
北大&清华&DeepSeek:唤醒闲置网卡,卡住大模型的不是算力,而是硬盘到网卡的 I/O 带宽!
DualPath 并没有发明新的 GPU 或更快的网卡,而是用极其敏锐的系统工程视角,找出了木桶上最短的那块板——预填充节点的存储网卡。通过“化零为整”,把闲置的解码节点带宽拉入战局,DualPath 优雅地化解了 Agent 时代的 I/O 危机。对于正在构建下一代长文本、多智能体协作系统的基础架构团队来说,DualPath 提供了一条极具价值的优化指引路线。
随着 ChatGPT 等大语言模型(LLM)从单轮对话机器人进化为能够自主规划、调用工具的智能体(Agent),我们的服务器正在经历一场前所未有的考验 。
很多开发者发现,在跑 Agent 任务时,昂贵的 GPU 居然在大量时间里“无所事事”地摸鱼。到底是谁拖慢了推理速度?今天,我们要解读的这篇顶会级别论文揭示了真相:卡住大模型的不是算力,而是硬盘到网卡的 I/O 带宽!

发现“真凶”:为什么 GPU 会大面积闲置?
在 Agent 的工作流中,AI 需要与环境进行几十甚至上百轮的交互(比如写代码、报错、修改、再运行)。这种模式有两个显著特点:
-
上下文极长且不断累积: Agent 的历史轨迹动辄几万甚至几十万 Token。
-
KV-Cache 命中率极高: 每一轮只有少量新生成的词,高达 95% 以上的历史 Context 是重复的。
由于显存(HBM)和内存(DRAM)容量有限,海量的历史 KV-Cache 必须存放在便宜的大容量 SSD 存储集群中 。每次交互,系统都需要从外存中重新拉取这些庞大的数据。
目前业界主流的推理架构是 Prefill-Decode(PD)分离架构 :
-
Prefill 节点(预填充): 负责吃进长文本,算力需求大,负责把存储里的 KV-Cache 搬进显存。
-
Decode 节点(解码): 负责一个词一个词往外蹦,对延迟敏感。
灾难就发生在这里! 在现有架构中,所有的历史 KV-Cache 都只能由 Prefill 节点从外部存储中读取 。这导致 Prefill 节点的存储网卡(SNIC)直接被 100% 跑满,彻底瘫痪;而另一边,Decode 节点的存储网卡却常年闲置,无所事事 。
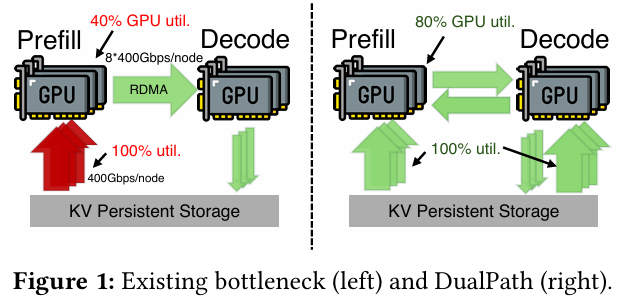
破局之道:DualPath(双通道加载)架构
既然 Prefill 节点的网卡被撑爆了,而 Decode 节点在闲置,能不能让 Decode 节点过来帮帮忙?
