
【上位机心法】榨干 GPU 算力:基于 Qt/QML 与 QSG 构建百万级数据点的专业示波器渲染引擎
构建一个专业级的上位机,是一场关于“数据生命周期”的精妙调度。从微安级的电流流过分流电阻,到 ADC 采样转化为二进制字节,再穿过 USB 的复合端点到达 PC,进入 C++ 的无锁环形缓冲区,经历极值降维的洗礼,最终化作顶点坐标被送入 GPU 的着色器。这套融合了底层物理+协议栈+高性能并行渲染的架构,不仅仅是为了“好看”。它让你打造的工具拥有了一双洞悉一切的眼睛,无论是看门狗复位前那 1 微秒
摘要:在开发专业级测量仪器(如功耗分析仪、示波器)的上位机时,标准图表组件(如 QChart / QCustomPlot)的 CPU 栅格化渲染方案注定无法胜任海量高频数据的实时刷新。本文将解构高性能波形渲染的三大支柱:C++ 层的无锁环形缓冲区、基于显示器分辨率的像素级数据降维算法,以及利用 Qt Scene Graph (
QSGGeometryNode) 直接向 GPU 提交顶点数据的终极黑魔法,带你打造丝滑的 60fps 数据可视化体验。
一、 QChart 的原罪:为什么你的图表会卡死?
当我们向标准图表库添加一个数据点时,底层到底发生了什么?
以 QChart 为例,它基于 QGraphicsView 框架。当你添加 10 万个点时,它实际上在内存中创建了 10 万个极为复杂的图元对象(包含坐标、画笔状态、碰撞检测边界等)。 每次刷新时,CPU 需要遍历这 10 万个对象,计算它们在屏幕上的投影,然后用 CPU 算力把它们转化为像素(栅格化)。
内存爆炸 + CPU 满载 = 界面猝死。
破局思路:我们要的不是 10 万个拥有独立属性的“高阶对象”,我们要的仅仅是屏幕上的一条**“线”**。我们必须绕过 CPU,直接和显卡(GPU)对话。
二、 内存的哲学:无锁环形缓冲区 (Ring Buffer)
在渲染之前,先解决数据的存储问题。 底层单片机的数据源源不断地通过 USB 涌入。如果你用 std::vector 存储,当超过屏幕显示范围时,你可能会调用 erase(vector.begin()) 来删除老数据。 这是毁灭性的。 擦除头部元素会导致后面数百万个内存块整体前移,耗尽 CPU 周期。
静态内存,循环覆盖
我们必须在 C++ 层实现一个固定大小的 环形缓冲区。
template<typename T, size_t Size>
class LockFreeRingBuffer {
private:
std::array<T, Size> buffer;
std::atomic<size_t> head{0}; // 写入指针
std::atomic<size_t> tail{0}; // 读取指针
public:
void push(const T& item) {
size_t next = (head + 1) % Size;
buffer[head] = item;
head = next;
// 如果 head 追上 tail,说明满了,强制覆盖老数据,推进 tail
}
// ...
};当我们需要渲染当前屏幕的波形时,只需提供一个当前的读取切片(Span),没有任何内存的动态分配(new/delete)与大块搬运。
三、 降维打击:像素级极值提取 (Min-Max Decimation)
这里有一个残酷的物理事实:
你的 4K 显示器,横向最多只有 3840 个像素。
如果你要把 100 万个数据点塞进这 3840 个像素里,意味着每一个横向像素点,叠了 260 个数据点。
如果你把这 100 万个点全部画出来,GPU 绝大多数时间都在同一个像素列里上下涂抹,毫无意义。
极值降维算法
在 C++ 准备顶点数据时,我们根据当前的缩放比例(Zoom Level),计算出每个像素列对应多少个原始数据点(比如 $N = 260$)。
在遍历这 $N$ 个点时,我们不画 260 条线,而是只找出这 260 个点中的最大值 ($V_{max}$) 和最小值 ($V_{min}$)。
然后,在这个像素列画一条从 $V_{min}$ 到 $V_{max}$ 的垂直线段。
结果:100 万个数据点,被瞬间压缩成了 3840 条垂直线段(7680 个顶点)。波形的毛刺(毛噪)被完美保留,但渲染压力降低了三个数量级!
