
从东西向到南北向:Border Leaf如何实现智算中心网络的“全向通达“
Type-5路由的自动传播让全网Leaf设备都能获得默认路由,实现了一处配置,全网生效的智能化管理。,每一台Leaf设备都能独立处理本地的三层转发,在Anycast Gateway的加持下,解决智算中心网络中最核心的延迟问题,配合多路ECMP、MTU 9000等技术,才能真正称得上是“大厂级”的算力底座。理论上讲,有两种架构方案,其中最常用的就是Border Leaf(边界叶交换机)架构,这种设计
前面几次实验的强度,可能有点大,除了基础架构都是Spine-Leaf的Clos架构之外,其余各有差异。
如果只是简单的Underlay网络,我们可以配置使用OSPF进行互通(双Spine架构实战:OSPF+ECMP打通智算中心任督二脉);对于大规模场景,我们更推荐配置使用BGP(四路ECMP玄机:用BGP玩转智算网络迷宫)。
Underlay网络跑通之后,我们就可以着手搭建Overlay网络了,例如使用BGP + EVPN + VXLAN技术(从零搭建EVPN/VXLAN网络:4-Spine架构下的高性能Overlay完全配置指南,打通智算中心任督二脉),可以轻松实现跨Leaf的大二层网络扩展。通过抓包分析(抓包带你搞懂VXLAN报文封装全流程,同时看看ECMP四路径负载均衡如何智能分流),我们不仅看清了VXLAN报文的庐山真面目,更理解了ECMP如何通过随机Hash实现流量负载均衡,为RDMA无损网络打下基础。
