
李哥深度学习-图片分类任务(自用)
卷积核作为图片厚度同样为3,与特征图对应厚度以及padding之后进行卷积会得到一张新特征图,将同一层得到的图片聚合为一张新特征图,那么也要用一个同样厚度新的卷积核进行卷积。对拉直的数据进行训练得到10*1的输出值矩阵向量,再加上10*1的偏差值矩阵向量,最后得到的结果再 找出最大值。深度学习基于大量的数据训练模型,通过一个合格的损失函数取判断输出值与精确值的差值,利用反向传播对模型进行优化。
深度学习的开始

深度学习基于大量的数据训练模型,通过一个合格的损失函数取判断输出值与精确值的差值,利用反向传播对模型进行优化。
线性模型
线性模型需要设置权重与偏差,其中最典型的就是 y = wx +b。 w为权重 b为偏差。最后loss的 大小可以反应w与b的设置是否得当。损失函数各有优劣,具体可通过正在做的项目去选择正确的损失函数。
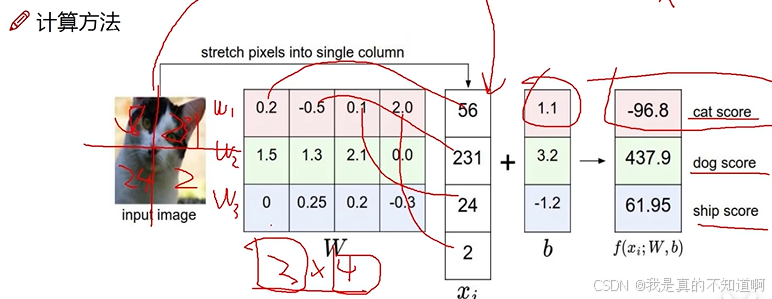
w(标签数,输入数) x为输入的值矩阵向量 b为偏差 最后得到结果值
权重的值往往代表对应输入值的重要程度
优化方法
基本的优化方法是采用了梯度下降的方法,梯度下降利用了反向传播来完成。
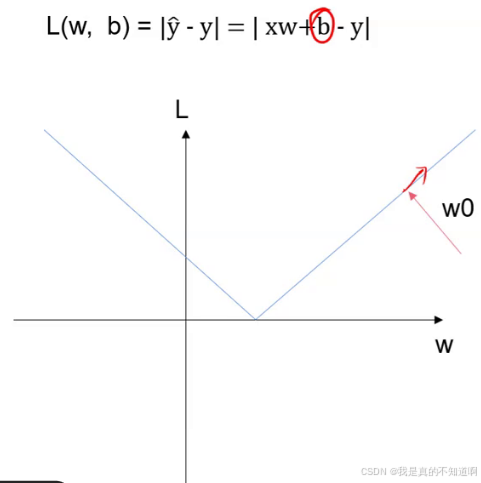
以损失函数结果L作为纵轴,权重作为横轴,随机取一点w0计算梯度,如果梯度为正,则说明随权重增加误差变大,此时就需要降低降低梯度。可以利用w减去自己的梯度。
可以通过设置学习率lr,来控制w变化的速率。同理,对误差b同样可以进行优化。
利用torch框架可以自动计算梯度。
多层神经网络
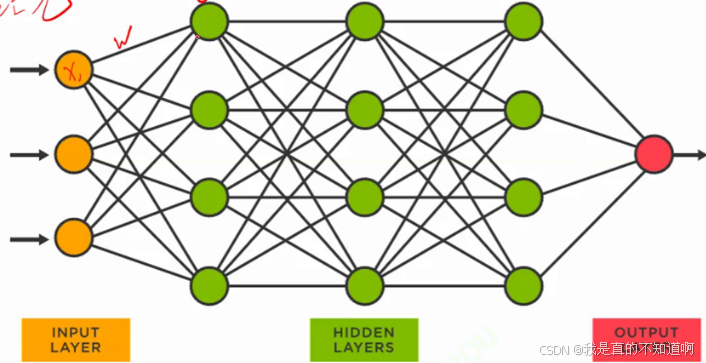
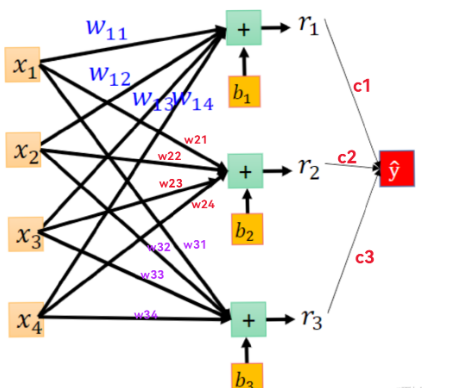
上述两个节点之间的连线就是一个线性函数,第二列第一行的节点值=w0*x0+w1*x1+w2*x2得到的结果。
分类任务其实是选择题
分类利用了回归,利用回归进行预测数据的各项值,再通过找出预测的数据的最大值来判断数据的类型。
在使用独热编码表示标签的前提下,针对种类的数量问题利用全连接方式在最后输出linear(?,种类数量),在种类数量一列找出最大值,其对应的下标即为其对应的标签。
对上述一段话进行解释:输出的结果实际作为一组向量,如何得到该向量呢?对拉直的数据进行训练得到10*1的输出值矩阵向量,再加上10*1的偏差值矩阵向量,最后得到的结果再 找出最大值。注意
数据的处理
1.所有的图片都需要有相同的大小,在数据处理中,需要将图片大小进行改变。
2.图片是天生的三通道数据,每一个通道的颜色不一致,具体对应到红绿蓝三种颜色(三原色)。
3.图片的矩阵模式如何输入进模型进行训练呢?将矩阵拉长,变为一维,输入进模型当中。
