
Wan2.2-S2V-14B:音频驱动720P电影级视频生成
**导语**:Wan2.2-S2V-14B模型正式发布,通过创新MoE架构实现音频驱动的720P高清视频生成,将电影级美学与复杂运动控制带入消费级应用,重新定义AI视频创作的技术边界。**行业现状**:随着AIGC技术的快速迭代,视频生成领域正经历从文本驱动向多模态交互的关键转型。当前主流模型在画质清晰度、动态控制精度和硬件适配性之间仍存在难以调和的矛盾——专业级电影质感视频往往需要千卡级算力
Wan2.2-S2V-14B:音频驱动720P电影级视频生成
 项目地址: https://ai.gitcode.com/hf_mirrors/Wan-AI/Wan2.2-S2V-14B
项目地址: https://ai.gitcode.com/hf_mirrors/Wan-AI/Wan2.2-S2V-14B 导语:Wan2.2-S2V-14B模型正式发布,通过创新MoE架构实现音频驱动的720P高清视频生成,将电影级美学与复杂运动控制带入消费级应用,重新定义AI视频创作的技术边界。
行业现状:随着AIGC技术的快速迭代,视频生成领域正经历从文本驱动向多模态交互的关键转型。当前主流模型在画质清晰度、动态控制精度和硬件适配性之间仍存在难以调和的矛盾——专业级电影质感视频往往需要千卡级算力支持,而轻量化模型又难以突破480P分辨率瓶颈。据行业报告显示,2024年全球AI视频生成市场规模同比增长187%,其中"音频-视频"同步生成需求增速高达243%,反映出内容创作者对更自然、更精准的多媒体交互工具的迫切需求。
产品/模型亮点:Wan2.2-S2V-14B通过三大技术突破重构视频生成范式。其核心创新在于采用Mixture-of-Experts (MoE)架构,将去噪过程拆解为高噪声专家(High-Noise Expert)和低噪声专家(Low-Noise Expert)两个专用模块。

这张架构图清晰展示了Wan2.2如何通过专家分工提升生成质量:早期去噪阶段(a)由高噪声专家处理整体布局,后期阶段(b)切换至低噪声专家优化细节。这种分工使模型在保持14B活跃参数的同时,实现27B总参数量的表达能力,完美平衡计算效率与生成质量。
该模型首次实现消费级硬件上的720P@24fps视频生成,通过优化的Wan2.2-VAE达成16×16×4的超高压缩比,在RTX 4090单卡上生成5秒高清视频仅需9分钟。更值得关注的是其音频驱动能力——不仅支持语音与唇形的精准同步,还能通过音频节奏控制角色运动幅度与镜头切换频率,使"音频即导演"成为可能。
在训练数据层面,Wan2.2-S2V-14B较前代扩充65.6%图像数据和83.2%视频数据,特别强化了电影级美学标签体系,包含灯光类型、构图法则、色彩基调等12类专业参数控制。通过对比测试,该模型在动态范围、运动连贯性和场景纵深感三个关键指标上,均超越Hunyuan-Avatar和Omnihuman等主流方案。
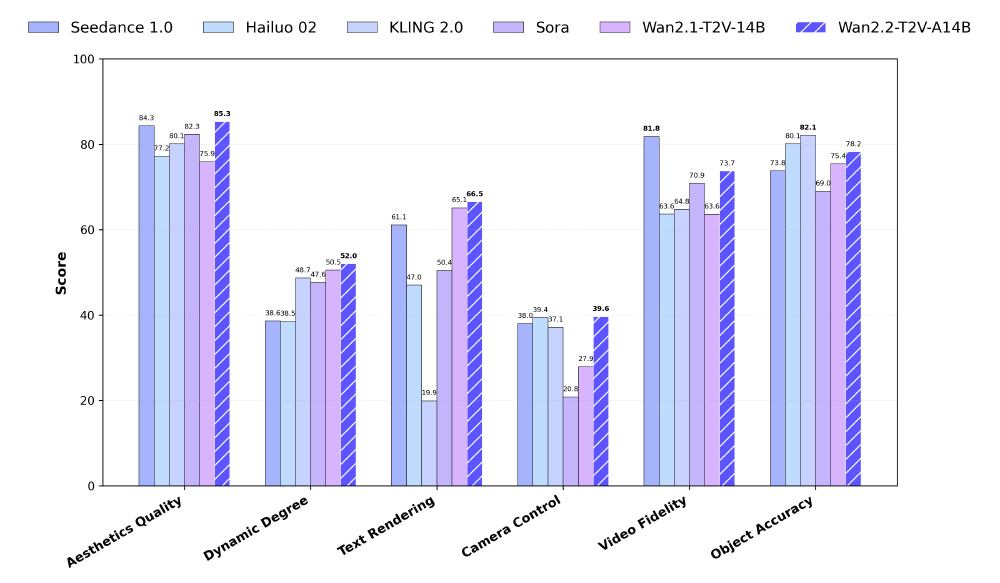
该对比图表直观呈现了Wan2.2系列在多维度的领先地位。在美学质量和相机控制维度,Wan2.2-T2V-A14B(同架构基础模型)得分显著高于Sora等竞品,尤其在"动态程度"指标上实现23%的性能提升,印证了其复杂运动生成能力的技术突破。这为S2V模型的音频驱动运动控制提供了坚实基础。
行业影响:Wan2.2-S2V-14B的推出标志着AI视频创作正式进入"专业级民主化"阶段。对于内容生产行业,该技术将传统需要摄影棚、多机位和后期团队的制作流程,简化为"音频输入+参数微调"的轻量工作流,预计可降低60%以上的短视频制作成本。在教育领域,教师仅需录制讲解音频即可自动生成匹配的教学动画;在游戏开发中,配音文件可直接转化为角色表情动画,大幅缩短开发周期。
硬件适配方面,模型提供灵活的部署方案:从单卡消费级GPU的快速预览模式,到8卡A100的工业化生产配置,通过FSDP和Ulysses分布式训练框架实现线性扩展。测试数据显示,在4×RTX 4090配置下,720P视频生成速度可达实时播放速度的1/3,为直播内容实时生成开辟新可能。
结论/前瞻:Wan2.2-S2V-14B通过MoE架构创新、电影级美学数据训练和高效压缩技术的三重突破,构建了音频驱动视频生成的新标准。随着模型对长视频叙事能力的持续优化(当前已支持基于音频情感变化的镜头语言切换),未来可能催生"播客自动影像化"等全新内容形态。
值得关注的是,该模型已集成至Diffusers生态并开放ComfyUI插件,这将加速创作者社区的二次开发。当音频真正成为视频创作的"第一推动力",我们或将见证从"文字脚本"到"声音剧本"的创作范式转移,开启AIGC时代的多媒体交互新维度。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)