摸清了原理,规模的扩展也只是配置量的叠加,不止可以上到4-Spine + 12-Leaf的Clos架构大规模集群(挑战极限!4-Spine+12-Leaf超大规模BGP/EVPN集群收敛性能的"终极考验"实战),即使再大规模的智算中心集群也是一个道理(2048卡H100算力中心100G无阻塞存储网建设方案)。
俗话说内外兼修,方得始终!任何数据中心都不是只有东西向流量,还会有拉取外网镜像、下载数据集、接受互联网访问等南北向流量。
对于小规模数据中心,可以使用EVPN L3VPN集中式网关(从二层到三层:EVPN L3VPN集中式网关配置及四种流量场景深度剖析),这种方式的优点是配置简单,缺点是跨网段流量会频繁地在物理链路上往返,即“三层绕路”,这对于追求极低延迟的RDMA无损网络中是极为致命的。所以,大规模集群会选择分布式网关(EVPN分布式网关实战:Anycast Gateway如何实现网络性能的"质变"),每一台Leaf设备都能独立处理本地的三层转发,在Anycast Gateway的加持下,解决智算中心网络中最核心的延迟问题,配合多路ECMP、MTU 9000等技术,才能真正称得上是“大厂级”的算力底座。
解决了东西向流量问题,我们再看看南北向流量。
理论上讲,有两种架构方案,其中最常用的就是Border Leaf(边界叶交换机)架构,这种设计可以将集群内部的复杂性与外部网络的策略完全解耦,而且可以横向扩展多组Border Leaf,不影响物理架构。