拉直之后往往具有庞大的数据量,但是注意在全脸接网络当中,庞大的输入数据量容易 导致过拟合,因此要在全连接网络的基础上引入卷积神经网络。
卷积神经网络
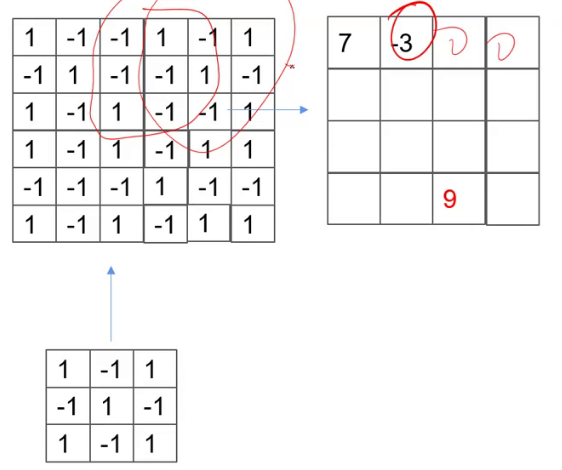
下面那张小图叫做卷积核,大图叫做特征图。
卷积核在特征图上进行滚动,各小格子相乘的结果相加得到新的特征图。根据新特征图上最 大值可以得到原特征图与卷积核最相似的部分
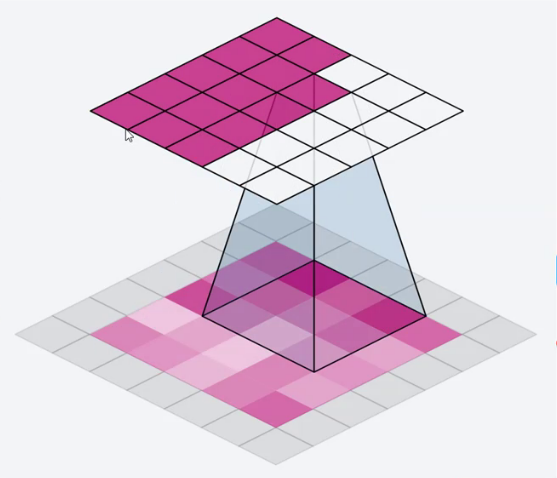
图片
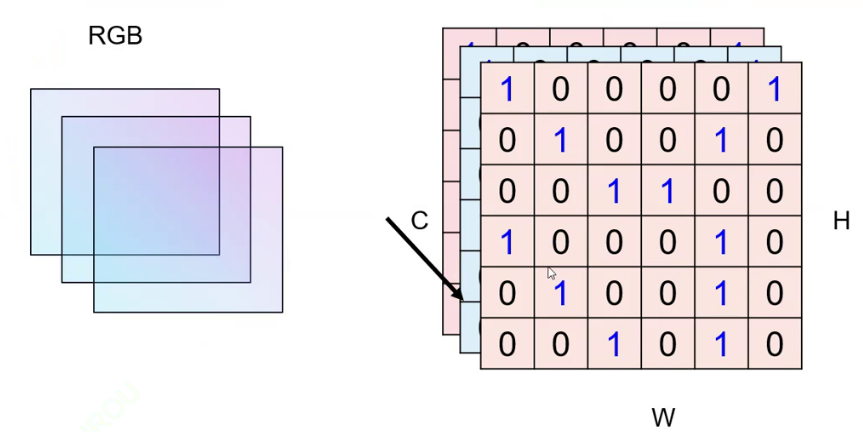
图片具有RGB三通道,一张图片可以利用长宽厚来表示,例如一张图片为 224*224*3,长宽皆为224,厚(通道数)为3
卷积过程保持特征图不变与新特征图的大小计算
新特征图大小 = (原特征图长-卷积核长+1)*(原特征图长-卷积核长+1)
卷积的过程中必然导致新特征图较原特征图小
在卷积过程中采用padding方式扩充原特征图可以保持新特征图较原特征图大小不 变
采用padding之后,若padding = N
新特征图长 = (原特征图长+padding*2-卷积核长)/步长+1 步长未提及默认为1
得到的新特征图卷积核的通道由卷积核的数量决定。
更多的卷积层数
卷积核作为图片厚度同样为3,与特征图对应厚度以及padding之后进行卷积会得到 一张新特征图,将同一层得到的图片聚合为一张新特征图,那么也要用一个同样厚 度新的卷积核进行卷积。
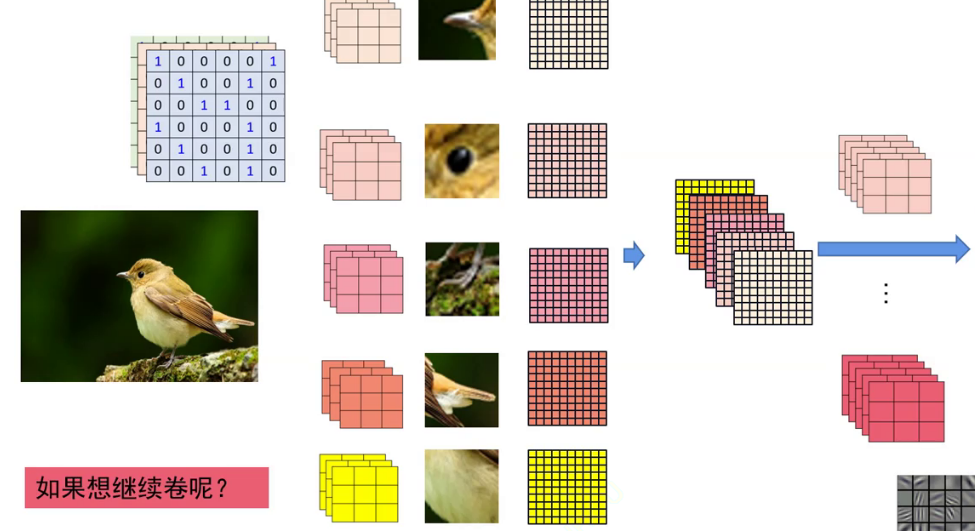
一层卷积核的参数量
一层卷积核参数量为 5*3*3*3 如上图所示
特征图变小的方法
1.扩大步长
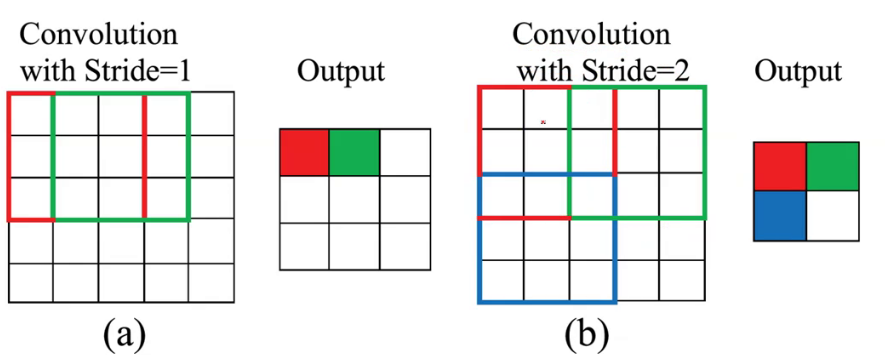
扩大步长即卷积核由一格一格滚动卷积变为两格两格的滚动卷积,大幅度降 低新特征图的大小。
缺点:容易缺失信息且加入复杂计算
2.池化
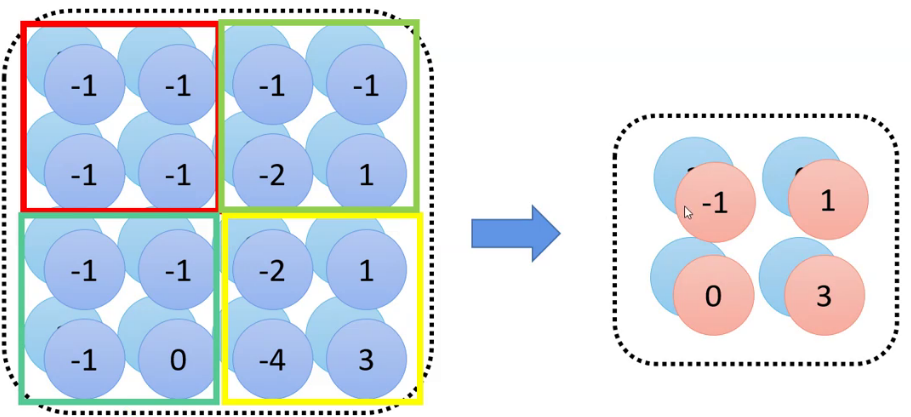
将大矩阵按照一定大小的小矩阵进行分割,将不同的小矩阵用一个数进行表示
1.平均池化->Pooling(N)
将小矩阵内部的值相加求平均数,用平均数代替该小矩阵。
N代表矩阵的边长 即N*N矩阵。
2.最大池化->AdaptiveAvgPool(N)
将小矩阵内的最大值代表该小矩阵。
N代表池化之后得到的新特征图的边长。
图片分类一般步骤
读取数据->数据预处理->卷积->拉直数据->数据全连接层->训练完毕->调参优化模型->对数据进行预测
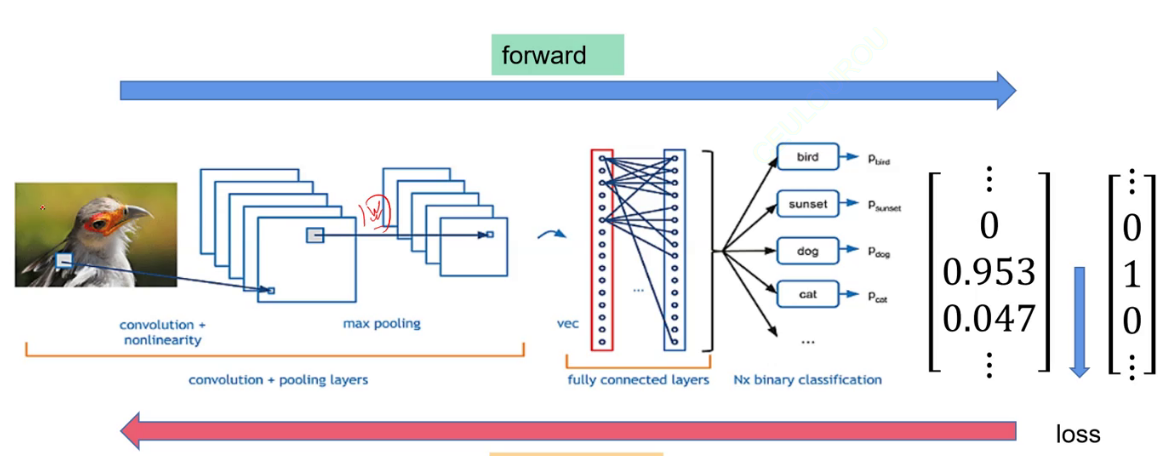

图片分类的损失函数
