
大模型微调教程:0 基础也能用云算力微调一个Ai甄嬛
微调相当于是可以使用自己的私有数据,私人定制一个专属大模型,比如法律领域、医疗领域、政务场景等。可以自定义模型回复的语气,个性和风格,你把大模型想象成一个小孩子,你想让他成为什么样,你就教他什么(训练语料数据集)。官话:微调LLM可定制其行为,增强领域知识,并针对特定任务优化性能。通过在特定数据集上微调预训练模型,旨在更有效地执行特定任务。实操部分。
入门最好的方式是实操,这篇文章一共耗时 7 个小时,用大白话和实操的角度给大家分享一下, 0 基础入门微调大模型
 今天阿里开源了 QwQ-32B 推理模型,320 亿参数和 DeepSeek 6710亿参数几乎相同的效果,部署成本和微调成本越来越低,所以,在做应用开发的同时,掌握微调的技能也很重要。
今天阿里开源了 QwQ-32B 推理模型,320 亿参数和 DeepSeek 6710亿参数几乎相同的效果,部署成本和微调成本越来越低,所以,在做应用开发的同时,掌握微调的技能也很重要。
这个文章,用大白话,面向纯小白,一步一步可实操,带你从 0 到1使用云算力(不受本地电脑配置限制)微调大模型。
学习目标:使用云算力、使用一站式微调框unsloth、下载部署Llama3模型、使用甄嬛剧本微调模型——Ai 甄嬛、了解微调的意义和概念
主要包含:
理论部分:
1、大白话讲讲什么是微调?
实操部分:
1、租用算力
2、安装依赖
3、下载训练数据集
4、加载 Llama3 模型
5、微调训练
6、保存并使用微调后的模型
理论部分
1、什么是微调
微调相当于是可以使用自己的私有数据,私人定制一个专属大模型,比如法律领域、医疗领域、政务场景等。
可以自定义模型回复的语气,个性和风格,你把大模型想象成一个小孩子,你想让他成为什么样,你就教他什么(训练语料数据集)。