与之对应的就是Border Spine(边界脊交换机)架构,虽然南北向流量可以直接从Spine设备出去,不需要经过Leaf设备转发,减少了VXLAN解封装后的转发跳数;但是,从经济角度来看,现代数据中心的Spine设备端口极其珍贵,且扩展难度大,Border Spine架构会拉高数据中心建设成本。当然,最重要的,这种让Spine设备既当高速公路又当海关口岸的架构,简直是赶鸭子上架,不仅大材小用,还风险重重:
1、出口路由抖动可能导致Spine设备BGP进程卡顿,从而冲击全网收敛;
2、Spine设备需要额外承载VRF、防火墙邻居以及海量外部路由前缀等职责,消耗设备性能;
3、此时Spine设备会更脆弱,如果宕机会直接导致整个集群内部带宽大幅衰减,影响东西向流量正常转发。
南北向出口选在哪儿,直接决定了整个集群的扩展性、稳定性和运维成本。所以,我们本次也就选择更为稳妥的Border Leaf架构,让VXLAN隧道内的业务流量,安全、有序地穿过海关,抵达外部网络。
本次实验,我们直接在上个实验的基础上继续即可。实验平台还是48核vCPU、96 GB内存的EVE-NG社区版6.2.0,实验设备配置为4-Spine + 4-Leaf + 8-Server 的标准Clos架构,在Leaf1设备上旁挂一台VSR设备连接外网。组网拓扑图如下所示:
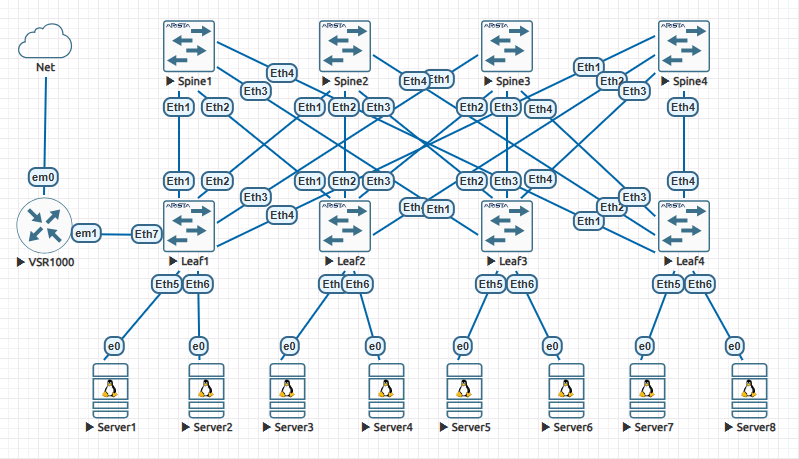
