
一文看懂KTransformers:大模型推理的革新利器
大模型发展面临算力与成本困境,云服务器租赁贵且不稳定,本地部署硬件成本高。KTransformers 开源项目应运而生,它能在有限资源下实现大模型本地高效部署,通过异构计算、量化与算子优化、CUDA Graph 加速等技术,提升推理效率,降低成本。虽存在推理速度慢、模型支持有限和 CPU 依赖等局限,但未来有望在多领域广泛应用,推动人工智能技术发展。

大模型推理困境:算力与成本的双重枷锁
在数字化浪潮蓬勃发展的当下,大模型凭借其强大的语言理解与生成能力,已成为推动各行业变革的关键力量。从智能客服高效解答客户疑问,到内容创作领域辅助创作者产出优质内容;从医疗领域协助医生精准诊断疾病,到金融行业助力风险评估与投资决策,大模型的应用广泛且深入,为人们的生活和工作带来了显著的便利与创新。
然而,随着模型规模呈指数级扩张,算力与成本的双重挑战日益凸显。以GPT-3为例,其拥有1750亿个参数,训练一次所需的算力极为庞大,若将其算力需求具象化,类比为一个小型城市的所有居民持续进行高强度计算,方能勉强满足其训练要求。在推理阶段,大模型同样对算力有着极高的要求,每次与模型的交互,无论是简单的问答还是复杂的文本生成,背后都依赖大量计算资源的支撑。
从成本角度考量,无论是选择云服务器租赁还是进行本地硬件部署,都面临着巨大的经济压力。云服务器租赁费用高昂,持续消耗企业和研究机构的资金。以某知名云服务提供商为例,一台配备高性能GPU的云服务器,每月租金可达数万元甚至更高,对于长期、大规模使用大模型的用户而言,这无疑是沉重的负担。此外,云服务器还存在稳定性问题,偶尔的宕机可能导致服务中断,给用户带来不可估量的损失。
本地部署虽能在一定程度上规避云服务器的不稳定因素,但也面临困境。高性能硬件设备的采购成本极高,购置一套能够满足大型模型运行的硬件设备,动辄需要数十万元甚至上百万元,这对于许多初创企业和小型研究团队来说,是难以跨越的障碍。并且,硬件设备的维护与升级成本也不容忽视,需要持续投入大量资金和人力。
以拥有671B参数的DeepSeek-R1模型为例,运行这样的大模型,传统方式要么选择云服务器,面临着高昂的租赁成本和不稳定的宕机风险;要么本地部署,但普通硬件无法满足其算力需求,往往只能运行参数缩水的蒸馏版,无法充分发挥模型的真正实力。大模型的算力与成本困境,已成为制约其进一步发展与广泛应用的关键瓶颈,亟待突破。
KTransformers横空出世
在大模型推理陷入算力与成本困境,众人寻求破局之法而不得时,2月10日,清华大学KVCache.AI团队联合趋境科技,推出了“秘密武器”——KTransformers开源项目,迅速吸引了整个AI领域的关注。
KTransformers的出现,旨在解决大模型本地部署难题,实现资源有限情况下大模型的高效本地部署,让更多人能够在自己的设备上运行曾经遥不可及的大型模型。这一目标切中了当下大模型发展的痛点,为众多个人研究者和小型团队带来了希望。
KTransformers的成果令人瞩目,它成功打破了大模型推理算力的门槛,实现了在24G显存的4090D显卡上,本地运行DeepSeek-R1、V3的671B“满血版”模型。此前运行这样的大模型,要么需要配备昂贵的专业服务器,要么只能运行参数量大幅缩水的蒸馏版,而KTransformers的出现彻底改变了这一局面,使普通用户也能拥有强大的大模型推理能力。
