险排名表现,但在特定时间点预测准确性仍有提升空间。未来的研究应聚焦于提升模型在不同时间区间内,尤其是较长生存期内,精确估计风险的能力。
本文提出了基于多模态数据的预后预测工作流程,具有若干关键优势:(1)模板设计使结构化临床数据能够捕捉更丰富的上下文信息,从而增强高维特征的语义表示;(2)利用基础模型在不同模态中编码高维特征,简化流程同时确保稳健的诊断辨别;(3)临床信息和转录组共同突出的病理组织区域的可视化与比较,为预后提供了见解。我们的模型已通过TCGA-LIHC、TCGA-BRCA和TCGACOADREAD验证,显示其性能优于以往方法。未来工作中,我们计划深入研究多模态特征的提取与选择,从有限数据中提取宝贵信息,以更好地完成目标任务,满足癌症计算机辅助诊断的临床需求。
方法
由基础模型编码的多模嵌入
临床信息。给定一组 nc 值的临床特征(文本或数字),记作 c ∈ Rnc。 考虑到临床记录特征的完整性及其与预后潜在关系,选定了六个临床特征(年龄、性别、肿瘤分期、诊断标准版本和肿瘤亚型),因此NC = 6。使用预训练的视觉语言基础模型CONCH [24]进行文本编码,实现了临床嵌入XC∈Rnc×dc,其中dc是每个临床嵌入的维度。该部件的过程如图2a所示。 转录组表达文件。分析了转录组数据,包括约6万个ng表达测量,记作g ∈ Rng。为减少冗余,我们采用了SurvPath[29]中描述的方法,从Reactome和Hallmarks库中选择331条与生存相关的通路,识别出4,999个与这些通路相关的基因,因此ng = 4,999。随后,我们使用预训练的 scFoundation [45] 对所选数据进行编码,结果为每个样本生成基因组嵌入,表示为 XG ∈ Rng×dg,输出为 ng = 4 个向量(符合 scFoundation 默认参数设置),dg 表示每个基因组嵌入的维度。该部件的工艺如图2b所示。 病理图像。