
【昇思MindSpore技术公开课】请查收第三讲ChatGLM2知识点回顾
上周六的第三节课程中,我们讲解了从ChatGLM到ChatGLM2的技术改进点,同时带领大家在OpenI启智社区云脑算力上,使用Ascend+ModelArts+MindSpore部署ChatGLM2聊天机器人,并且介绍了最近开源的ChatGLM3的相关特性。未报名的小伙伴抓紧时间扫描下方二维码参与课程,并同步加入课程群,有免费丰富的课程资源在等着你。ChatGLM2在ChatGLM基础上,除了使
昇思MindSpore技术公开课大模型专题第二期课程火爆来袭!未报名的小伙伴抓紧时间扫描下方二维码参与课程,并同步加入课程群,有免费丰富的课程资源在等着你。课程同步赋能华为ICT大赛2023-2024,欢迎大家报名参与!

上周六的第三节课程中,我们讲解了从ChatGLM到ChatGLM2的技术改进点,同时带领大家在OpenI启智社区云脑算力上,使用Ascend+ModelArts+MindSpore部署ChatGLM2聊天机器人,并且介绍了最近开源的ChatGLM3的相关特性。下面我们对本节课程知识点进行简单总结,迎接下一节课程的继续深入。
【课程回顾】
1. ChatGLM2技术改进点解析
ChatGLM2在ChatGLM基础上,除了使用更大的训练数据达到更好的模型效果,以及使用了更开源的协议外,最重要两点便是引入了Multi-Query Atttention和FlashAttention算法。
1.1 Multi-Query Attention(MQA)
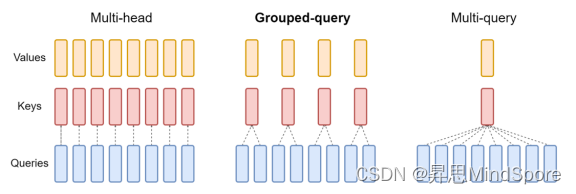
Motivation:为了解决Transformer结构的模型decoder进行incremental inference推理性能较慢的问题。
Method:在Multi-Head Attention(MHA)上做出了微小调整,所有头共享一对key和value,从而减少keys和values的缓存。
Result:有效提升了decoder推理速度,但在模型效果上稍差于MHA。
Development:后续演变出了Grouped-Query Attention,多个query一组,共享一对key和value,这种方式下模型推理速度高于MHA,但模型效果优于MQA。
1.2 FlashAttention
Motivation:更侧重硬件层面的优化,为了解决Transformer结构的模型时间和空间复杂度会随输入序列长度增长而进行二次增长的问题。
Previous work:自注意力计算矩阵稀疏化(sparse transformer)、降维(low-rank transformer)等,但计算出的attention并不是精确值。
Method:减少访问GPU显存的时间,原本为访问HBM,调整为访问SRAM
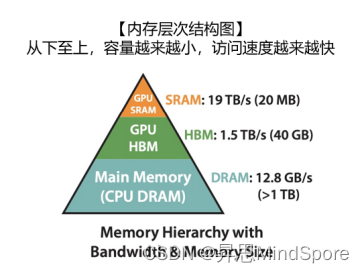
将参与计算的矩阵分块送入访问速度更快的SRAM中(关键实现:softmax的tiling展开、反向传播中的重计算、算子融合)。
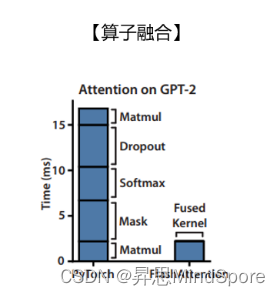

Result:训练速度同比提升了到了3倍以上。
2. 使用NPU+MindSpore Transformers试用ChatGLM2推理部署
环境配置:MindSpore 2.0.0, MindSpore Transformers dev
(具体操作与ChatGLM的推理相似,此处不做赘述,详见第一讲ChatGLM课程回顾)
3. ChatGLM3特性介绍
ChatGLM3相比ChatGLM2,使用了全新的prompt设计,并且可以原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
3.1 全新的prompt设计
Previous work:自然语言prompt格式,但不好进行多轮训练,并且无法进行原生工具调用
Method:引入了4种special tokens

<|system|>:系统信息,模型设定扮演的角色
<|user|>:用户输入,可以用于定位模型生成结束
<|assistant|>:AI 助手,模型输出,在出现之前必须有一个来自 <|user|> 的信息
<|observation|>:外部(例如调用工具)的返回结果,<|assistant|> 信息之后,同样可以用于定位模型生成结束
3.2 工具调用模式与代码解释器模式
工具模式:模型可进行工具调用,通过<|system|>中指定模型可调用的工具,可自行添加注册新的工具
代码解释器模式:提供代码运行环境,可进行图案绘画、数学计算等复杂运算
【课后练习】
1. ChatGLM2推理部署代码试运行
运行ChatGLM2推理部署代码,尝试和模型进行对话(如果出现回复不理想的情况,也欢迎在代码仓issue中进行反馈)
2. ChatGLM3试用
尝试ChatGLM3的各种模式对话
【课程预告】
昇思MindSpore技术公开课第二期的第四讲将在11月25日(周六)14:00-15:30与大家见面。为大家带来文本生成解码原理(包括采样、Beam search等)的讲解与代码演示,敬请期待!
更多推荐
 0
0 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)