
加速扩散!西湖大学提出RDPO:强化学习框架,实现扩散模型并行推理加速
该研究的第一作者是来自西湖大学的博士生王若禹,伊利诺伊大学香槟分校的本科生李子誉,和南洋理工大学的博后朱贝尔,指导老师是西湖大学助理教授张驰,该研究是在团队ICCV 2025录用论文EPD-Solver基础上的扩展。RDPO的成功证明了:高质量的生成不一定要靠堆算力去硬磕大模型参数,巧妙的优化策略往往能以极小的代价换取极大的增益。早在上半年,西湖大学AGI Lab就发表了初版EPD-Solver,
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料及应用!发论文/搞科研/涨薪,强烈推荐!

非羊 整理自 凹非寺
转载自:量子位(QbitAI)
用扩散模型(比如Stable Diffusion)一张张“挤”出高分辨率图像的时代,正在被世界模型实时生成高清视频的浪潮冲刷。
但无论图像还是视频,扩散模型骨子里的“顺序去噪”过程,就像一场无法并行的接力赛,成为速度提升的终极瓶颈。
如何在不伤及模型“绘画功力”的前提下,为它装上加速引擎?
西湖大学AGI Lab提出的RDPO(残差狄利克雷策略优化)框架,给出了一种巧妙的答案:不必改动模型本身,而是优化它的“采样导航系统”。

扩散模型(DMs)虽然取得了最先进的生成性能,但由于其顺序去噪的特性,面临着采样延迟高的问题。现有的基于求解器的加速方法在低延迟预算下往往面临严重的图像质量退化,这主要是由于无法捕获高曲率轨迹段而导致的累积截断误差所致。
集成并行方向求解器(Ensemble Parallel Direction Solver,简称EPD-Solver)通过在每一步中整合多个并行梯度评估来减少此类误差。受采样轨迹基本受限于低维流形这一几何洞察的启发,EPD-Solver利用向量值函数均值定理更准确地逼近积分解。
重要的是,由于额外的梯度计算是独立的,它们可以完全并行化,从而保持低延迟采样的特性。
团队引入了一个两阶段优化框架:最初,EPD-Solver通过基于蒸馏的方法优化一小组可学习参数;随后,团队进一步提出了一种参数高效的强化学习微调框架RDPO,将求解器重新构建为随机的狄利克雷(Dirichlet)策略。
与微调庞大骨干网络的传统方法不同,团队的RL方法严格在低维求解器空间内运行,在增强复杂文本到图像(T2I)生成任务性能的同时,有效缓解了奖励作弊(Reward Hacking)现象。此外,团队的方法具有灵活性,可以作为插件(EPD-Plugin)来改进现有的ODE采样器。
通过大量实验,证明了EPD-Solver的有效性以及RDPO框架的优越性。在相同步数下,该方法在CIFAR-10、FFHQ、ImageNet等多个基准测试中取得了领先的图像生成效果,展示出其在低延迟高质量生成任务中的巨大潜力。
在Text-to-Image任务中,经过RDPO优化的EPD-Solver显著提升了Stable Diffusion v1.5和SD3-Medium的生成能力,在更少的步数下,达到更优的质量。
能否在不乱动模型大笔触的前提下,优雅地完成加速与对齐?
早在上半年,西湖大学AGI Lab就发表了初版EPD-Solver,通过并行计算采样轨迹某些中间点的梯度,来优化每一步去噪的方向,实现在较低步数下提升生成质量。
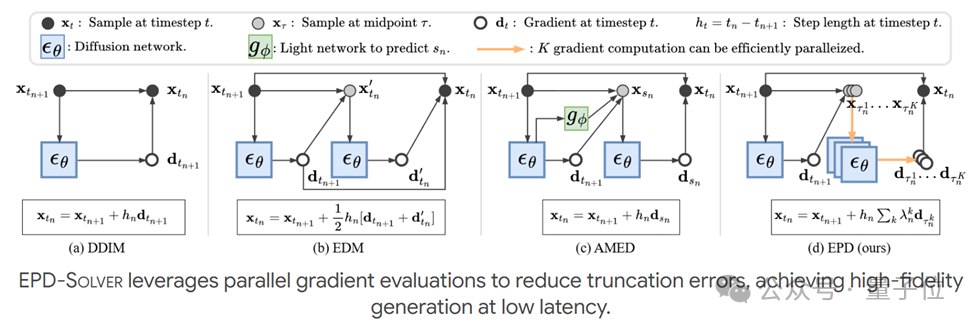
近期,团队提出了RDPO(残差狄利克雷策略优化)框架,来进一步提升EPD-Solver采样器的能力。
它不去暴力拆解模型本体,而是将目光锁定了求解器的参数空间。
核心秘籍:站在“巨人”肩膀上的低维残差微调
RDPO的设计精髓可以概括为:先找准基准线,再做残差微调。
既然模型骨干(Backbone)已经很强了,为什么不只优化采样路径上的几个关键节点?