这就是 DualPath 的核心思想:引入双通道 KV-Cache 加载机制 。
除了传统的“存储 -> Prefill”路径外,DualPath 开辟了一条史无前例的“奇招”路径:
-
借道拉取: 先让闲置的 Decode 节点从外部存储中把 KV-Cache 拉出来。
-
高速转移: 然后利用节点间超高速的计算网络(通过 RDMA),把这些数据瞬间传给 Prefill 节点。
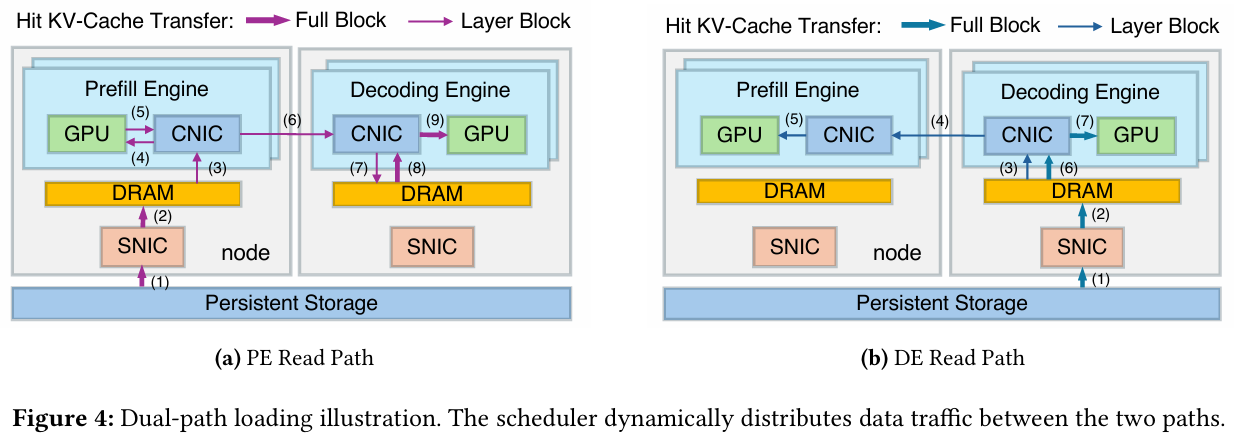
通过这种“劫富济贫”的流量调度策略,DualPath 把全集群的存储带宽利用率直接拉满,彻底打破了单点瓶颈 。
这种设计会引发新的网络拥堵吗?(硬核推导)
你可能会问:把数据在计算网络里来回倒腾,会不会把计算网卡也挤爆?研究团队给出了严格的数学证明。假设 ggg 为单节点 GPU 数量,sss 为单节点存储网卡带宽倍率:
Prefill 节点读取路径上的流量 TpT_pTp 满足公式 :
Tp=Bs/(Dg2)T_p = Bs/(Dg^2)Tp=Bs/(Dg2)
Decode 节点读取路径上的流量 TcT_cTc 满足公式 :
Tc=Bs/(Pg2)T_c = Bs/(Pg^2)Tc=Bs/(Pg2)
为了保证计算网卡在写入和读取操作时均不产生瓶颈,系统的前后置节点比例 P/DP/DP/D 必须满足一定的边界条件 :
sg−s≤P/D≤g−2ss\frac{s}{g-s} \le P/D \le \frac{g-2s}{s}g−ss≤P/D≤sg−2s
论文证明,在大多数实际的高性能集群配置下,这个安全区间能够完美覆盖正常的部署比例,绝对不会引发新的网络拥堵 。
两大核心黑科技,为 DualPath 保驾护航
想法很美好,但在工程落地时,如何保证搬运数据时不影响 AI 本身的推理运算?DualPath 祭出了两大杀器:
黑科技一:CNIC 为中心的流量管家 (Traffic Isolation)
AI 推理时有很多对延迟极其敏感的通信操作(比如并行计算时的 AllToAll)。如果搬运 KV-Cache 的“货车”堵住了 AI 推理的“救护车”,那整个模型的速度就会断崖式下跌。
DualPath 使用了 InfiniBand 的虚拟信道(Virtual Lanes, VL)技术 。它给模型推理分配了具有 99% 绝对优先级的“VIP 车道”,而 KV-Cache 的搬运只能在“普通车道”上捡漏(利用闲置带宽)。这样既搬了砖,又绝不添乱 。
黑科技二:全局动态调度器 (Adaptive Request Scheduler)
由于有了两条读取路径,系统需要一个绝顶聪明的“大脑”来决定:这个任务是走 Prefill 直读,还是走 Decode 借道?