我们选择了高质量的石蜡嵌入的苏木精和伊松染色的数字WSI。 CLAM [57] 用于分割组织区域,从中切割出256*256非重叠的斑块在20×倍率下。根据每张切片的大小和质量,可以剪出一组np小块(数量级范围为1,000到10,000),记作P = {p1, p2, ... , pnp}。UNI [46],一个预训练的基础模型,提取特征为每个补丁生成病理图像嵌入,记作xpi∈Rdp,其中dp表示每个补丁的维度。因此,每个包含np片段的样本嵌入可以表示为XP的Rnp×dp∈。该过程如图2c所示。
基于交叉注意力机制的多模融合
首先,我们利用可学习的线性层将每种模态的嵌入映射到同一维度 d,分别得到 XC ∈ Rnc×d、XG ∈ Rng×d、XP ∈ Rnp×d。随后,以病理学和临床信息为例,将两种模态的嵌入串联得到 X∈ R(nc+np)×d,查询(Q)、键(K)和值(V)向量则通过线性投影的自注意机制(方程(1)-(3))获得。可学习权重矩阵W的维数为:WQ ∈ Rd×d′,WK ∈ Rd×d′,WV ∈ Rd×d′,其中d′表示投影后的嵌入维数。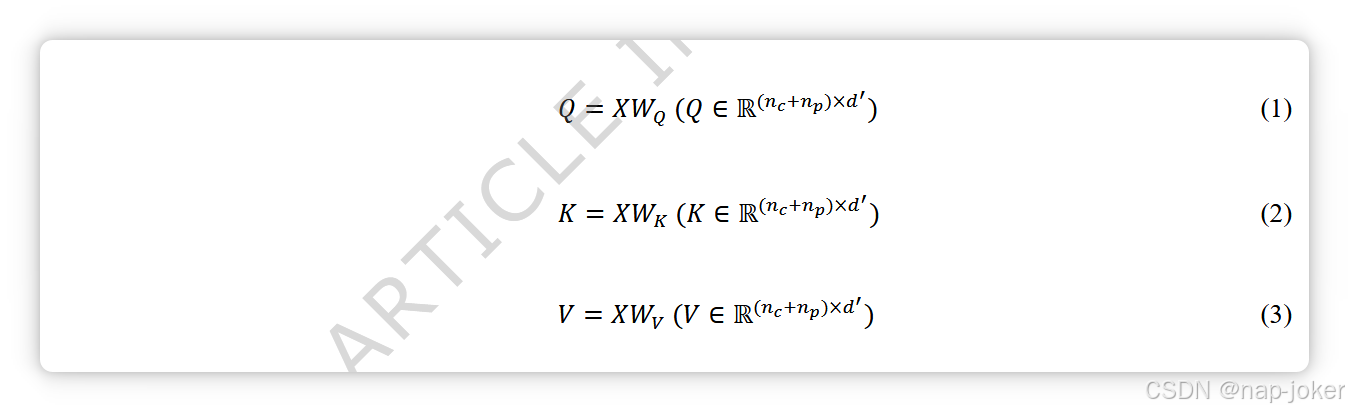
通过利用两种模态的嵌入计算注意力矩阵A(参见方程(4)),我们可以有效地过滤掉与下游任务最相关的信息。
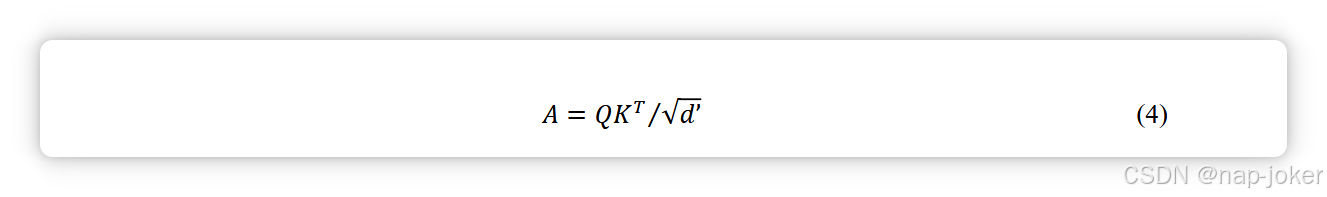
根据G. Jaume等人[29]的观点,双向交叉注意力融合增强了模型利用任务相关信息的能力,提升了预测性能。我们设计了一个双路径交叉注意力融合模型(见图2d),双向交叉注意力机制分别应用于临床信息与病理的融合,以及基因组学与病理的融合。计算了临床-病理融合(AC↔P)和基因组-病理融合(AG↔P)的注意力矩阵。每条路径中的融合向量XAttn可计算为方程(5),其中σ为softmax函数:
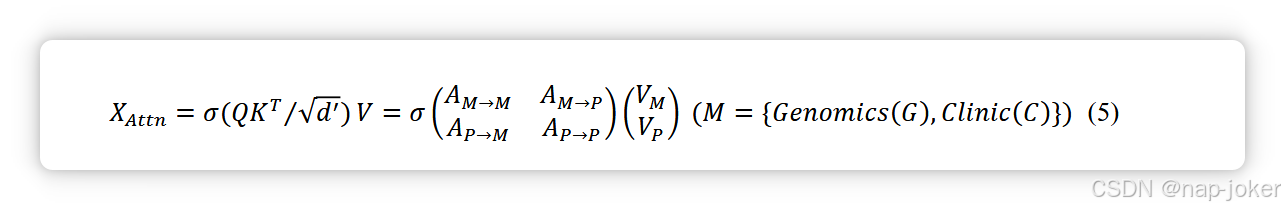