其中,Spine/Leaf交换机均使用Arista vEOS的4.35.1版本,资源配置为2核CPU、4 GB内存;服务器使用Ubuntu 20.04,资源配置为2核CPU、2 GB内存。Spine设备与Leaf设备之间的互联情况如下所示:
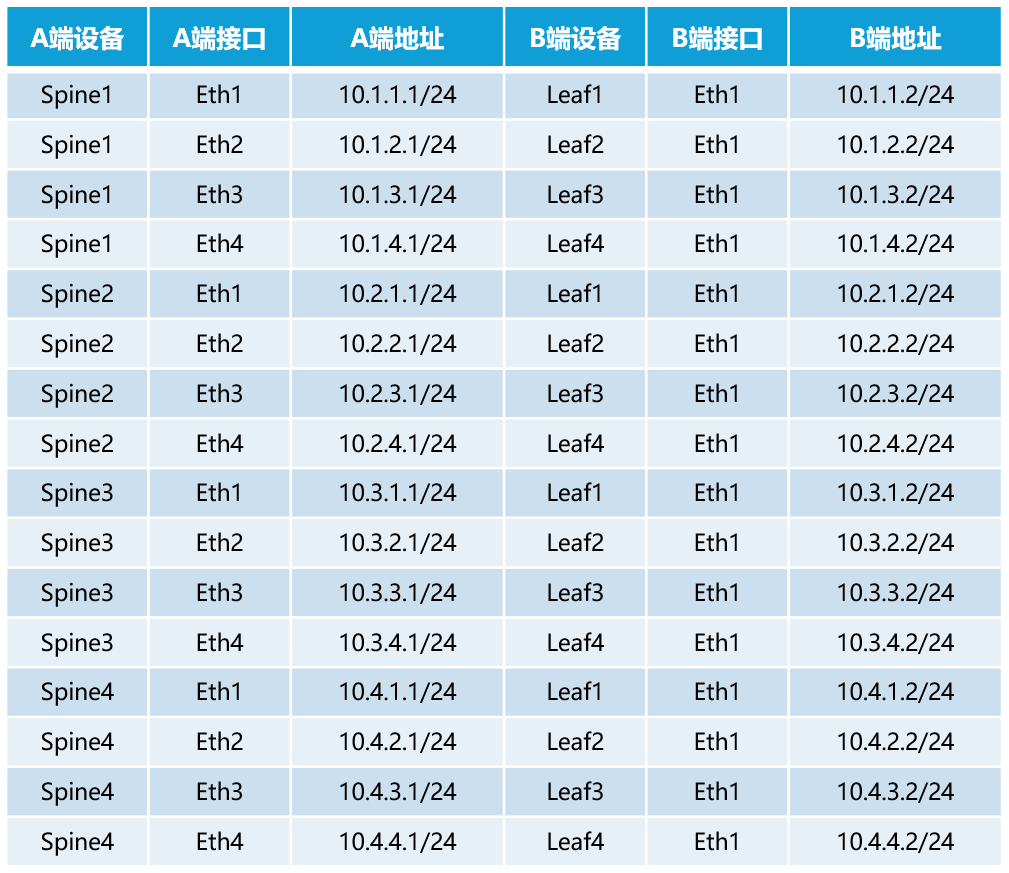
首先,我们配置VSR能接入互联网。
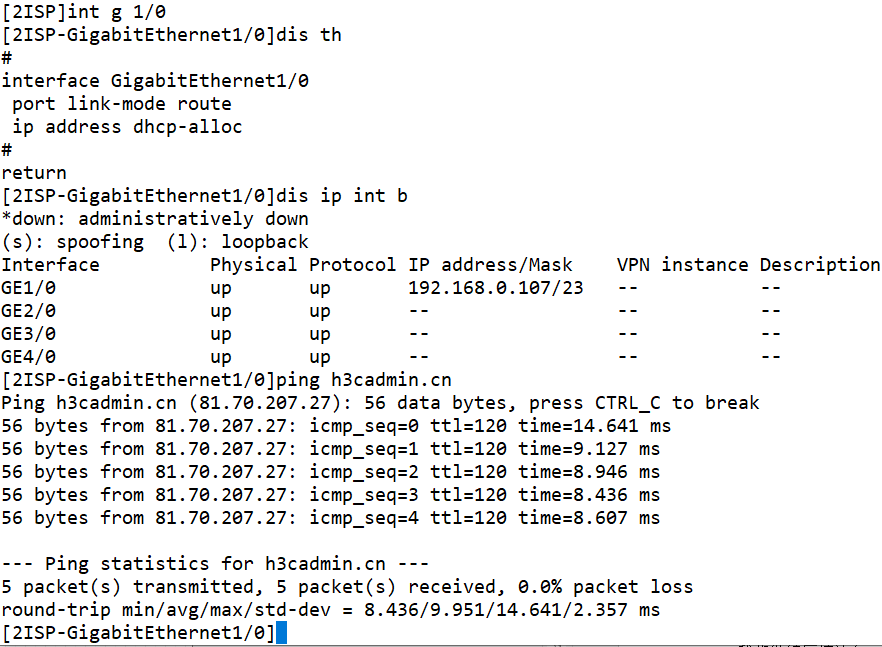
剩下的,就是完成VSR跟Leaf1设备的BGP对接了。
现在,集群的内部业务流量都在VRF l3vpn里,而我们的VSR模拟的是外部网络,为了让逻辑最简化且符合智算中心规范,我们直接把Leaf1设备的ETH7接口划入业务VRF l3vpn中。
interface Ethernet7 description 2VSR no switchport vrf l3vpn ip address 10.8.1.2/24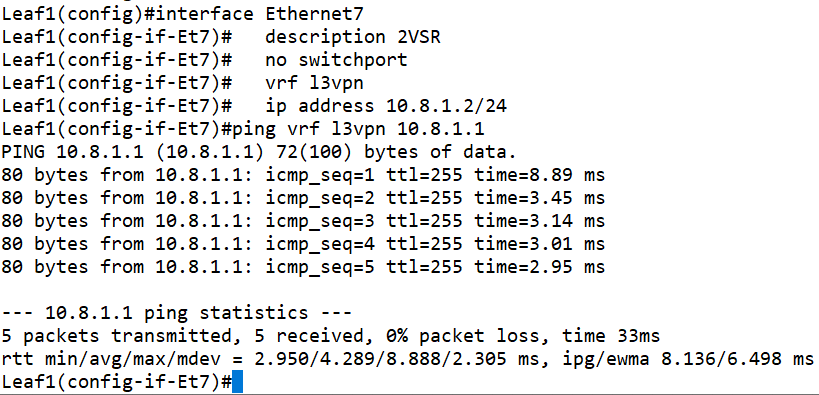
最简单的配置就是指一条默认路由到VSR,但这是数据中心,我们还是配置BGP来进行路由的自动化学习吧,显得B格高一点。
接下来,我们要配置Leaf1设备与VSR建立EBGP邻居。将VSR的BGP AS号配置为65100。