团队将任务转化为了一个低维空间的策略优化问题:
1. 第一阶段:锁定高精度“赛道”
团队首先利用轨迹蒸馏技术,让EPD-Solver学习高精度教师求解器(如DPM-Solver-2)的采样路径。这一步决定了采样的“基本盘”,确保画出来的东西在物理逻辑上是正确的。
2. 第二阶段:残差策略优化
这是RDPO最亮眼的部分。团队没有让RL去直接修改几亿参数的模型,而是将其建模为一个残差策略:
-
非零起点:RL并不是在真空中探索,而是将第一阶段得到的参数作为起始策略。
-
只学“偏移量”:RDPO在对数浓度空间(Log-concentration space)中只学习一个极小的残差项。这意味着AI只能在已经很完美的采样路径附近进行修正。
这种“残差”设计就像是给赛车手提供了一条精准的职业赛车线,RL只是在入弯角度上做微调,而不是重新发明怎么开车。
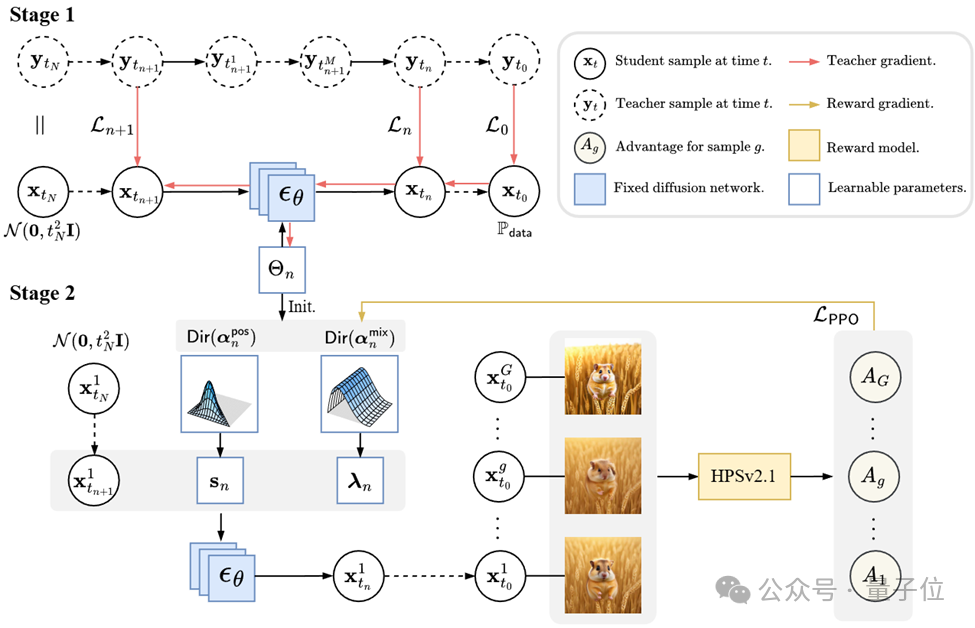
告别“奖励作弊(RewardHacking)”
RDPO完美避开了这个坑:
-
低维屏障:优化空间被严格限制在求解器参数层面。AI失去了修改底层像素纹理的“作案工具”,只能通过改变采样节点的权重来对齐审美。
-