四、 终极黑魔法:QML 与 Qt Scene Graph (QSG)
在现代 Qt (Qt 5/6) 中,QML 的底层渲染引擎是 Scene Graph。它直接利用 OpenGL/Vulkan/DirectX 将图元转化为显卡指令。
我们不使用 QML 自带的 Canvas 或 Chart,而是通过 C++ 继承 QQuickItem,重写底层的 updatePaintNode 函数。
绕过画笔,直击顶点
我们要做的,是创建一个 QSGGeometryNode(几何节点),直接把我们在第三步算出的顶点数组,丢进 GPU 的显存里。
QSGNode* WaveformItem::updatePaintNode(QSGNode *oldNode, UpdatePaintNodeData *) {
QSGGeometryNode *node = static_cast<QSGGeometryNode *>(oldNode);
QSGGeometry *geometry;
if (!node) {
node = new QSGGeometryNode;
geometry = new QSGGeometry(QSGGeometry::defaultAttributes_Point2D(), 0);
geometry->setDrawingMode(QSGGeometry::DrawLineStrip); // 绘制连续线段
node->setGeometry(geometry);
node->setFlag(QSGNode::OwnsGeometry);
QSGFlatColorMaterial *material = new QSGFlatColorMaterial;
material->setColor(QColor(0, 255, 0)); // 经典的示波器荧光绿
node->setMaterial(material);
node->setFlag(QSGNode::OwnsMaterial);
} else {
geometry = node->geometry();
}
// 更新顶点数据 (decimated_points 是我们降维后的顶点集合)
geometry->allocate(decimated_points.size());
QSGGeometry::Point2D *vertices = geometry->vertexDataAsPoint2D();
for (int i = 0; i < decimated_points.size(); ++i) {
vertices[i].set(decimated_points[i].x, decimated_points[i].y);
}
node->markDirty(QSGNode::DirtyGeometry); // 告诉 GPU:数据脏了,去重绘吧!
return node;
}把这个 C++ 类注册到 QML 中。前端只需要写一行 WaveformItem { anchors.fill: parent }。
在这套架构下,CPU 只负责逻辑与降维,绘图工作 100% 交由 GPU 并发处理,界面刷新率死死咬住显示器的 60Hz,毫无波澜。
五、 专业级交互:触发 (Trigger) 与 游标 (Cursor)
光能画线还不够,测量仪器的灵魂在于交互。
1. 软件触发机制 (Software Trigger)
如果数据一直在滚动,人眼根本看不清波形。我们需要像示波器一样,设置一个触发电平(比如上升沿跨过 3.3V 时画面静止)。
架构位置:触发逻辑绝不能写在 UI 渲染层。它必须在 C++ 的底层数据接收线程中。
当接收线程发现当前电压突破了阈值电平,它锁定当前的环形缓冲区切片,并抛出一个 Signal 通知前端 UI 停止更新缓冲索引,将这一帧画面“冻结”在屏幕上。
2. 响应式游标 (Cursors)
在 QML 视图层,我们可以轻松叠加两条垂直的“游标线”。
通过 QML 的拖拽属性(Drag.active),获取 X 坐标。将 X 坐标逆向映射为时间 $T$,并在 C++ Model 中查表得出此时的电压 $V$。
利用 QML 的声明式绑定,自动计算并实时显示差值:
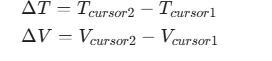
六、 结语:数据的全景与显微镜
构建一个专业级的上位机,是一场关于 “数据生命周期” 的精妙调度。
从微安级的电流流过分流电阻,到 ADC 采样转化为二进制字节,再穿过 USB 的复合端点到达 PC,进入 C++ 的无锁环形缓冲区,经历极值降维的洗礼,最终化作顶点坐标被送入 GPU 的着色器。
这套融合了 底层物理+协议栈+高性能并行渲染 的架构,不仅仅是为了“好看”。它让你打造的工具拥有了一双洞悉一切的眼睛,无论是看门狗复位前那 1 微秒的电压跌落,还是电机启动时那 1 毫秒的电流尖峰,都在这块毫无延迟的屏幕上无所遁形。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)