#bgp 65100 router-id 10.8.1.1 peer 10.8.1.2 as-number 65001 # address-family ipv4 unicast import-route direct peer 10.8.1.2 enable peer 10.8.1.2 default-route-advertise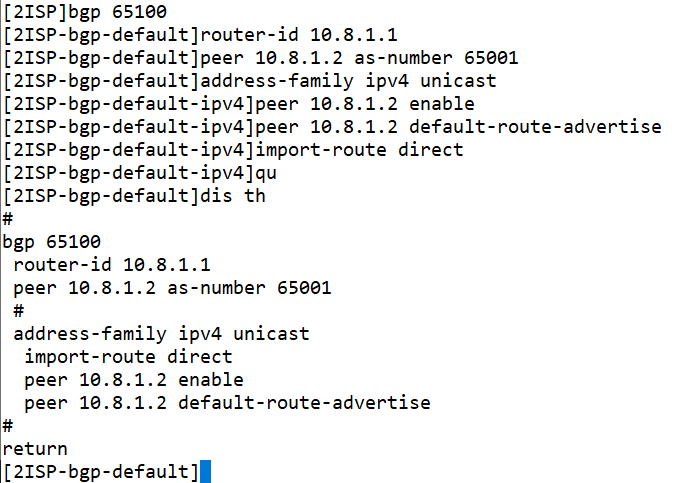
然后配置Leaf1设备。
router bgp 65001 vrf l3vpn neighbor 10.8.1.1 remote-as 65100 neighbor 10.8.1.1 description 2VSR ! address-family ipv4 neighbor 10.8.1.1 activate network 10.10.1.0/24 network 10.20.1.0/24
配置完成,我们先在Leaf1设备上检查一下BGP邻居状态:
show ip bgp summary vrf l3vpn
查看l3vpn实例下的路由信息。
show ip route vrf l3vpn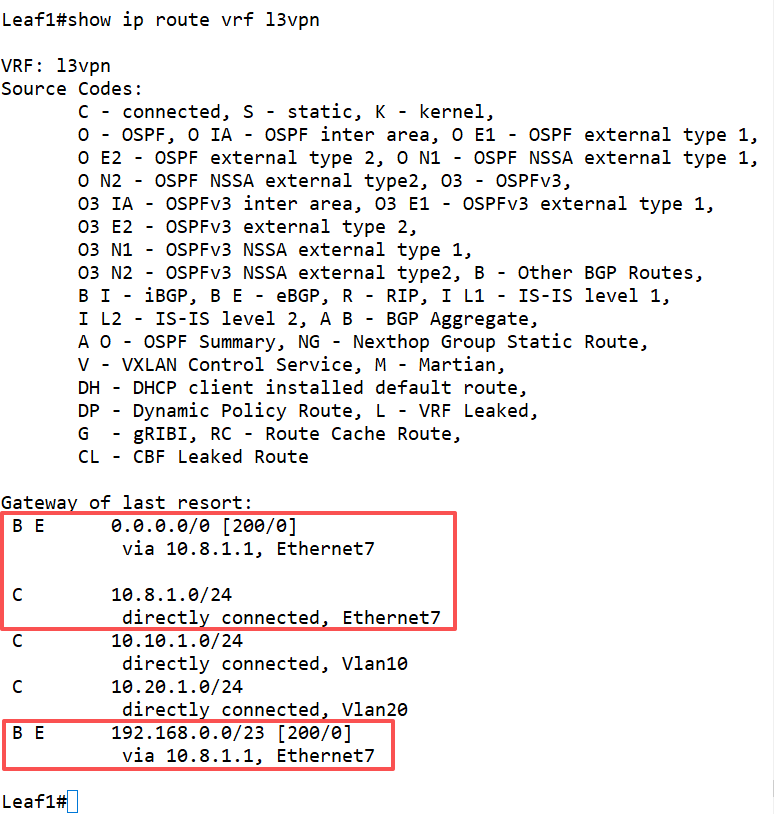
有了这个默认路由就足够了,我们先在Leaf1设备上检查一下公网访问情况。
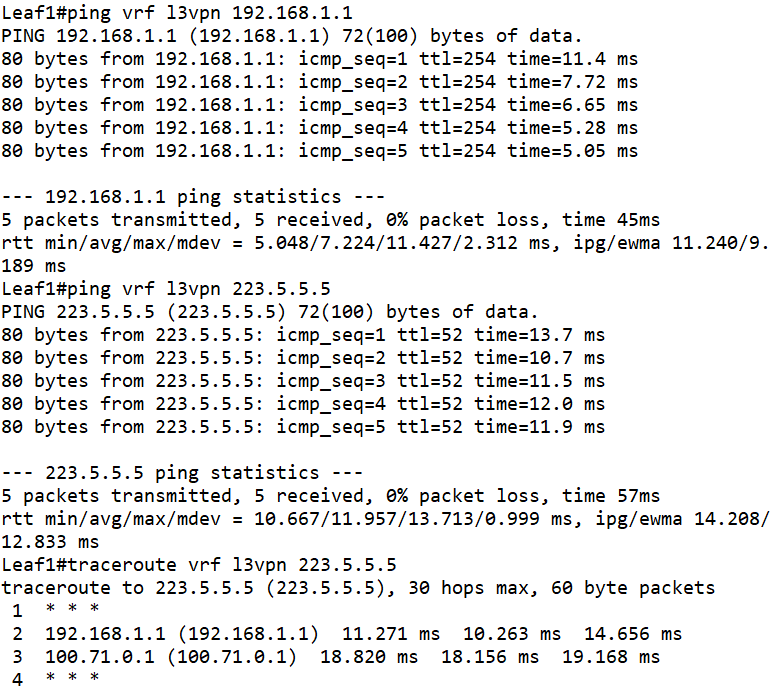
没问题,访问正常。但是,我们先在只有Leaf1跟VSR建立了BGP邻居,那其他Leaf设备有没有路由表项呢?我们在Leaf4设备上检查一下BGP邻居状态和路由信息:
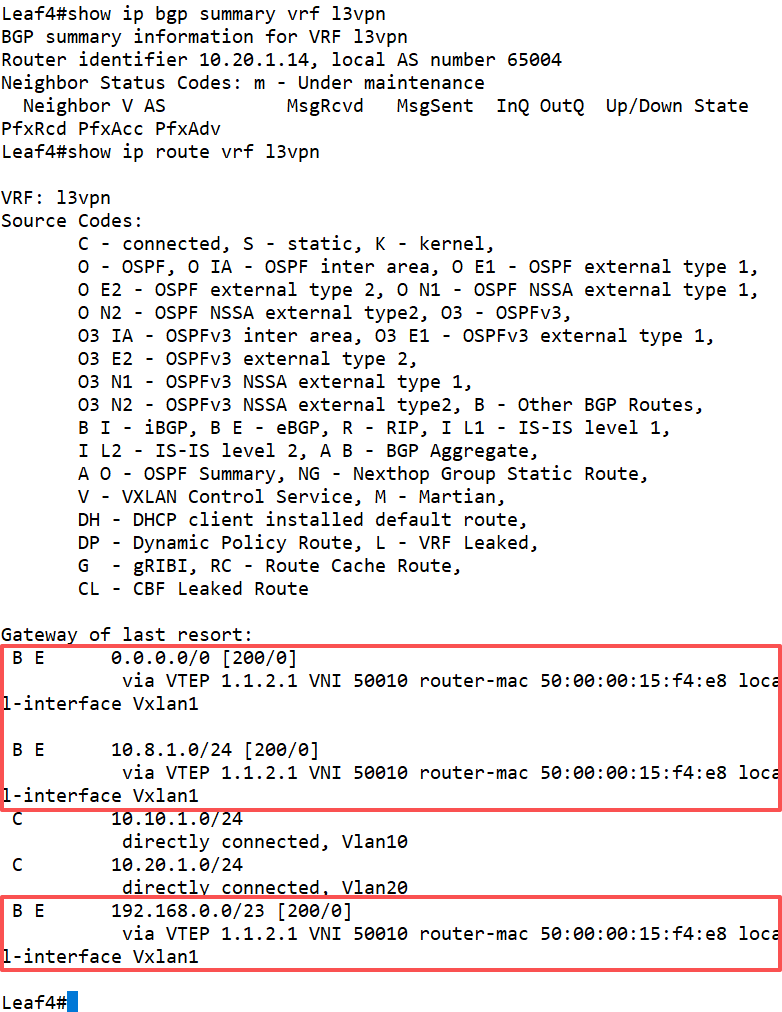
