
比Gemini 3早发布的这篇Google论文更有意思!
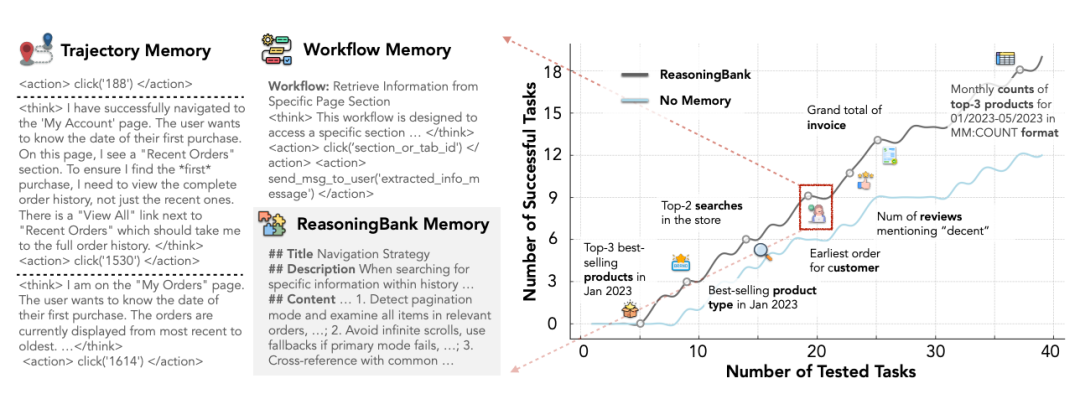
这让智能体得以持续进化,在 WebArena-Admin 子集上获得比“无记忆”基线更高的累积成功率。图 7:加入失败轨迹后,仅 ReasoningBank 能继续提升(49.7↑from 46.5),其余方法原地踏步甚至掉分。图 6:同一条记忆从“点按钮”→“自检元素”→“交叉验证”逐步长复杂,像 RL 的策略演化。测试时把算力花在深度探索单任务,生成多样经验反哺记忆,形成“越用越聪明”闭环。L
Datawhale干货
团队:Google,来源:PaperAgent
Google近期发了Gemini 3,在推理、多模态理解和智能体Agent能力上全面跃升,几乎全面 SOTA。今天分享一篇Google近期有意思的论文:ReasoningBank。

原文链接:https://arxiv.org/pdf/2509.25140
一、LLM 智能体“金鱼记忆”
当前大模型智能体在长周期、多任务场景下表现拉胯:
-
做完就忘,重复踩坑
-
只记“成功案例”,失败经验全丢
-
记忆=原始轨迹堆仓库,检索又慢又杂
一句话总结:没有“错题本”的学霸不是真学霸。
二、核心贡献速览
ReasoningBank 能够归纳出可复用的推理策略,使记忆项在未来任务中更具迁移性。这让智能体得以持续进化,在 WebArena-Admin 子集上获得比“无记忆”基线更高的累积成功率。
|
亮点 |
一句话总结 |
|
ReasoningBank |
把成功+失败轨迹蒸馏成可迁移的推理策略,人话版“错题+经验笔记”。 |
|
MaTTS |
测试时把算力花在深度探索单任务,生成多样经验反哺记忆,形成“越用越聪明”闭环。 |
|
实验 |
