
强化学习代码-基于Q-learning实现迷宫的路径规划-005 包括A*、dijksta、强...
和Dijkstra都可以用来解决迷宫的路径规划问题,但它们各有优劣。Q-learning是一种基于试错的学习算法,适合在未知环境中逐步学习最优策略;而A和Dijkstra则是经典的搜索算法,适合在已知环境中快速找到最优路径。选择哪种算法,取决于具体的应用场景和需求。希望这篇文章能帮助你更好地理解这些算法,并在实际项目中灵活运用。
强化学习代码-基于Q-learning实现迷宫的路径规划-005 包括A*、dijksta、强化学习算法实现迷宫路径规划对比 内容:在迷宫中,存在大量的障碍物,如何规避障碍物,找到一条从初始点到终点的最优路径,改程序程序通过强化学习Q-learning的方法寻找到一条最优路径。
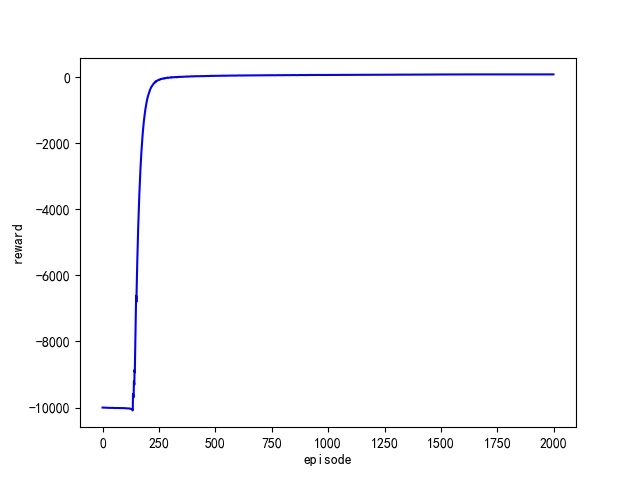
在迷宫的路径规划问题中,我们常常需要找到一条从起点到终点的最优路径,同时避开所有的障碍物。今天,我们就来聊聊如何用强化学习中的Q-learning算法来实现这一目标,顺便对比一下A*和Dijkstra这两种经典的路径规划算法。
迷宫与障碍物
首先,我们需要定义一个迷宫。假设迷宫是一个二维网格,其中某些格子是障碍物,其他格子是可以通过的。我们可以用一个二维数组来表示迷宫,比如:
maze = [
[0, 1, 0, 0, 0],
[0, 1, 0, 1, 0],
[0, 0, 0, 1, 0],
[0, 1, 1, 1, 0],
[0, 0, 0, 0, 0]
]这里,0表示可以通过的格子,1表示障碍物。
Q-learning算法
Q-learning是一种无模型的强化学习算法,它通过不断试错来学习最优策略。在迷宫的路径规划中,我们可以将每个格子看作一个状态,动作可以是向上、向下、向左或向右移动。Q-learning的核心是Q表,它记录了在每个状态下采取每个动作的预期奖励。
import numpy as np
Q = np.zeros((len(maze), len(maze[0]), 4)) # 4个动作:上、下、左、右
# 定义参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # 探索率
# 定义动作
actions = ['up', 'down', 'left', 'right']
# Q-learning主循环
for episode in range(1000):
state = (0, 0) # 起点
while state != (4, 4): # 终点
# 选择动作
if np.random.rand() < epsilon:
action = np.random.choice(actions)
else:
action = actions[np.argmax(Q[state[0], state[1]])]
# 执行动作
if action == 'up':
next_state = (state[0] - 1, state[1])
elif action == 'down':
next_state = (state[0] + 1, state[1])
elif action == 'left':
next_state = (state[0], state[1] - 1)
elif action == 'right':
next_state = (state[0], state[1] + 1)
# 检查是否越界或遇到障碍物
if next_state[0] < 0 or next_state[0] >= len(maze) or next_state[1] < 0 or next_state[1] >= len(maze[0]) or maze[next_state[0]][next_state[1]] == 1:
next_state = state
# 计算奖励
if next_state == (4, 4):
reward = 100
else:
reward = -1
# 更新Q表
Q[state[0], state[1], actions.index(action)] += alpha * (reward + gamma * np.max(Q[next_state[0], next_state[1]]) - Q[state[0], state[1], actions.index(action)])
# 更新状态
state = next_state代码分析