"
官话:微调LLM可定制其行为,增强领域知识,并针对特定任务优化性能。通过在特定数据集上微调预训练模型,旨在更有效地执行特定任务。
实操部分
一、租用算力
云算力地址:https://www.autodl.com
第一步:打开网站——控制台——容器实例——租用新实例
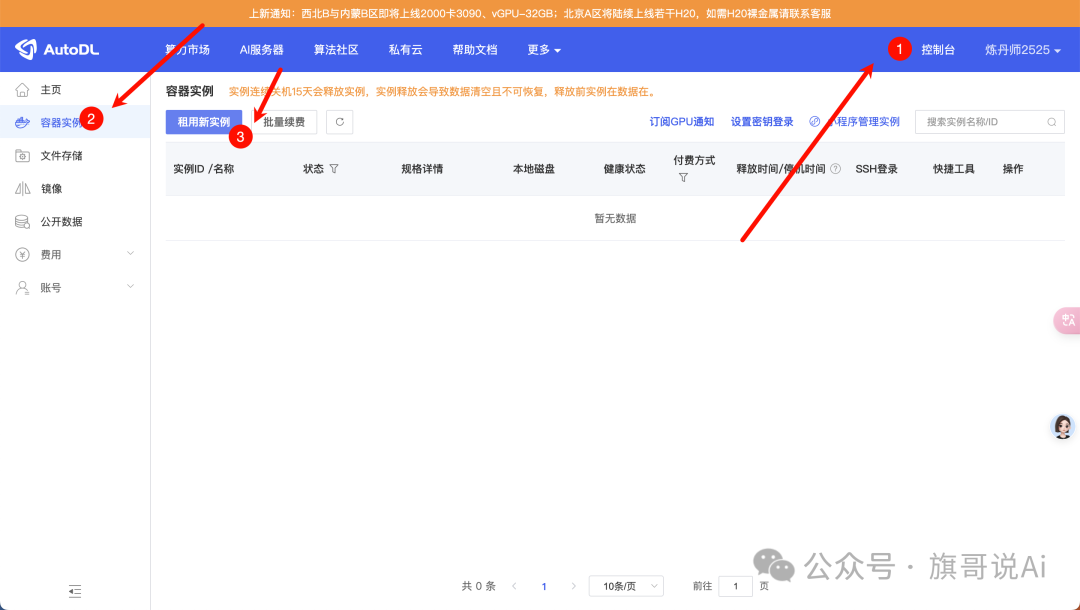 image.png
image.png
第二步:
分别选择: 1、按量计费 2、地区和 GPU 选择一个 ,4090显卡,有资源的即可(空闲 GPU>0 的) 3、磁盘选择不扩容(50G 即可) 4、镜像:选择CUDA 12.4 和 PyTorch 2.5*
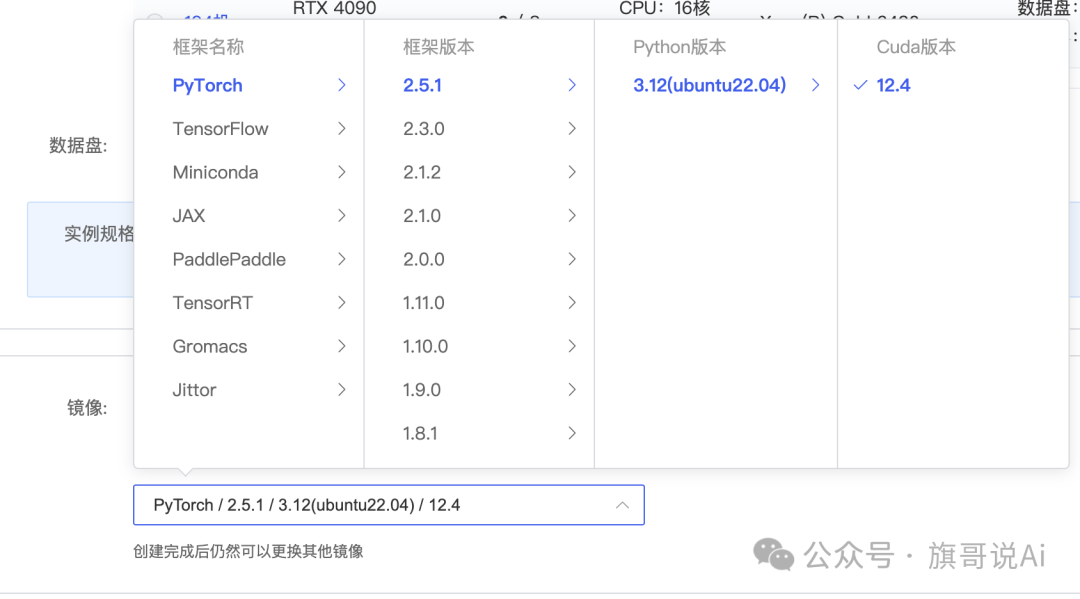 image.png
image.png
创建好了之后会进行跳转
点击jupyter进入开发界面
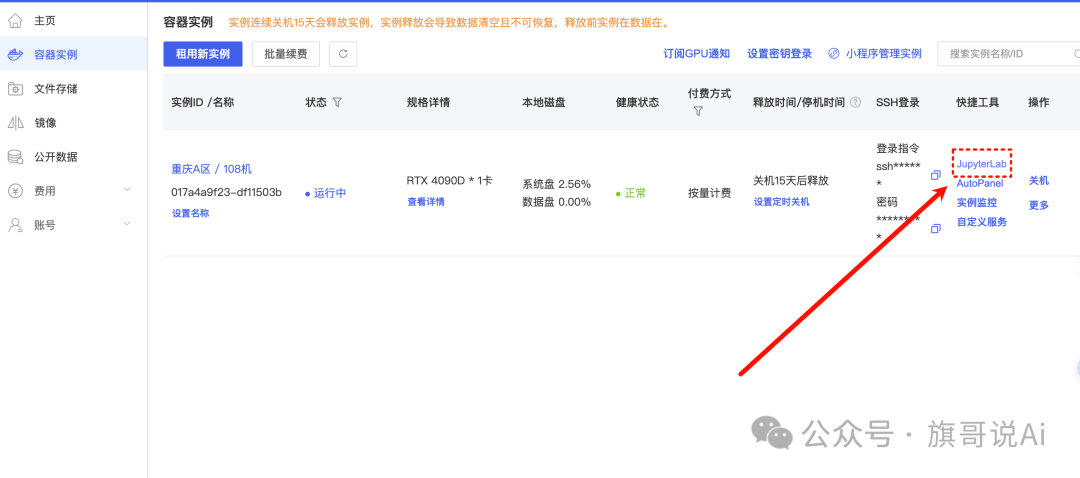 进入到下面的页面,就可以用云算力了。
进入到下面的页面,就可以用云算力了。
 image.png
image.png
二、下载大模型
在终端命令行中执行以下代码:
1、安装unsloth微调框架
pip install "unsloth[cu124-torch250] @ git+https://github.com/unslothai/unsloth.git"
2、安装依赖 在命令行终端,执行命令如下:
pip install --upgrade pip
pip install modelscope
3.下载训练数据集
左边侧边栏,右键新建记事本,复制图片下方的代码,执行一下。
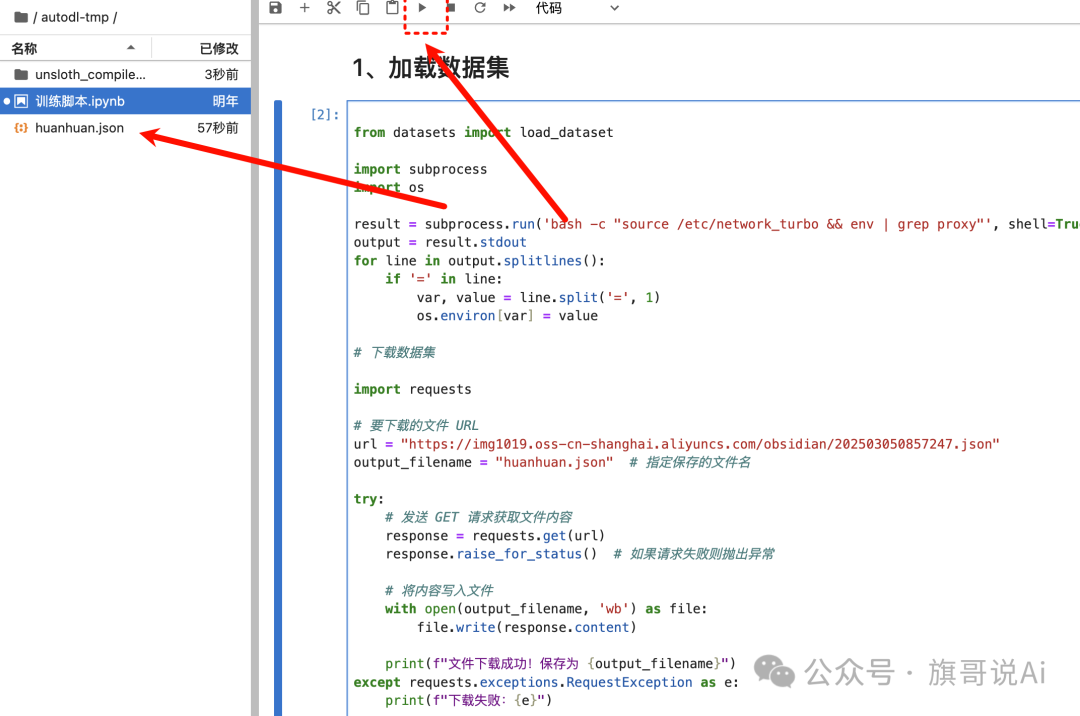 image.png