得到的结果往往是数,要通过softmax改为概率分布,根据最高的概率来预测数据的类别
分类任务往往采用交叉熵损失

log 底数小于1得到的值为负数,这样的计算方式能让正确预测组得到的loss较小

AlexNet优点
1.relu:激活函数,引入非线性
2.dropout:训练的过程中,隐藏层的神经元会有一定数量的被丢弃掉。这意味着训练发 生在神经网络不同组合的神经网络的几个架构上,可以将Dropout视为一种综合技术, 然后将多个网络的输出用于产生最终输出
3.池化:
4.归一化:降低数据量纲的影响
正则化
正则化的引入是为了防止模型在训练数据上过度拟合。
损失函数 = 数据损失 + 正则化处罚项(当前模型由于权重参数所带来的损失)![]()
![]()
正则化惩罚项通常加在原始损失函数(如均方误差、交叉熵等)之上,目的是限制模型参数 的规模,从而减少模型的复杂度,使得模型更加泛化,而不是过度适应训练数据中的噪声和 细节。
需要正则化的时刻:模型复杂度过高、数据量不足
常见的正则化方法
L1 正则化:
L1 正则化倾向于产生稀疏解,即许多权重会被设为零。有助于简化模型,使 得只有最重要的特征被保留下来。
L2 正则化:
L2 正则化倾向于使权重趋向于较小的值,但不会将它们强制设为零。这有 助于保持模型的平滑性,并减少模型对训练数据中噪声的敏感性。
Dropout:通过随机地丢弃一部分神经元以及它们的连接,减少神经网络的复杂度来防 止过拟合
weight_decay设置为1e-4较为合适。
全监督数据流程
1.数据处理:
1.1创建数据结构
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)1.2接收数据
from PIL import Image
for j, img_name in enumerate(file_list):#同一文件夹下
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
for i in tqdm(range(11)):#不同文件夹下,将每次接收的数据进行连接
path1 = path + "\%02d"%i
file_list = os.listdir(path1) #返回的是列表
xi = np.zeros((len(file_list),HW,HW,3),dtype=np.uint8)
yi = np.zeros(len(file_list),dtype=np.uint8)
for j,img_name in enumerate(file_list):
img_path = os.path.join(path1,img_name)
img = Image.open(img_path)
img = img.resize((HW,HW)) #重设大小