物理约束:由于是基于狄利克雷分布的残差优化,采样轨迹始终被约束在数学上的单纯形(Simplex)空间内。
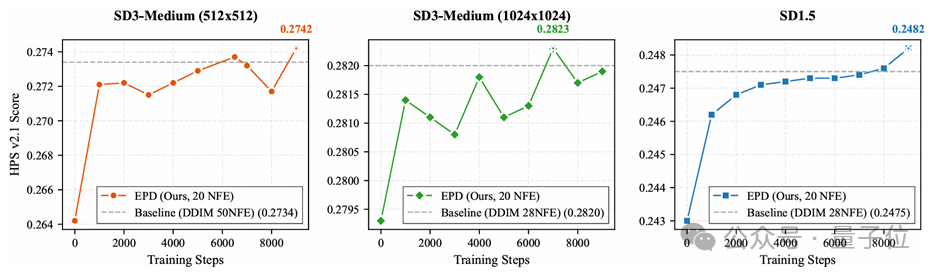
HPS v2.1不同模型和分辨率下的训练动态评分:
训练过程中生成样本图像的演变:

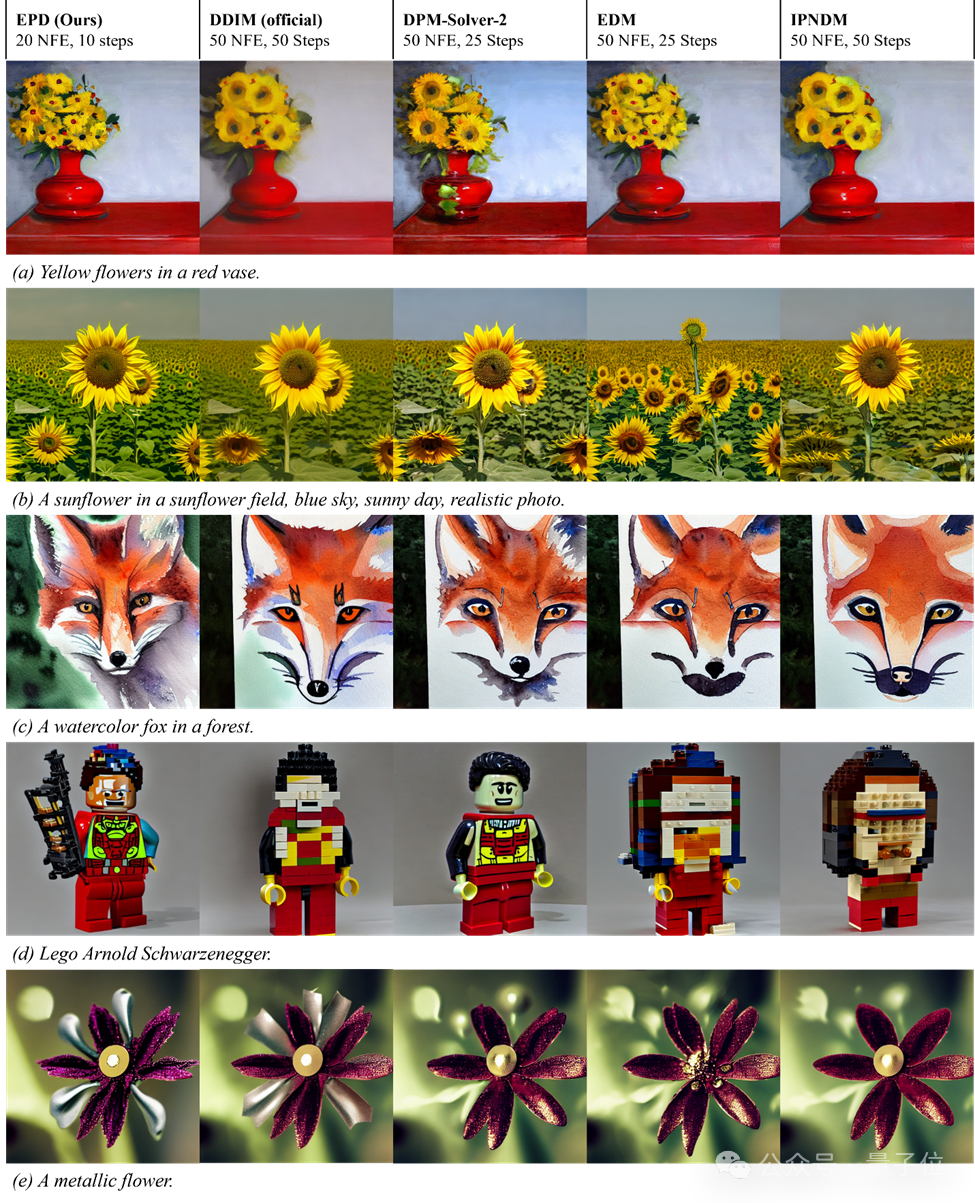
以下是经过RDPO优化的EPD-Solver在文生图(T2I)任务的表现:
部分在数据集上的定量测试结果:
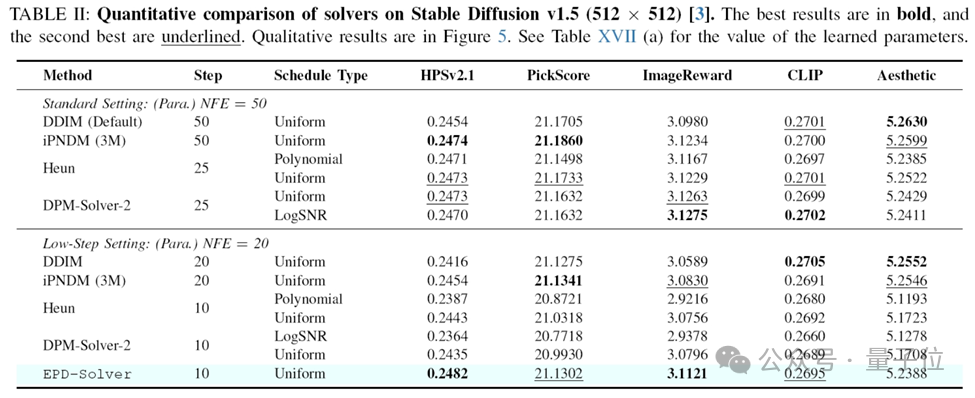
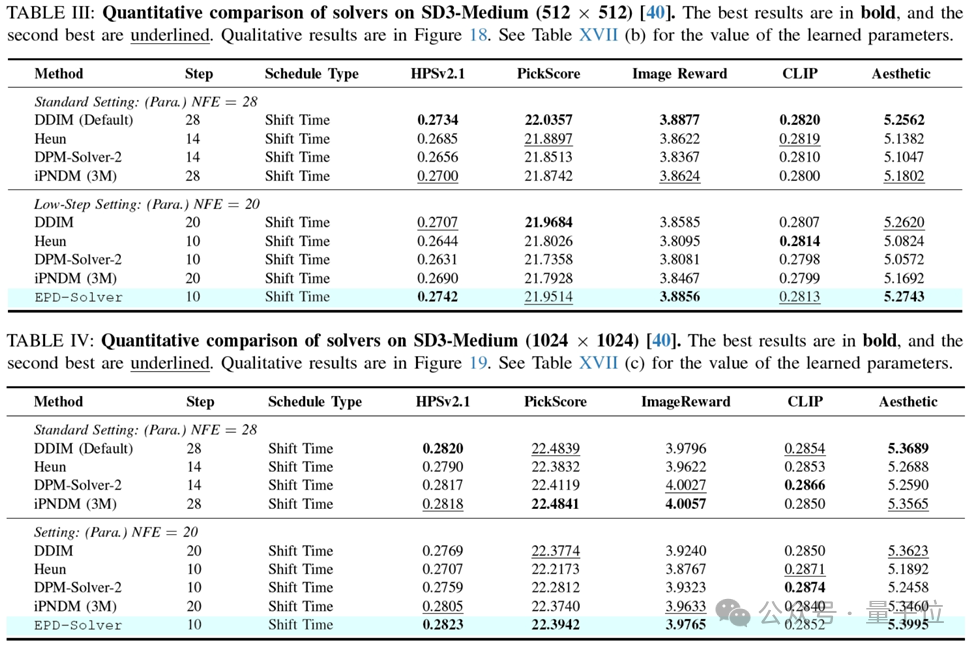
RDPO的成功证明了:高质量的生成不一定要靠堆算力去硬磕大模型参数,巧妙的优化策略往往能以极小的代价换取极大的增益。它不仅解决了加速问题,更提供了一种极其稳健的RLHF对齐新范式。
(文中的所有展示图片都截取自原论文)
该研究的第一作者是来自西湖大学的博士生王若禹,伊利诺伊大学香槟分校的本科生李子誉,和南洋理工大学的博后朱贝尔,指导老师是西湖大学助理教授张驰,该研究是在团队ICCV 2025录用论文EPD-Solver基础上的扩展(https://arxiv.org/abs/2507.14797)。
西湖大学AGI Lab由张驰教授指导,致力于探索下一代通用人工智能技术。
论文题目:
Parallel Diffusion Solver via Residual Dirichlet Policy Optimization
论文地址:
https://arxiv.org/abs/2512.22796
项目地址:
https://epd-solver.github.io/
GitHub链接:
https://github.com/BeierZhu/EPD
本文系学术转载,如有侵权,请联系CVer小助手删文
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ICCV 2025 论文和代码下载
在CVer公众号后台回复:ICCV2025,即可下载ICCV 2025论文和代码开源的论文合CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看
更多推荐

 0
0 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)