image.png
加载数据集:
from datasets import load_dataset
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if'='in line:
var, value = line.split('=', 1)
os.environ[var] = value
# 下载数据集
import requests
# 要下载的文件 URL
url = "https://img1019.oss-cn-shanghai.aliyuncs.com/obsidian/202503050857247.json"
output_filename = "huanhuan.json"# 指定保存的文件名
try:
# 发送 GET 请求获取文件内容
response = requests.get(url)
response.raise_for_status() # 如果请求失败则抛出异常
# 将内容写入文件
with open(output_filename, 'wb') as file:
file.write(response.content)
print(f"文件下载成功!保存为 {output_filename}")
except requests.exceptions.RequestException as e:
print(f"下载失败:{e}")
# 加载 数据集
dataset = load_dataset("json", data_files={"train": "./huanhuan.json"}, split="train")
4、然后下载完整的模型库
执行图片下方的代码
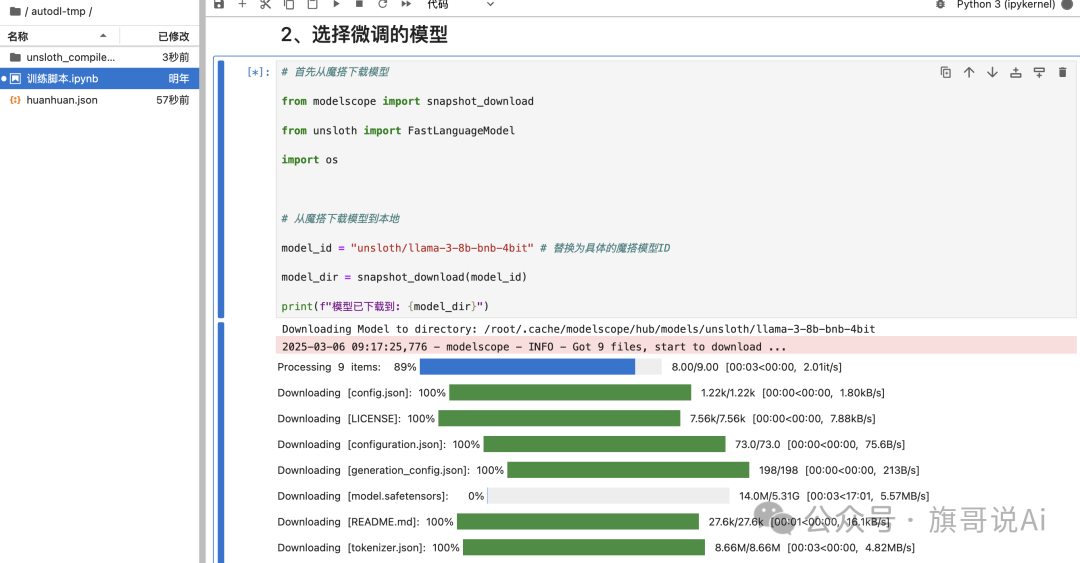 image.png
