
[论文阅读] 人工智能 + 软件工程 | 不用A100也能自动修bug!SLM+int8量化让APR落地笔记本,精度仅降0.25个bug
本篇博客围绕“小语言模型(SLM)+量化在自动程序修复(APR)中的应用”展开,梳理了相关论文的核心内容:首先介绍APR的价值和LLM的“算力困境”,再拆解论文的实验设计(14个SLM+2个LLM、QuixBugs数据集、4种量化精度),最后重点解读关键结果——顶尖SLM(Phi-3/Qwen2.5-Coder)能媲美LLM,int8量化是“精度-效率”最优解,并通过问答形式解答开发者关心的核心问
不用A100也能自动修bug!SLM+int8量化让APR落地笔记本,精度仅降0.25个bug
论文信息
| 项目 | 详情 |
|---|---|
| 论文原标题 | How Small is Enough? Empirical Evidence of Quantized Small Language Models for Automated Program Repair |
| 主要作者及机构 | Kazuki Kusama、Honglin Shu、Masanari Kondo、Yasutaka Kamei(均来自日本九州大学,Kyushu University, Fukuoka, Japan) |
| arXiv编号 | arXiv:2508.16499v1 [cs.SE] (2025年8月22日) |
| APA引文格式 | Kusama, K., Shu, H., Kondo, M., & Kamei, Y. (2025). How Small is Enough? Empirical Evidence of Quantized Small Language Models for Automated Program Repair. arXiv preprint arXiv:2508.16499v1. |
| 开源复现包地址 | https://doi.org/10.5281/zenodo.15472061(含所有实验数据和代码) |
一段话总结
该论文针对“大语言模型(LLM)在自动程序修复(APR)中精度高但耗资源,难以落地普通开发环境”的问题,通过在QuixBugs(Python/Java各40个bug)基准上测评14个小语言模型(SLM)和2个LLM,并分析float32/float16/int8/int4四种量化的影响,发现Phi-3(3.8B)、Qwen2.5-Coder-3B等顶尖SLM能修复38/40个bug,性能媲美修复39/40个bug的LLM(Codex) ;且int8量化对APR精度影响极小(平均仅少修0.25个bug),却能大幅降低内存需求(如Qwen2.5-Coder-7B从float32的27.22GB降至6.8GB),最终证明“代码专用SLM+int8量化”是LLM的可行替代方案,能让APR在普通GPU(如RTX 30系列)上落地。
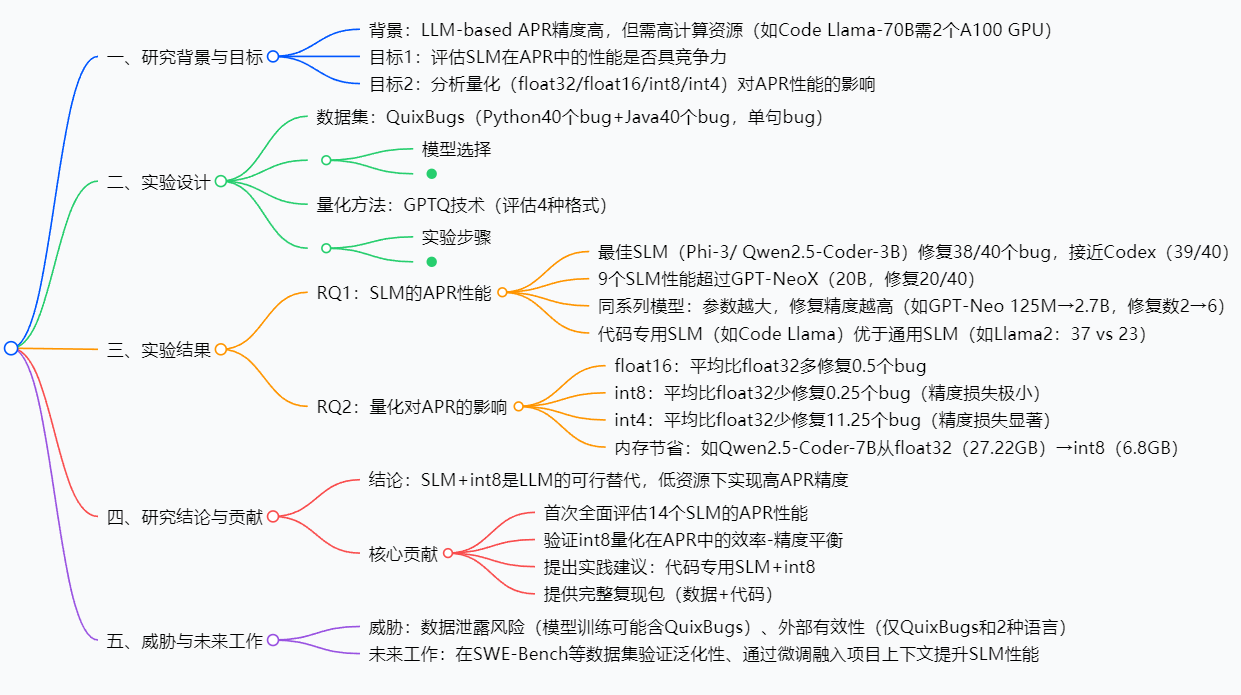
思维导图
研究背景
要理解这篇论文,得先搞懂“自动程序修复(APR)”的价值和当前的“算力困境”——
1. 为什么需要APR?
