
STEP3-VL-10B部署教程:CSDN算力平台镜像免配置,5分钟启用多模态服务
本文介绍了如何在星图GPU平台上自动化部署STEP3-VL-10B多模态视觉语言模型(阶跃星辰)。该平台提供的预置镜像免去了复杂的环境配置,用户可快速启用服务。该模型能理解图像内容并进行对话,典型应用场景包括分析包含图表和公式的数学题图片,并给出推理和解答。
STEP3-VL-10B部署教程:CSDN算力平台镜像免配置,5分钟启用多模态服务
想体验一个能看懂图片、理解图表、甚至帮你分析复杂文档的AI助手吗?今天要介绍的STEP3-VL-10B,就是一个让你5分钟就能上手的多模态视觉语言模型。
这个模型最吸引人的地方在于,它虽然只有100亿参数,但在很多任务上的表现,能媲美那些参数大它10-20倍的“巨无霸”模型。更棒的是,现在通过CSDN算力平台的预置镜像,你完全不需要折腾环境配置,点几下鼠标就能用上。
这篇文章,我就带你从零开始,一步步在CSDN算力平台上部署并启动STEP3-VL-10B。整个过程非常简单,就像安装一个普通软件一样,你不需要懂复杂的命令行,也不需要担心显卡驱动、Python环境这些麻烦事。
1. 认识STEP3-VL-10B:小而强的多模态模型
在开始动手之前,我们先花两分钟了解一下STEP3-VL-10B到底是什么,它能做什么。
STEP3-VL-10B是由阶跃星辰(StepFun)开源的一个轻量级多模态基础模型。简单来说,它就是一个既能“看”又能“说”的AI。你给它一张图片,它能告诉你图片里有什么;你给它一个图表,它能帮你分析数据;你问它一个关于图片的问题,它能像人一样跟你对话解答。
别看它只有100亿参数,它的能力可一点都不“轻量”。在几个权威的评测基准上,它的表现都达到了同级别模型的最优水平,甚至在某些任务上,比那些参数大得多的模型还要好。
下面这个表格,能让你更直观地了解它的核心能力:
| 能力领域 | 测试项目 | 得分表现 | 这意味着什么 |
|---|---|---|---|
| STEM推理 | MMMU | 78.11 | 在科学、技术、工程、数学等复杂问题上,理解和推理能力很强。 |
| 数学视觉 | MathVista | 83.97 | 能看懂图表、图形中的数学问题,并给出解答。 |
| 视觉识别 | MMBench (EN) | 92.05 | 对图片中物体、场景、关系的识别非常准确。 |
| OCR文档 | OCRBench | 86.75 | 从图片或扫描件中提取文字信息的能力出色。 |
| GUI定位 | ScreenSpot-V2 | 92.61 | 能理解软件界面,精准定位界面上的按钮、菜单等元素。 |
这些分数可能听起来有点抽象,我举个例子你就明白了。比如你拍一张数学题的图片(包含图表和公式)发给它,它不仅能识别出图片里的文字,还能理解题目的意思,并一步步推理出正确答案。这对于学生、研究人员或者需要处理大量文档的人来说,是个非常实用的工具。
2. 环境准备:在CSDN算力平台创建实例
传统的模型部署,往往需要自己准备服务器、安装显卡驱动、配置CUDA环境、解决各种依赖包冲突……这个过程足以劝退很多人。但现在,我们可以利用CSDN算力平台提供的“镜像”功能,跳过所有繁琐步骤。
镜像,你可以把它理解为一个“软件快照”。平台已经帮我们把STEP3-VL-10B模型、运行所需的所有软件环境(Python、PyTorch、依赖库等)都打包好了。我们只需要选择这个镜像来创建一台云服务器,一切就都准备就绪了。
整个准备过程只需要三步:
- 访问CSDN算力平台:打开CSDN星图镜像广场或算力平台页面。
- 选择STEP3-VL-10B镜像:在镜像广场搜索“STEP3-VL-10B”,找到由官方或社区维护的预置镜像。通常镜像描述里会写明已集成WebUI和API服务。
- 创建算力实例:
- 选择你需要的GPU型号(模型要求至少24GB显存,推荐使用A100或RTX 4090及以上规格)。