在这个Q-learning的实现中,我们首先初始化了一个Q表,大小为迷宫的行数乘以列数,再乘以4个动作。然后,我们定义了学习率alpha、折扣因子gamma和探索率epsilon。
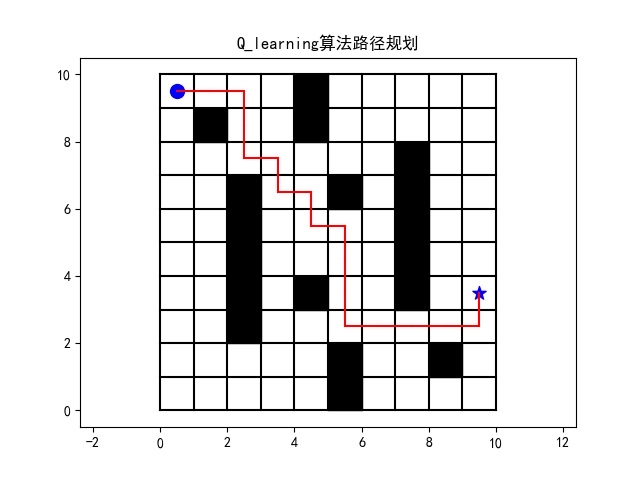
在每一次迭代中,我们从起点开始,根据当前状态和Q表选择动作。如果随机数小于探索率,我们就随机选择一个动作;否则,我们选择当前状态下Q值最大的动作。执行动作后,我们更新状态,并根据新状态计算奖励。最后,我们使用Q-learning的更新公式来更新Q表。
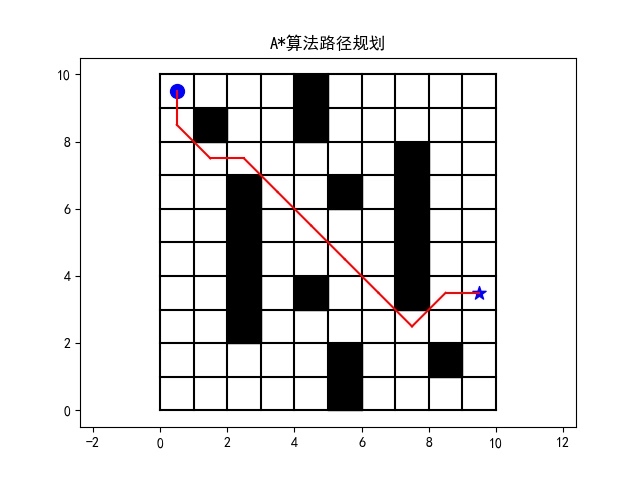
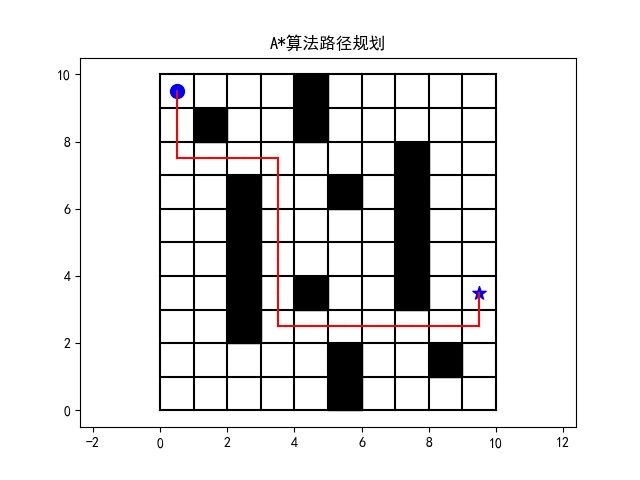
对比A*和Dijkstra
A和Dijkstra是两种经典的路径规划算法。Dijkstra算法通过广度优先搜索来找到最短路径,而A算法则在Dijkstra的基础上引入了启发式函数,可以更快地找到最优路径。
import heapq
def dijkstra(maze, start, end):
# 初始化距离表
dist = [[float('inf')] * len(maze[0]) for _ in range(len(maze))]
dist[start[0]][start[1]] = 0
heap = [(0, start)]
while heap:
current_dist, (x, y) = heapq.heappop(heap)
if (x, y) == end:
break
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
nx, ny = x + dx, y + dy
if 0 <= nx < len(maze) and 0 <= ny < len(maze[0]) and maze[nx][ny] == 0:
if current_dist + 1 < dist[nx][ny]:
dist[nx][ny] = current_dist + 1
heapq.heappush(heap, (dist[nx][ny], (nx, ny)))
return dist[end[0]][end[1]]
def astar(maze, start, end):
# 启发式函数
def heuristic(a, b):
return abs(a[0] - b[0]) + abs(a[1] - b[1])
# 初始化距离表
dist = [[float('inf')] * len(maze[0]) for _ in range(len(maze))]
dist[start[0]][start[1]] = 0
heap = [(0 + heuristic(start, end), 0, start)]
while heap:
_, current_dist, (x, y) = heapq.heappop(heap)
if (x, y) == end:
break
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
nx, ny = x + dx, y + dy
if 0 <= nx < len(maze) and 0 <= ny < len(maze[0]) and maze[nx][ny] == 0:
if current_dist + 1 < dist[nx][ny]:
dist[nx][ny] = current_dist + 1
heapq.heappush(heap, (dist[nx][ny] + heuristic((nx, ny), end), dist[nx][ny], (nx, ny)))
return dist[end[0]][end[1]]总结
Q-learning、A和Dijkstra都可以用来解决迷宫的路径规划问题,但它们各有优劣。Q-learning是一种基于试错的学习算法,适合在未知环境中逐步学习最优策略;而A和Dijkstra则是经典的搜索算法,适合在已知环境中快速找到最优路径。选择哪种算法,取决于具体的应用场景和需求。
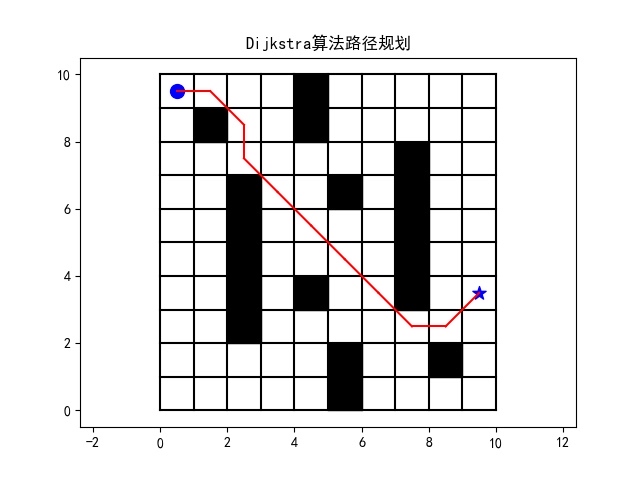
希望这篇文章能帮助你更好地理解这些算法,并在实际项目中灵活运用。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)