更详细地说,上述操作通过串联得到X,并将其映射到Q、K、V向量。因此,对应的Q、K、V向量具有特定模态,可以直接分块计算注意力矩阵。 为了简化模型并关注跨模态交互,我们省略了模态内注意力矩阵AP→P,如[29]所示。以临床信息与病理学融合为例,双向交叉注意力过程如方程(6)-(9)所示。
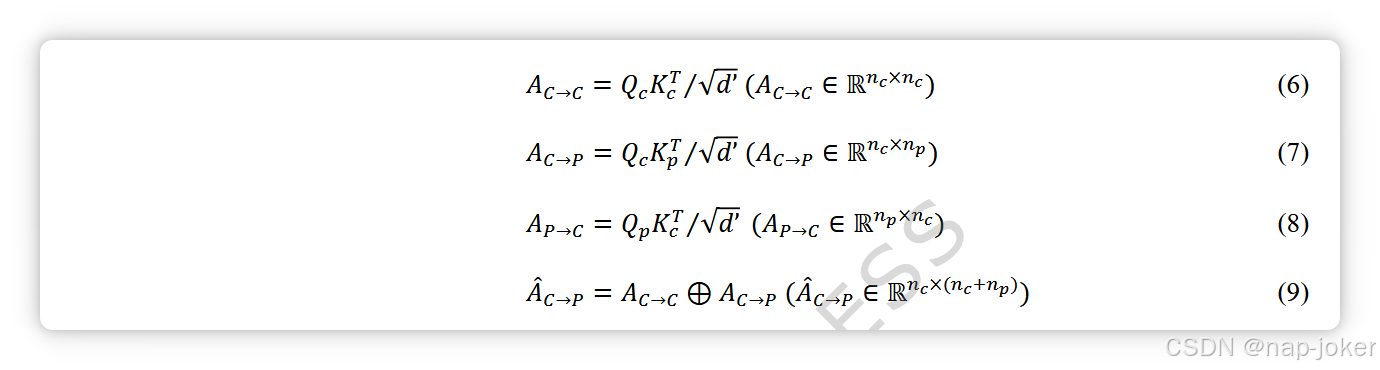
将双向交叉注意力矩阵 ̂AC→P、AP→C 乘以每种模态的 V 向量,得到融合向量 XC→P、XP→C(方程 (10)-(11))。经过前向传播层并进行归一化操作后,计算融合向量表示的平均值,得到 ̅XC→P ∈ Rd′ 和 ̅XP→C ∈ Rd′。
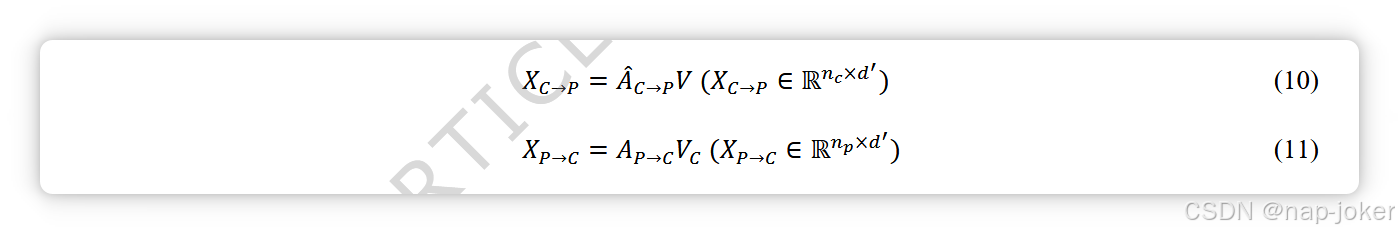
基因组学与病理学的融合过程相似。最终,可以得到4个具有双向注意力融合的同维融合矢量:̅XC→P、̅XP→C、̅XG→P、̅XP→G。将4个融合向量串接得到XFusion(方程12)),作为最终模型决策层的输入。
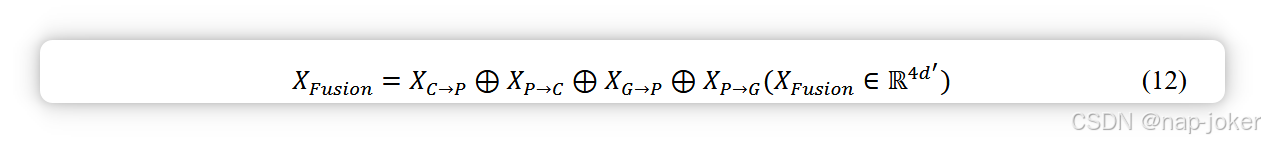
损失函数
我们遵循了之前的研究[12]、[27]、[58],采用了负对数似然(NLL)损失,以避免由审查率引起的偏差,该率通过预测生存时间落入不同时间区间的概率,将生存预测转化为分类任务。正如之前的工作[27][28][29]所示,t表示存活时间,c表示患者的审查状态,c=0表示患者随访记录中观察到的死亡时间点t,c=1表示t为最后一次随访记录,死亡时间未知。基于最长持续时间记录,我们定义了 i 个区间,表示为 [0, t1), [t1, t2), ... , [ti−1, ti)。模型输出的“y”通过S形映射,以估算时间内部的死亡概率,表示为“y” = [y1, y2, ..., yi]。基于 ̂y,可以参考方程(13)计算每个区间的存活概率。 最后,通过对区间生存率的负值相加,定义了患者层级的生存风险描述。