xi[j,...] = img
yi[j] = i
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X,xi),axis=0)
Y = np.concatenate((Y,yi),axis=0)
1.3数据增广
train_transform = transforms.Compose(
[
transforms.ToPILImage(), #标量转化图片 224 224 3 -> 3 224 224
transforms.RandomResizedCrop(224),
transforms.RandomRotation(50),
transforms.ToTensor() # 其输入数据需要为整形数据,因此要将输入的数据修改为整形, 如果不给予初始数据 那么xi中数据将同img中数据为float64
]
)
val_transform = transforms.Compose(
[
transforms.ToPILImage(), #标量转化图片
transforms.ToTensor() # 其输入数据需要为整形数据,因此要将输入的数据修改为整形, 如果不给予初始数据 那么xi中数据将同img中数据为float64
]
)1.4数据接口
class food_Dataset():
def __init__(self,path,mode = "train"): # 得到数据集
self.mode = mode
if mode == "semi":
self.X= read_path(path,mode)
else:
self.X,self.Y = read_path(path,mode) #读取数据
self.Y = torch.LongTensor(self.Y) #标签应为整形 采用独热编码
if mode == "train":
self.transform = train_transform # 数据增广
else:
self.transform = val_transform
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]),self.X[item]
else:
return self.transform(self.X[item]),self.Y[item]
def __len__(self):
return len(self.X)2.模型构建:
class myModel(nn.Module): #搭建模型框架
def __init__(self,num_class):#分类任务在模型类的init中要传入分类个数
super(myModel,self).__init__() #表示继承父类__init__() 下列几行都是自己的
