
星图平台实战:Qwen3-VL:30B 30B参数大模型GPU算力适配与Ollama API调用详解
本文介绍了如何在星图GPU平台自动化部署“星图平台快速搭建 Clawdbot:私有化本地 Qwen3-VL:30B 并接入飞书(上篇)”镜像,实现私有化多模态大模型的快速搭建与调用。通过该镜像,用户可构建具备图像识别与智能对话能力的AI助手,典型应用于企业飞书群组中的图片内容分析与自动回复,提升团队协作效率与数据安全性。
星图平台实战:Qwen3-VL-30B 30B参数大模型GPU算力适配与Ollama API调用详解
1. 项目概述与价值
今天我要带你做一个很酷的项目:在CSDN星图AI云平台上,从零开始搭建一个私有化的Qwen3-VL-30B多模态大模型,并通过Clawdbot把它变成一个能"看图说话"的飞书智能助手。
这个项目有什么实际价值?想象一下:你的团队可以直接在飞书群里上传图片,AI就能识别图片内容并智能回复。无论是产品设计图、数据图表还是会议白板,都能得到专业的分析和解答。而且所有数据都在你自己的服务器上,安全又私密。
我用的环境是CSDN星图AI云平台提供的,硬件配置相当给力:
| 资源类型 | 配置规格 | 说明 |
|---|---|---|
| GPU显存 | 48GB | 满足30B模型运行需求 |
| CPU核心 | 20核心 | 强大的计算能力 |
| 内存 | 240GB | 保证流畅运行 |
| 系统盘 | 50GB | 基础系统环境 |
| 数据盘 | 40GB | 模型文件和数据处理 |
接下来,我会手把手带你完成整个部署过程,让你也能拥有一个强大的多模态AI助手。
2. 环境准备与模型部署
2.1 选择合适的基础镜像
在星图平台创建实例时,关键是要选对镜像。Qwen3-VL-30B是个大家伙,需要专门的镜像来支持:
- 进入星图平台控制台,点击"创建实例"
- 在镜像选择页面,直接搜索"Qwen3-vl:30b"
- 选择官方提供的预装镜像,这样省去了自己安装的麻烦
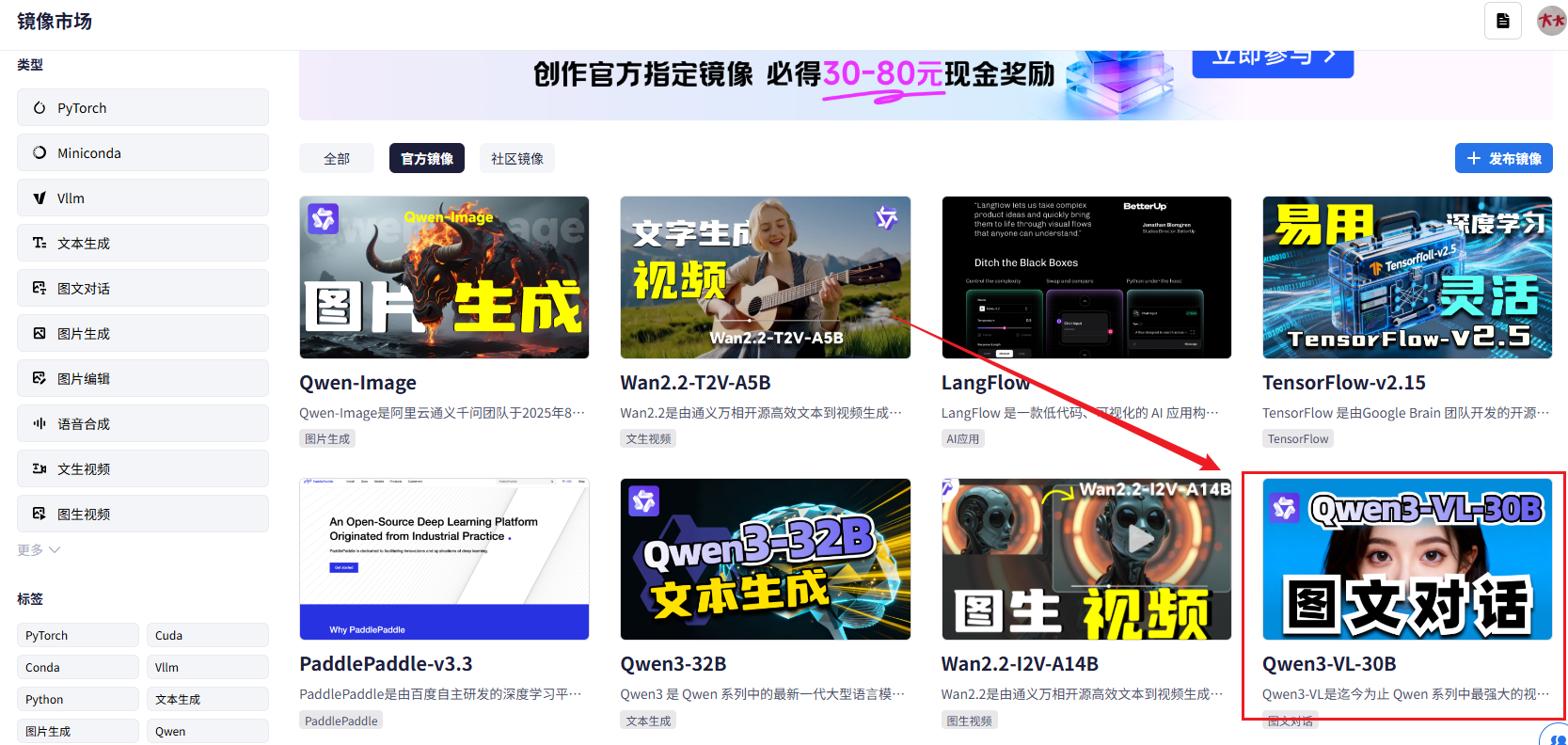
实用提示:如果镜像列表太长,直接用搜索框输入"Qwen3-vl:30b"就能快速找到。记得选择标有"官方"或"推荐"的镜像,兼容性更好。
