
大模型三阶段解析:训练、微调与推理的区别与应用!
本文详细解析了大模型的三个关键阶段:训练(预训练和后训练)、微调和推理。训练是构建模型基础知识的阶段,需要海量数据和强大算力;微调则是针对特定领域优化模型,成本较低且周期短;推理是模型实际应用阶段,不再学习而是基于已有参数进行预测。三者从开发主体、数据需求、参数更新、成本和时间等方面各有不同,适用于不同场景和应用需求,为大模型的全生命周期提供了清晰指导。
简介
本文详细解析了大模型的三个关键阶段:训练(预训练和后训练)、微调和推理。训练是构建模型基础知识的阶段,需要海量数据和强大算力;微调则是针对特定领域优化模型,成本较低且周期短;推理是模型实际应用阶段,不再学习而是基于已有参数进行预测。三者从开发主体、数据需求、参数更新、成本和时间等方面各有不同,适用于不同场景和应用需求,为大模型的全生命周期提供了清晰指导。
训练(Training)
核心是“算力+算法+数据”,以强大的计算资源(GPU/TPU等)为硬件基础,结合算法,将数以万亿级的海量参数从0到1训练为具有复杂结构和特征的深度学习模型。
训练过程分为预训练(Pre-training)和后训练(Post-training),预训练的作用是构建知识基座,就好比想要写文章得先学认字一样;后训练是在预训练模型的基础上,通过特定任务数据优化模型,使模型更好的适应该特定领域的需求,就好比我们在高中学完语数外物化生,到了大学选择计算机专业深入学习。
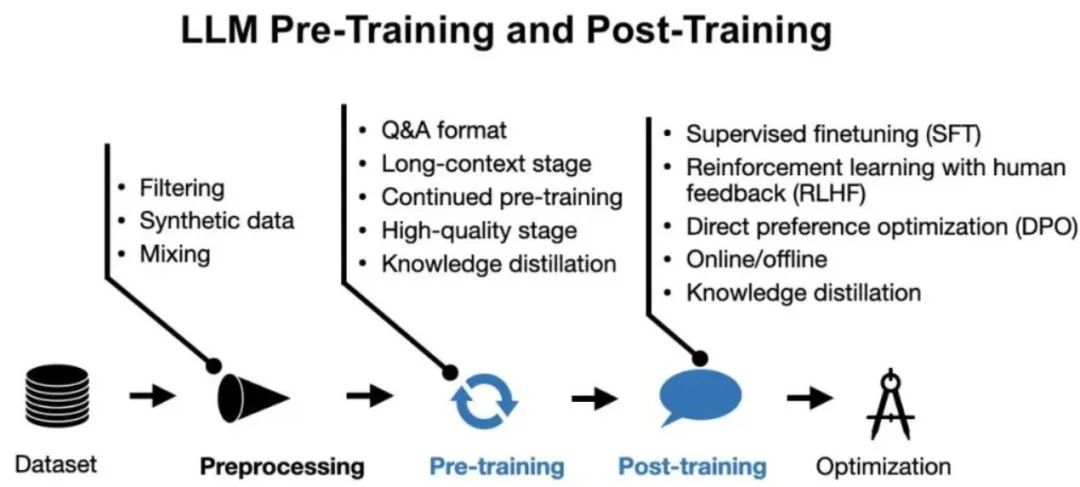
| 预训练 | 后训练 | |
| 主流架构 | Transformer | 全参数微调 |
| 扩展架构 | 混合专家模型 | 强化学习 |
| 学习方法 | 监督学习 | 监督微调 |
| 训练成本 | 高 | 低 |
| 训练时间 | 长 | 短 |
微调(Fine-tuning)
在训练模型的基础上,用特定领域的小规模标注数据进一步调整参数,使之在该领域的性能得以提升。
有人说,这微调和后训练没差别啊,确实很类似。后训练不是一次性的行为,会经过多次微调,但“后训练中的微调”“对训练模型的微调”在开发主体和应用场景上还是有些区别的。很多人都拿上学举例子,这确实生动易懂:
训练(预训练)——完成从小学到高中的所有基础课程。
训练(后训练)——选择计算机专业,学习与专业相关的数据结构、模拟电路、线性代数、C语言等。