- 系统会自动加载你选择的镜像。
- 配置其他资源(如CPU、内存,按推荐配置即可)。
- 点击“创建”或“启动”。
等待几分钟,你的专属STEP3-VL-10B服务器就创建好了。平台会自动完成所有底层环境的初始化,你完全不需要介入。
3. 快速启动:5分钟开启WebUI对话服务
实例创建成功后,我们进入最关键的一步——启动服务。得益于镜像的预配置,这一步简单到超乎想象。
3.1 通过Supervisor一键启动(推荐)
这是最省心的方法。镜像已经使用 Supervisor 这个工具配置好了后台服务。Supervisor就像一个“服务管家”,能保证我们的Web界面在服务器启动后自动运行,即使遇到意外中断也能自动重启。
你几乎什么都不用做:
- 进入你的算力实例管理页面。
- 在右侧的导航栏或“快速访问”区域,找到名为 “WebUI” 或标注端口为 7860 的访问链接。
- 点击这个链接。
浏览器会自动打开一个新标签页,地址类似这样:https://gpu-pod[你的实例ID]-7860.web.gpu.csdn.net/。稍等片刻,你就能看到STEP3-VL-10B的Web聊天界面了! 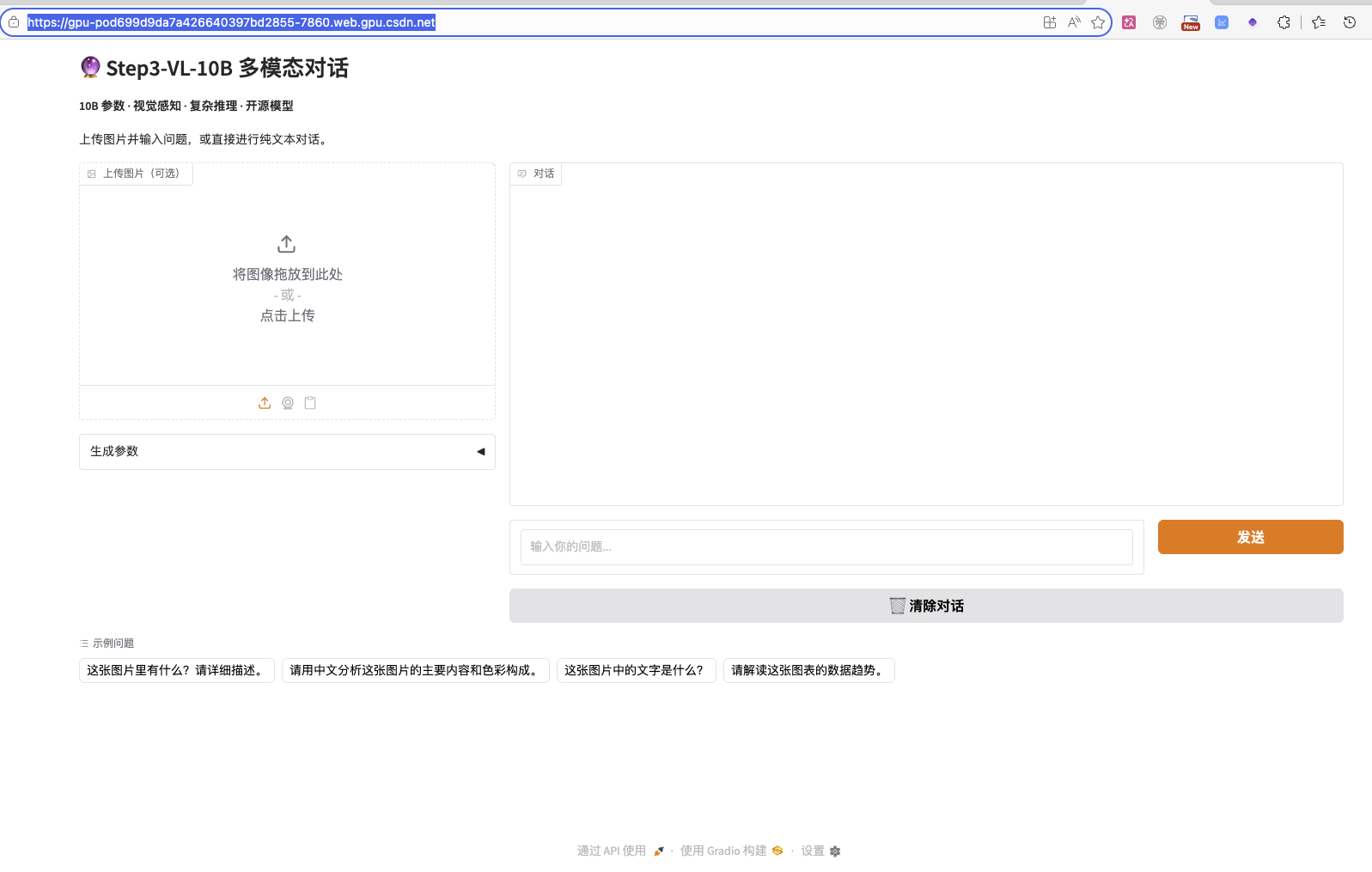
服务管理小贴士(如果需要):
虽然服务是自动运行的,但了解如何管理它也没坏处。你可以通过SSH连接到你的服务器,使用简单的命令来查看或控制服务状态:
# 查看所有服务的状态
supervisorctl status
# 停止WebUI服务(比如想暂时关闭)
supervisorctl stop webui
# 重启WebUI服务(比如修改了配置后)
supervisorctl restart webui
# 启动WebUI服务
supervisorctl start webui
# 停止所有由Supervisor管理的服务
supervisorctl stop all
如果你想修改WebUI服务的启动端口(比如从7860改为其他端口),可以编辑启动脚本文件 /usr/local/bin/start-webui-service.sh,修改其中的 --port 7860 参数即可。
3.2 手动启动Gradio WebUI(备选)
如果自动启动遇到问题,或者你想更深入了解启动过程,也可以选择手动启动。操作也很简单:
- 通过SSH或平台提供的终端连接到你的服务器。
- 依次执行以下三条命令:
# 1. 进入模型目录
cd ~/Step3-VL-10B
# 2. 激活Python虚拟环境(镜像已预装)
source /Step3-VL-10B/venv/bin/activate
# 3. 启动WebUI服务
python3 webui.py --host 0.0.0.0 --port 7860
执行后,终端会显示服务启动日志。同样,在浏览器访问平台提供的7860端口链接,就能打开界面。 
4. 开始使用:两种方式与模型交互
服务启动后,你就可以和这个强大的多模态模型对话了。它主要提供两种使用方式:直观的网页界面和灵活的编程接口。
4.1 使用Gradio WebUI(适合所有人)
这是最简单直观的方式,打开网页就能用,像聊天一样。
- 上传图片:点击聊天框上方的图片上传按钮,选择本地图片。
- 输入问题:在下面的输入框里,用文字描述你的问题。比如:
- “描述一下这张图片里有什么。”
- “这张图表展示了什么趋势?”
- “图片里的这个人穿着什么颜色的衣服?”
- 获取回答:点击发送,模型就会分析图片并生成文字回答。
你可以进行多轮对话,模型能记住之前的聊天上下文。这对于需要深入分析一张复杂图片的场景特别有用。
4.2 调用OpenAI兼容API(适合开发者)
如果你想把这个模型的能力集成到自己的应用程序、脚本或者自动化工作流里,那么API方式就是最佳选择。STEP3-VL-10B的API设计成和OpenAI的格式兼容,这意味着如果你用过ChatGPT的API,几乎可以无缝切换过来。