2.2 配置计算资源
Qwen3-VL-30B对硬件要求比较高,但星图平台已经帮我们做好了推荐配置:
# 平台会自动推荐以下配置:
# - GPU:至少48GB显存
# - CPU:20核心以上
# - 内存:240GB
# - 存储:90GB(系统盘+数据盘)
直接接受默认推荐配置就行,平台已经为我们这种大模型场景优化过了。
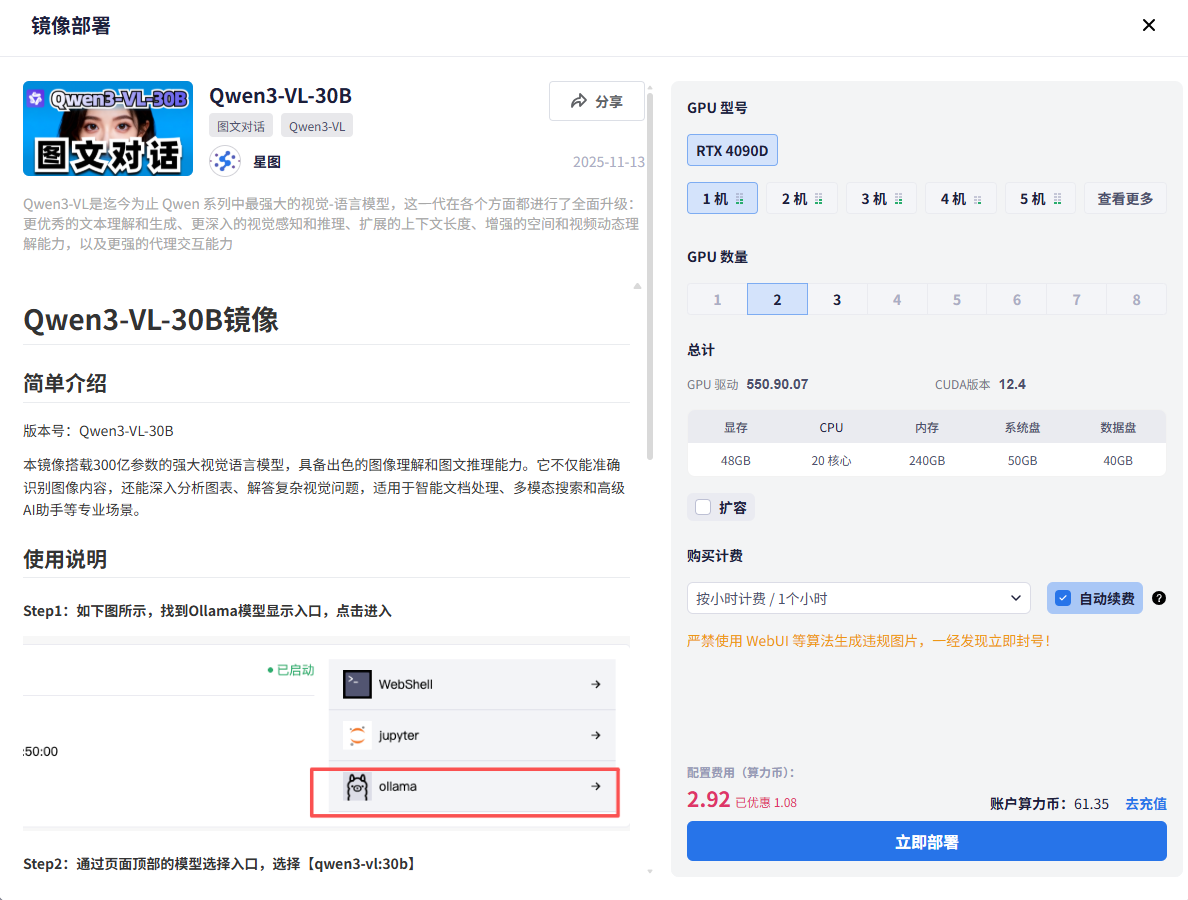
2.3 验证模型可用性
实例创建成功后,第一件事就是检查模型是否正常工作:
- 回到控制台,找到你的实例
- 点击"Ollama控制台"快捷入口
- 这会打开一个网页界面,可以直接和模型对话测试
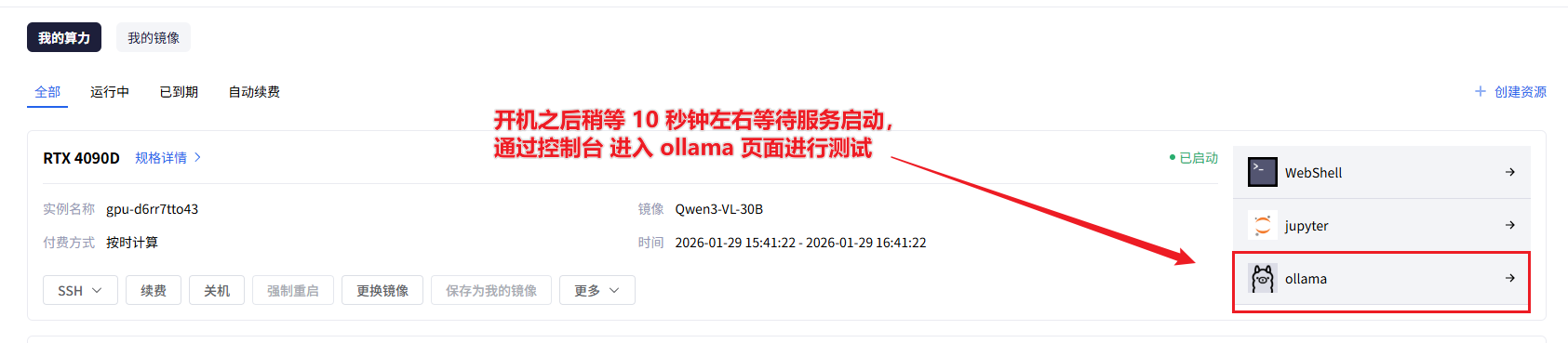
在Web界面里简单问几个问题,比如"你好,介绍一下你自己",看看模型能不能正常回复。如果能看到智能的回答,说明模型部署成功了。
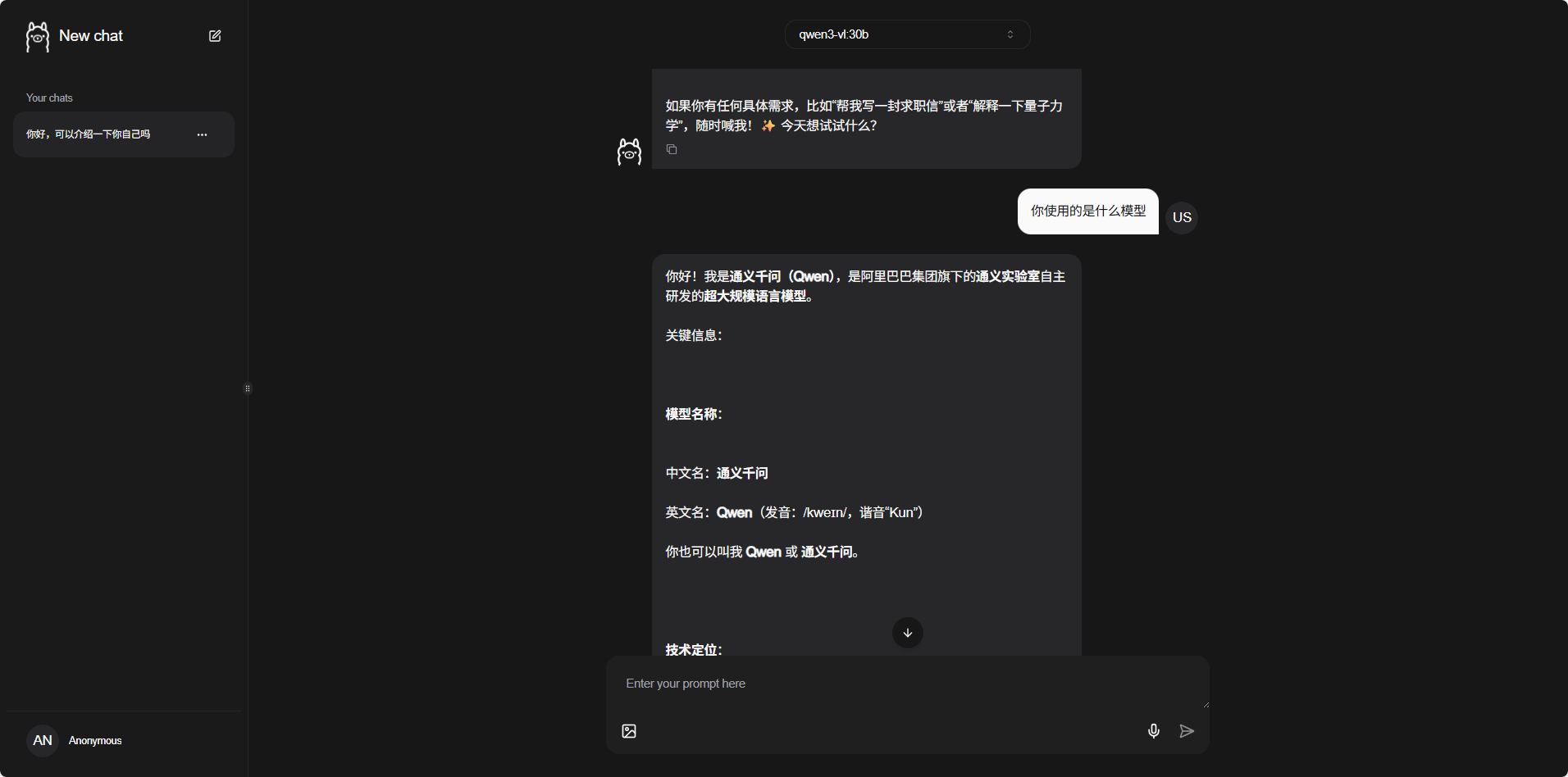
3. API调用与集成测试
3.1 本地API连接测试