调试是软件开发中最“烧钱”的环节之一:剑桥大学研究显示,手动调试会消耗大量时间成本(比如定位一个小bug可能要几小时)。而APR的目标是让机器自动找bug、生成修复代码,就像给代码装个“自动纠错器”,能大幅降低开发成本。
早期APR方法(如模板匹配、传统机器学习)受限于训练数据量,只能修简单bug;2022年后,LLM-based APR 爆发了——比如OpenAI的Codex(12B参数)能修复38%的bug,远超传统方法的26%。这是因为LLM训练了几百亿个文本和代码token,甚至能搞定复杂bug。
2. 当下的核心问题:LLM太“重”,用不起
LLM的高精度是有代价的:它需要巨量的计算资源。比如在APR中表现不错的Code Llama-70B(700亿参数),推理时至少要2块NVIDIA A100 80GB GPU——这对普通开发者来说就是“奢侈品”:个人笔记本、甚至中小型公司的服务器都跑不动。
举个类比:LLM就像一台“超级跑车”,跑bug修复很快,但必须在“专业赛道”(高端GPU集群)上开;而开发者需要的是能在“城市道路”(笔记本、普通IDE)上跑的“家用车”,还不能丢太多性能。
3. 破局思路:SLM+量化
为了解决“LLM落地难”的问题,论文盯上了两个技术:
- 小语言模型(SLM):参数远少于LLM(比如Phi-3只有38亿参数),推理时内存/算力需求低。比如Phi-3能在16GB内存的笔记本上跑,不用依赖云端服务器。
- 量化技术:把模型权重从“高精度格式”(如float32,32位浮点数)转成“低精度格式”(如int8,8位整数)。理论上,float32转int8能让模型体积缩小到原来的1/4,还能加速推理(因为CPU/GPU跑整数运算比浮点数快)。
但这里有个疑问:SLM的性能会不会比LLM差很多?量化会不会让APR精度暴跌?这正是论文要解决的核心问题。
创新点
这篇论文的独特价值,在于填补了“SLM+量化在APR中应用”的实证空白,有4个关键亮点:
-
首次大规模测评SLM:之前研究要么只测几个SLM,要么只关注LLM;本文一口气测了14个SLM(覆盖13种架构,参数从0.5B到14B),还对比了2个LLM,能全面反映SLM的真实能力。
-
量化影响的细粒度分析:之前研究只测过量化对“代码生成”的影响,没关注“APR”;本文用float32/float16/int8/int4四种精度,明确了“哪种量化精度最适合APR”(int8是最优解)。
-
SLM的“代码专用”优势验证:首次对比“通用SLM”和“代码专用SLM”——比如Llama2(通用)只能修23个bug,而它的代码专用版Code Llama能修37个;反过来,为对话优化的Vicuna(基于Llama2)只能修19个,证明“针对代码微调”对APR至关重要。
-
实用导向的结论:不搞纯理论,直接给开发者落地建议——“用代码专用SLM(如Phi-3、Qwen2.5-Coder)+int8量化”,既能媲美LLM精度,又能在RTX 30系列(6GB/8GB VRAM)上跑,解决了“落地最后一公里”问题。
研究方法和实验设计
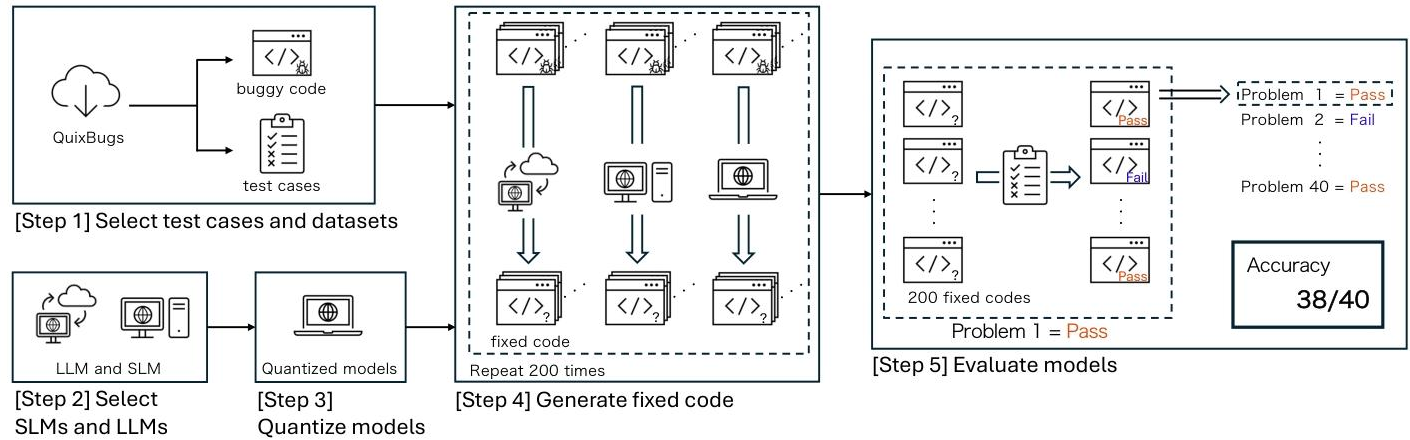
论文的实验逻辑非常清晰,可拆解为5个步骤,每一步都瞄准“回答RQ1和RQ2”:
步骤1:选数据集——QuixBugs基准
为什么选它?因为QuixBugs是APR领域的“标准考题”:
- 包含Python和Java各40个bug,每个bug都是“单句错误”(比如快排漏了 pivot 值),容易验证修复结果;
- 每个bug都附带测试用例和预期输出,能自动判断“生成的代码是否修好bug”(不用人工审核)。
步骤2:选模型——14个SLM+2个LLM
为了全面性,模型选择有两个原则:
- 覆盖不同参数规模:从0.5B(Qwen2.5-Coder-0.5B)到20B(GPT-NeoX,LLM),确保能对比“模型大小 vs 修复能力”;