基础文本对话示例: 这个例子展示如何进行一次简单的纯文本对话。你需要将命令中的URL替换成你自己的服务器地址。
curl -X POST https://gpu-pod699d9da7a426640397bd2855-7860.web.gpu.csdn.net/api/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Step3-VL-10B",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己。"}
],
"max_tokens": 1024
}'

多模态对话示例(图片理解): 这才是STEP3-VL-10B的精华所在。下面的例子展示了如何让模型分析一张网络图片。在content字段里,我们同时传递了图片URL和文本指令。
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Step3-VL-10B",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"}
},
{
"type": "text",
"text": "请详细描述这张图片,包括主体、背景、颜色和可能的场景。"
}
]
}
],
"max_tokens": 1024
}'

API使用关键点:
- 地址:如果你在服务器本地调用,可以用
http://localhost:8000;如果从外部调用,需要使用CSDN平台提供的外网访问地址(通常是7860端口,但API路径在/api/v1下)。 - 图片输入:
content可以是一个数组,混合image_url和text对象,实现图文对话。 - 模型名称:在请求中指定
"model": "Step3-VL-10B"。 - 格式:整个请求格式与OpenAI的ChatCompletion API保持一致,降低了学习成本。
5. 总结与下一步
通过上面的步骤,你应该已经成功在CSDN算力平台上跑起了STEP3-VL-10B模型,并且通过WebUI或API和它进行了对话。回顾一下,整个过程的核心优势就是 “免配置” 和 “开箱即用”。平台镜像帮我们解决了所有环境依赖问题,Supervisor服务保证了稳定性,我们只需要专注于使用模型本身。
你可以尝试的下一步:
- 探索更多功能:试试上传更复杂的图片,比如带表格的文档、信息图、设计草图,看看模型的理解能力如何。
- 集成到工作流:如果你是开发者,可以尝试用Python的
openai库(将base_url指向你的API地址)来调用,将其集成到你的数据分析、内容审核或自动化客服系统中。 - 调整参数:在API调用中,可以尝试调整
temperature(创造性)、max_tokens(生成长度)等参数,获得不同的输出效果。 - 参考官方资源:遇到深入的技术问题或想了解模型细节,可以访问STEP3-VL-10B的官方资源:
- GitHub仓库: https://github.com/stepfun-ai/Step3-VL-10B
- HuggingFace模型页: https://huggingface.co/stepfun-ai/Step3-VL-10B
- 魔搭ModelScope: https://modelscope.cn/models/stepfun-ai/Step3-VL-10B
- 技术论文: https://arxiv.org/abs/2601.09668
希望这篇教程能帮你轻松开启多模态AI的大门。现在,就去上传你的第一张图片,开始和这个“视觉助手”对话吧!
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。
更多推荐
 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)