在预处理速度上,KTransformers最高可达286 tokens/s,推理生成速度最高也能达到14 tokens/s。这意味着用户在与模型交互时,能够快速得到模型的响应,大大提高了工作效率。甚至有开发者借助这一优化技术,在3090显卡和200GB内存的配置下,使Q2_K_XL模型的推理速度达到9.1 tokens/s,实现了千亿级模型的“家庭化”运行。这一突破让大模型不再是高高在上的“奢侈品”,而是走进了千家万户,成为普通用户也能驾驭的工具。
KTransformers的诞生,是大模型发展史上的重要里程碑,为大模型本地部署指明了方向,让人们对大模型的未来应用充满更多期待。接下来,让我们深入探索KTransformers的技术原理。
探秘KTransformers核心技术
KTransformers在大模型推理领域取得显著成效,依靠的是一系列先进的硬核技术。这些技术精准针对大模型推理的痛点,从多个维度优化模型的运行效率和成本。以下将深入剖析KTransformers的核心技术,揭开其高效运行大模型的神秘面纱。
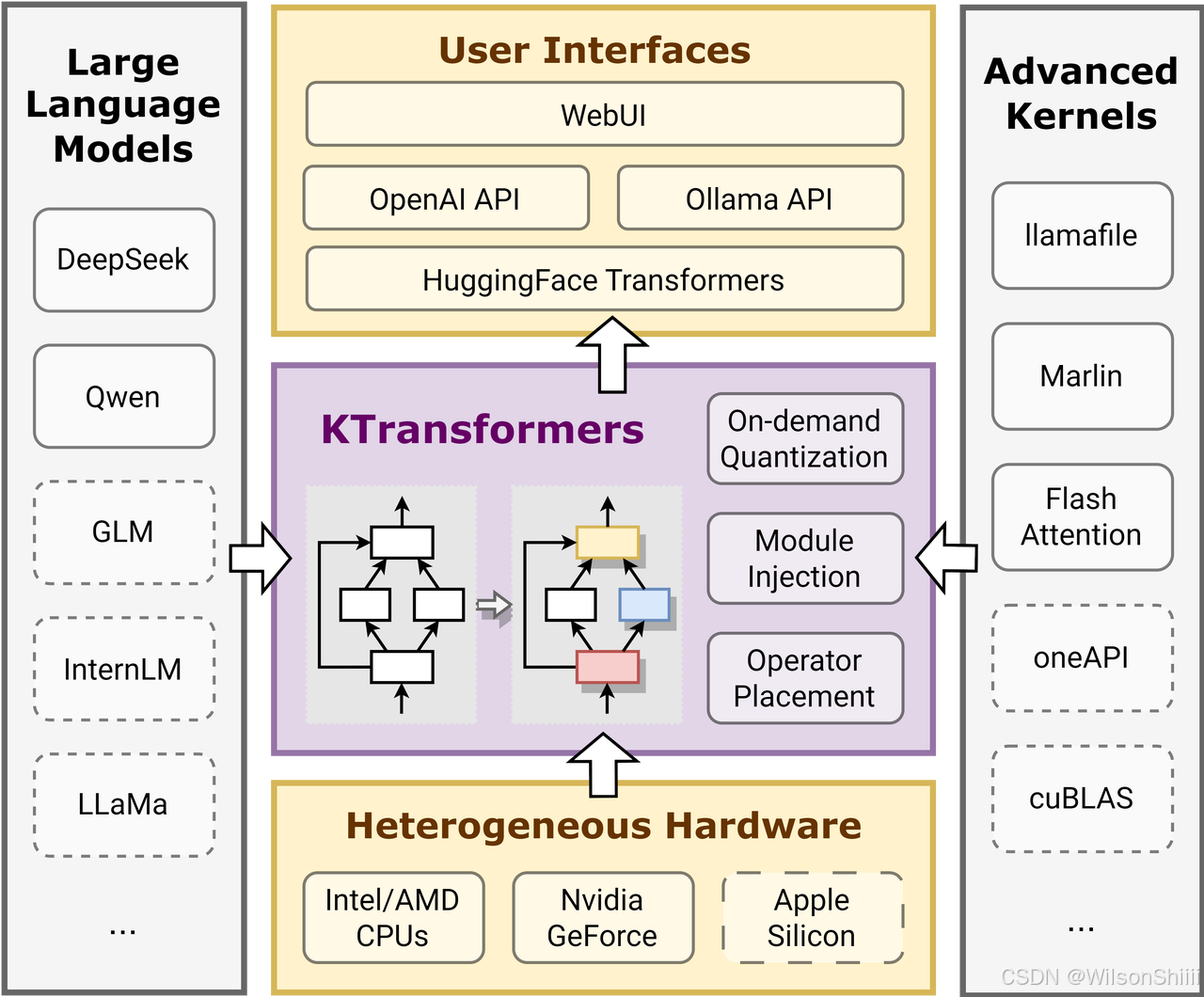
异构计算,巧妙分工
在大模型的推理过程中,不同的计算任务具有不同的特点,有的计算量极大,对计算速度要求极高;有的任务虽然参数众多,但计算量相对较小。若所有任务都集中在GPU上处理,不仅会造成资源浪费,还会影响计算效率。
KTransformers巧妙利用混合专家(MoE)架构的稀疏性,将非共享的稀疏矩阵卸载至CPU内存进行处理。这一操作有效降低了对GPU显存的需求,原本需要320GB显存的模型,在KTransformers的优化下,仅需24GB即可运行。
在具体的计算任务分配上,KTransformers将计算复杂、参数较少的MLA注意力模块留在GPU上处理,因为GPU在并行计算方面具有优势,能够快速处理这类需要高速计算的任务。而对于参数较大、计算较轻的FNN(MOE)模块,KTransformers则将其交由CPU执行,CPU虽然计算速度相对较慢,但在处理大量参数时能够有条不紊地进行计算,确保任务顺利完成。
在GPU/CPU协同方面,KTransformers将MLA层保留在GPU,而把路由专家层卸载至CPU,并充分利用Intel至强AMX指令集进行加速。通过这种动态任务分配方式,根据计算强度分级调度,使每个计算资源都能得到充分利用,大幅提升了整体计算效率。
量化与算子优化,加速推理
在大模型处理数据的过程中,数据量庞大,如同巨大的冰山,给模型运行带来负担。为了提升模型运行效率,KTransformers采用了4bit量化技术,该技术能够将模型的显存占用压缩至原版的10%。以Q4_K_M量化模型为例,原本需要大量显存支持的它,在4bit量化技术的加持下,仅需14GB的显存就能运行,显著减轻了硬件负担。
除了4bit量化技术,KTransformers还引入了Marlin GPU算子,对模型的计算过程进行深度优化,使推理效率大幅提升。与优化前相比,推理速度提高了3.87倍,模型能够在更短的时间内处理更多数据,工作效率得到极大提高。
在CPU端,KTransformers采用的llamafile CPU算子支持NUMA感知并行,能够根据硬件的架构特点合理分配计算任务,进一步提升了CPU的计算效率。通过4bit量化技术与Marlin GPU算子、llamafile CPU算子的协同作用,KTransformers为大模型的推理过程打造了一个高效的“加速引擎”。