实验WebArena、Mind2Web、SWE-Bench-Verified 三基准 全面 SOTA,成功率最高↑34%,步数 ↓16%。 |
三、方法总览一张图看懂
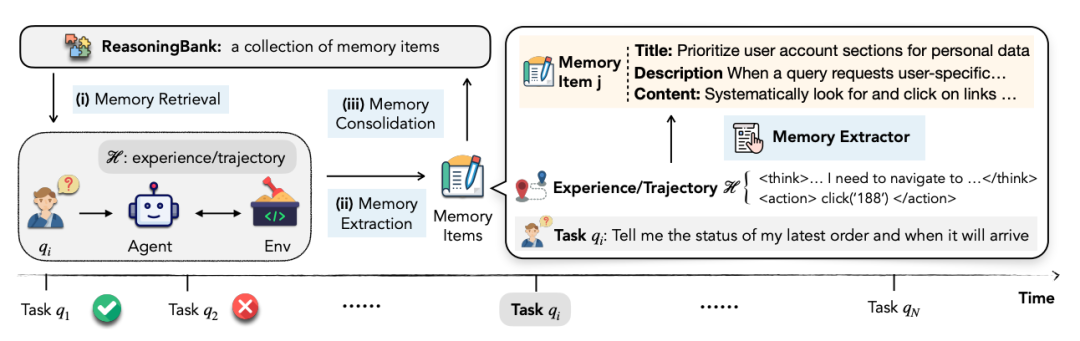
图 2:闭环记忆流程——检索 → 执行 → 提炼 → 回存
|
步骤 |
关键设计 |
|---|---|
|
① 记忆抽取 |
LLM-as-a-Judge 先判 success/failure,再蒸馏成 {标题, 描述, 内容} 三元组 |
|
② 记忆检索 |
用 Gemini Embedding 做语义检索,Top-k 相关策略注入系统 prompt |
|
③ 记忆巩固 |
新轨迹即时提取并追加到记忆池,零参数更新,线上即用 |
ReasoningBank 记忆格式(3 件套)
|
字段 |
作用 |
|---|---|
| Title |
策略关键词,如“优先检查分页控件” |
| Description |
一句话摘要 |
| Content |
1-3 句可迁移的推理要点,去网站/去查询泛化 |
失败轨迹同样提炼“防坑指南”,首次让负样本发光发热。
四、MaTTS:把算力变成“好记性”
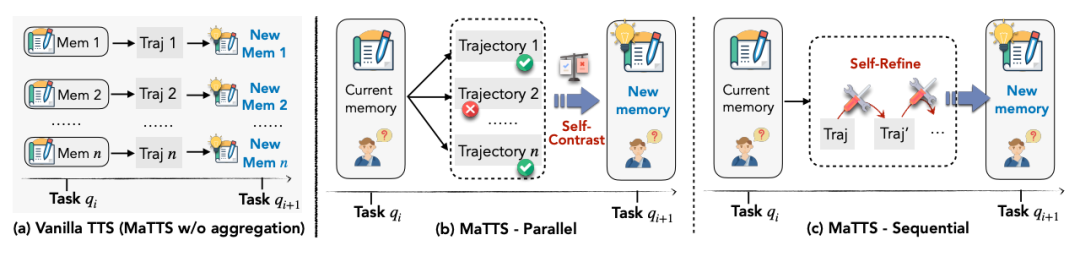
图 3:Vanilla TTS vs MaTTS 并行/串行 scaling
|
模式 |
做法 |
好处 |
|---|---|---|
| Parallel |
同一任务跑 k 条轨迹,自对比筛出一致策略 |
越大 k 越香,Best-of-N 从 49.7→55.1 |
| Sequential |
单条轨迹多轮自反思,中间笔记也入库 |
小 k 性价比最高,收敛更快 |
记忆与 scaling 形成双飞轮:好记忆指引探索 → 多样探索反哺更好记忆。
五、实验结果:数字不说谎
1. WebArena 成功率 & 步数
