
RUHMI & RA8P1 教程 part6 - 无 NPU 加持的模型转换和部署
本节仍以 RA8P1 和本文中 的 `minst.tflite`模型文件为例,说明仅使用 CPU 执行推理的源码工程开发过程,并通过实测的数据展现 NPU 加持算力的加速效果。
·
RUHMI & RA8P1 教程 part6 - 无 NPU 加持的模型转换和部署
RUHMI 不仅仅能生成使用 Arm Ethos-U NPU 计算模型的 C 源码,还可以生成不依赖于 Ethos-U NPU,仅使用 CPU 计算模型的C源码,实际上,当遇到 Ethos-U NPU 硬件不支持的算子,RUHMI 生成的源码大多是基于 Arm CMSIS-NN 软件库调用 CPU 的算力完成,当然也可以完全由 Arm CMSIS-NN 软件库实现。这种用法适用于一些对算力要求不高,或者对计算实时性要求不高的应用场景。但是,开发者应当有概念,使用通用CPU和使用NPU加持下的模型计算过程,其计算时间相差很大。
本节仍以 RA8P1 和本文中 的 minst.tflite模型文件为例,说明仅使用 CPU 执行推理的源码工程开发过程,并通过实测的数据展现 NPU 加持算力的加速效果。
配置生成仅由 CPU 执行模型的源码
实际上,在前文中描述配置 Conversion Tool 的参数以启动 RUHMI 进行转换时,就允许开发者选择生成仅由 CPU 执行的源码。如图x所示。

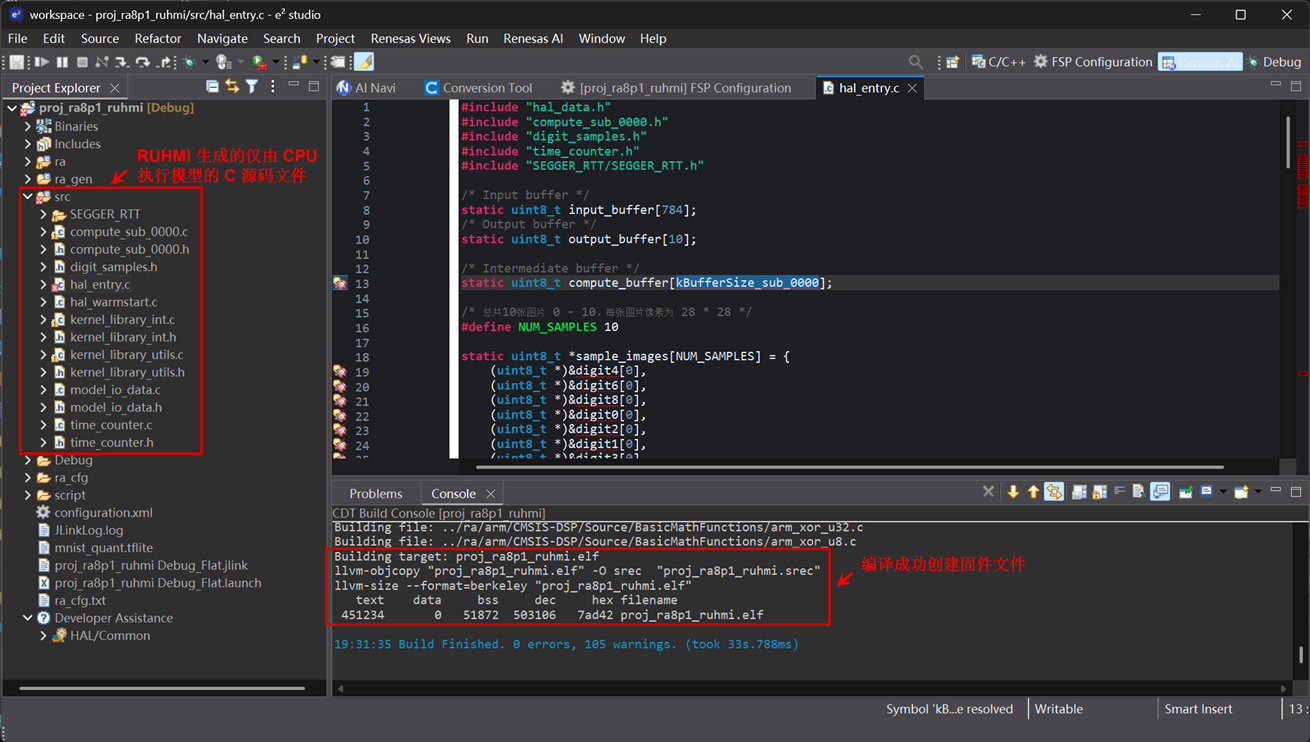
RUHMI 生成的仅由 CPU 执行模型的源码文件相对于调用 ethos-u driver 的源文件要精简一些。替换掉工程中原来的 src 文件夹后,编译工程,成功生成固件。如图x所示。
同之前的操作类似,从编译生成的 map 文件中查找 SEGGER_RTT 组件的内存地址,配置 J-Link RTT Viewer 观察程序执行的 log 信息。如图x所示。

然后,运行程序观察实际的执行效果。如图x所示。

关键源码解析
使用 RUHMI 工具转换模型的过程中,生成了仅使用CPU推理模型的代码。
hal_entry.c文件中,同样通过调用mnist_inference()函数,向模型传样本数据、执行模型、获取模型推理结果。
但是,mninst_inference()函数中向模型输入输出和执行计算的过程有所不同。
void mnist_inference(uint8_t *p)
{
memcpy(input_buffer, p, 28*28);
TimeCounter_CountReset();
g_dwt_start_0 = TimeCounter_CurrentCountGet();
// RUN MODEL
compute_sub_0000(compute_buffer, input_buffer, output_buffer);
g_dwt_end_0 = TimeCounter_CurrentCountGet();
g_dwt_diff = g_dwt_end_0 - g_dwt_start_0;
SEGGER_RTT_printf(0, "\r\nDWT Inference took %d cycles\r\n", g_dwt_diff);
invalidate_dcache_range((void*)output_ptr, 10); // 10 = 输出字节数
result = 0;
for (cnt = 0; cnt < 10; cnt++)
{
SEGGER_RTT_printf(0, "Output %d: %d\r\n", cnt,output_buffer[cnt]);
if(output_buffer[cnt]==0xFF)
{
result = cnt;
SEGGER_RTT_printf(0, "recognized! idx is %d\r\n",result);
}
}
}
这里仅使用compute_sub_0000()函数,完成了模型的输入输出和执行计算的过程。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)