微调——找了个工作是程序员,什么数电模电的先放下,把与今后工作相关的C语言知识再着重强化学习一下。
那么,我们再换个维度,把预训练、后训练和微调放一起做个对比吧。
| 预训练 | 后训练 | 微调 | |
| 开发主体 | 模型厂商 | 模型厂商 | 行业用户 |
| 应用场景,以GPT-4为例 | 训练ChatGPT聊天机器人的基础模型 | 出厂前对ChatGPT进行优化 | 让ChatGPT更适配某行业 |
| 数据需求 | 万亿级 | 十亿级 | 十万级 |
| 参数更新 | 全局参数更新 | 30%~70%参数更新 | 0.1%~0.3参数更新 |
| 成本 | 高 | 中 | 低 |
| 时间 | 长 | 中 | 短 |
推理(Inference)
在模型完成训练和微调后,进入实际应用阶段。推理阶段,模型不会再学习,而是根据已经训练好的参数对输入信息进行预测或决策。
推理应该是最好理解的,我们平时看的侦探小说、动画片,主角根据之前所探查的一系列“证据”,导出最终的“结果”。这个“结果”,是既成事实,不再衍生新的推断(柯南:什么,事情另有隐情,凶手也是个苦命人?)。
那么现在来比较一下训练和推理的一部分区别:
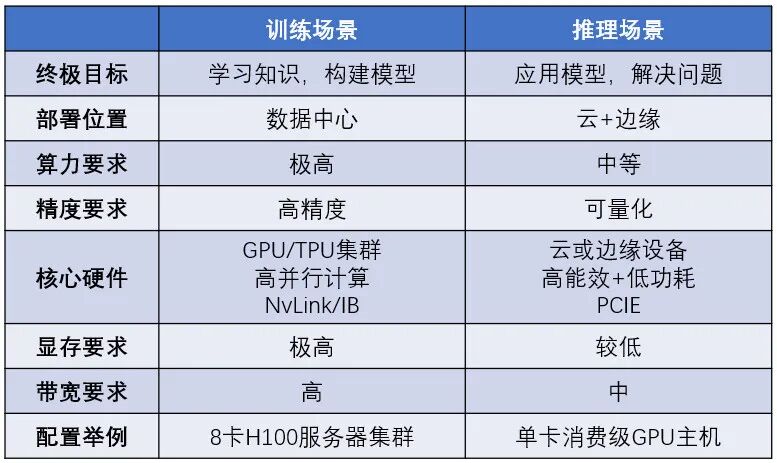
典型场景
训练
(1)通用语言模型构建:构建具备广泛只是理解能力的基座模型,如GPT。
(2)多模态模型预训练:多模态(如音频、视频)数据中包含更多的特征,可以弥补单个模态的缺陷,更适用于实际场景。
(3)行业基座模型开发。垂直领域基础建模,为特定行业(如智能制造、农业)从0开始构建行业模型。
微调
(1)专业领域知识注入:将垂直领域的专业知识(如规则、术语等)融入模型,提升其在该领域的性能,例如医学、法律等行业。
(2)任务定制化优化:针对具体任务调整模型结构,提升任务性能,如生成式AI。
(3)动态数据适应:使模型适应实时的数据变化,保持稳定性。像金融、医疗等行业,数据都是随时更新的。
推理(到了应用领域就太多了,随便说几个)
(1)在线服务:智能客服,内容生成。
(2)边缘/终端部署:便携设备。
(3)混合推理架构:自动驾驶。
推理(到了应用领域就太多了,随便说几个)
(1)在线服务:智能客服,内容生成。
(2)边缘/终端部署:便携设备。
(3)混合推理架构:自动驾驶。
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)