可以看到,虽然Leaf4没有直接与VSR建立邻居关系,但是Leaf1设备将默认路由又通过EVPN的Type-5路由通告传递到了全网的Leaf设备。
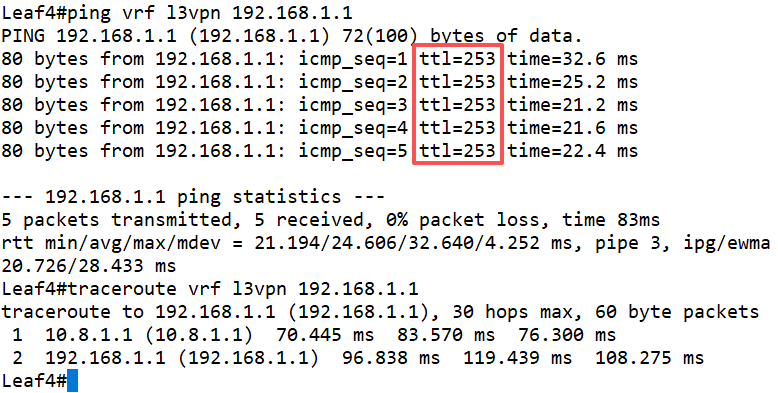
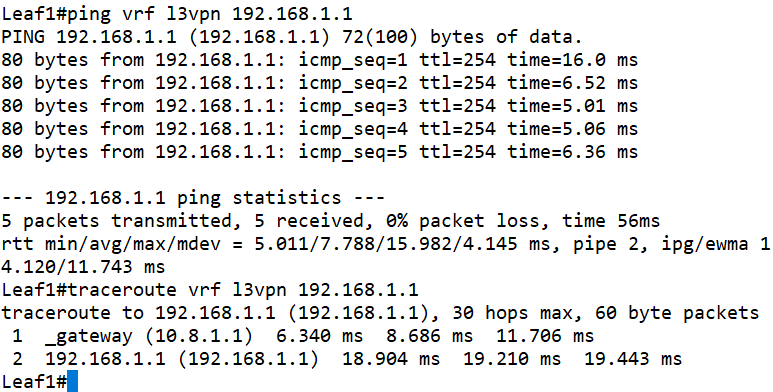
如果检查转发路径,我们发现一个有意思的现象,虽然TTL值为253,也就是三跳;但是显示转发路径只有两跳,第一跳Leaf1设备被隐藏掉了。通过跟Leaf1设备进行对比就很明显了。
最后,我们直接在Leaf4下挂的Server9设备上测试一下到公网访问是否正常。
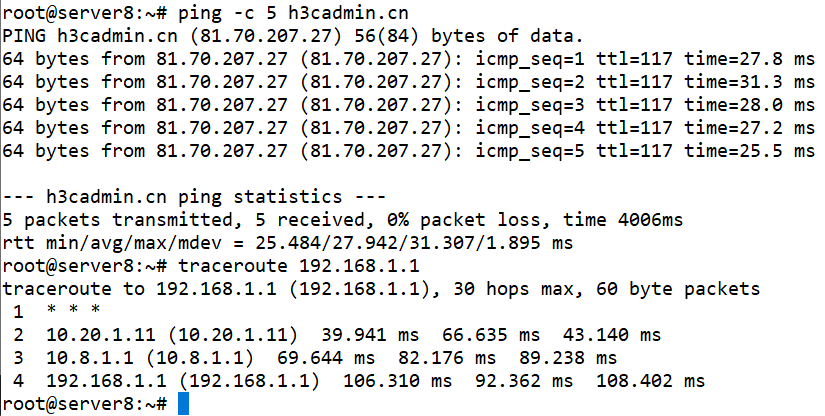
不错,这里的traceroute展示就正常了:第一跳应该是Leaf4,第二跳显示为10.20.1.11,也就是Leaf1,第三跳显示为VSR,第四跳为出口路由器。
总结一下,在分布式网关环境下,Border-Leaf的设备角色最特殊,它既要跑EVPN,又要跑普通的BGP。三层转发全靠Type-5前缀路由,如果Border-Leaf同步Type-5前缀路由异常,内网终端就无法正常访问互联网。
集成了外网出口后,我们的智算中心才算真正“活”了。这套架构从Underlay的BGP建立,到分布式网关的部署,再到现在的边界出口,已经完整覆盖了大厂生产环境的核心逻辑。