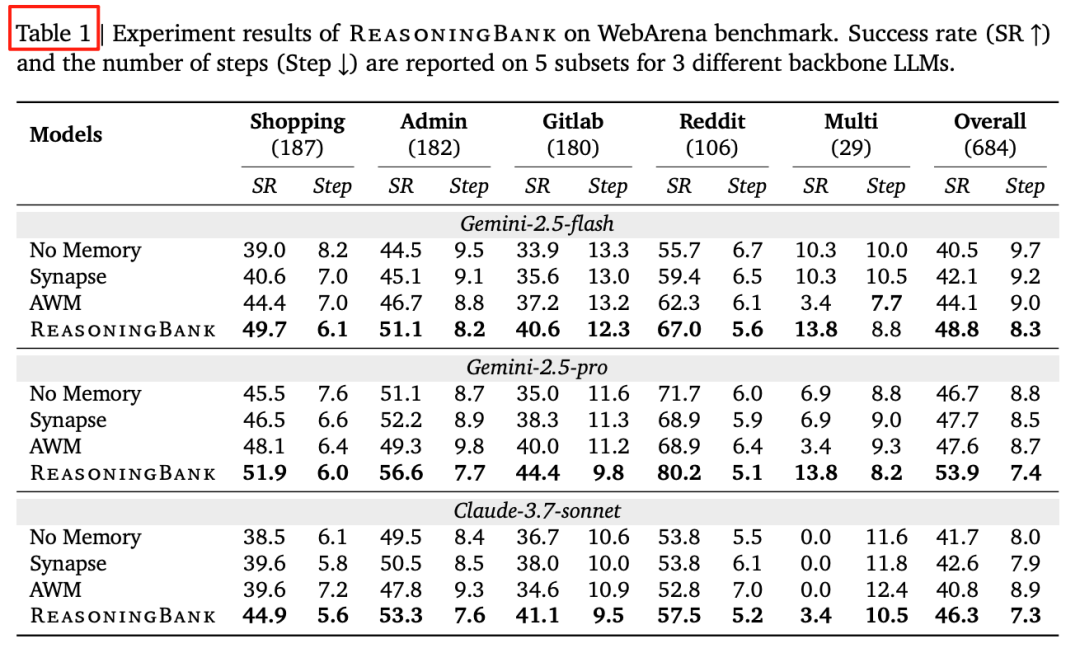
 表 1:5 个子域平均,ReasoningBank 稳定领先
表 1:5 个子域平均,ReasoningBank 稳定领先
-
Gemini-2.5-Pro backbone:↑7.2% 绝对成功率,步数 ↓1.4
-
跨域 Multi 任务(最硬核):仅 ReasoningBank 还能涨,其他记忆方法直接翻车。
2. SWE-Bench-Verified 修 Bug
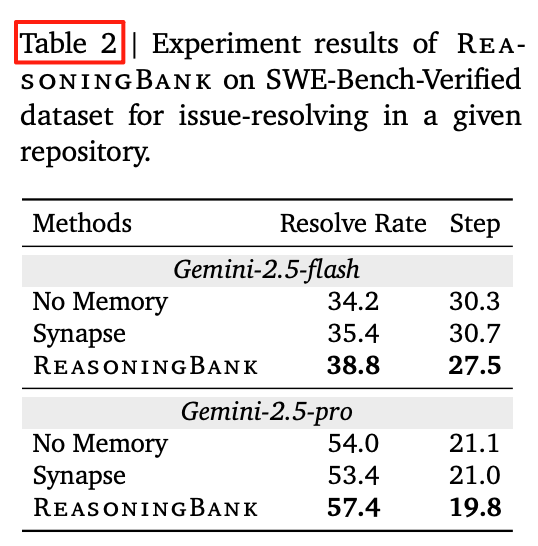
表 2:代码补丁分辨率,↑3.4~4.4%,步数 ↓2.8
3. Mind2Web 跨站/跨域泛化
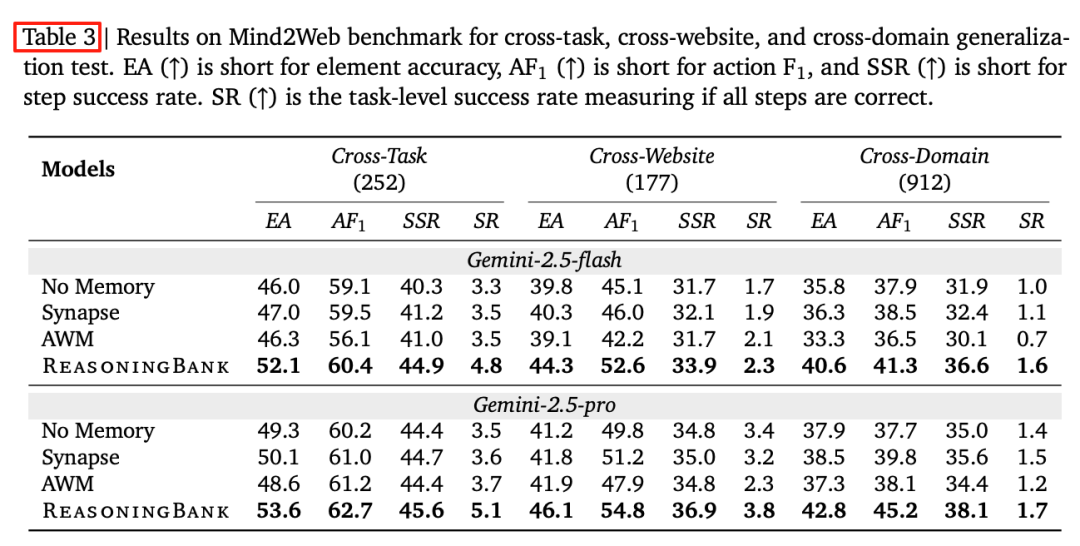
表 3:Cross-Domain 成功率翻倍,元素准确率 ↑4.8
六、失败样本有多香?一图胜千言

图 7:加入失败轨迹后,仅 ReasoningBank 能继续提升(49.7↑from 46.5),其余方法原地踏步甚至掉分
七、记忆也会“进化”! emergent strategy 案例

图 6:同一条记忆从“点按钮”→“自检元素”→“交叉验证”逐步长复杂,像 RL 的策略演化
八、局限 & 未来方向
|
当前局限 |
未来可卷 |
|---|---|
|
仅关注记忆内容,未对比层次/ episodic 结构 |
多层记忆 + 自适应检索 |
|
LLM-as-a-Judge 可能噪声 |
引入人类或更强 verifier |
|
记忆条目线性拼接,无组合推理 |
可组合/可宏调的Memory DSL |

一起“点赞”三连↓
更多推荐
 0
0 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)