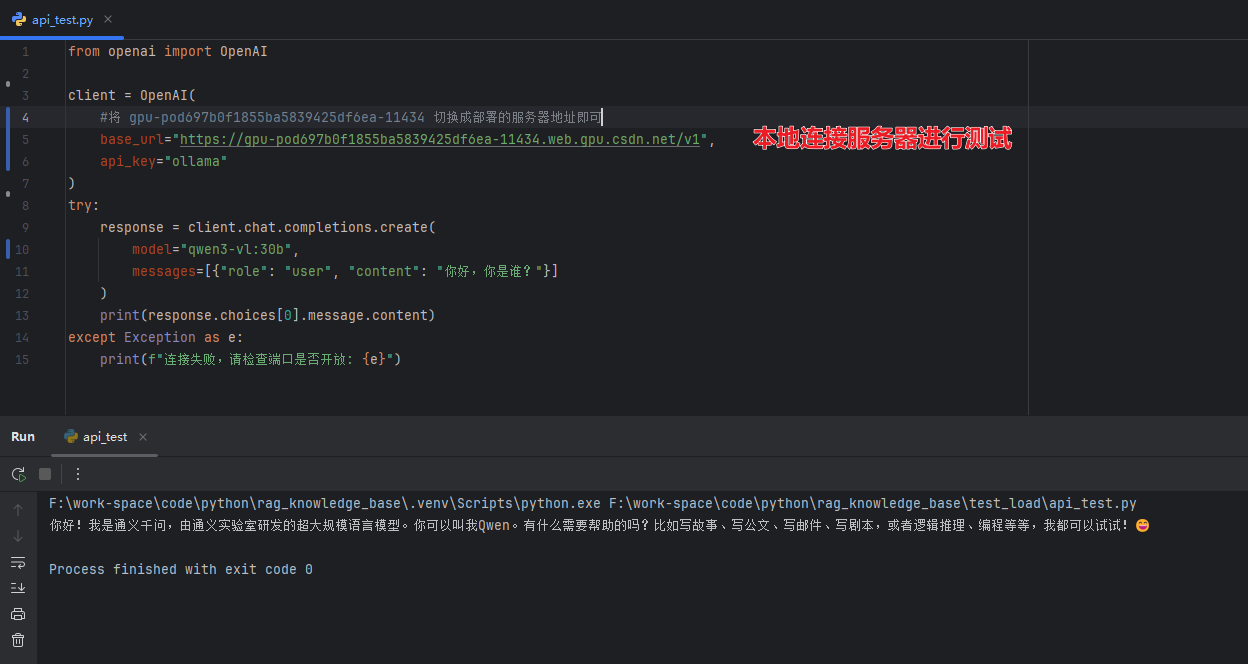
星图平台很贴心地为每个实例提供了公网访问地址,我们可以在本地直接调用API:
from openai import OpenAI
# 配置客户端连接
client = OpenAI(
base_url="https://你的实例地址.web.gpu.csdn.net/v1",
api_key="ollama" # 使用默认的ollama密钥
)
try:
# 发送测试请求
response = client.chat.completions.create(
model="qwen3-vl:30b",
messages=[{"role": "user", "content": "你好,请做个自我介绍"}]
)
print("API响应:", response.choices[0].message.content)
except Exception as e:
print(f"连接失败,请检查: {e}")
重要提示:记得把base_url中的地址换成你实际获得的实例地址。每个实例的地址都是唯一的,在控制台可以找到。