image.png
代码如下:
# 首先从魔搭下载模型
from modelscope import snapshot_download
from unsloth import FastLanguageModel
import os
# 从魔搭下载模型到本地
model_id = "unsloth/llama-3-8b-bnb-4bit"# 替换为具体的魔搭模型ID
model_dir = snapshot_download(model_id)
print(f"模型已下载到: {model_dir}")
大约需要 5-10 分钟
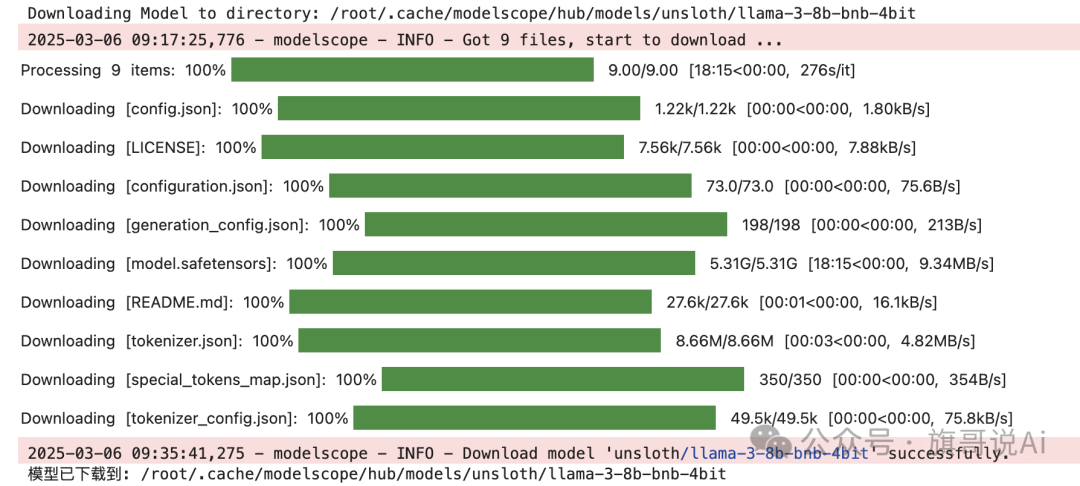 image.png
image.png
这几个都下载完成,就可以下一步了~
在代码文件中,新增代码块,一步一步执行下去就行了。
三、训练模型
1、加载模型
代码如下:
# 加载模型
load_in_4bit=True
# 然后使用Unsloth加载本地模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_dir, # 使用下载到本地的模型路径
max_seq_length=2048, # 设置最大序列长度
load_in_4bit=True, # 使用4位量化以节省显存
dtype=None
)
2、配置微调参数
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA 的秩
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16, # LoRA 的缩放因子
lora_dropout=0, # LoRA 的 dropout 概率
bias="none", # 是否使用偏置