纸上得来终觉浅,绝知此事要躬行。通过本次Border Leaf架构的实战部署,我们成功实现了智算中心南北向流量的高效转发。Type-5路由的自动传播让全网Leaf设备都能获得默认路由,实现了一处配置,全网生效的智能化管理。从Underlay到Overlay,从东西向到南北向,我们成功构建了一套完整的高性能网络体系。
***推荐阅读***
我们的WireGuard管理系统支持手机电脑了!全平台终端配置,支持扫码连接,一键搞定
还在为AI API费用发愁?我找到了免费使用Gemini 3和Claude 4.5的方法
保姆级教程:一条命令部署OpenVPN管理系统V4版,支持Win/Mac/安卓/iOS全平台接入
挑战极限!4-Spine+12-Leaf超大规模BGP/EVPN集群收敛性能的"终极考验"实战
EVE-NG高手进阶:两步搞定终端显示难题,让你的实验环境更专业
抓包带你搞懂VXLAN报文封装全流程,同时看看ECMP四路径负载均衡如何智能分流
成本省下99.7%!用40元的腾讯云服务器自建IPsecVPN,成功对接企业级飞塔防火墙
从零搭建EVPN/VXLAN网络:4-Spine架构下的高性能Overlay完全配置指南,打通智算中心任督二脉
从二层到三层:EVPN L3VPN集中式网关配置及四种流量场景深度剖析
EVPN分布式网关实战:Anycast Gateway如何实现网络性能的"质变"

更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)