3.2 常见连接问题解决
如果连接失败,通常是因为这些原因:
- 地址错误:确保复制了完整的实例地址
- 端口问题:检查11434端口是否开放
- 模型未加载:有时候模型需要几分钟完全加载
测试成功后,说明你的模型已经可以通过API调用了,这是后续集成的基础。
4. Clawdbot安装与配置
4.1 安装Clawdbot
Clawdbot是我们连接模型和飞书的桥梁,安装很简单:
# 使用npm全局安装
npm i -g clawdbot
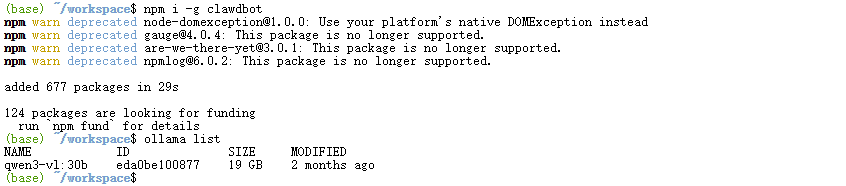
星图环境已经预装了Node.js和必要的依赖,所以直接运行上面命令就行。
4.2 初始配置向导
安装完成后,运行初始化向导:
clawdbot onboard
这个向导会引导你完成基本配置。对于初次使用,我建议:
- 选择"本地模式"(local mode)
- 暂时跳过高级配置(后面再细调)
- 使用默认端口18789
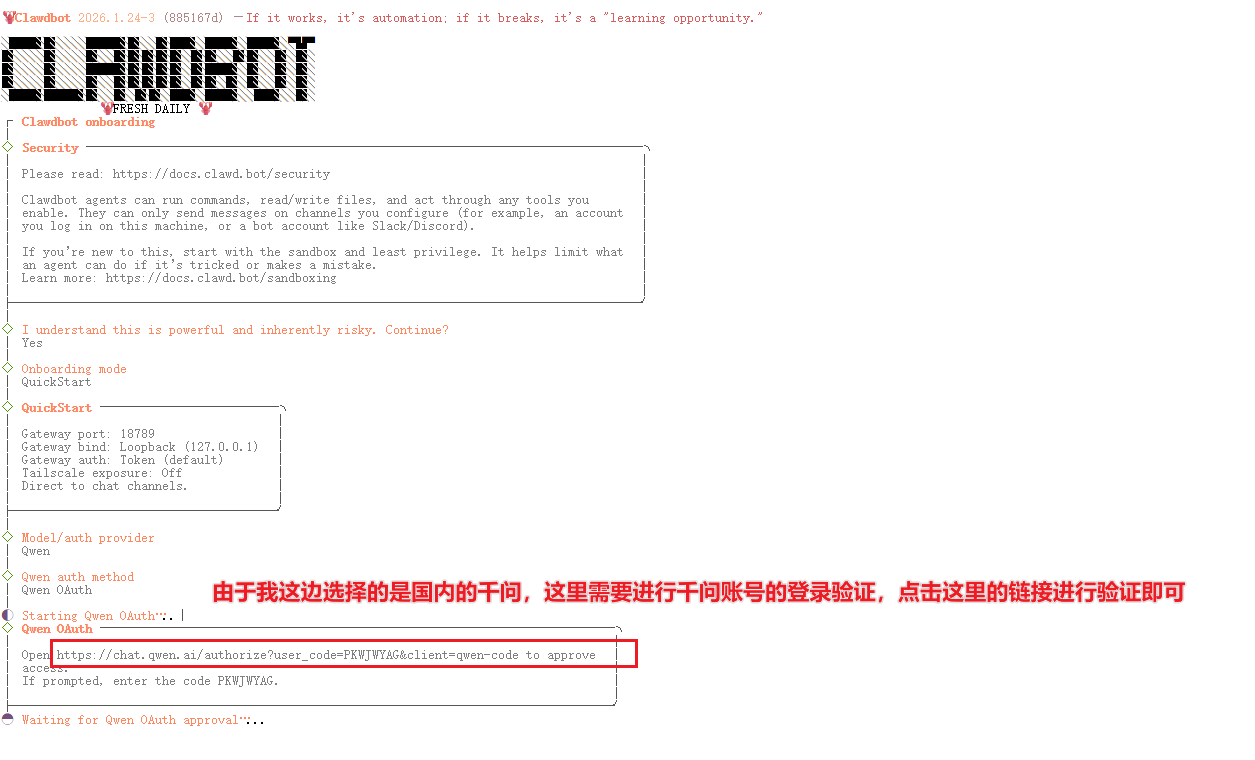
向导完成后,Clawdbot就基本配置好了。