CUDA Graph加速,减少开销
在大模型的推理过程中,CPU和GPU之间的通信频繁,产生大量开销,如同物流运输中的各种费用,消耗大量时间和资源。为降低这些开销,KTransformers引入了CUDA Graph加速技术,对CPU和GPU之间的通信进行深度优化。
CUDA Graph加速技术将一系列的GPU操作组合成一个“图”结构,然后一次性提交给GPU执行。这一操作减少了CPU和GPU之间的通信次数,从而降低了通信开销。在传统的模型运行过程中,每次解码都需要多次进行CPU和GPU之间的通信,而KTransformers通过优化,使得每次解码仅需一次完整的CUDA Graph调用,大大提高了运行效率。
具体数据显示,在KTransformers的优化下,生成速度提升至14 tokens/s,功耗仅80W。与传统方式相比,预处理速度较llama.cpp快28倍,实现了高效与节能的双赢。CUDA Graph加速技术为大模型的高效运行提供了有力保障。
灵活可扩展性
KTransformers采用模块化设计,通过YAML配置文件,用户可以根据自身需求自定义量化策略与内核组合,具有极高的灵活可扩展性。
无论是在Windows系统还是Linux系统上,KTransformers都能完美适配。并且,它还集成了ChatGPT式Web界面,方便用户与模型进行交互,无论是专业开发者还是普通用户,都能轻松上手。
KTransformers实战表现
安装与部署指南
理论知识固然重要,但实际操作才能真正掌握技术。以下为KTransformers的安装与部署指南,帮助读者亲身体验这一神奇技术的魅力。
- 下载源代码:从GitHub上下载KTransformers的源代码。打开浏览器,输入KTransformers的GitHub地址(https://github.com/kvcache-ai/ktransformers ),进入项目页面后,点击绿色的“Code”按钮,选择“Download ZIP”选项,将代码以ZIP格式下载到本地电脑。下载完成后,解压文件,即可获取KTransformers的源代码。
- 创建虚拟环境:为避免不同项目之间的依赖冲突,推荐使用Conda创建虚拟环境。打开命令行终端,输入以下命令:
conda create --name ktransformers python=3.11
conda activate ktransformers
这两条命令会创建一个名为“ktransformers”的虚拟环境,并激活它。若首次使用Conda,可能需要先运行“conda init”并重新打开终端。
- 安装依赖库:激活虚拟环境后,安装KTransformers所需的依赖库,这些依赖库是KTransformers运行的基础,在命令行中输入以下命令:
pip install torch packaging ninja cpufeature numpy
这些依赖库包括PyTorch、packaging、ninja、cpufeature和numpy等。
- 编译源代码:由于KTransformers包含一些自定义的算子和优化策略,需要编译源代码来生成可执行文件。进入KTransformers的源代码目录,使用CMake等工具来编译源代码。开发者还可以使用Makefile来编译和格式化代码。
cd ktransformers
mkdir build
cd build
cmake..