- 明确定义SLM:论文没照搬别人的定义,而是从“落地性”出发——SLM是“能在RTX 30系列GPU(6GB/8GB/12GB/24GB VRAM)上推理的模型”,比如3.8B参数的Phi-3用float16格式只需7.12GB VRAM,能在8GB GPU上跑。
具体模型列表(关键款):
| 模型类型 | 代表模型 | 参数规模 | 特点 |
|---|---|---|---|
| SLM | Phi-3 | 3.8B | 微软开发,代码能力强 |
| SLM | Qwen2.5-Coder-Instruct | 3B | 阿里代码专用模型 |
| SLM | Code Llama | 7B | Llama2的代码微调版 |
| LLM | Codex | 12B | 代码生成标杆,闭源(API调用) |
| LLM | GPT-NeoX | 20B | 开源大模型,作对比基准 |
步骤3:量化模型——GPTQ技术+4种精度
用GPTQ量化(业界常用且易实现),生成4个版本的模型:
- float32(默认,高精度,最耗资源);
- float16(半精度,资源降50%);
- int8(8位整数,资源降75%);
- int4(4位整数,资源降87.5%,但风险高)。
举个例子,Qwen2.5-Coder-7B的内存需求变化:
| 精度 | 内存需求(GB) | 支持GPU(RTX 30系列) |
|---|---|---|
| float32 | 27.22 | 24GB(红区) |
| float16 | 13.61 | 24GB(红区) |
| int8 | 6.8 | 6GB/8GB/12GB/24GB(绿区) |
| int4 | 3.4 | 所有型号(绿区) |
步骤4:生成修复代码——few-shot提示+多次生成
LLM/SLM本身没专门为APR训练,所以论文用“few-shot提示”引导模型:
- 提示包含2个例子:1个斐波那契函数的bug修复(讲清任务逻辑),1个QuixBugs的真实例子(对齐代码风格);
- 每个bug生成200次修复代码(因为模型输出有随机性,多生成几次能覆盖更多可能)。
步骤5:评估模型——测试用例验证
判断“bug是否修复”的标准很简单:200个生成样本中,只要有1个能通过所有测试用例,就算修复成功。最后统计每个模型修复的bug数量(共40个)。
主要成果和贡献
1. RQ1结果:SLM能媲美LLM,代码专用模型最牛
| 模型类型 | 代表模型 | 参数规模 | QuixBugs-Python修复数 | QuixBugs-Java修复数 | 关键结论 |
|---|---|---|---|---|---|
| LLM | Codex | 12B | 39/40 | 30/40 | 当前APR标杆,精度最高 |
| LLM | GPT-NeoX | 20B | 20/40 | 6/40 | 参数大不代表性能好(非代码专用) |
| SLM | Phi-3 | 3.8B | 38/40 | 37/40 | 性能最接近Codex的SLM |
| SLM | Qwen2.5-Coder-3B | 3B | 38/40 | 29/40 | 代码专用SLM表现突出 |
| SLM | Code Llama | 7B | 37/40 | 35/40 | 比通用SLM(Llama2)高14个bug |
| SLM | Llama2(通用) | 7B | 23/40 | 23/40 | 非代码专用,性能拉胯 |
大白话结论:
- 别迷信“参数越大越好”:20B的GPT-NeoX还不如3.8B的Phi-3;
- “代码专用”是关键:同样基于Llama2,Code Llama(代码微调)比Llama2(通用)多修14个bug,比Vicuna(对话微调)多修18个bug。
2. RQ2结果:int8量化是“性价比之王”
| 量化精度 | 平均修复数变化(vs float32) | 内存节省比例 | 适用场景 |