use_gradient_checkpointing="unsloth", # 使用 Unsloth 的梯度检查点技术
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
3、数据处理
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
dataset = dataset.map(formatting_prompts_func, batched = True,)
4、训练
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
# 创建微调训练器
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = 2048,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 160,
learning_rate = 1e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 10,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
# 开始训练
trainer_stats = trainer.train()
看到下面的样子就是成功了~
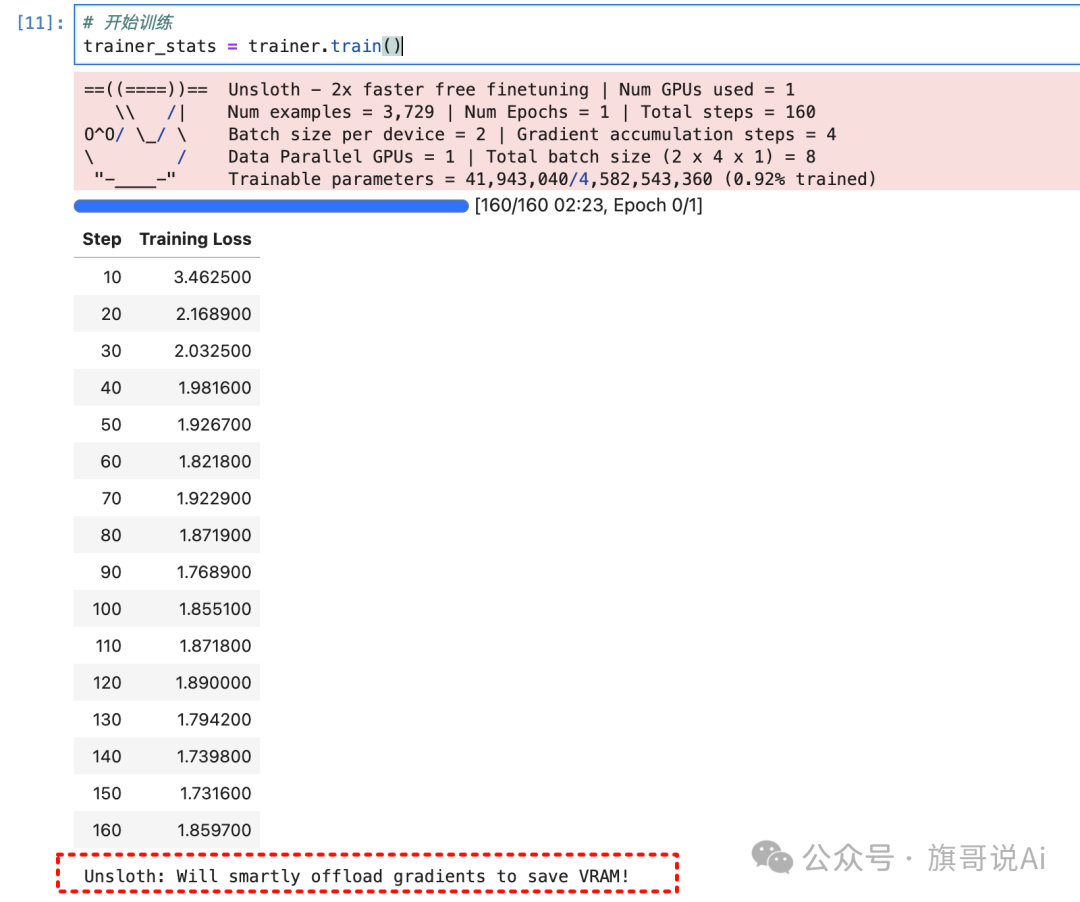 image.png
image.png
测试效果:
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"你是谁?你父亲是谁?", # instruction
"", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