DualPath 的调度器会实时监控各个节点的 GPU Token 负载 和 磁盘排队长度 。它优先将请求分配给那些存储排队短的节点,确保大家“有饭一起吃,有活一起干” 。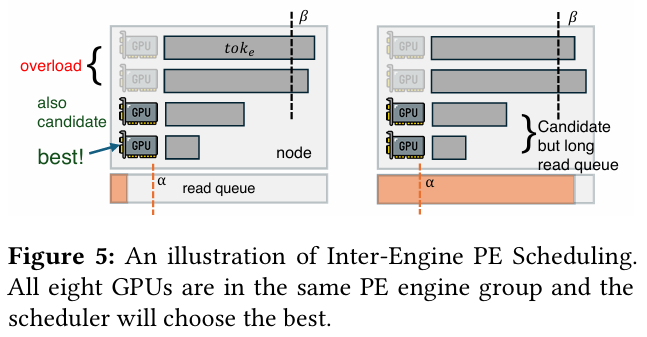
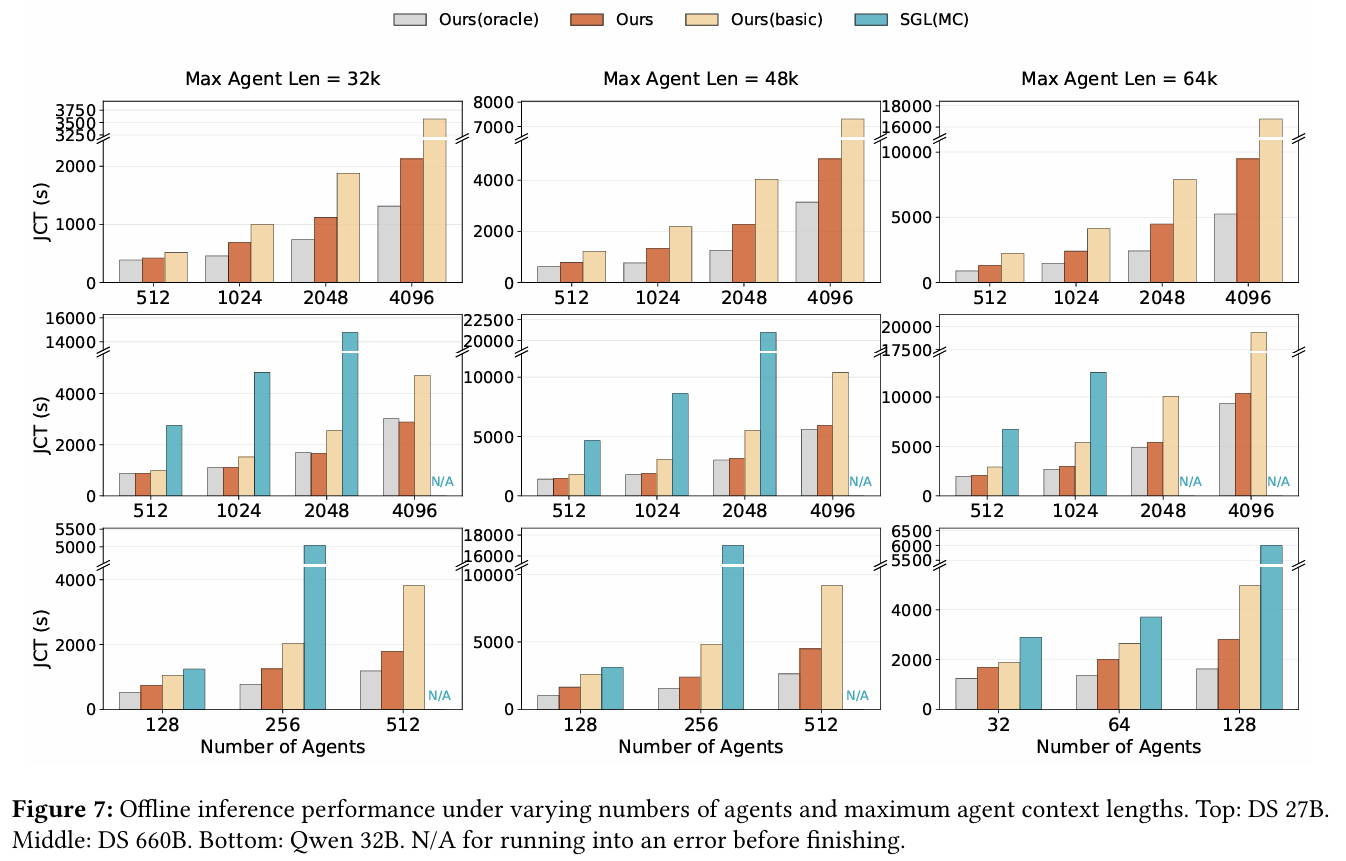
惊艳的性能表现
理论再强,也得上机跑跑看。研究团队在 DeepSeek V3.2 660B、Qwen2.5-32B 等主流大模型上进行了真实的 Agentic 业务压测 。
-
离线推理吞吐量(Offline Inference): 在长上下文、多轮交互的压测中,相较于未经优化的系统,DualPath 将任务吞吐量提升了最高 1.87 倍 !这意味着原本需要跑近两个小时的强化学习收集任务,现在一小时内就能搞定。
-
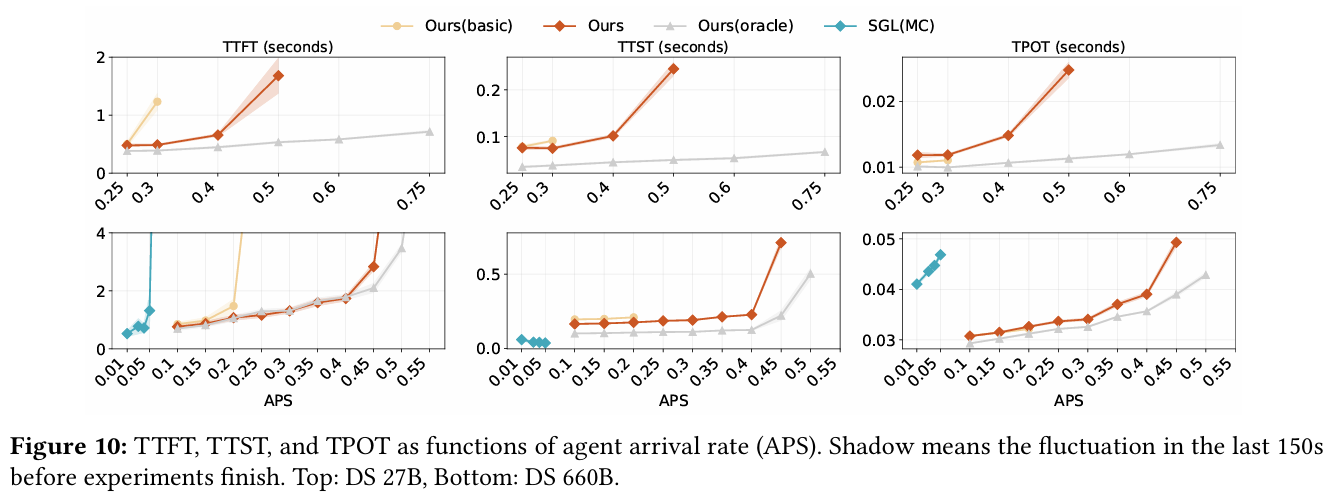
在线服务(Online Serving): 在保证首字延迟(TTFT)和生成延迟(TPOT)达标的前提下,DualPath 能够承载的系统并发量平均提升了 1.96 倍。
总结
DualPath 并没有发明新的 GPU 或更快的网卡,而是用极其敏锐的系统工程视角,找出了木桶上最短的那块板——预填充节点的存储网卡 。通过“化零为整”,把闲置的解码节点带宽拉入战局,DualPath 优雅地化解了 Agent 时代的 I/O 危机 。
对于正在构建下一代长文本、多智能体协作系统的基础架构团队来说,DualPath 提供了一条极具价值的优化指引路线。
- 论文标题:DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference
- 论文链接:https://arxiv.org/pdf/2602.21548
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)