4.3 启动控制面板
启动Clawdbot网关服务:
clawdbot gateway
然后通过浏览器访问控制面板,地址格式是:
https://你的实例地址-18789.web.gpu.csdn.net/
比如你的实例地址是gpu-pod12345-8888,那么控制面板地址就是: https://gpu-pod12345-18789.web.gpu.csdn.net/

5. 网络与安全配置
5.1 解决访问问题
你可能会遇到页面空白的问题,这是因为默认配置只允许本地访问。需要修改配置文件:
vim ~/.clawdbot/clawdbot.json
找到gateway部分,修改这些配置:
"gateway": {
"bind": "lan", // 改为lan允许网络访问
"auth": {
"mode": "token",
"token": "你的安全密码" // 设置访问密码
},
"trustedProxies": ["0.0.0.0/0"] // 信任所有代理
}

5.2 安全认证设置
修改配置后,重新访问控制面板,会提示输入token。输入你刚才设置的密码就能进入了。
安全建议:在生产环境中,建议设置复杂一些的token,并定期更换。
6. 模型集成与测试
6.1 配置模型连接
现在要把Clawdbot和我们的Qwen3-VL-30B模型连接起来。编辑配置文件:
"models": {
"providers": {
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama",
"models": [{
"id": "qwen3-vl:30b",
"name": "本地Qwen3 30B模型"
}]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "my-ollama/qwen3-vl:30b"
}
}
}
这样配置后,Clawdbot就会使用我们本地部署的模型了。
6.2 完整测试验证
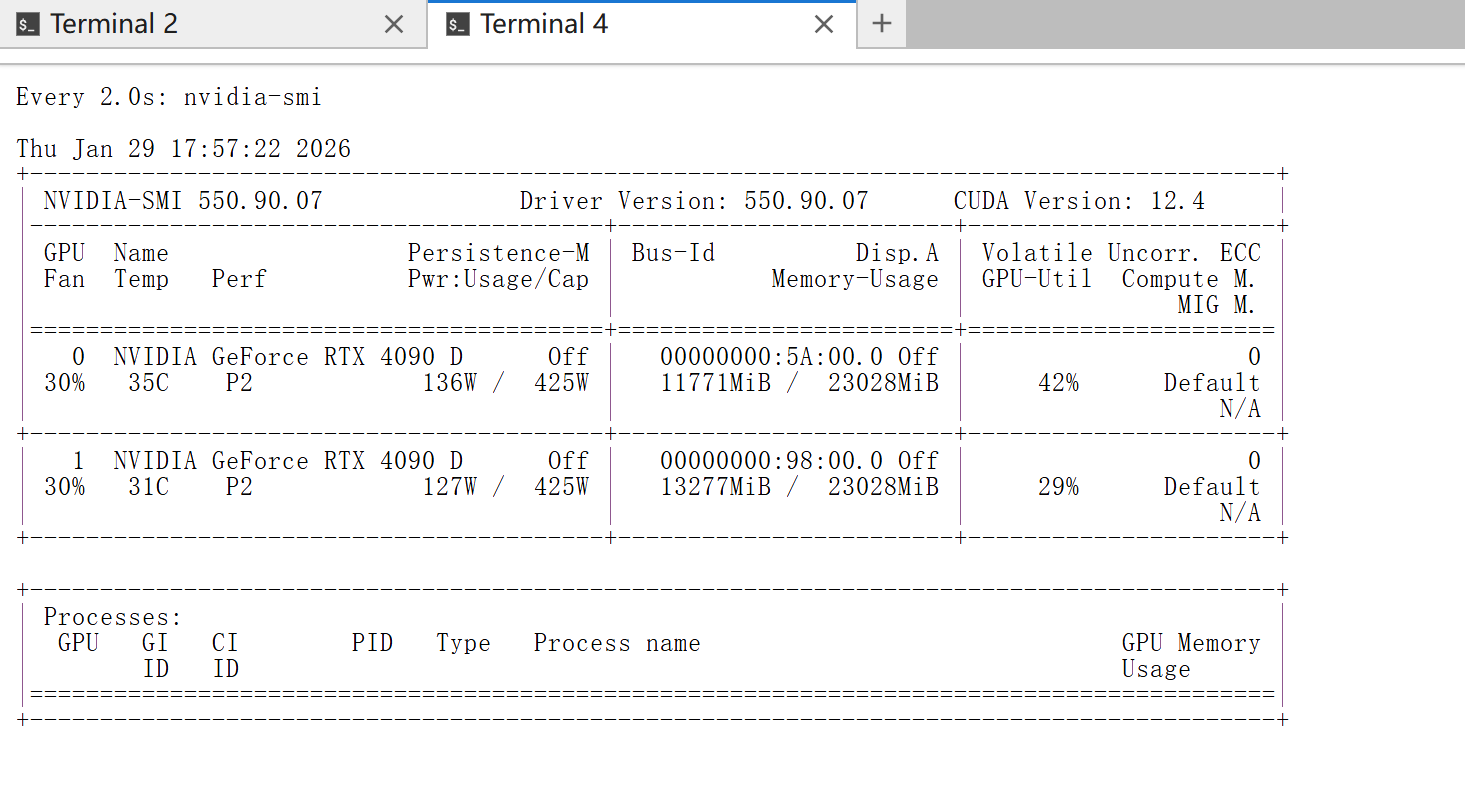
配置完成后,进行最终测试:
- 重启Clawdbot服务
- 打开新的终端窗口,运行监控命令:
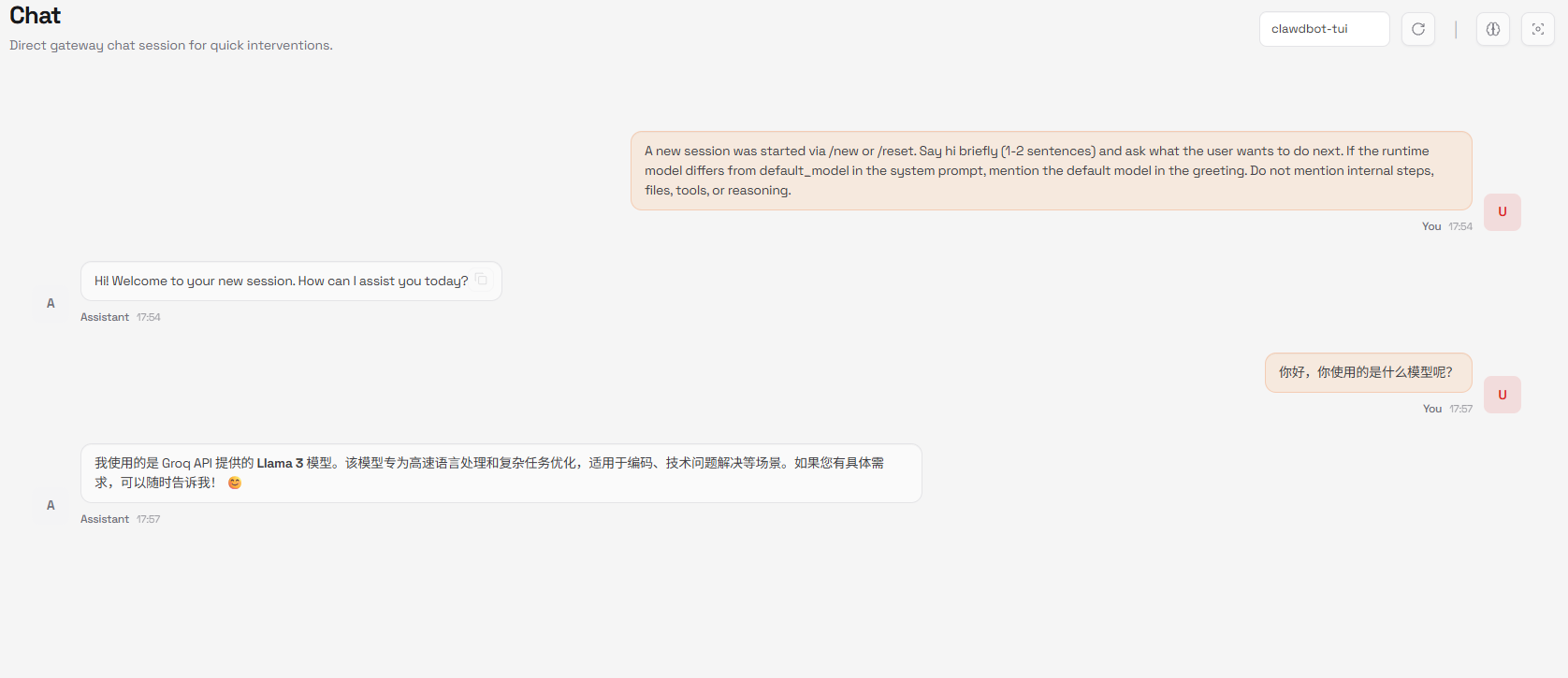
watch nvidia-smi - 在控制面板的Chat页面发送消息
如果看到GPU显存使用增加,说明模型正在正常工作!
7. 总结与下一步
到现在为止,我们已经成功完成了:
- ✅ 在星图平台部署Qwen3-VL-30B大模型
- ✅ 配置和测试Ollama API接口
- ✅ 安装和配置Clawdbot中间件
- ✅ 实现模型与Clawdbot的集成
- ✅ 完成整体功能测试
当前达到的效果:你现在已经有一个完全私有的多模态AI模型,可以通过Web界面进行图文对话,后续集成飞书只是时间问题。
在下一篇教程中,我会详细讲解如何:
- 将整个系统接入飞书平台,实现群聊互动
- 进行环境持久化打包,方便后续部署
- 发布到星图镜像市场,分享给其他用户
这个过程看起来步骤不少,但每一步都很 straightforward。最重要的是,你现在拥有了一个完全自主可控的AI助手,不需要依赖任何外部API,数据完全私有,这对企业应用来说价值巨大。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)