|---|---|---|---|
| float16 | +0.5(略升) | 50% | 有12GB/24GB GPU,追求更高精度 |
| int8 | -0.25(几乎无影响) | 75% | 6GB/8GB GPU,平衡精度和效率 |
| int4 | -11.25(暴跌) | 87.5% | 仅极端低资源场景(不推荐APR) |
例子佐证:Phi-3(3.8B)在int8量化下,修复数从38个降到38个(±0),但内存从14.23GB(float32)降到3.56GB(int8),普通6GB GPU就能跑。
3. 四大核心贡献
| 贡献类型 | 具体内容 | 对领域的价值 |
|---|---|---|
| 实证贡献 | 首次全面测评14个SLM在APR中的表现,明确SLM的能力边界 | 打破“LLM不可替代”的认知,为APR落地提供新方向 |
| 技术贡献 | 验证int8量化是APR的最优量化方案,平衡精度和资源 | 让SLM能在普通GPU上跑,降低APR的使用门槛 |
| 实用贡献 | 提出“代码专用SLM+int8量化”的落地建议 | 开发者不用买高端GPU,在笔记本上就能用APR工具 |
| 生态贡献 | 开源复现包(含实验数据、代码、模型配置) | 其他研究者可基于此扩展(比如测更多数据集、优化SLM) |
关键问题(问答形式)
-
Q:小语言模型(SLM)在自动程序修复(APR)中,能达到大语言模型(LLM)的精度吗?
A:能。顶尖SLM(如Phi-3、Qwen2.5-Coder-3B)能修复38/40个bug,仅比最好的LLM(Codex,39/40)少1个;且9个SLM的性能优于20B参数的LLM(GPT-NeoX)。 -
Q:量化技术会让SLM的APR精度暴跌吗?哪种量化精度最适合APR?
A:不会,关键看精度等级。float16量化精度略升(平均多修0.5个bug),int8量化仅略降(平均少修0.25个bug),但能省75%内存;int4量化会暴跌(少修11.25个),不推荐。int8是“精度-效率”最优解。 -
Q:什么样的SLM在APR中表现最好?通用SLM和代码专用SLM有区别吗?
A:代码专用SLM表现最好。比如Code Llama(Llama2的代码微调版)能修复37/40个bug,比通用的Llama2(23/40)多14个;而对话微调的Vicuna(基于Llama2)仅能修复19个,证明“针对代码优化”是核心。 -
Q:用SLM+量化做APR,普通开发者的设备能跑吗?比如RTX 30系列GPU。
A:能。以Qwen2.5-Coder-7B为例,int8量化后仅需6.8GB内存,RTX 3060(6GB)、3070(8GB)都能跑;Phi-3(3.8B)int8版仅需3.56GB内存,几乎所有家用GPU都支持。 -
Q:这篇论文的研究有局限吗?未来可以往哪些方向优化?
A:有局限:仅用QuixBugs数据集(可能存在数据泄露风险),未覆盖C++/Go等更多语言。未来可测评SWE-Bench等真实GitHub bug数据集,或通过微调融入项目上下文,进一步提升SLM的APR能力。
论文总结
这篇论文通过扎实的实证实验,解决了“LLM-based APR落地难”的核心问题:
- 证明SLM能成为LLM的可行替代方案——顶尖SLM在APR中精度媲美Codex,且资源需求低;
- 找到int8量化这一关键技术——在几乎不损失精度的前提下,让SLM能在普通GPU上运行;
- 给出实用落地建议——优先选择代码专用SLM(如Phi-3、Qwen2.5-Coder),搭配int8量化,既能保证精度,又能降低算力成本。
对开发者来说,这意味着“自动修bug”不再是高端GPU的专属功能;对研究领域来说,它为APR的“轻量化”发展提供了明确方向,也为后续SLM优化打下了基础。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)