make -j
- 配置环境变量:为方便运行KTransformers,需要将编译生成的可执行文件所在的目录添加到系统的环境变量中。这样,就可以在任何地方通过命令行来运行KTransformers。具体配置方法因操作系统而异,以Linux系统为例,可以编辑~/.bashrc文件,在文件末尾添加以下内容:
export PATH=$PATH:/path/to/ktransformers/build
其中,“/path/to/ktransformers/build”是KTransformers编译生成的可执行文件所在的目录。添加完成后,保存文件并执行以下命令使配置生效:
source ~/.bashrc
性能实测数据
为了直观展示KTransformers的实际性能,在RTX 4090单卡上运行DeepSeek-R1,进行全面的性能测试,得到以下数据:
- 预处理速度:KTransformers最高可达286 tokens/s,与传统的llama.cpp相比,预处理速度快了28倍,传统llama.cpp的预处理速度约为10.21 tokens/s(286÷28)。
- 推理生成速度:最高能达到14 tokens/s,在与模型交互时,用户能够快速得到响应,提高了工作效率。
- 显存占用和内存占用:显存占用约为14GB,内存占用约为380GB。与传统方案中运行DeepSeek-R1需要320GB显存相比,KTransformers的显存需求被成功压缩至14GB。
优势与局限并存
显著优势
KTransformers在大模型推理领域展现出诸多显著优势:
- 成本优势:在传统方案中,运行DeepSeek-R1这样的大模型,通常需要配备8卡A100服务器,硬件采购成本高达百万元,按需计费每小时费用数千元,这对于许多个人研究者和小型团队来说是难以承受的。而KTransformers仅需单张RTX 4090显卡,整机成本约2万元,整套方案不到7万元,成本降低95%以上,大大降低了大模型运行的成本门槛。
- 技术优势:支持更长的上下文,在处理上万级Token上下文任务时,能够快速准确地进行处理,而其他一些传统方案可能会出现卡顿甚至无法处理的情况。推理生成速度最高可达14 tokens/s,在文本生成场景中,能够快速生成高质量的文本。采用4bit量化技术和Marlin GPU算子配合,使得推理效率较传统方案提升了3.87倍。
- 框架优势:采用模块化设计,通过YAML配置文件,用户可以自由选择和组合量化策略与内核,自定义模型的运行方案。在Windows系统和Linux系统上都能完美适配,并且集成了ChatGPT式Web界面,方便用户与模型交互。
现存局限
尽管KTransformers取得了显著进展,但目前仍存在一些局限性:
- 推理速度方面:与高端服务器相比,KTransformers在处理对实时性要求极高的任务时,如大型游戏中的实时智能NPC对话、金融高频交易中的快速风险评估等场景,推理速度稍慢,无法满足这些场景的严格要求。
- 模型支持方面:目前主要针对DeepSeek的MOE模型进行优化,对于其他主流模型,如GPT系列、BERT等的支持还有待提高,在运行这些模型时可能无法充分发挥其优势,甚至会出现兼容性问题,限制了其应用范围。
- CPU依赖方面:KTransformers依赖英特尔的AMX指令集,这使得使用其他品牌CPU(如AMD等)的用户无法使用这一技术,限制了其在更广泛用户群体中的推广和应用。不过,目前相关团队也在探索其他可能的优化方向,未来或许能够降低对特定指令集的依赖 。
KTransformers的无限可能
随着科技的不断发展,KTransformers在大模型推理领域的潜力将逐渐被挖掘,未来发展前景广阔。
在自然语言处理领域,KTransformers有望助力小型语言科技公司开发出更智能的聊天机器人,能够更精准地理解用户意图,提供更人性化的回答;在机器翻译方面,可使翻译结果更加流畅自然,促进全球信息流通。
在图像识别领域,KTransformers能够帮助研究人员训练出更高效的图像分类模型,在安防监控中,能够更快速准确地识别异常行为和目标物体;在医疗影像诊断中,辅助医生更精准地检测疾病,提高诊断效率和准确性。在智能推荐领域,KTransformers能为电商平台和内容平台提供更个性化的推荐服务,根据用户的浏览历史、购买行为等数据,精准推荐符合用户需求的商品和内容,提升用户体验和平台的转化率。
KTransformers的出现,刺激了消费级显卡市场的需求。为满足不断增长的大模型计算需求,硬件厂商将不断研发和推出性能更强大的显卡,推动硬件技术的进步,形成良性的技术发展循环。
更多推荐


 47
47 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)