 image.png
image.png
一、保存模型到本地
# 保存模型到本地
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
二、加载模型
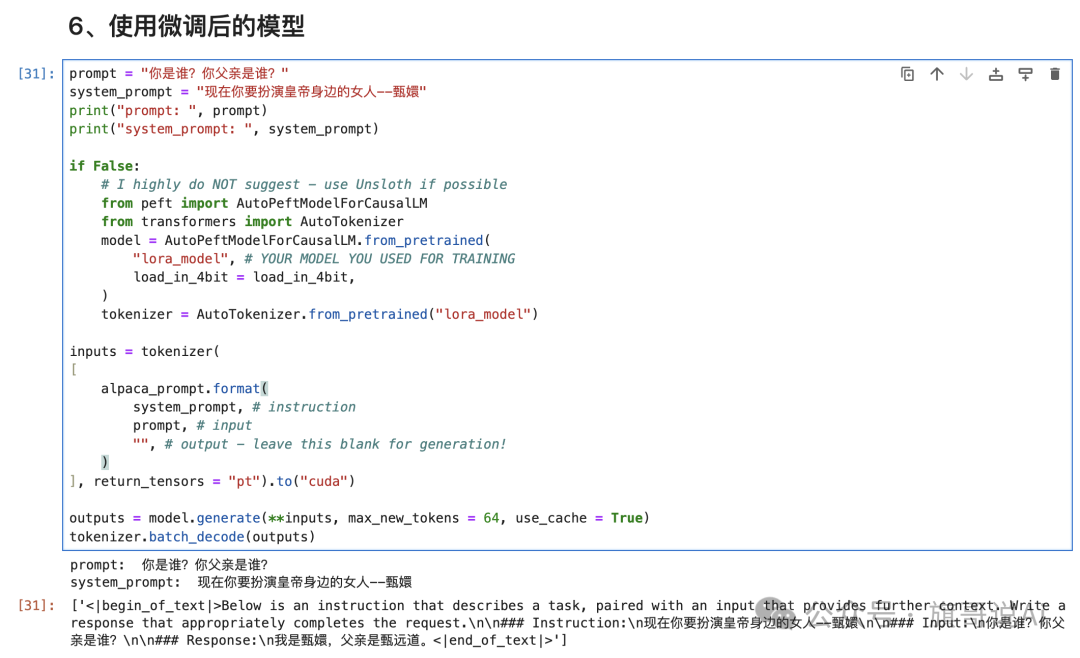
prompt = "你是谁?你父亲是谁?"
system_prompt = "现在你要扮演皇帝身边的女人--甄嬛"
print("prompt: ", prompt)
print("system_prompt: ", system_prompt)
ifFalse:
# I highly do NOT suggest - use Unsloth if possible
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
model = AutoPeftModelForCausalLM.from_pretrained(
"lora_model", # YOUR MODEL YOU USED FOR TRAINING
load_in_4bit = load_in_4bit,
)
tokenizer = AutoTokenizer.from_pretrained("lora_model")
inputs = tokenizer(
[
alpaca_prompt.format(
system_prompt, # instruction
prompt, # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
更多推荐
 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)