#3*224*224->512*7*7
self.conv1 = nn.Conv2d(3,64,3,1,1) #64*224*224
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) #64*112*112
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), # 128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) # 128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1), # 256*56*56
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) # 256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1), # 512*28*28
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) # 512*14*14
)
self.pool2 = nn.MaxPool2d(2) # 512*7*7
self.fc1 = nn.Linear(25088,1000)
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000,num_class)
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.pool1(x)
x =self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0],-1)
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x3.模型训练
def train_val(model,train_loader,val_loader,device,epochs,optimizer,loss,save_path):
model = model.to(device)
semi_loader = None
plt_train_loss = [] #记录损失
plt_val_loss = []
plt_train_acc = [] #记录准确率
plt_val_acc = []
max_acc = 0.0
for epoch in range(epochs):
train_loss = 0.0 #初始化备用
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0
start_time = time.time() #记录开始时间
model.train()
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device) #GPU存在可以利用GPU加速计算 但是提取数据对数据进行操作只能在CPU上
pred = model(x) #输入x进入模型得到的对应预测值
train_bat_loss = loss(pred, target)
train_bat_loss.backward() #自动计算梯度,反向传播更新参数
optimizer.step() #更新权重w 之后要梯度清零否则会累积梯度
optimizer.zero_grad() #更新权重之后,将模型计算出的所有参数清零 否侧下次计算的梯度会累加到本次的基础上
train_loss += train_bat_loss.cpu().item() #item()只能在cpu上 用于提取数值转为张量
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
#np.argmax(pred, axis=1) 的作用是找到每个样本的最大值所在的索引
#.detach() 方法会从模型中分离出张量,返回一个新的张量,这个新张量不会参与梯度计算。这样可以避免不必要的内存开销和梯度追踪。(抽离输入模型中的变量)
#.numpy() 方法将 PyTorch 张量转换为 NumPy 数组。将数组进行比较来确定
# axis=0->第一行 =1->第一列 =-1->最后一维(列) =-2->倒数第二维(行)
plt_train_loss.append(train_loss / train_loader.__len__())
plt_train_acc.append(train_acc / train_loader.dataset.__len__()) # 记录准确率,
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
# if epoch % 3 == 0 and plt_val_acc[-1] > 0.6:
# semi_loader = get_semi_loader(no_label_loader, model, device, thres)
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_loss
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1],
plt_val_acc[-1])
) # 打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)