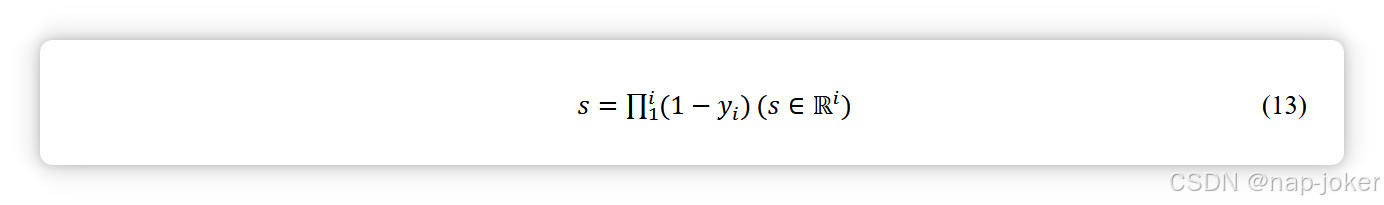
为了确保模型能捕捉WSI的不同区域同时避免冗余,我们引入了余弦相似性损失函数。该损失函数降低了两个交叉注意力模块输出的融合嵌入之间的相似性,引导模型关注来自各模态的互补信息。损失函数为方程(14),其中β为损失余弦的权重。
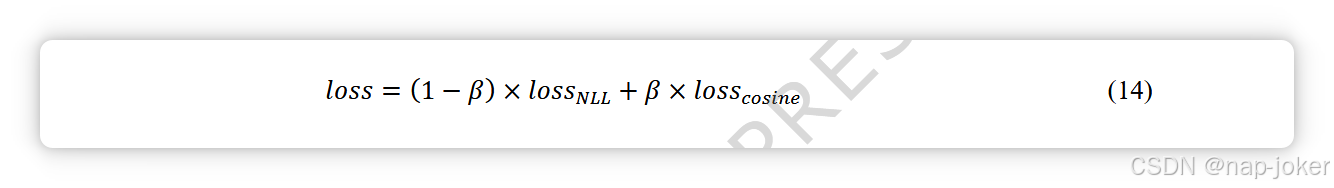
由于相似性损失函数带来的模型性能提升不稳定,未包含在表1的结果中。关于相似性损失函数的讨论见补充材料第2节。
评估指标
为评估模型预后表现,我们使用了多种指标:C指数评估预测结果与实际结果的一致性,iAUC评估多个时间点(1年、3年和5年)的表现。 KM曲线直观显示风险组的生存概率,而对数排名检验则评估生存差异,p<0.05被视为显著。
数据可用性声明
研究分析的数据来自公开在线数据集,包括TCGA(http://portal.gdc.cancer.gov/projects/TCGA-LIHC 年访问时间为2024年10月24日)、http://portal.gdc.cancer.gov/projects/TCGA-BRCA 年(访问时间为2024年12月21日)、http://portal.gdc.cancer.gov/projects/TCGA-COAD 数据(访问时间为2025年6月30日)、http://portal.gdc.cancer.gov/projects/TCGA-READ 数据(访问时间为2025年6月30日))以及加州大学圣克鲁斯分校Xena(访问时间为2024年12月26日)https://xenabrowser.net/datapages/)。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)